
 起点课堂会员权益
起点课堂会员权益
从0构建大模型知识体系(4):大模型的爸爸Transformer
 技术知识、行业知识、业务知识等,都是B端产品经理需要了解和掌握的领域相关的知识,有助于进行产品方案设计和评估
技术知识、行业知识、业务知识等,都是B端产品经理需要了解和掌握的领域相关的知识,有助于进行产品方案设计和评估在人工智能领域,尤其是自然语言处理(NLP)的浪潮中,Transformer架构无疑是近年来最重要的突破之一。它不仅彻底解决了传统循环神经网络(RNN)的健忘和训练速度慢的问题,还开启了大语言模型的新纪元。本文将从机器翻译这一经典任务出发,深入剖析Transformer架构的核心原理,包括编码器-解码器架构、注意力机制的奥秘,以及它如何通过纯注意力机制实现高效的序列处理。

按照惯例,结论先行
这篇文章要讨论啥?
讨论当前大语言模型的基石——Transformer。Transformer彻底解决了RNN健忘和训练速度慢的问题,实现性能和效率的飞跃,并成为自然语言处理的主宰。现在的大模型如DeepSeek、GPT都是在Transformer的基础上发展而来的,因此了解Transformer有助于理解大语言模型是如何理解自然语言的。
我会以解决双语翻译问题为切入口,剖析Transformer是如何通过纯注意力机制构建起编码器-解码器架构来解决这个问题的
文章讨论的核心问题和结论是啥?
① 什么是编码器-解码器架构?
这是一个用于解决翻译问题的经典架构,整个模型包含编码器和解码器两部分,编码器负责将原文转化成机器能高效理解的数字,解码器负责将数字转化为人类能理解的语言。
② 什么是注意力机制?
这是一种能让机器理解字词之间关联关系的方法。比如在“这老板真水”这句话中,只有注意到“水”和“老板”的修饰关系才能将这里的水理解为水平低下,而非物理意义上的水。

③ 什么是Transformer?
一个采用编码器-解码器架构并完全使用注意力机制构建起来的双语翻译模型
④ Transformer是怎么训练的?
不断的给它“原文→译文”语料对,通过这些语料来调整参数
⑤ 怎么量化翻译质量?
用BLEU评分。核心思想是看机器翻译结果和人工翻译结果的重合度有多高。
⑥ Transformer和现在的大模型到底是什么关系?
Google把Transformer的编码器拿出来优化,于是得到了BERT。OpenAI把解码器拿出来优化,于是得到了GPT
“我让GPT帮我修改这篇文章,它只回了一句话:‘你见过儿子指点老子的吗?’”
——题记
在上一篇文章《从0构建大模型知识体系(3):大模型的祖宗RNN》中,我们介绍了循环神经网络(RNN)是如何通过循环结构来处理自然语言这样的序列数据,并训练了一个简单的客服机器人来完成文本生成任务。同时也深入到模型基于概率的输出机制来阐释大模型幻觉现象的根本原因。
在很长一段时间里RNN及其改良版本(LSTM)都是自然语言处理领域的王者。然而,RNN头顶上的两朵乌云一直没有被彻底驱散:
1)健忘:句子一长模型就无法记住开头的信息。比如你问它“ 小明的妈妈生了三个儿子,大儿子叫大毛,二儿子叫二毛,三儿子叫什么?”它要是说叫三毛,那显然就是没有记住开头“小明的妈妈生了三个儿子”这个信息,所以三儿子应该叫小明才对。
2)训练速度慢:RNN中有大量串行计算导致GPU加速程度有限。回顾一下,所谓串行计算是指“不先算出A,就算不出B”,并行计算是指“A算没算出来都不影响B算不算得出来”。模型中的计算如果都是并行的话就能用GPU极大加速,但很可惜,RNN中的很多计算都是串行的。
那有没有一种方法,既能让模型记住长距离信息,又能并行计算,让模型训练又快又好呢?那必然有啊,不然我为啥要这么设问呢~~
