
 起点课堂会员权益
起点课堂会员权益从无监督学习说起:算法模型有哪几种?

无监督学习是没有任何的数据标注,只有数据本身。无监督学习解决的主要是“聚类(Clustering)”问题,那它的算法模型有哪几种?
在上一篇笔记里我们简单地学习了监督学习的几种算法模型,今天就来学习一下无监督学习的基本概念和相应的几种算法模型。
无监督学习(Unsupervised Learning)是和监督学习相对的另一种主流机器学习的方法,我们知道监督学习解决的是“分类”和“回归”问题,而无监督学习解决的主要是“聚类(Clustering)”问题。

监督学习通过对数据进行标注,来让机器学习到,比如:小曹多重多高就是胖纸,或者用身高体重等数据,来计算得到小曹的BMI系数;而无监督学习则没有任何的数据标注(超过多高算高,超过多重算胖),只有数据本身。
比如:有一大群人,知道他们的身高体重,但是我们不告诉机器“胖”和“瘦”的评判标准,聚类就是让机器根据数据间的相似度,把这些人分成几个类别。
那它是怎么实现的呢?怎么才能判断哪些数据属于一类呢?
这是几种常见的主要用于无监督学习的算法。
- K均值(K-Means)算法;
- 自编码器(Auto-Encoder);
- 主成分分析(Principal Component Analysis)。
K均值算法
K均值算法有这么几步:
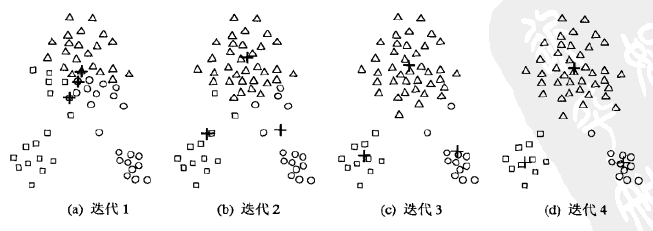
- 随机的选取K个中心点,代表K个类别;
- 计算N个样本点和K个中心点之间的欧氏距离;
- 将每个样本点划分到最近的(欧氏距离最小的)中心点类别中——迭代1;
- 计算每个类别中样本点的均值,得到K个均值,将K个均值作为新的中心点——迭代2;
- 重复234;
- 得到收敛后的K个中心点(中心点不再变化)——迭代4。
上面提到的欧氏距离(Euclidean Distance),又叫欧几里得距离,表示欧几里得空间中两点间的距离。我们初中学过的坐标系,就是二维的欧几里得空间,欧氏距离就是两点间的距离,三维同理,多维空间的计算方式和三维二维相同。
举栗子:
我们现在有三组身高体重数据180kg、180cm,120kg、160cm和90kg、140cm,提问:这三个人里,哪两个人的身材比较相近呢?
这三组数据可以表示为A(180,180),B(120,160)和C(90,140),这就是我们很熟悉的平面直角坐标系里的三个点,他们之间的距离大家都知道算。
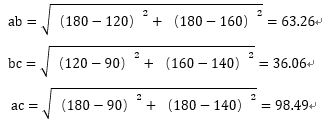
从结果可以看到Bc间的距离最小,也就是Bc的身材最相似。我们再增加一个维度,腰围,分别是100cm、120cm和140cm(随便编的不要当真),那现在这三组数据可以表示为A(180,180,100),B(120,160,120)和C(90,140,140),这就变成了我们高中学过的空间直角坐标系里的三个点,要计算它们之间的距离也很简单。
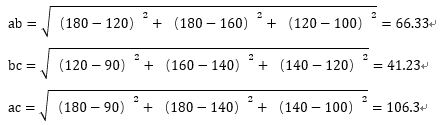
现在还是Bc的身材最相似,如果我们增加N个维度,数据就可以用(X₁,X₂,X₃,…..,Xn)和(Y₁,Y₂,Y₃,…..,Yn)来表示,他们之间的距离就是
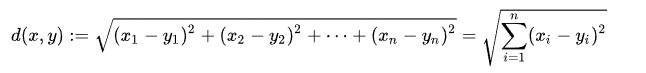
K均值算法里样本点到中心点的距离就是这么计算的,这个用空间点,来表示数据的思想,在机器学习领域是非常常见和重要的,以后还会经常见到。值得注意的是:虽然K近邻算法和K均值算法没有什么关系,但是它们的思想有想通之处,并且原始模型实际使用起来计算起来都比较慢。
自编码器
自编码器(Auto-encoder)(其实相当于一个神经网络,但这里不用神经网络的结构来解读)做的事情很有意思,它的基本思想就是对输入(input)编码(encode)后得到一个隐含的表征再解码(decode)并输出(output),这么看起来不是在绕圈圈吗?
