
 起点课堂会员权益
起点课堂会员权益AI产品之路:机器学习(二)

关于机器学习,你了解多少呢?
上篇文章里,主要分享了关于机器学习、深度学习的基本概念和他们之间的区别,最后介绍了有监督学习方式中的回归。其实我在最后留下一点小问题,那就是如果数据不是线性关系的话,怎么回归?这篇文章就会回答这个问题,主要分享监督学习和非监督学习中的三大类:
- 监督学习方式下,回归中的“非线性回归”
- 监督学习方式下的“分类”
- 非监督学习方式的“聚类”
- 关于机器学习的复盘
1.非线性回归
直逼主题,上篇我们假定的数据都是线性的,那么最后当然可以回归出y=wx+b这样的线性方程,可我们最终是想通过机器学习解决现实问题,而现实中的很多数据不可能单单是线性关系,如果强行使用,那么算法模型只能是欠拟合,误差非常大。
这里我们就着重说一下,回归中的非线性回归,而其中应用最多的就是“逻辑回归”。
先上公式:
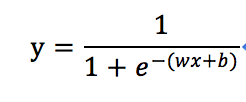
看到这个公式先别慌,其中你们注意(wx+b)是我们上篇已经熟悉的线性回归方程,把它想象成一个整体,带入到这个新公式中,代表着什么呢?下面我们看这个公式的函数图
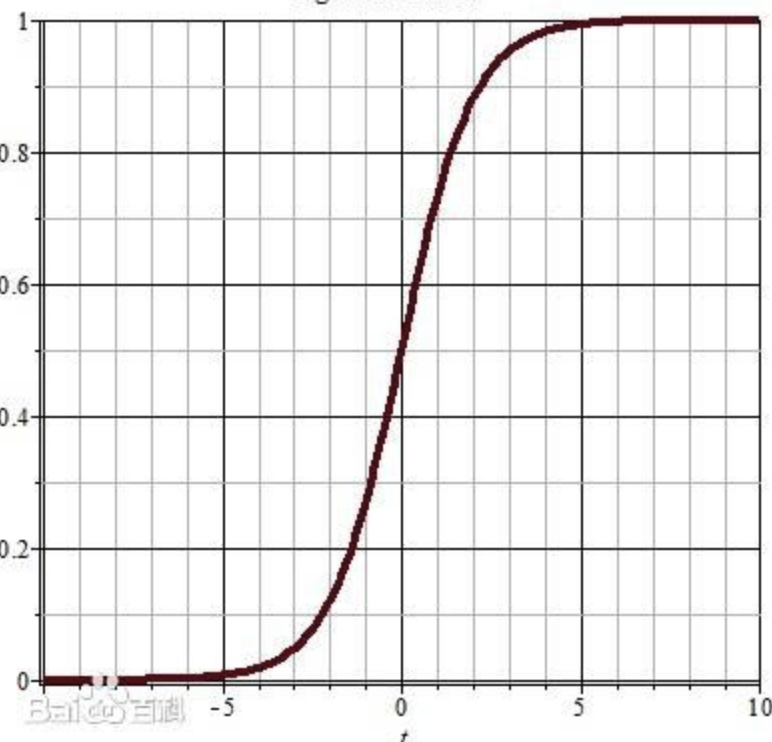
可以看到,在x可以取(-无穷小,+无穷大)的区间里,整个y值是的区间只能是【0,1】之间。具体的数学函数转换如果搞不明白完全没关系,只需要回忆一下上一篇中“线性回归”的思想,通过找到损失函数Loss最小的对应wx+b中对应的w与b的值。而这个逻辑回归函数的作用,在仅仅是把x多映射一次,即让输出的y值恒定落在【0,1】这个区间而已,其回归思想的本质并没有改变。
那么为什么要加入这个函数呢?其实是方便做概率判断:
因为这个函数会让x无论输入的是什么,最终输出的y肯定是0-1之间的值,那么越接近1,我们可以认为越接近“1”代表的特征,越接近0,我们认为越接近“0”代表的特征。而“0”与“1”具体要赋予什么意义,就看我们到底想通过机器学习去识别什么了。
2.监督学习–“分类”
先感性谈谈“分类”这个概念。就是我们希望有一台机器,可以帮助我们进行图像的分类识别。比如我这里有一堆混杂着“鱼”、“狗”和“猫”的图片,光靠人力完成是非常困难的,我想通把这些大量的数据输入给计算机,它很快就能完成而不需要耗费我很长时间去一个一个挑选。但我们知道计算机天生不具备这样的功能,就可以通过机器学习中的“分类”去完成。有了前面“回归”机器学习的思想基础,这个应该很好理解了。
即我会找到大量的“鱼”“猫”和“狗”的图片,每种都对应好标签比如“1”“2”“3”。这时候我们拿这些数据去训练分类器。分类器的训练过程和线性回归基本很相似:
- 建立映射关系的假说即 y=wx+b
- 找到全局损失函数Loss与我们想要求解的w与b的映射关系方程
- 找到Loss符合误差范围的w与b (训练过程结束)
- 拿着训练好的模型去用验证集验证
3.非监督学习–“聚类”