2017年,Google发表的论文Attention is All You Need彻底解决了这两个问题。平时咱们刷文章刷视频看到的Transformer就是这篇论文里提出的。哇~这篇论文可太拽了:
1)首先它这个标题就很拽。“Attention is All You Need”仿佛是在宣告全世界:“你们都别瞎搞了,用我的方法就行了”
2)更拽的是他们给自己的模型取名叫“Transformer”(变形金刚,现在知道为啥封面图要放个变形金刚了吧~)。这相当于咱设计个模型然后取名叫“齐天大圣”
3)当然,最拽的还得是这篇论文彻彻底底地改变了NLP领域的游戏规则。就这么说吧,如果把chatGPT、DeepSeek当成摩天大楼,那Transformer就是砖瓦——没有砖瓦是盖不起楼的。比如我们来快速看一眼DeepSeek-V3的架构图
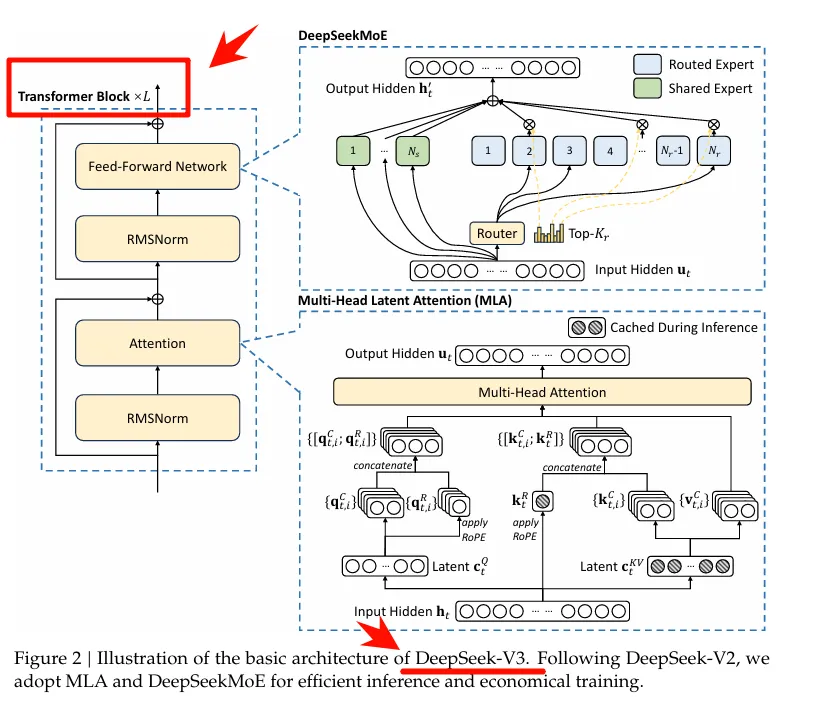
其中明确表明了它是通过堆叠多个Transformer块而来的。所以把Transformer比喻成砖瓦还是很恰当的。
而缔造这一切的传奇论文却并不是为了解决“创造一个与人类智能水平相当的机器”这种宏大的问题,反而是为了解决“提高机器翻译质量”这种相比起来“没那么起眼”的问题。
从机器翻译说起:序列到序列的挑战
输入是一个序列,输出也是一个序列的任务,就被称为“序列到序列”(Sequence-to-Sequence, 简写为Seq2Seq)任务。假设你想开发一个中译英的翻译工具。用户输入中文“这老板真水”,模型能输出英文“This boss is really a joke”。这里的输入是一个完整的句子(序列),输出也是一个完整的句子(序列),而且输入和输出的长度很可能不一样(中文5个字,英文6个词)。更复杂的是,词语之间并非简单的逐字对应(“水”被翻译成了“a joke”而非water)。
解决Seq2Seq问题的经典架构:编码器-解码器(Encoder-Decoder)。别怕,编码器解码器这些词虽然听上去很高端,但背后的思想很简单:
- 编码:即是将外界给模型的输入编写成机器可以理解的代码
- 解码:即是将模型内部的代码翻译成人类可理解的输出
人类做翻译的过程也可以看作一个编码-解码的过程。比如中英翻译,别人说一句“你好”之后,我们得先理解这句中文是“简单问候”这么个“意思”,然后再通过脑内的语言系统把这个“意思”翻译成“hello”输出,我们可以这样表示这个过程:

对于机器来说,这个图就得改成这样
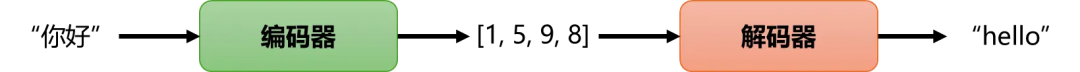
唯一的区别就是编码器输出的那个“意思”在机器中是用一串数字来表示的。所以你看,机器将我们给它的输入(你好)编写成了一串人类无法理解的数字(1,5,9,8),但这串数字通过解码器就能翻译成人类可理解的输出(hello),这就是所谓的编码器-解码器架构。
总结一下,编码器负责理解外界输入,解码器负责向外界输出。
Transformer采用的就是这个架构,那显然,在这个架构下决定翻译质量好坏的就是编码器和解码器的具体设计了。这就不得不提到大名鼎鼎的注意力机制了,也就是论文标题Attention is All You Need中的 Attention
理解注意力机制需要4步
第一步,先感性理解注意力机制的作用:能让模型理解序列中元素之间的关系。以“这老板真水”为例,“这老板真”几个字并没什么特殊的,特殊的是“水”,因为这里的“水”并不是物理意义上的水,而是指一个人水平低下。人类之所以能理解这一点是因为我们能“注意到”这里的“水”是用来形容“老板”的。换句话说,当我们读到“水”这个字时,只有注意到它和“老板”之间的修饰关系才能正确理解其含义。注意力机制要干的事儿就是让机器也能像这样理解一个序列中元素之间的关系。