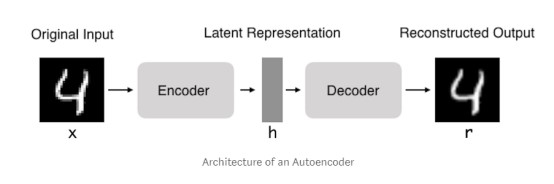
如果说我们的自编码器只是为了得到一个和输入一模一样的输出,那我们的行为确实没什么用,但是细心的胖友,你们觉得这张图里什么是关键呢?
对了,是中间的隐含表征(latent representation)!
自编码器的两个主要应用是降噪(denoising)和稀疏化数据(sparse)。
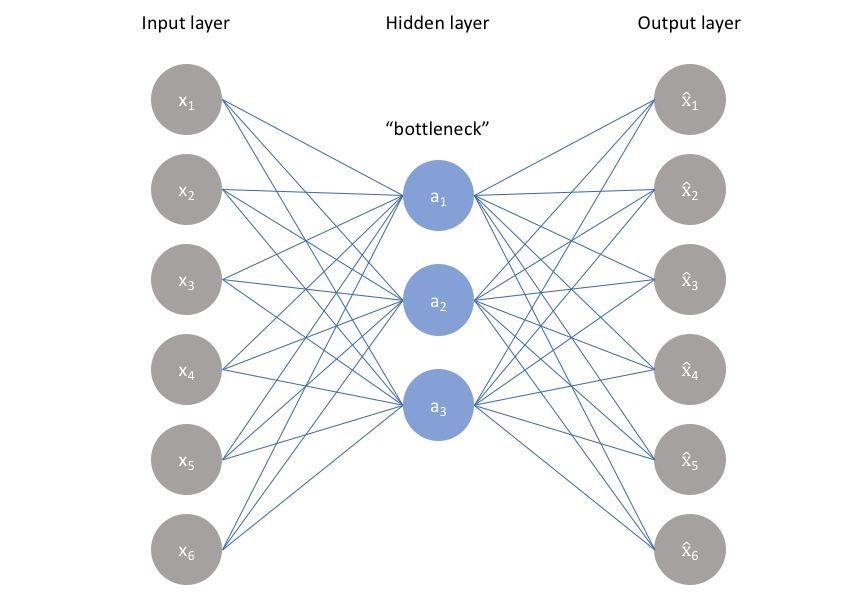
什么叫降噪和降维呢?
让我们用这张图来理解,图中有三层,输入、隐含和输出层,每一层的么一个圈圈代表一个特征。输入层经过编码变成了中间的隐含层,隐含层解码后得到后面的输出层。可以看到,隐含层只有输入层的一半,原本的6个特征变成了3个特征,这意味着什么?
又到了举栗子的时间:
如果要来表示小明的身材,输入的六个特征分别为“肉多”、“体脂率高”、“质量大”、“个子不高”、“总是心情好”、“喜欢笑”而隐含层的三个特征为“肉多”、“体脂率高”、“个子不高”,这个自编码器就是用来降噪的。
噪音(noise)指的是影响我们算法模型的不相关因素;降噪呢,就是用特定的方法去掉这些不相关的因素。
如果要来表示小明的主要特征,输入的六个特征还是“肉多”、“体脂率高”、“质量大”、“个子不高”、“心情好”、“喜欢看剧”而隐含层的特征变成了“胖”、“矮”和“开朗”,这个自编码器就是稀疏自编码器。
稀疏化数据,就是指将密集的浅层含义的数据(比如说:肉多这样的外在表现)表示为稀疏的更抽象的数据(将外在表现提炼为总结性的特征,比如:胖)。
完成上述两个任务,都需要构建合适的损失函数(loss function)(了解一下)。
(后面的依据个人兴趣选择是否阅读)
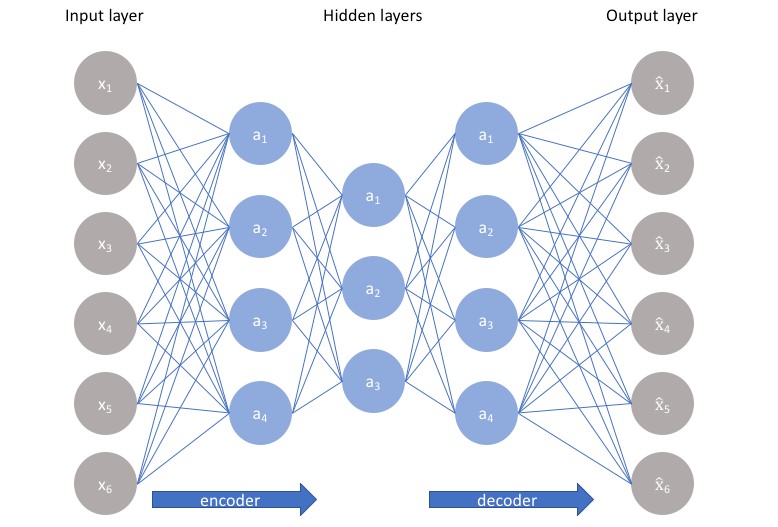
隐含层的层数是可以增加的,每一层都可以作为我们需要的特征,多层的结构能够让自编码器对特征的分析更加准确和稳定,而如果这个层数再增加一些(很多很多很多层)。
(省略了后面的解码步骤)
它就是堆叠/卷积自编码器(Convolution autoencoder),可以说是一种卷积神经网络(Convolutional neural network,CNN),更多的关于神经网络的知识会在后面详细说。
而回到最开始的图,我们刚才一直在说的是隐含层的意义和变化,那最后的输出一点用都没有吗?
