
 起点课堂会员权益
起点课堂会员权益功能产品经理视角下的「用数据驱动产品」

在Growth Hacker出现之后,「用数据驱动产品」这一概念愈发的火热,在跟同行业里的一些产品经理交流的时候,基本都是三句离不开数据。笔者并不是大牛,或者说,笔者现在还处于数据小白的阶段,但是由于日常工作的需要,外加上自己兴趣爱好,工作之余抽出时间梳理了一下自己眼中的「用数据驱动产品」这一方法论。
什么是「用数据驱动产品」
数据的本质作用是量化和对比,量化可以让抽象的问题具象化:比如说,北京距离深圳很远,这是一个很抽象的表述;如果换成用数字表述之后,就会变得很具象:从北京到深圳是2400公里;再比如说,北京距离深圳很远,北京距离新加坡也很远,那么接下来如果要问从北京到新加坡和从北京到深圳,哪个更远呢?如果不引入数据量化和对比的方式是无法回答这个问题的。
再看一个问题:从北京到深圳是2400多公里,这么长的路算远么?对于一群(从北京出发)隔三差五的需要飞往美国或者巴黎的人群来说,2400公里并不是很远,但是对于每天都在同一个地方上班,很少外出旅行和出差的群体里的人来说,2400公里已经是一段非常长的距离了。
以上的几个问题都是日常生活中简单的不能再简单的问题了。其实,细细的想一下,所谓的 「用数据驱动产品」背后的问题的本质也相差无几:为了方便说明,我们假设我们公司现在发布了一款图片处理产品:
- 用户反馈我们的产品很不错,我们的产品到底有多好?
- B公司也发布了一款功能基本相似的产品,我们的产品和他们的产品谁的更好?
- 我们的留存20%,我们用户粘性是否已经足够好?
这些问题是我们的产品经理和运营人员几乎每天都要面对的问题。其实我们每天都在用「用数据驱动产品」的思想来构建和完善我们的产品。而对于外行人来说,这个方法论其实也没有那么神秘,直白的将,「用数据驱动产品」其实就是用数据作为工具来衡量我们的产品,将复杂的、抽象的问题通过数据指标组合进行标识,利用一定的数据模型对数据指标的变化进行分析,然后通过寻找问题解决方案进行解决并通过数据来验证结果。在《精益数据分析》一书中如此描述这一个过程:
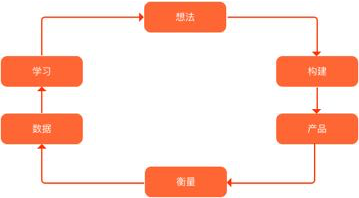
基础系统构建
用数据指导产品策略,第一步,当然是构建能够监控产品对应数据变化的系统。对于具有一定规模的公司来说,一般都有自己的数据监控平台。如果是从零构建数据系统,以下是笔者的一些经验。(在笔者从事开发工作的期间,曾经参与过公司的数据系统构建,这里做粗浅的分享)
如果需要简单快速的构建自己的系统,对定制化的需求没有特别高,可以选择以下的产品。
- 友盟
- 小米统计
这些产品的优点在于,集成简单,所有的数据指标都是己定好的指标,集成SDK就可以用,前期投入成本相对较低。但是这些产品也有他们的局限性,即到后期,自己的定制化需求增加的时候,这些平台就无法满足了。
如果有一定条件,可以自己构建自己的数据中心,至于数据可视化工具么,以下是笔者比较推荐的几个数据可视化工具:
- tableau
- Amplitude
- MicroStrategy
这些产品基本足够强大到能够满足90%的需求吧。至于再复杂的需求,笔者也没有太多经验了,也只能到这里了。
以上是几种可选的构建产品数据监控系统的可选的方法吧,但是具体真正的构建过程中采用哪种方法,还要结合自己产品的规模,可以投入的费用、时长以及内部资源水平等因素进行综合考虑。
在构建了自己的数据平台之后,需要进一步构建的是可以监控市场上其他竞品的数据平台,笔者自己用以下几种方式来“监控”竞品:
- Appannie,如果是做海外市场,Appannie是一个不错的选择,在Appannie上可以看到各个领域的产品数据趋势(虽然绝对值并不准确,但是数据范围和趋势可以做参考)。
- QuestMobile:更面向国内的市场,海外数据监控相对弱一些。
- Statista:一些市场大盘的数据可以在这上面找到,不过statista的服务大多都比较昂贵,个人开账号有点心疼。
- Google:google,恩,这绝对是人类工具史上的最伟大发明之一。如果你能够掌握好Google的使用方法,你几乎能够从上面找到你想找到的所有的信息。
开始使用数据工具
有了数据监控平台之后,下一步需要做的工作就是让这些数据监控工具服务于自己的产品。(以下是笔者自己用数据的过程中总结的一些心得,从朋友、网上以及同事那里学习以及自己总结的)