第二步,感性理解注意力机制的原理。我们来看个故事。有这么一场相亲会,会上一共有3个嘉宾:

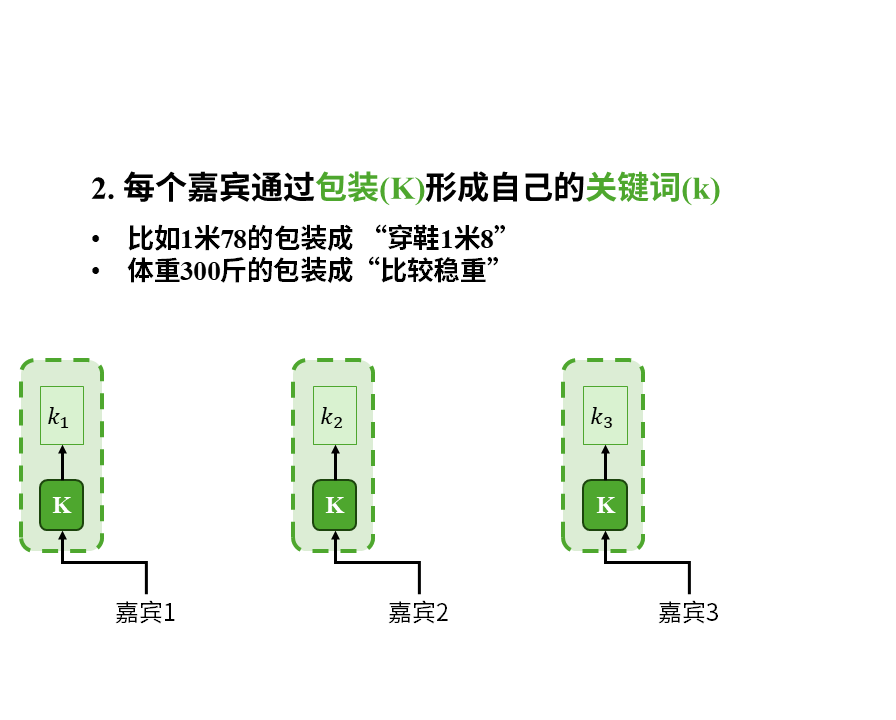
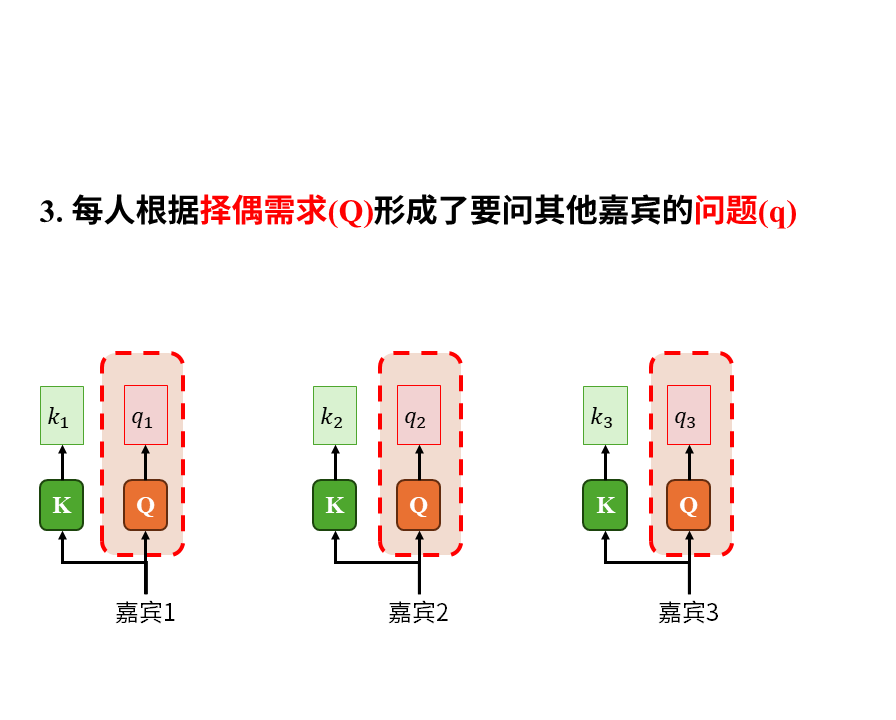
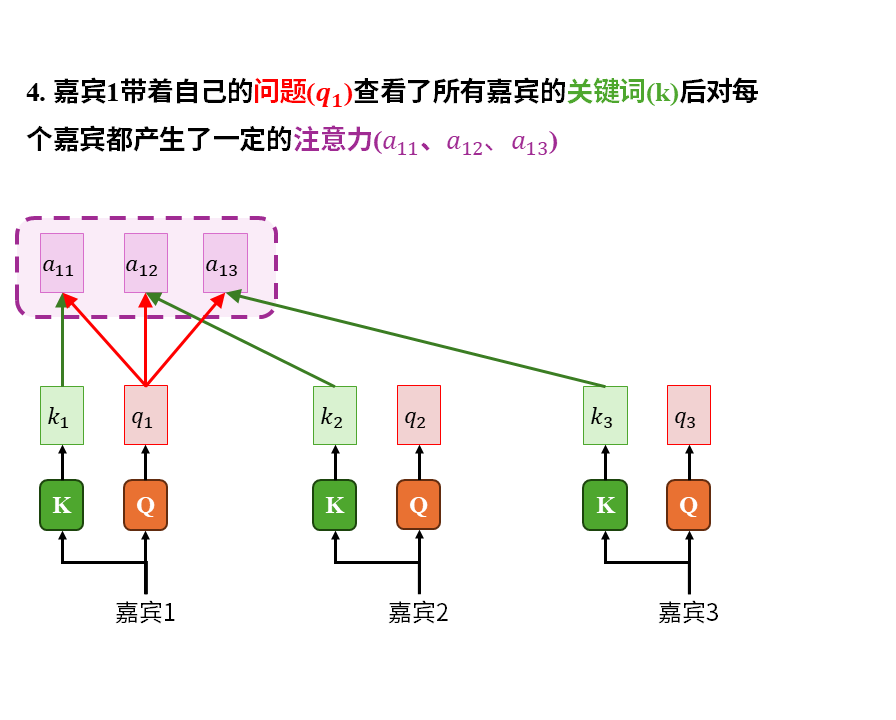
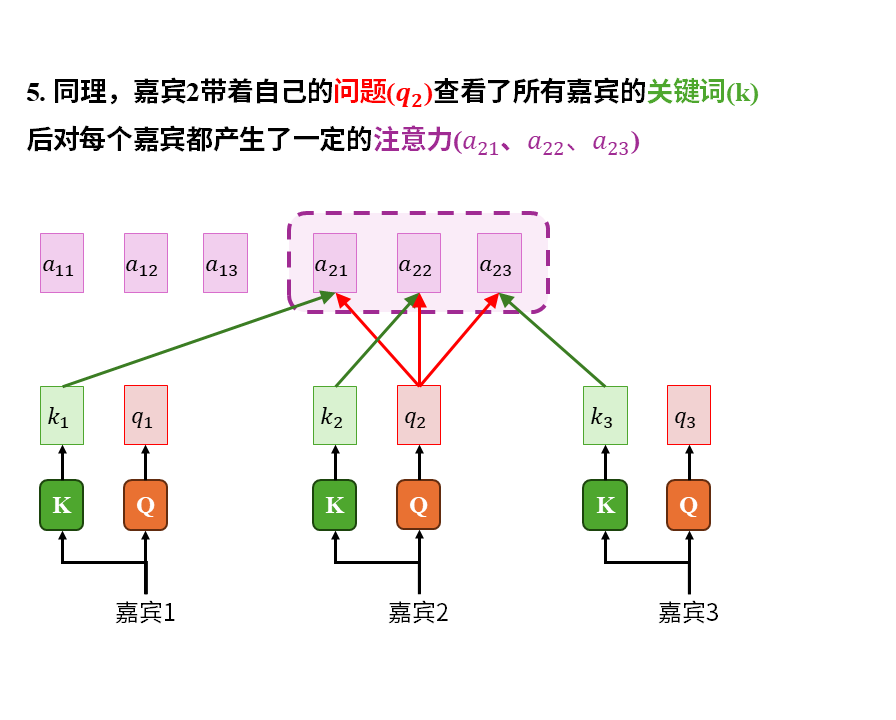
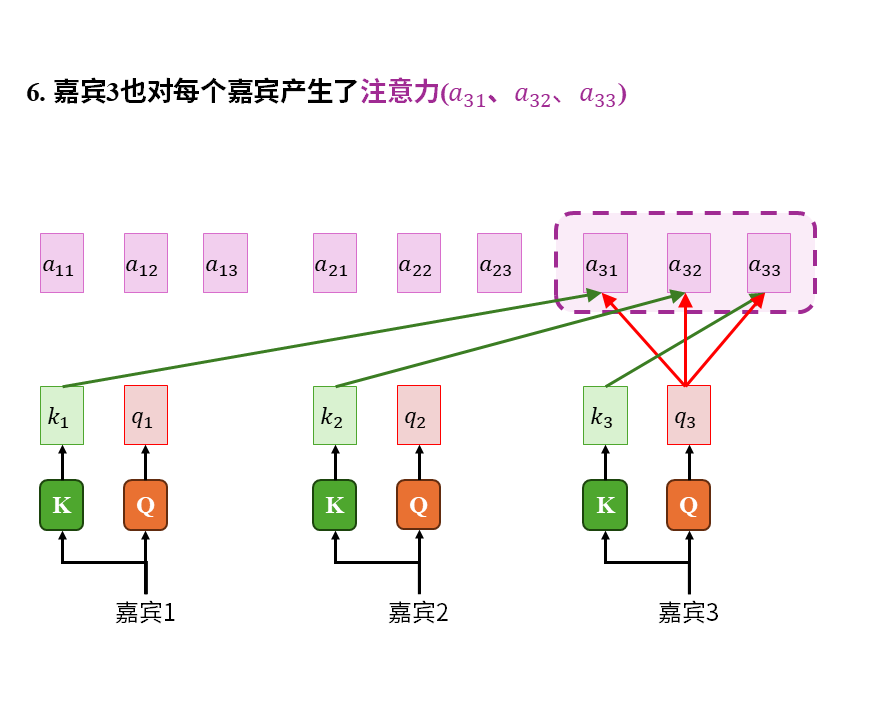
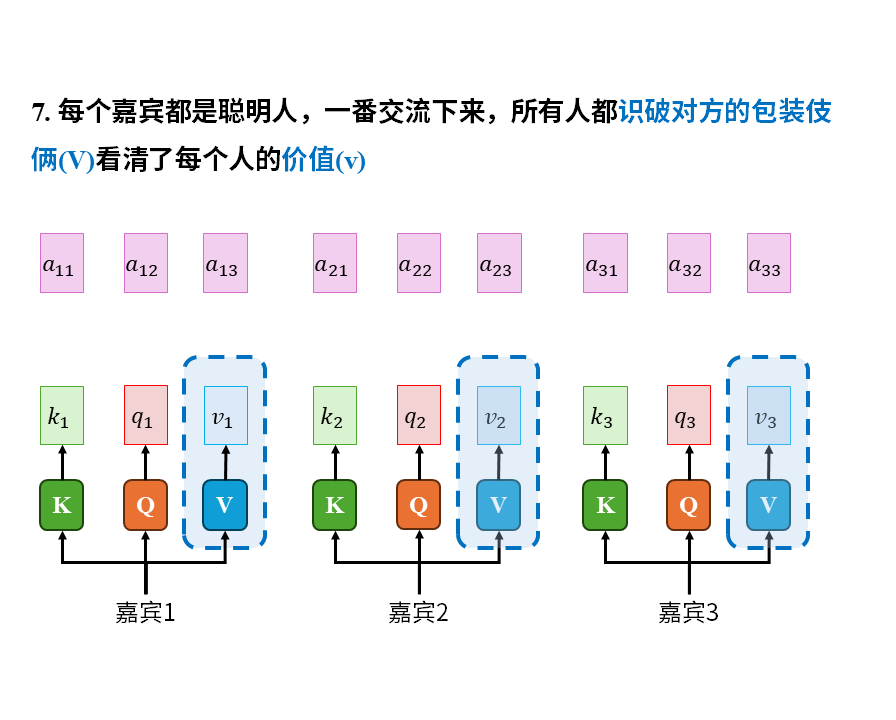
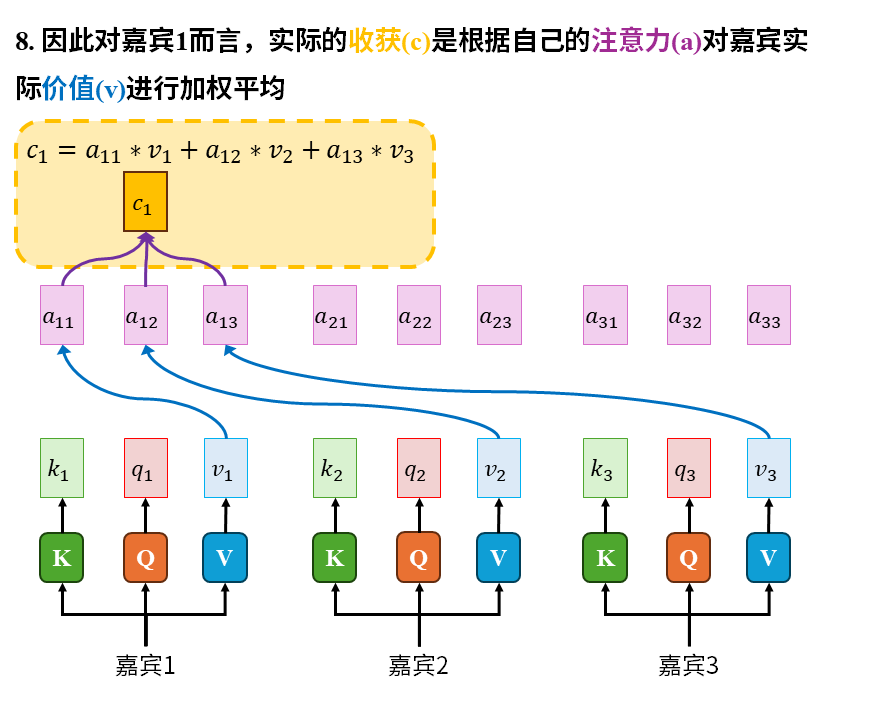
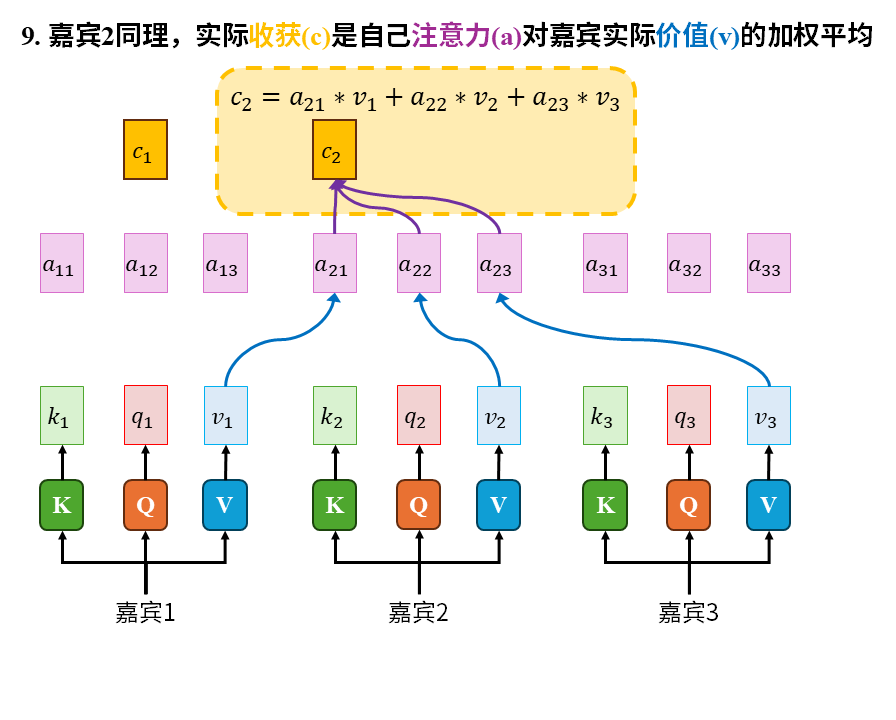
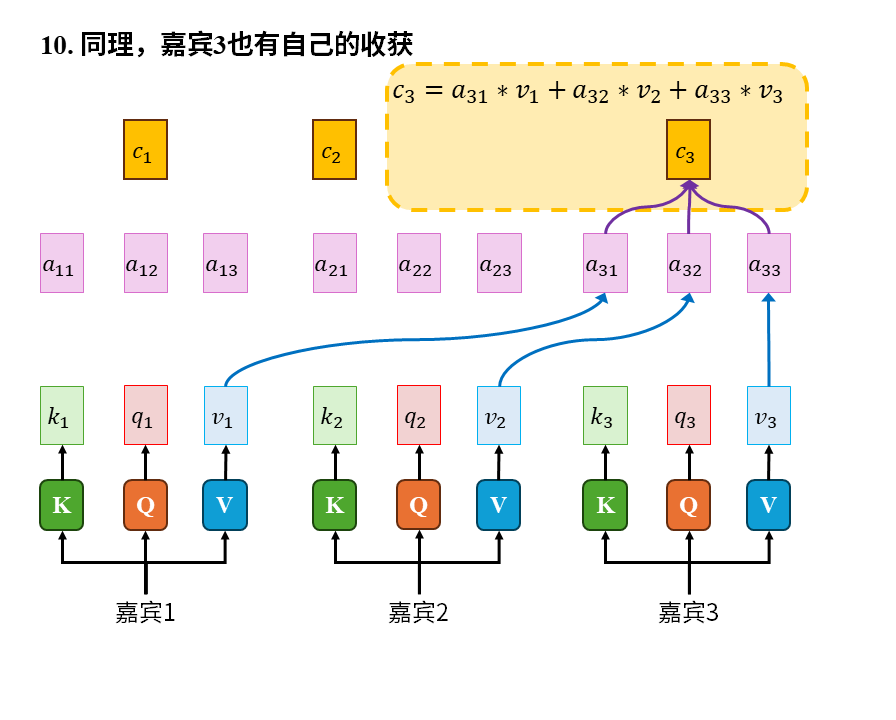
在这个故事中我们重点注意以下几点:
1)注意力是嘉宾带着自己的问题(q)在查看所有人的关键词(k)后才产生的。这其中的所有人也包括嘉宾自己。
2)被识破包装伎俩后的信息(v)才是真正有价值的东西。关键词只能吸引注意力,大家关心的是去伪存真后的真实信息(v)
3)嘉宾的收获(c)是自己的注意力(a)对所有嘉宾实际价值的加权平均。这其中也包括嘉宾自己
到此,我们对注意力机制的理解其实已经大差不差了,接下来快速介绍两个数学运算,为从技术层面理解注意力机制做铺垫。
第3步,快速理解矩阵乘法和向量内积两个数学运算。
1)矩阵乘法就是说两个矩阵相乘可以得到一个新的矩阵。比如:
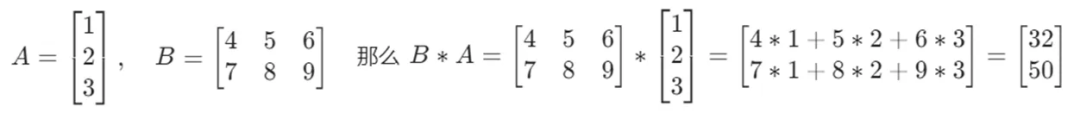
2)向量内积就是说两个向量的元素相乘再相加后可以得到一个数。比如:

第4步,从技术层面理解注意力机制。我们还是用“这老板真水”为例,并且假设1个汉字就算一个token。

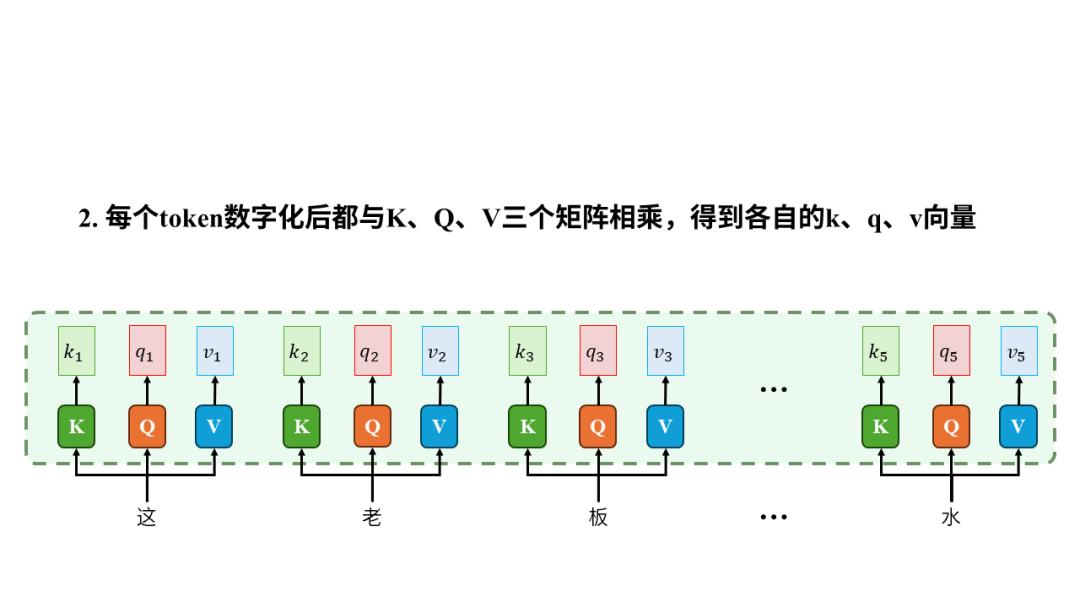
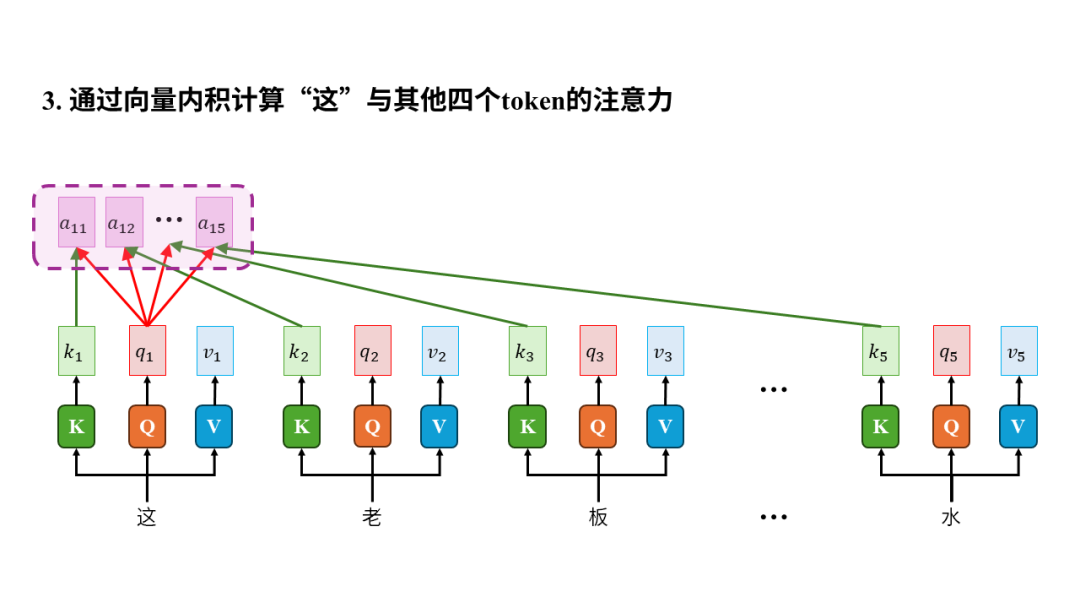
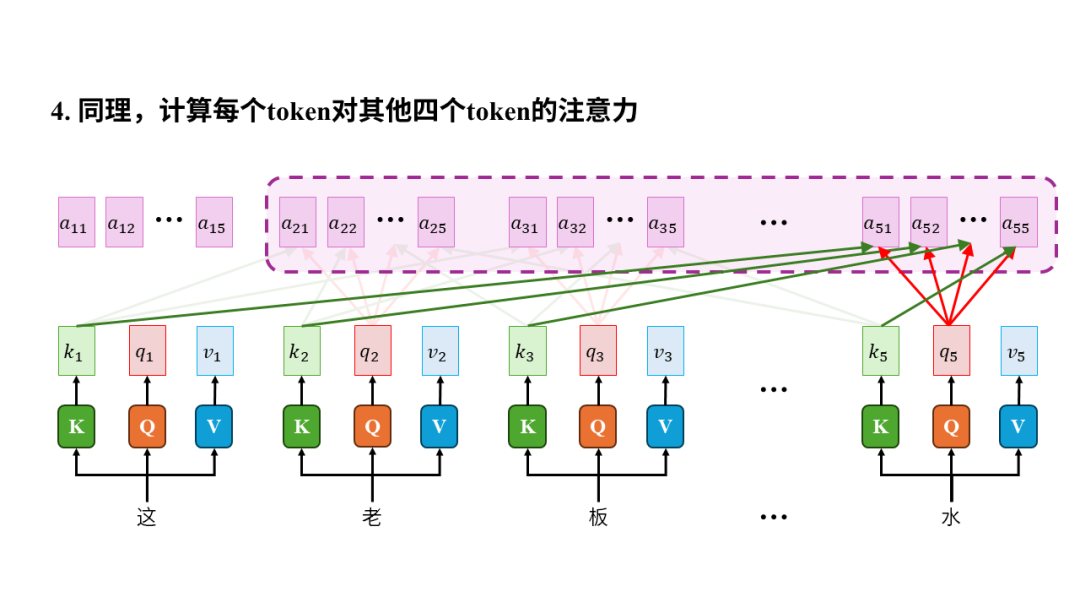
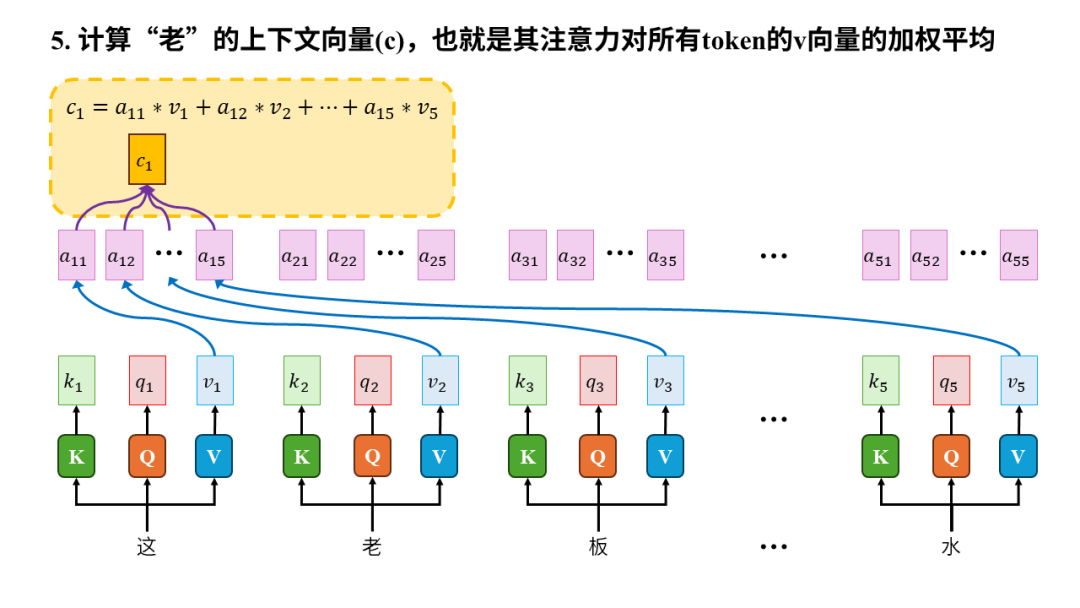
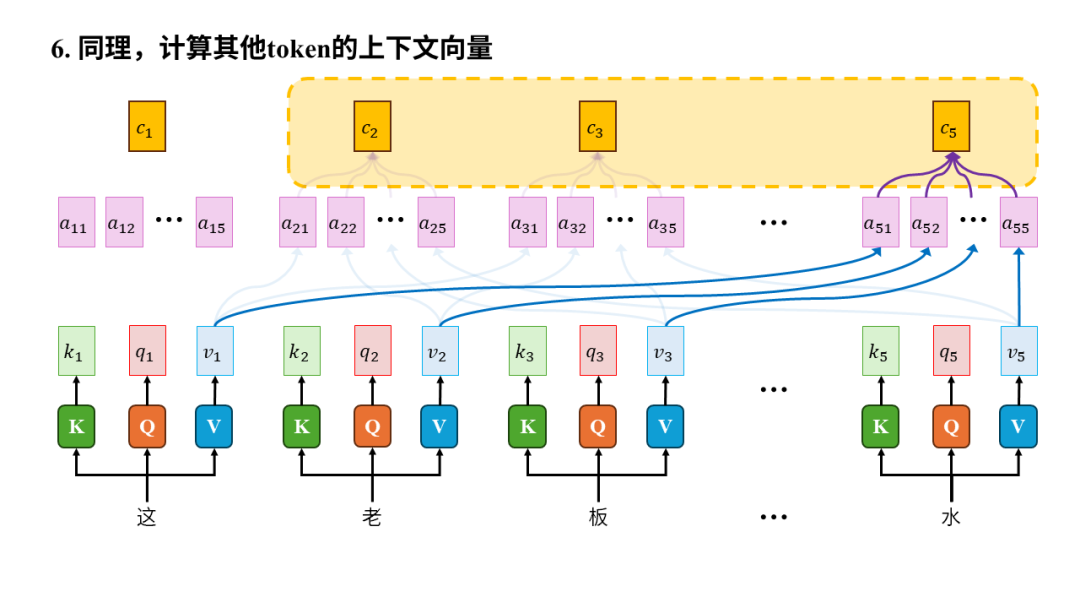
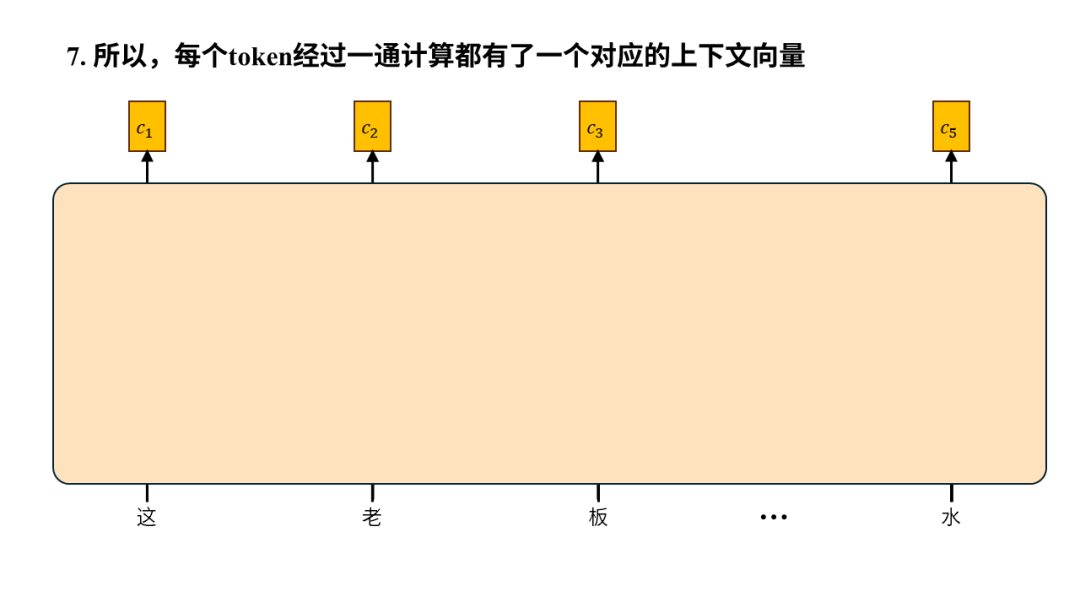
所以从输入输出的角度来看,注意力机制的输入是一个序列,输出是序列中每个元素生成的上下文向量(context vector)。之所以叫“上下文向量”是因为生成过程中计算了元素之间的注意力,以此将其他元素(也就是上下文)有权重的融入到当前元素最终生成的向量中,所以叫上下文向量。
注意力的计算与元素的距离无关,模型从此不健忘。无论两个元素相隔多远,我们都可以很方便的用一个元素的k向量和另一个元素的q向量做向量内积,进而计算注意力,完全不会受到两个元素距离的影响,这使得模型能够有效的捕捉长距离的信息,再也不会健忘。
注意力可以并行计算,模型训练速度从此飞升。虽然上图中我们是依次计算token注意力,但其实只要每个token的k、q、v向量都算好后,计算两个token间的注意力完全不依赖其他任何计算,所以可以同时计算所有元素对所有其他元素的注意力,也就是并行计算。
因此,只要元素间注意力计算得足够准确,我们就能实现“水”的上下文向量会比较多的融入“老板”,从而让机器正确的理解这句话中的“水”到底是何含义。
那怎样才能保证注意力计算足够准确呢?问得好~!