前面我们介绍的线性回归、非线性回归和分类,都属于“监督学习方式”,要在训练数据之前进行标记,这样的数据模型才可以被训练。但数据量很大的时候,人工标注起来是非常困难的。
先回忆一下非监督学习的定义: 获得训练的向量数据后没有标签的情况下,尝试找出其内部蕴含的一种关系的挖掘工作。而聚类,在感性的认知就是把特征形态相同或相近的聚合到一个概念类别下,把特征形态不同的分开。
聚类核心思想:通过对数据进行特征抽象和提取,转换为空间中的向量,通过计算每个“向量”的距离,从远近的角度去判定是否从属一个类别。其本质就是把现实世界中的特征,转化为数学的空间向量,这样我们就把现实的特征问题,转化成了一个可能通过数学方式解决的“向量计算问题”。当然在具体计算的时候还涉及到“特征提取及转换”的步骤(这也是深度学习的重要内容)
举个例子我这里有几个概念,“卡车”、“汽车”、“飞机”和“人”,他们每个都可以用空间中的向量去表示,那么“卡车”与“汽车”的距离就应该是最近的,其次是“飞机”,因为他们都属于“交通工具”这个大类,“汽车”与“人”代表的向量应该是空间中距离最远的,这样就是实现了现实世界概念特征的聚类。
4.机器学习的复盘
到这里已经把机器学习中最重要的概念和原理大体讲了一遍。其实发现并没有特别难的样子,主要在于理解机器学习的思想与基本原理。
其实机器学习(深度学习)都是手段,我们的目的是让计算机可以对现实物理世界比如图像、声音、视频等进行分类、识别甚至一定程度的理解和反馈。可计算机并不能像人类一样可以进行抽象思考,而机器学习的本质,就是把这些物理世界的特征进行数学化,转换成计算机可以听懂的语言,这样它就可以对这些“数学化的物理特征”进行计算了,只不过在我们看来,它好像是通过像人一样学习和思考似的。
对于如何判定机器学习的结果,其本质也是转换成数学中的误差问题进行求解,找到符合我们要求的误差,即认为机器学习完成。
最后我们记住一个公式: y=wx+b,看似简单的公式,后面在神经网络和深度学习中会经常用到,而且无论是学习方式的转换,还是神经网络结构的变换,其最终目的,简单理解的话都可以认为是建立损失函数Loss与w和b的一个映射关系,找到Loss符合我们要求的对应的w和b。(当然怎么找,这就非常复杂了,我也在学习中)
机器学习的部分就分享到这里,下一篇会更新有关“神经元和神经网络”的知识,这是了解深度学习的基石。
相关阅读
本文由 @ Free 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议









监督学习–“分类”这个模块标注,并非是给不同图标注1、2、3。而是标注上图片里的生物特征,几个爪子什么颜色眼睛之类的。
非监督学习–“聚类”这个模块由于数据量大需要用非监督学习,是对一个品类(如猫这个品类)需要标注的字端及其复杂,人工识别标注几张图就要非常非常久。
楼主看下,我理解的对么 😕
两篇文章仔细看下来,说不清楚具体学到了什么。但总算对机器学习有个大致了解,希望以后能成为AI产品经理一员。多谢分享~