
 起点课堂会员权益
起点课堂会员权益大数据案例:啤酒尿布的关联算法怎么来的?

故事背景:
在一家超市中,通过大数据分析发现了一个特别有趣的现象:尿布与啤酒这两种风马牛不相及的商品的销售数据曲线竟然初期的相似,于是就将尿布与啤酒摆在一起。没想到这一举措居然使尿布和啤酒的销量大幅增加了。这可不是一个笑话,而是一直被商家所津津乐道的发生在美国沃尔玛连锁超市的真实大数据案例。原来,美国的妇女通常在家照顾孩子,所 以她们经常会嘱咐丈夫在下班回家的路上为孩子买尿布,而丈夫在买尿布的同时又会顺手购买自己爱喝的啤酒。

这个发现为商家带来了大量的利润,但是如何从浩如烟海却又杂乱无章的大数据中,发现啤酒和尿布销售之间的联系呢?这又给了我们什么样的启示呢?
这就是关联!
关联,其实很简单,就是几个东西或者事件是经常同时出现的,“啤酒+尿布”就是非常典型的两个关联商品。所谓关联,反映的是一个事件和其他事件之间依赖或关 联的知识。当我们查找英文文献的时候,可以发现有两个英文词都能形容关联的含义。第一个是相关性relevance,第二个是关联性 association,两者都可以用来描述事件之间的关联程度。其中前者主要用在互联网的内容和文档上,比如搜索引擎算法中文档之间的关联性,我们采用 的词是relevance;而后者往往用在实际的事物之上,比如电子商务网站上的商品之间的关联度我们是用association来表示的,而关联规则是 用associationrules来表示的。
如果两项或多项属性之间存在关联,那么其中一项的属性值就可以依据其 他属性值进行预测。简单地来说,关联规则可以用这样的方式来表示:A→B,其中A被称为前提或者左部(LHS),而B被称为结果或者右部(RHS)。如果 我们要描述关于尿布和啤酒的关联规则(买尿布的人也会买啤酒),那么我们可以这样表示:买尿布→买啤酒。
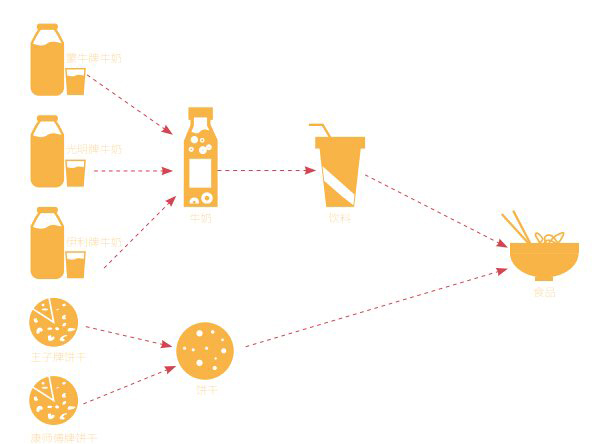
关联算法的两个概念
在关联算法中很重要的一个概念是支持度(Support),也就是数据集中包含某几个特定项的概率。
比如在1000次的商品交易中同时出现了啤酒和尿布的次数是50次,那么此关联的支持度为5%。
和关联算法很相关的另一个概念是置信度(Confidence),也就是在数据集中已经出现A时,B发生的概率,置信度的计算公式是:A与B同时出现的概率/A出现的概率。
数 据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个变量的取值之间存在某种规律性,就称为关联。关联可分为简单关联、时序关联、因果关联等。 关联分析的目的是找出数据库中隐藏的关联网。有时并不知道数据库中数据的关联函数,或者即使知道也是不确定的,因此关联分析生成的规则带有置信度。
关联规则挖掘发现大量数据中项集之间有趣的关联或相关联系。它在数据挖掘中是一个重要的课题,最近几年已被业界所广泛研究。
关联规则挖掘的一个典型例子是购物篮分析。关联规则研究有助于发现交易数据库中不同商品(项)之间的联系,找出顾客购买行为模式,如购买了某一商品对购买其他商品的影响。分析结果可以应用于商品货架布局、货存安排以及根据购买模式对用户进行分类。
关联规则的发现过程可分为如下两步:
第一步是迭代识别所有的频繁项目集(FrequentItemsets),要求频繁项目集的支持度不低于用户设定的最低值;
第二步是从频繁项目集中构造置信度不低于用户设定的最低值的规则,产生关联规则。识别或发现所有频繁项目集是关联规则发现算法的核心,也是计算量最大的部分。
支 持度和置信度两个阈值是描述关联规则的两个最重要的概念。一项目组出现的频率称为支持度,反映关联规则在数据库中的重要性。而置信度衡量关联规则的可信程度。如果某条规则同时满足最小支持度(min-support)和最小置信度(min-confidence),则称它为强关联规则。
关联规则数据挖掘阶段
第 一阶段必须从原始资料集合中,找出所有高频项目组(LargeItemsets)。高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一 水平。以一个包含A与B两个项目的2-itemset为例,我们可以求得包含{A,B}项目组的支持度,若支持度大于等于所设定的最小支持度 (MinimumSupport)门槛值时,则{A,B}称为高频项目组。一个满足最小支持度的k-itemset,则称为高频k-项目组 (Frequentk-itemset),一般表示为Largek或Frequentk。算法并从Largek的项目组中再试图产生长度超过k的项目集 Largek+1,直到无法再找到更长的高频项目组为止。
关联规则挖掘的第二阶段是要产生关联规则。从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小可信度(MinimumConfidence)的条件门槛下,若一规则所求得的可信度满足最小可信度,则称此规则为关联规则。
例如:经由高频k-项目组{A,B}所产生的规则,若其可信度大于等于最小可信度,则称{A,B}为关联规则。
就 “啤酒+尿布”这个案例而言,使用关联规则挖掘技术,对交易资料库中的记录进行资料挖掘,首先必须要设定最小支持度与最小可信度两个门槛值,在此假设最小 支持度min-support=5%且最小可信度min-confidence=65%。因此符合需求的关联规则将必须同时满足以上两个条件。若经过挖掘 所找到的关联规则{尿布,啤酒}满足下列条件,将可接受{尿布,啤酒}的关联规则。用公式可以描述为:
Support(尿布,啤酒)≥5%andConfidence(尿布,啤酒)≥65%。
其 中,Support(尿布,啤酒)≥5%于此应用范例中的意义为:在所有的交易记录资料中,至少有5%的交易呈现尿布与啤酒这两项商品被同时购买的交易行 为。Confidence(尿布,啤酒)≥65%于此应用范例中的意义为:在所有包含尿布的交易记录资料中,至少有65%的交易会同时购买啤酒。
因此,今后若有某消费者出现购买尿布的行为,我们将可推荐该消费者同时购买啤酒。这个商品推荐的行为则是根据{尿布,啤酒}关联规则而定,因为就过去的交易记录而言,支持了“大部分购买尿布的交易,会同时购买啤酒”的消费行为。
从上面的介绍还可以看出,关联规则挖掘通常比较适用于记录中的指标取离散值的情况。
如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。
via:i天下网商















数据挖掘层面的东西,跟大数据关系不大,趁着大数据这个概念火了,什么玩意都冒充大数据
语无伦次,你扯得蛋疼吗
有点专业不太易理解。。。平时能应用到这个理论么
可以的,很多超市等行业都可以应用到