K、Q、V三个矩阵决定了注意力计算是否准确,是需要通过数据训练的参数。在上述过程中,最终生成的上下文向量是算出来的,元素间的注意力是算出来的,每个token的k向量(也被称作key)、q向量(也被称作query)、v向量(也被称作value)也是通过 K、Q、V矩阵和token相乘算出来的。因此决定整个注意力机制效果的根基在于K、Q、V三个矩阵的参数,这些正是模型需要通过大量数据来不断调整的地方。
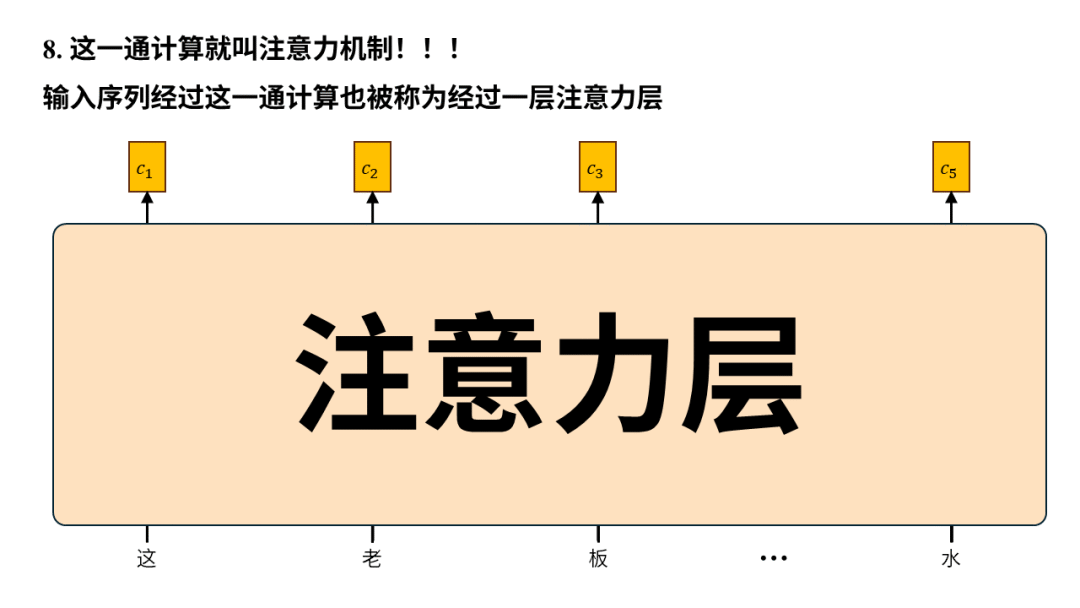
这,就是Transformer
文章开篇指出 Transformer 为解决翻译问题采用编码器 – 解码器架构,使用这个架构并不稀奇,稀奇的是Transformer 用纯注意力机制来构建编码器-解码器,我们一起来看下:
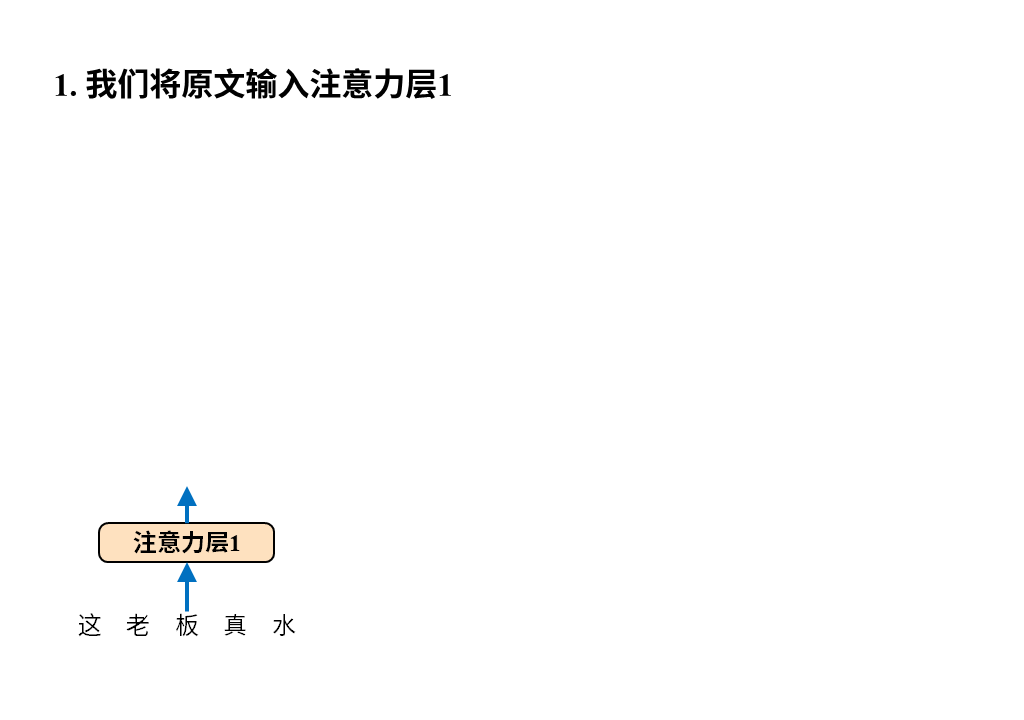
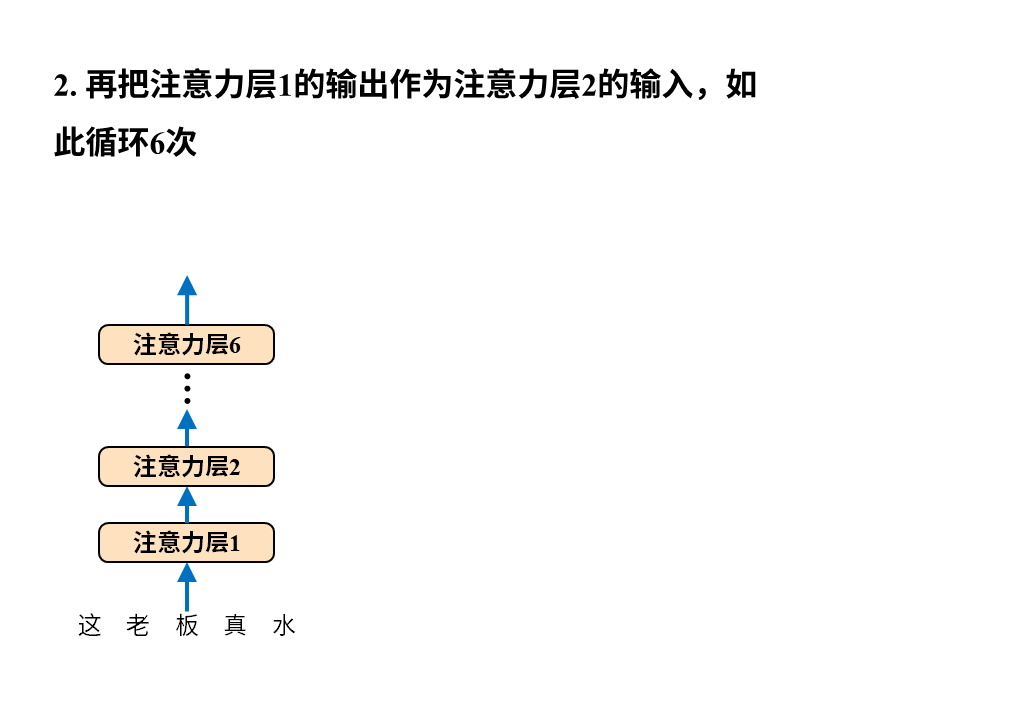
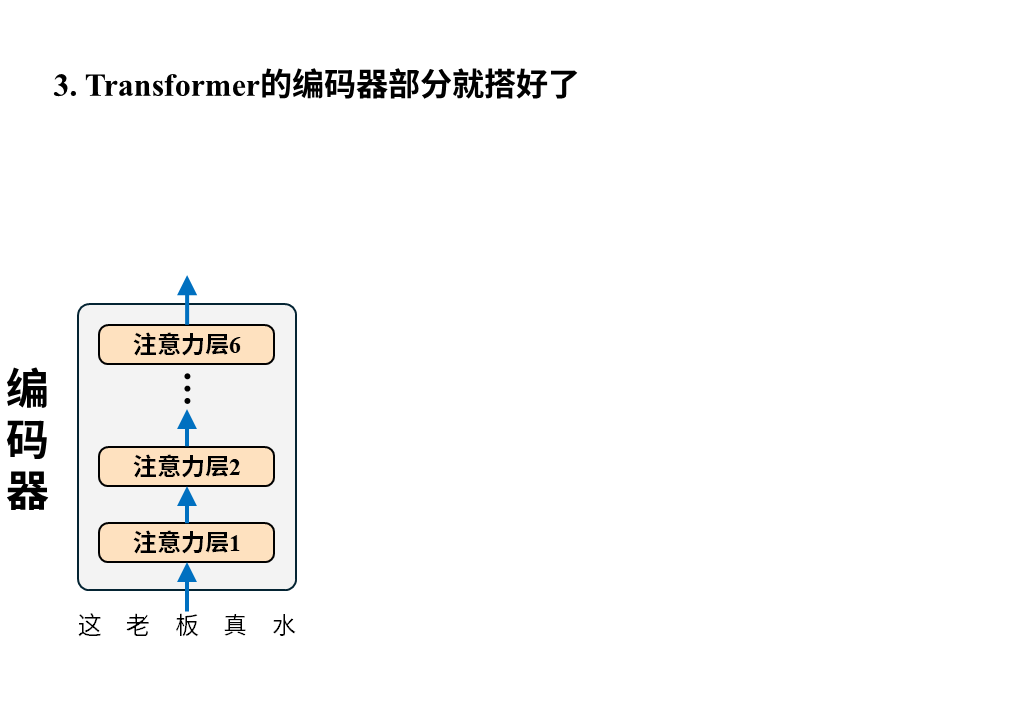
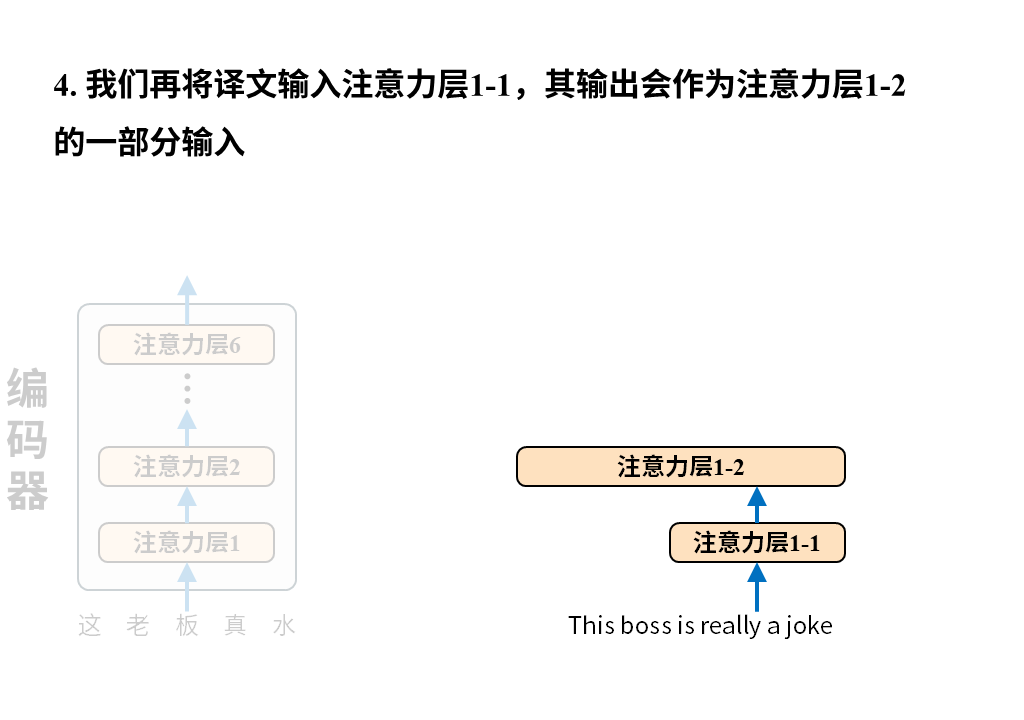
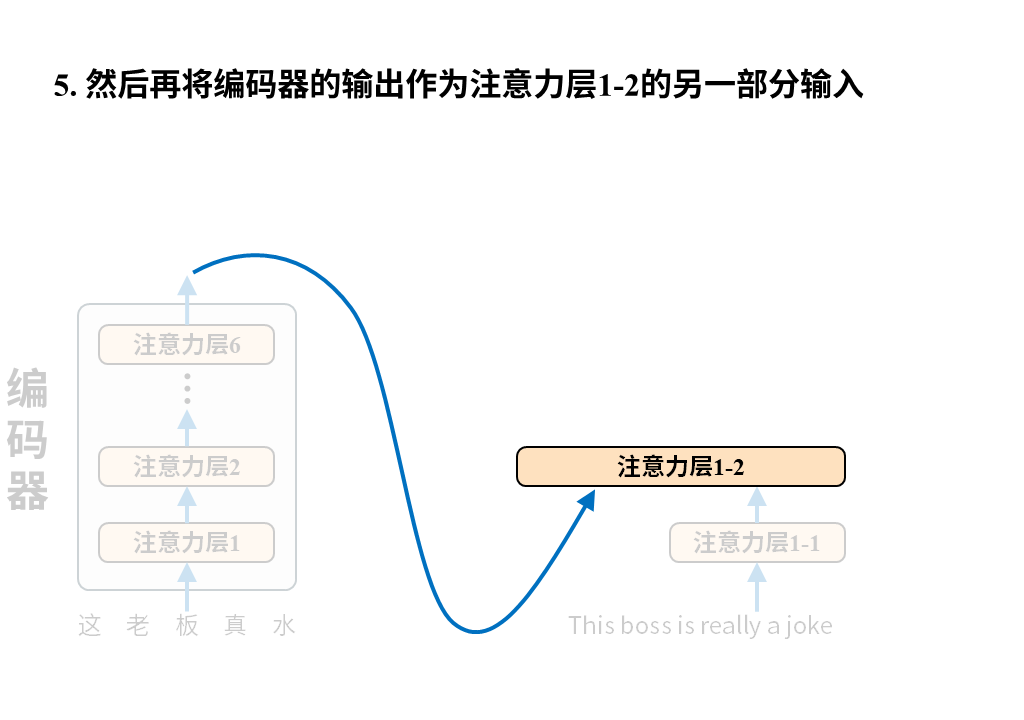
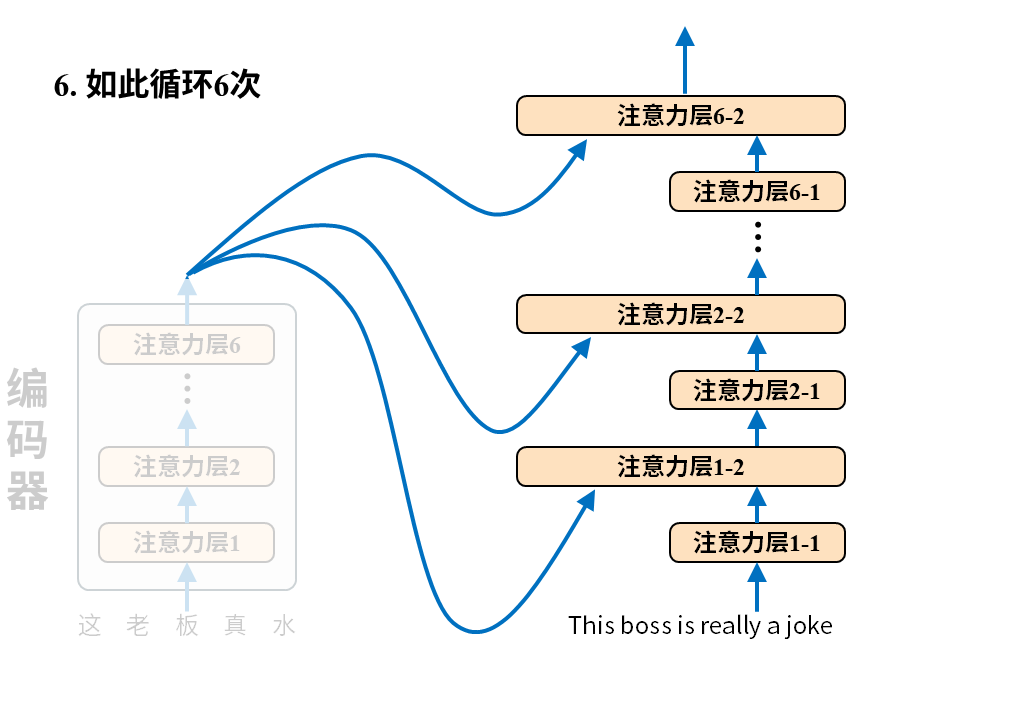
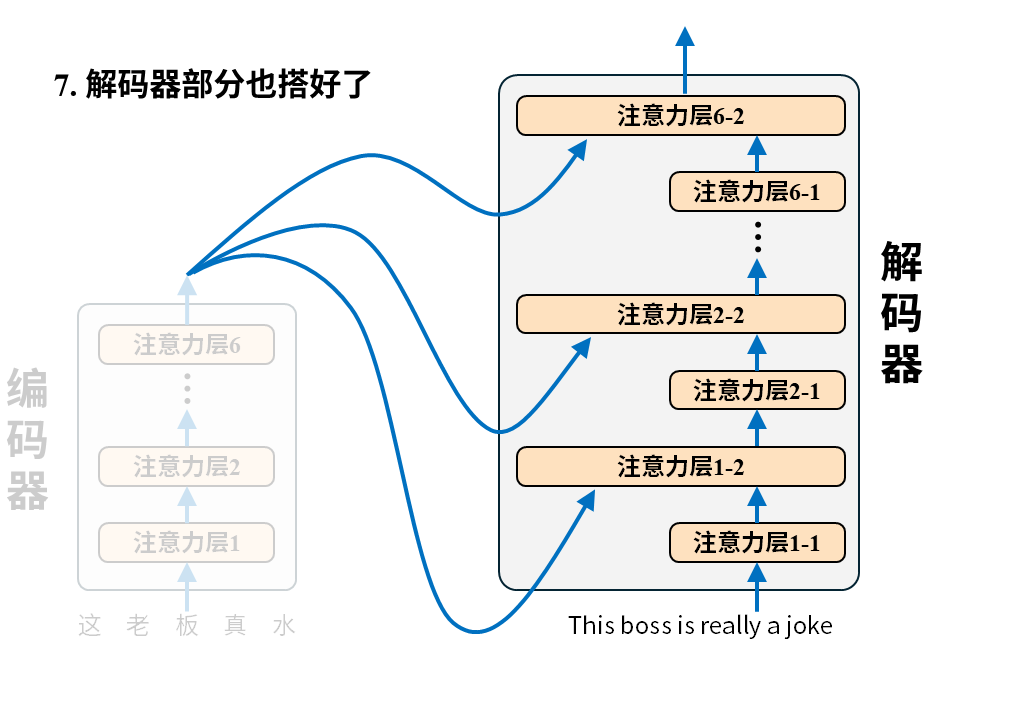