- 梳理业务,明确业务中存在的问题或者是将来可能出现的问题,使用数据背后的逻辑是解决业务中存在的问题或者预防其中可能出现的问题。所以,脱离了问题看数据是没有任何意义的。梳理业务的目的是找出影响业务发展的关键问题。这个过程需要对业务有高度的理解,能够找出、定义问题,才能解决问题。
- 选择合适的数据指标,明确用什么样的数据统计方式来表示这些问题,一般的来说,同一类产品在业务上有很多共同点,所以对于每一大类的产品,通常都有一些相似数据指标。例如:
- 基础数据:下载量、激活量、新增用户量、活跃用户
- 社交:用户分布、用户留存(次日、3日、7日、月、次月、3月)
- 电商:淘宝指数、网站流量、内容转换率
- 地图导航类:用户每日打开次数、地域分布
- 内容类:内容转化率(内容下载量/内容浏览量)、留存量
- 工具类:功能点击量、应用商城排名
- 其他:竞品数据(下载、激活等)
以上是一些具有共性的产品数据指标,针对自己实际业务,需要进一步定义自己的指标,另外数据指标不是一尘不变的,他是需要随着业务的变化不断的调整的。
- 产品上线后,监控这些数据指标的变化趋势,根据数据的表现结果确定接下来的改进方案
- 改进方案上线后,对比前后的变化,循环此过程直到自己认为自己的各项数据指标都进入良好发展的状态,那么接下来的问题来了,到了一个什么样的程度算是发展良好了?其实这里的判断一般都来源于自己的经验。好与不好是相对的,这里的比较对象是市场大盘的竞品的情况。在进行数据分析起步阶段的PM们可以多请教一些资深的数据产品经理,或者多分析竞品案例,通过分析竞品的数据案例可以更多的了解一款产品的常规衡量维度,以及产品在发展各个阶段的数据变化是如何的。这个时候Appannie和QM就是非常好的案例学习库。
对于一些简单的问题反映和监控,一些简单的数据指标可以非常直观的反映出问题,但是对于那些复杂的问题,简单的数据指标并不能完整的反映出其中的问题,这个时候就需要引入数据模型。
数据分析模型
想必大家应该都听过漏斗模型吧,对于一些高度流程化的业务模块(例如注册登录),漏斗模型可以非常好的反映出业务流程每一步的用户流失问题。如果是想要涵盖产品发展的整个生命周期的各个阶段的话,可以选择AARRR模型。选择业务模型的目的是反映和解决问题。所以在选择模型的时候要注意模型所能解决的问题和自己遇到的问题的匹配性。必要的时候,可以自己创建自己的模型。在这个问题上,没有最好的模型,只有最适合你的模型。
数据分析过程中存在的误区
曾经听过这样一句话:不要相信数据,数据是会骗人的。例如在二战的时候有一个非常有意思的案例:二战时英国空军为了降低飞机的损失,决定给飞机的机身进行装甲加固。由于当时条件所限,只能用装甲加固飞机上的少数部位。他们对执行完轰炸任务返航的飞机进行仔细的观察、分析、统计。发现大多数的弹孔,都集中在飞机的机翼上;只有少数弹孔位于驾驶舱。从数据上说, 加固机翼的性价比最高. 但实际情况缺恰恰相反, 驾驶舱才是最应加固的地方, 因为驾驶舱被击中的飞机几乎都没飞回来.
在这个案例中,看似我们得到的数据欺骗了我们,但是细想一下,其实,数据并没有骗我们,数据就是数据,他只是真是存在的一个物体,是我们在分析的过程中忽略了一些本来应该是很重要的信息,比如上述案例中的“驾驶舱被击中的飞机几乎都没飞回来”。如果说能够把所有没有回来的飞机的中弹情况也列出来,那么结果就会很接近真实情况了。
在定义指标和进行分析的时候都要时刻注意一个问题,我当前选择的这些维度的数据指标是否足够表达我即将面对的这些问题?如果不是,有哪些维度的数据是无法获取的或者是不能用数据表示的?这部分信息应该用什么样的其他的手段进行描述、定义?如何和我的数据模型进行结合?
数据驱动产品,数据只是我们和用户、市场之间对话的工具,是工具有就它的应用场景和局限性,不要把数据当成万能的,不要太过依赖数据,合理的使用数据,最后数据分析最重要的是解决业务中存在的问题。如果脱离了业务,数据分析只是一个华丽的PPT功能,没有任何实际的意义。
本文由 @Jerico 原创发布于人人都是产品经理。未经许可,禁止转载。









写的虽然粗浅,但思路清晰,笔者加油,一起交流学习吧
谢谢鼓励
有点嫩还
恩恩,谢谢评论,会继续努力