这里不得不提一下生成式对抗网络(Generative adversarial networks,GAN)。
生成式对抗网络的精髓就是两个网络,一个网络生成图片,一个网络辨别图片是不是真实的,当生成图片的网络能够“欺骗”识别图片的网络的时候,我们就得到了一个能够生成足够真实图片的网络。
这是一个很有趣的模型,机器根据已有的实物创造了实际中不存在的事物,下图是从真实图片转化为生成图片的过程。

这个思想能够实现一些很神奇的事情,比如:将文字变成图像,用对抗网络来构造药品和疾病的对抗等(https://www.jiqizhixin.com/articles/2017-08-23-6)
而对抗自编码器(Adversarial Autoencoder,AAE) ,使用了最近提出的生成对抗网络(GAN),通过任意先验分布与VAE隐藏代码向量的聚合后验匹配,来实现变分推理。
简单地说,就是它把GAN和自编码器组合成了一个具有生成能力的模型,也就是对抗自编码器。AAE能够在监督、无监督的条件下,都展现出不错的识别和生成能力。由于相关资料和文献不算很多,我也没有很清楚它的具体应用场景,这里就不做过多的解读了,欢迎大家给出一些指点。
主成分分析
主成分分析(Principal Component Analysis)是一种数据降维的方法,我们可以简单地把数据降维和稀疏化数据当成一个意思来理解(还是有区别的)。
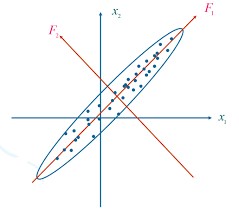
从数学的视角来看,二维平面中的主成分分析,就是用最大方差法将坐标系里分布的点投影到同一条线上(一维的);三维空间中的主成分分析,就是同理将空间中的分布点投影到同一个(超)平面上。
最大方差法不做过多解释(要摆公式),但我们知道方差是表示一组数据间差异大小的,方差最大就保证了数据的间隔足够大,这也就意味着数据在降维后不容易发生重叠。比如:上面的图,我们会用F₁而不是F₂。
其实在实际应用中主成分分析主要是数学方法,但是为了帮助理解还是打个比方。
上文中提到的身材的特征的稀疏化,表达其实就可以理解为主成分分析。顾名思义,“把主要成分提取出来分析”,就像我们在讨论一个国家经济实力的时候,不会讨论这个国家一年生产多少石油,出口多少商品,进口多少原材料,国民总共又拿了多少工资。我们会用国民生产总值和国民人均生产总值,来代表上面所说的哪些零散的数据,这就是主成分分析。
参考资料
K均值算法概念及其代码实现:https://my.oschina.net/keyven/blog/518670
欧几里得距离:https://en.wikipedia.org/wiki/Euclidean_distance
K-means算法实现:https://feisky.xyz/machine-learning/clustering/k-means/
自编码器与堆叠自编码器简述:http://peteryuan.net/autoencoder-stacked/
对抗自编码器:https://blog.csdn.net/shebao3333/article/details/78760580
从自编码器到生成对抗网络:一文纵览无监督学习研究现状:https://zhuanlan.zhihu.com/p/26751367
翻译:AAE 对抗自编码(一):https://kingsleyhsu.github.io/2017/10/10/AAE/
生成对抗网络原理与应用:GAN如何使生活更美好:https://www.jiqizhixin.com/articles/2017-08-23-6
对抗生成网络详解:https://cethik.vip/2017/01/11/deepGan/
主成分分析(PCA)-最大方差解释:https://blog.csdn.net/huang1024rui/article/details/46662195
主成分分析(principal components analysis, PCA)——无监督学习:https://www.cnblogs.com/fuleying/p/4458439.html
图片来源:google、个人
作者:小曹,公众号:小曹的AI学习笔记
本文由 @小曹 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









哦吼,先来留名 ❓