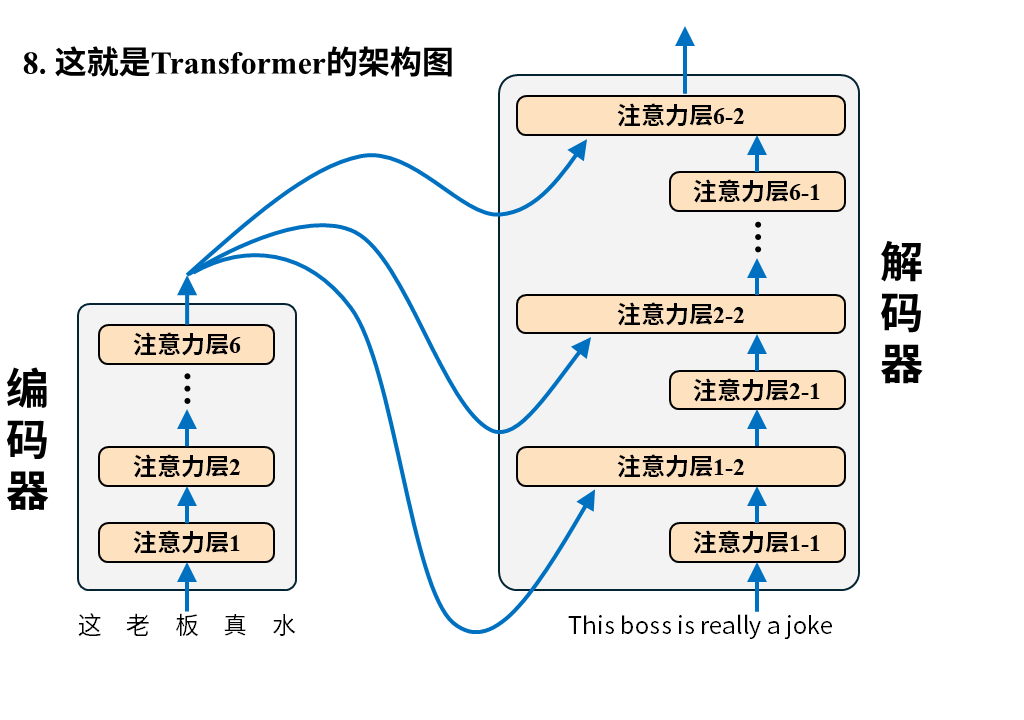
需要注意的是这张图只画出了Transformer中的注意力层,因为它最大的创新之处正是以注意力层为核心构建编码器-解码器(所以论文叫attention isALLyou need),但真正的Transformer还有诸如位置编码、归一化、残差连接、前向反馈等其他层。
我们还是从输入输出的角度来理解一下编码器-解码器。
编码器很好理解,输入就是待翻译的原文,字词间的关系经过6层注意力层后被机器彻底理解并最终输出成一堆数字,这堆数字接下来被送往解码器。
解码器的输入是译文,它会先经过一层注意力层,然后和编码器送来的原文编码结果一起再经过一层注意力层,如此循环6次最终得到输出token的概率分布,就像下面这样。
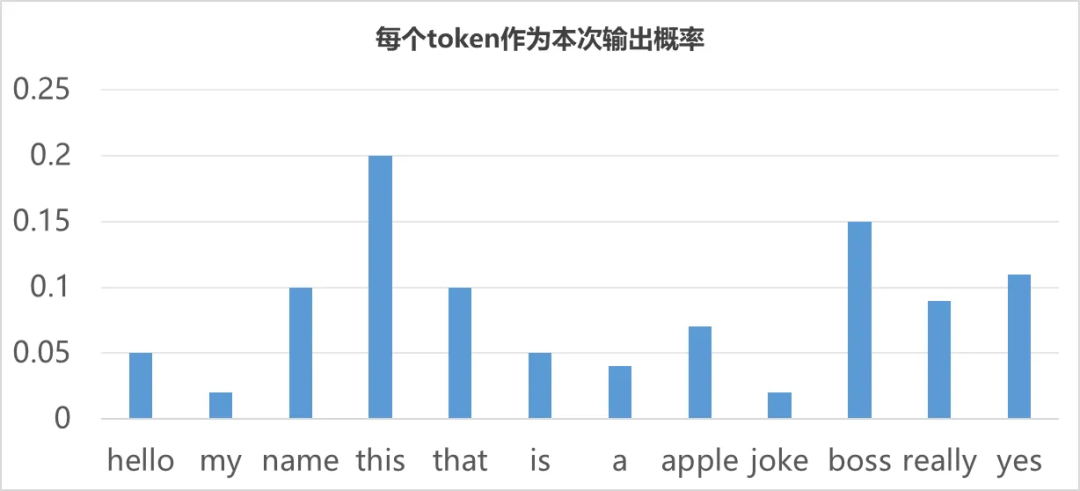
所谓输出token的概率分布简单来说就是模型觉得每个词都有一定概率被输出,只不过概率有大有小。(关于输出token的概率分布在《从0构建大模型知识体系(3):大模型的祖宗RNN》中的《来,让我们给AI开记忆》有详细介绍)
从这张图来看,模型认为“this”最有可能成为输出,所以如果我们的token采样策略是输出最大概率token的话,那模型就会输出“this”
等下,好像屏幕前有人在问:“你不是说Transformer是用来做翻译的吗?然后你又说这里还需要把译文喂给解码器,也就是说Transformer得在有译文的情况下才能翻译?我都有译文了还翻译个啥?这是在搞笑吗?”
问~得~好!先快速回答一下,在训练阶段我们确实会把原文和译文都输入给Transformer来让它学会翻译,但在完成训练后真的用它来翻译时就只会给原文了。这就引出了我们接下来要讨论的内容:Transformer的训练数据怎么准备?怎么训练?训练后怎么使用?
训练前:准备训练数据
翻译嘛,那自然是准备一堆原文及其对应译文的语料即可。比如:

训练中:输入语料对调整参数
每一对语料都将用于调整模型参数,以第一个语料对(我爱你,I love you)为例:
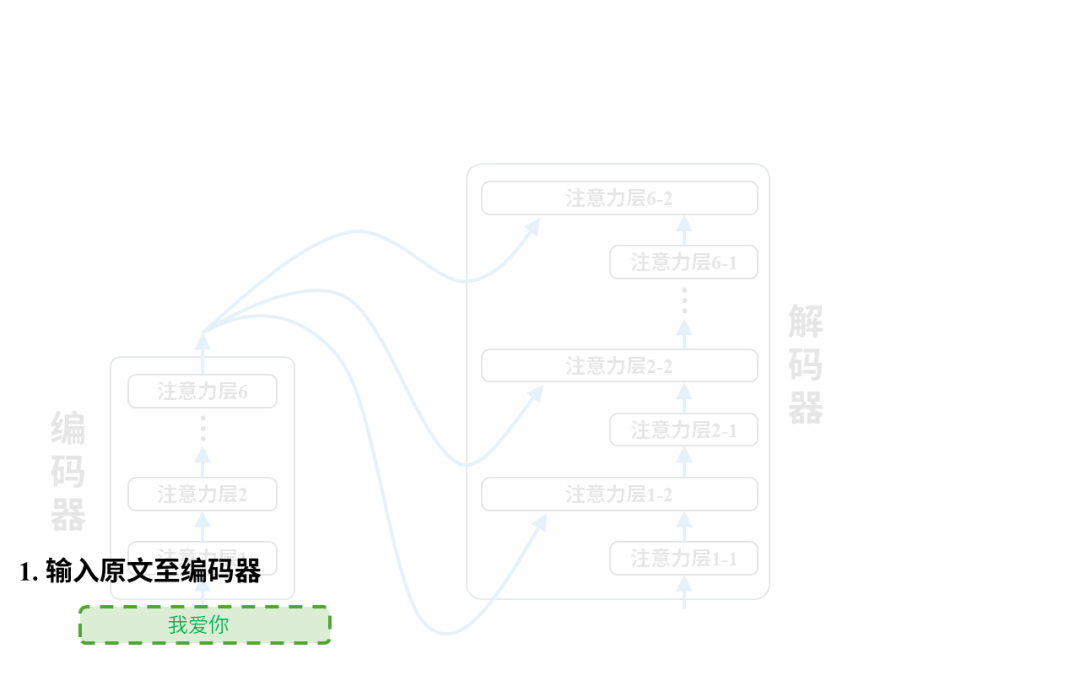
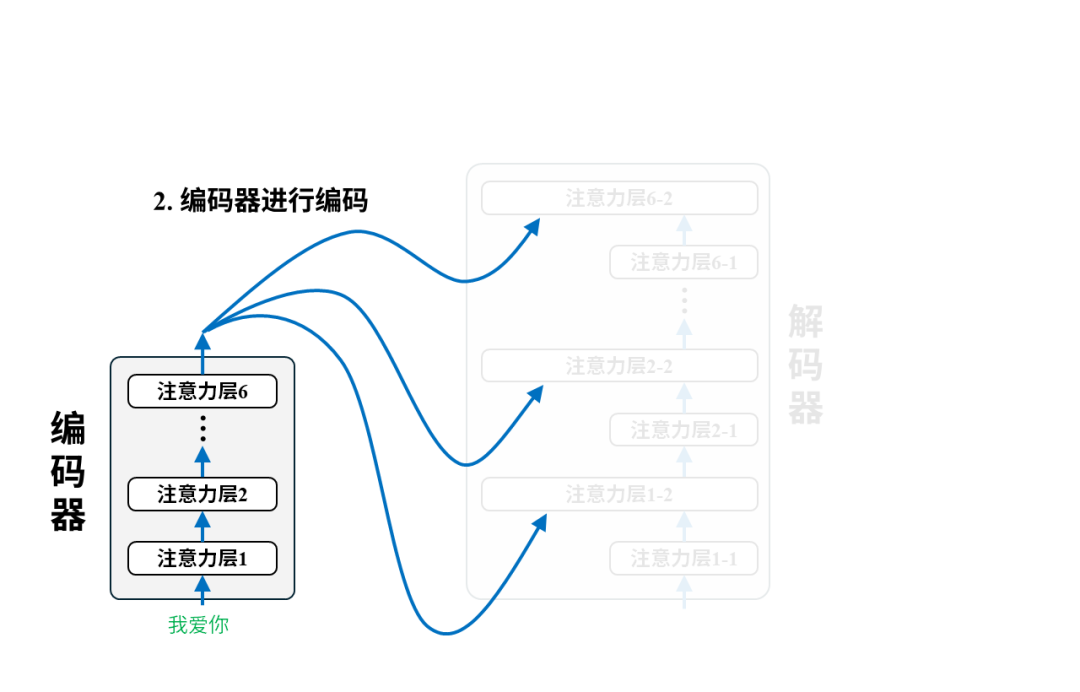
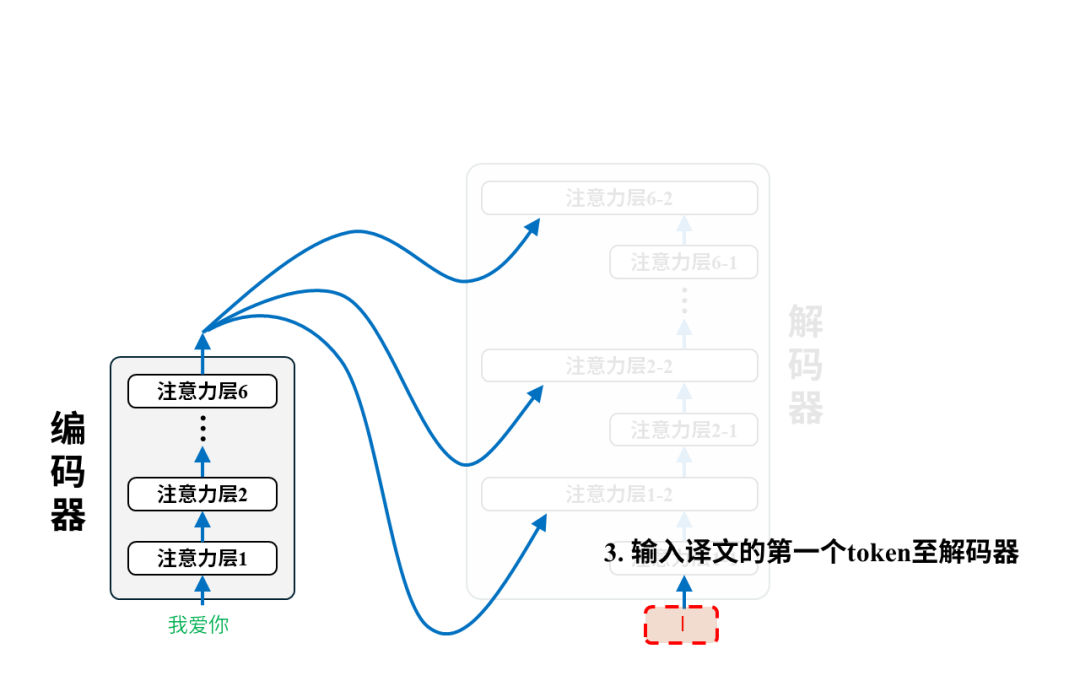
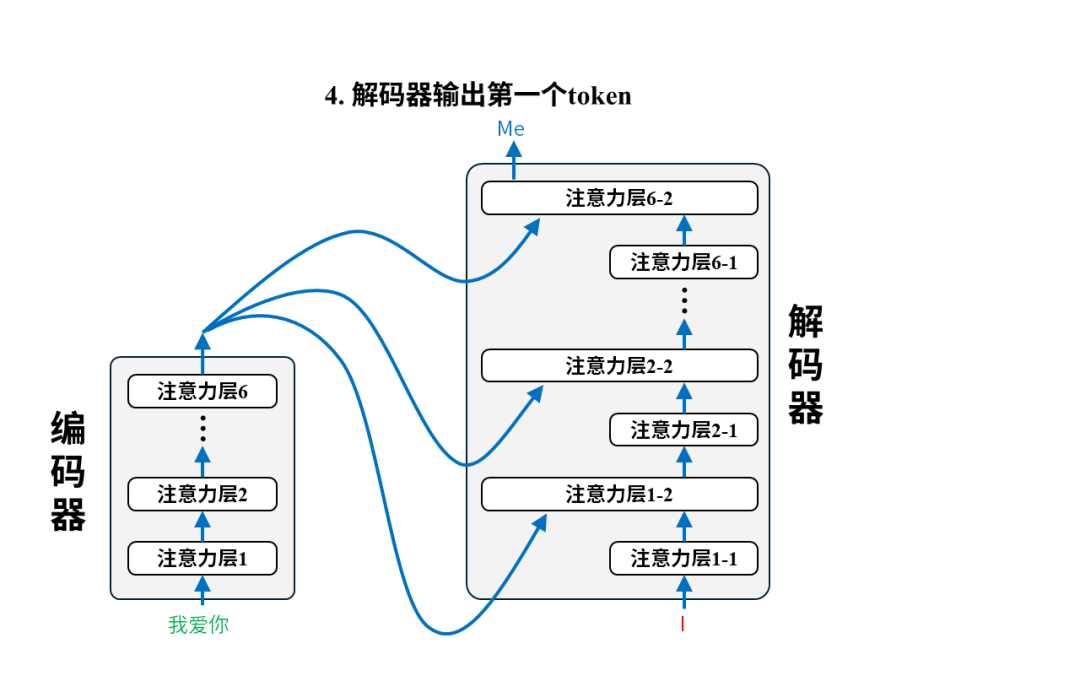
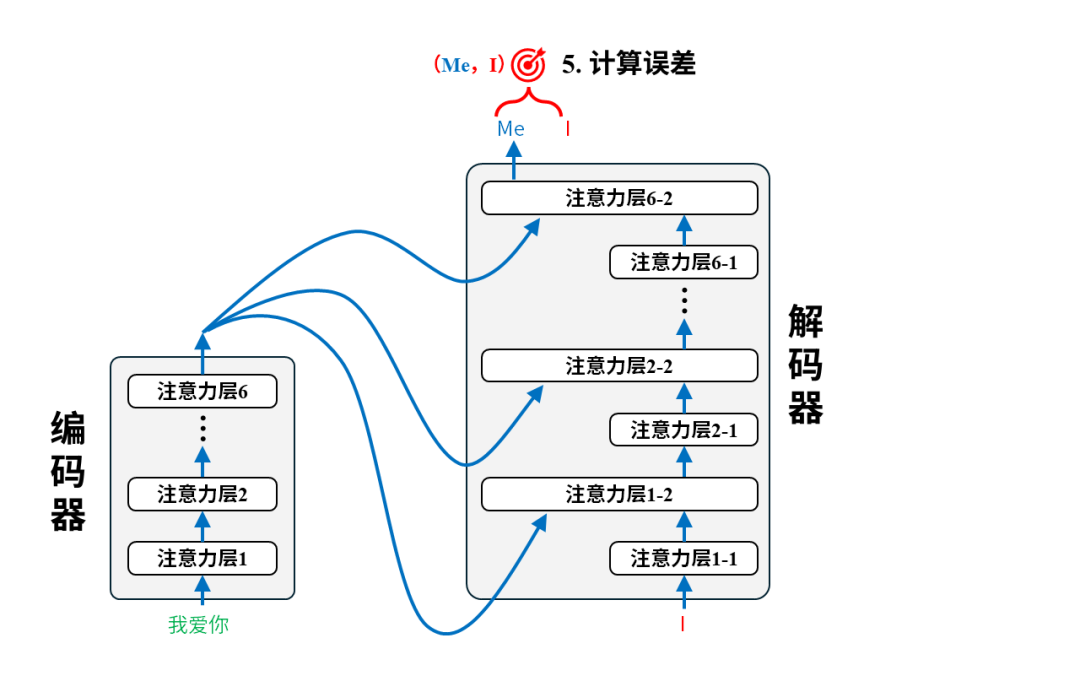
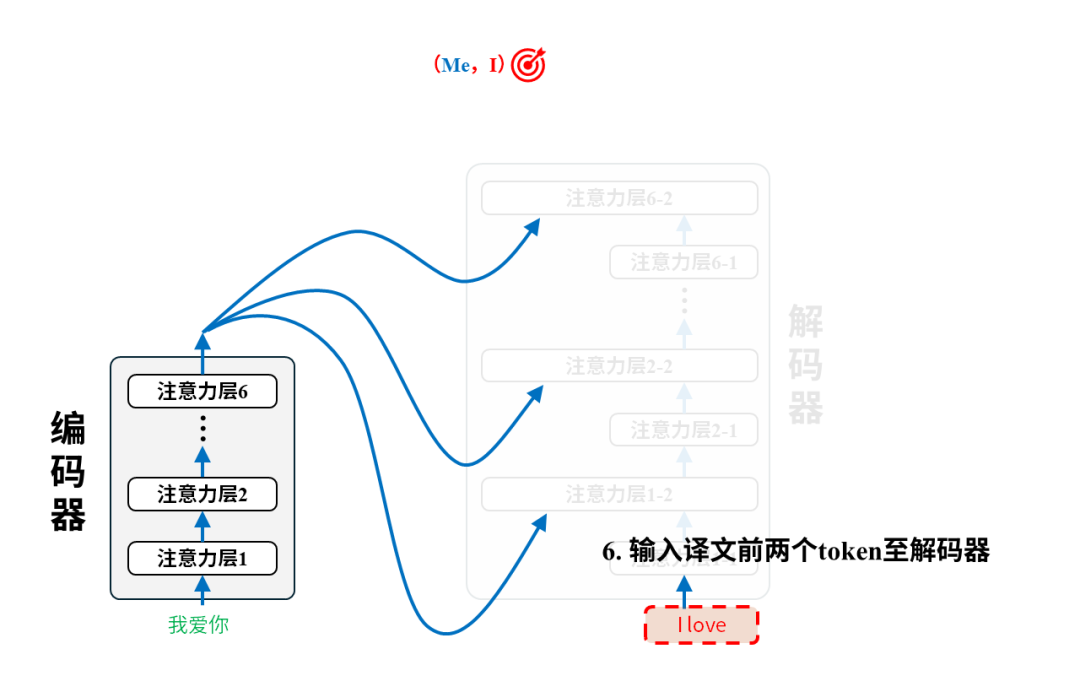
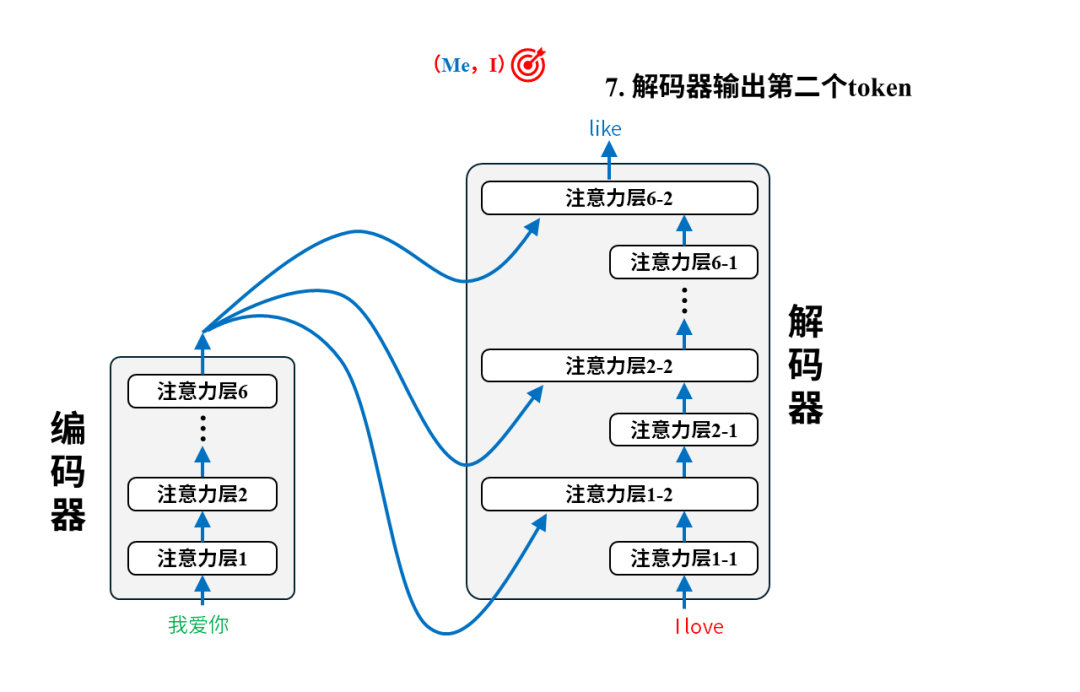
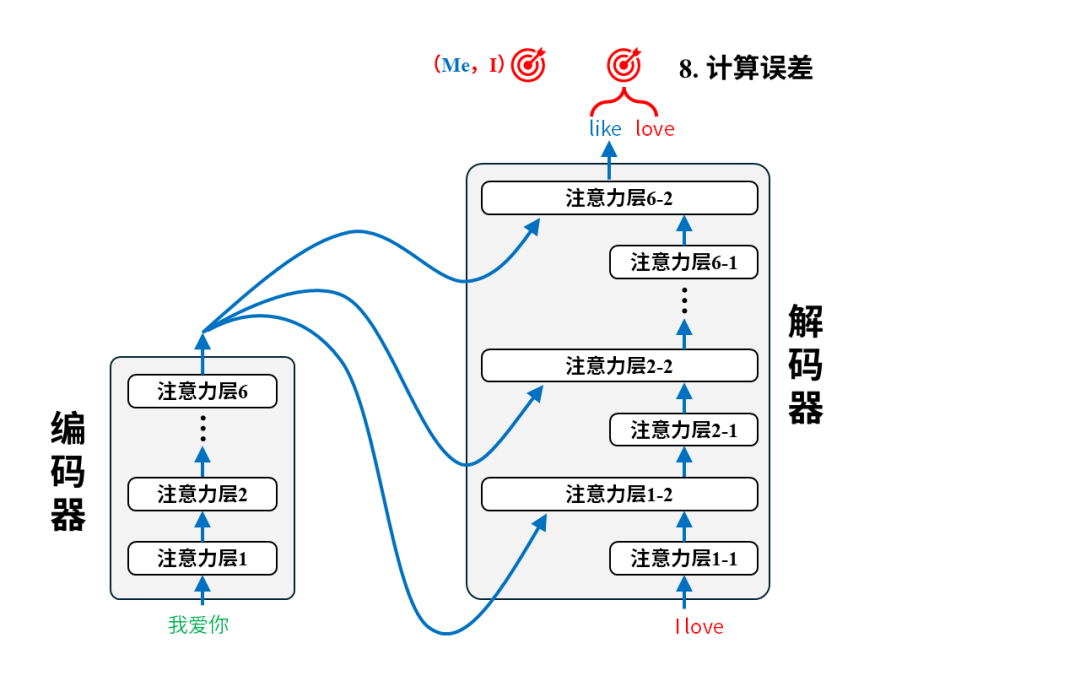
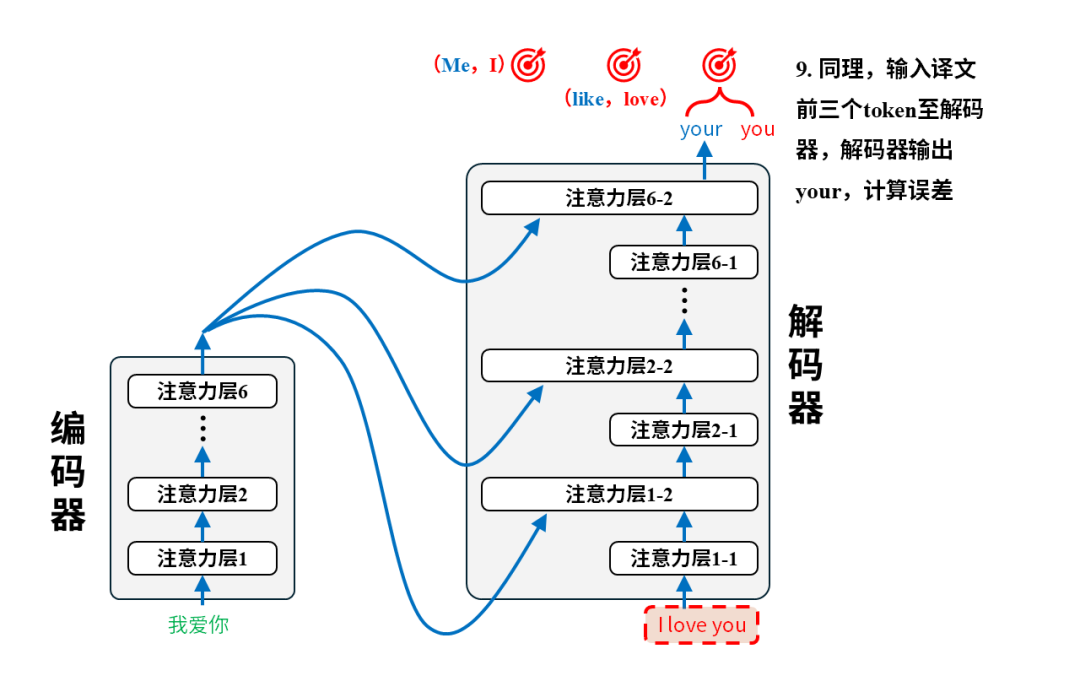
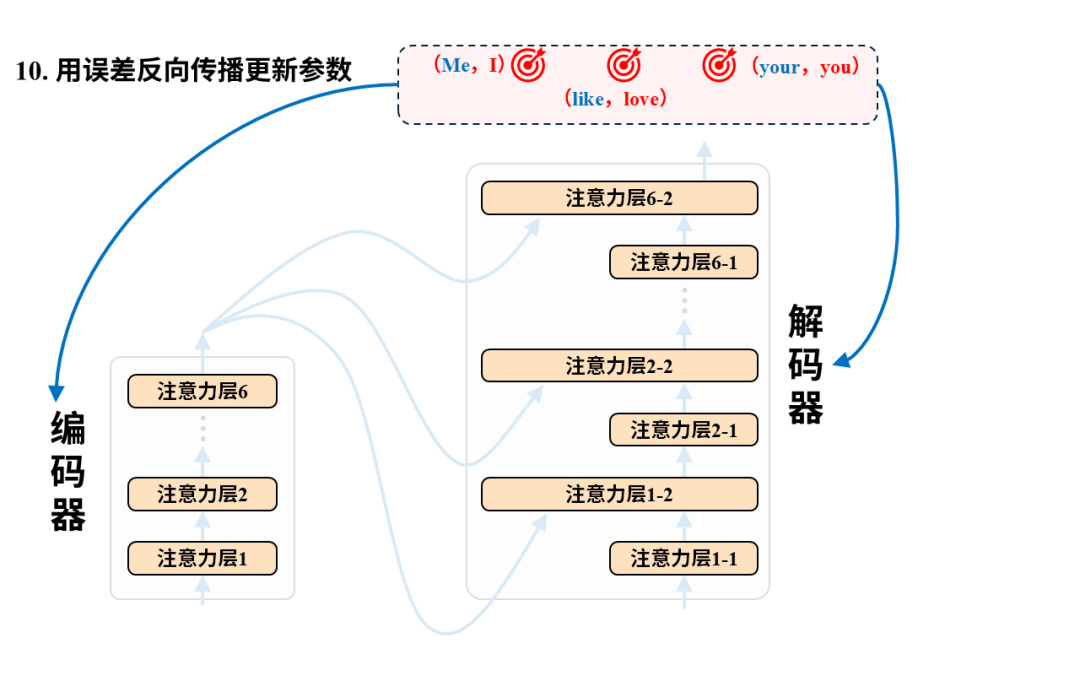
训练后:翻译
完成训练后的模型就可以投入使用进行翻译了。我们只需要把原文输入给编码器即可,以翻译“我爱你”为例,实际的翻译过程是这样的:
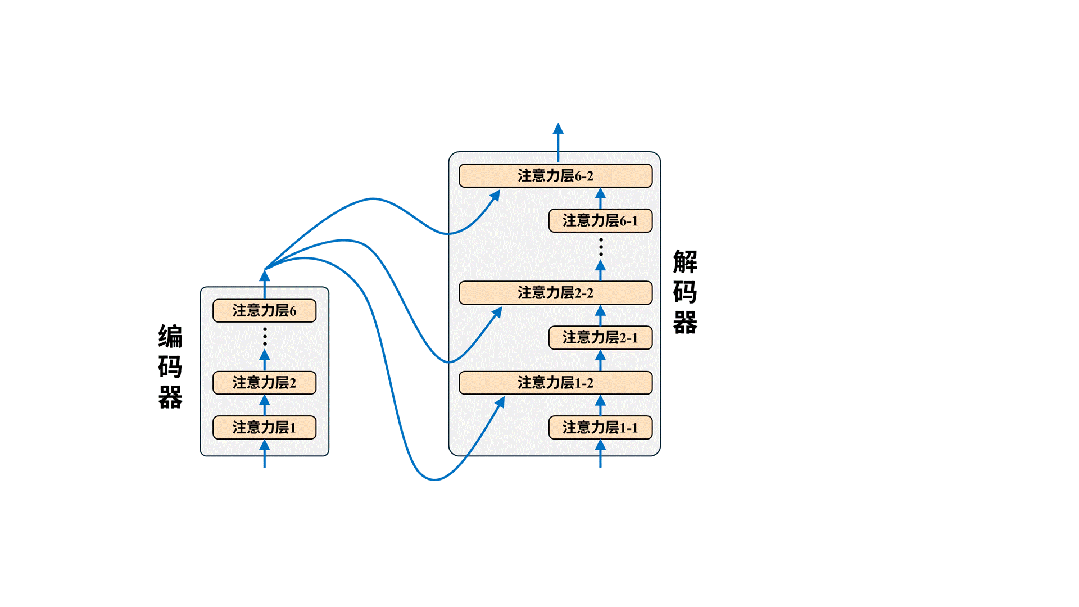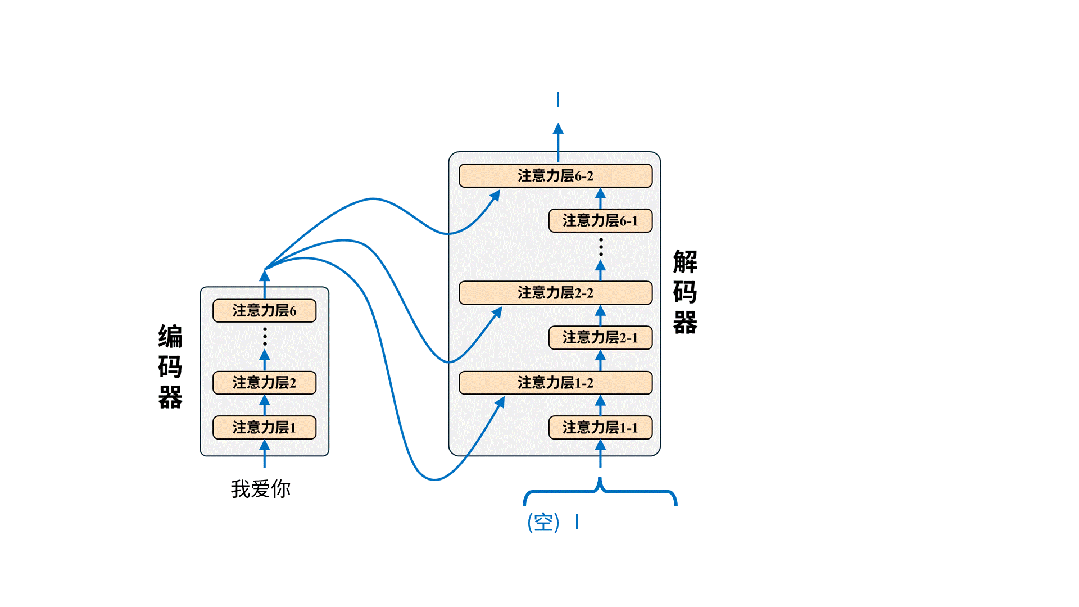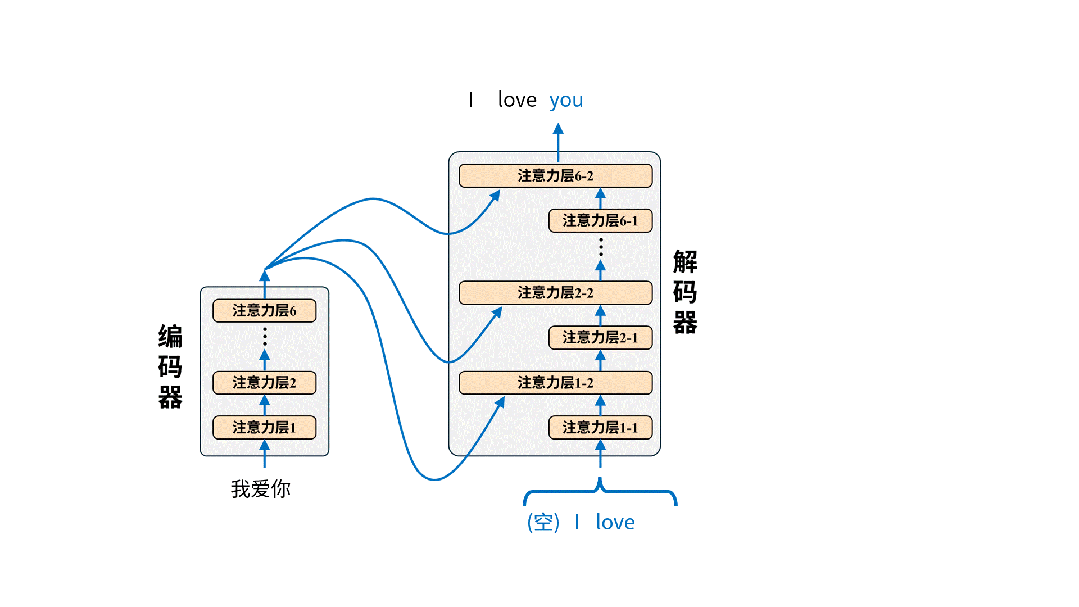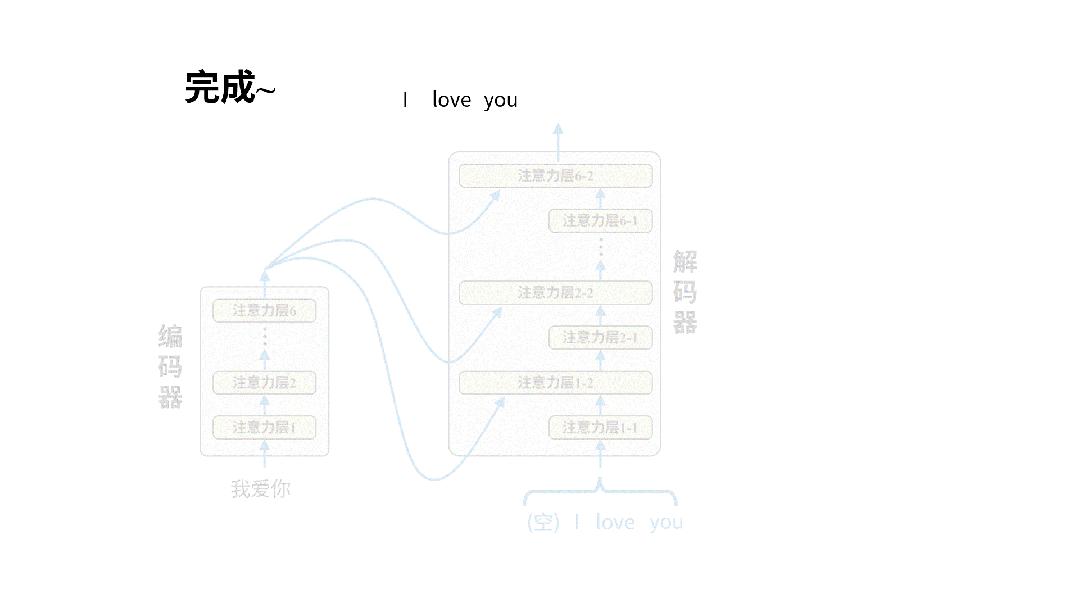
在实际翻译时,我们只将原文输入给编码器,解码器的输入为空。解码器每次输出的token都将被重新用作生成下一个token的输入。
好了,现在我们搭建的Transformer可以用来翻译了,下一个自然的问题是,我们怎么衡量它翻译得好坏呢?
评价翻译好坏的标准:BLEU
现在被广泛采用的评估指标叫做BLEU,Bilingual Evaluation Understudy,双语评估替补。BLEU的核心思想很简单:看机器翻译的结果跟人工翻译结果在“词语片段”上有多少重合度。举例如下:
- 原文:猫坐在垫子上
- 机器翻译结果:The cat is on the mat
- 人工翻译结果:The cat is sitting on the mat
我们先来看1个词(称作:1-gram)的重合度。需要先将机翻和人翻的结果一个词一个词的拆分开
- 机翻结果按单个词拆分:the, cat, is, on, the, mat
- 人翻结果按单个词拆分:the, cat, is, sitting, on, the, mat
然后我们一个个的看机翻拆分结果是否在人翻拆分结果中。即:“the”在人翻的拆分结果中吗?在;“cat”在人翻的拆分结果中吗?在;“is”在吗?在……机翻拆分后的6个词都在,那么1-gram精度为6/6
然后再来看2个词(称作:2-gram)的重合度。需要先将机翻和人翻的结果两个词两个词的拆分开
- 机翻结果按两个词拆分:the cat, cat is, is on, on the, the mat
- 人翻结果按两个词拆分:the cat, cat is, is sitting, sitting on, on the, the mat
然后我们一个个的看机翻拆分结果是否在人翻拆分结果中。即:“the cat”在人翻的拆分结果中吗?在;“cat is”在人翻的拆分结果中吗?在;“is on”在吗?不在……机翻拆分后的5个结果中有4个在,那么2-gram精度为4/5
然后再来看3个词(称作:3-gram)的重合度。需要先将机翻和人翻的结果三个词三个词的拆分开
- 机翻结果按三个词拆分:the cat is, cat is on, is on the, on the mat
- 人翻结果按三个词拆分:the cat is, cat is sitting, is sitting on, sitting on the, on the mat
这回机翻的4个拆分结果中只有“the cat is”和“on the mat”在人翻拆分结果中,所以3-gram进度为2/4
一般来说还会再看4-gram的进度,这里就不做演示了。
得到了1-gram到4-gram的精度后会对4种情况下的精确度进行加权,具体计算公式如下,咱感受一下就行
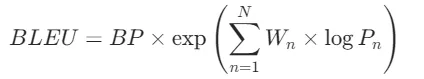
其中:
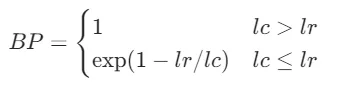
- lc表示机器翻译结果的长度
- lr表示人工翻译结果的长度
- Wn是n-gram的权重,一般都设置为等权重
- Pn就是我们刚刚说的1-gram、2-gram等等各种n-gram的精确度
这套公式会给出一个0到1之间的分数(不过通常会乘以100表示为0-100以符合百分制的习惯)。分数越高,说明机器翻译和人工翻译越接近,质量可能越好。当然,BLEU只是一个机械性的评估,它并未考虑语义,所以有时高分翻译不一定通顺自然,低分翻译也可能有可取之处。但它提供了一个快速、量化的参考标准,在模型开发迭代中非常常用。
Transformer最后在 WMT 2014 英德翻译任务上达到了 28.4 的 BLEU 分数,比当时的行业最佳高 2 分以上。在 8 个 GPU 上训练 3.5 天后,在 WMT 2014 英法翻译任务上达到了 41.8 的单模型最高 BLEU 纪录。
Transformer的后裔:BERT与GPT
Transformer 本身是一个强大的架构,它的强大在于以注意力机制为核心构建的编码器、解码器能让模型高效理解外界输入,并向外界输出。
之后研究者们发现,Transformer的编码器如果单独拿出来优化优化,模型就不只是能理解待译原文字词间的关系这么简单了,于是有了BERT。
研究者们还发现,Transformer的解码器如果单独拿出来再优化优化,模型就不只是能做翻译这么简单了,于是有了GPT(没错,就是那个大名鼎鼎的chatGPT的GPT)。
所以下一篇文章我们将详细讨论BERT与GPT。
复盘一下,我们学到了什么
RNN的两大瓶颈在于健忘和训练速度慢。这两个问题虽然被其改良版本(LSTM)显著缓解,但依旧没有被彻底解决。健忘是因为序列一长将导致反向传播无法有效调整参数,训练速度慢是因为RNN有许多串行计算,因而无法大规模的通过GPU并行训练。
彻底解决RNN两大瓶颈的模型是Transformer。Transformer在处理序列时会直接计算某个元素和其他所有元素的注意力,无论两个元素相隔有多远,因此彻底解决了健忘问题。此外, 一个序列所有元素的注意力计算可以同时进行,这使得其可以在GPU上并行训练。
输入和输出都是序列的任务就被称为“序列到序列任务”,解决这一问题的经典架构是编码器-解码器。编码器负责把输入序列转化为机器能理解的数字,解码器再负责把它转化为人类能理解的形式。Transformer采用的就是编码器-解码器架构。
注意力机制能让模型理解序列元素之间的关系。所谓注意力即是序列元素之间的相关性,“这老板真水”中“水”和“老板”的相关性显然就要比别的词强,注意力机制能让模型理解这种相关性。
K、Q、V三个矩阵是注意力机制中需要训练的参数。计算注意力需要对数字化后的token分别乘以K、Q、V矩阵得到k向量(key)、q向量(query)和v向量(value),然后通过计算key和query的内积得到注意力。K、Q、V矩阵的具体数值需要通过大规模数据来调整。 值得一提的是,DeepSeek 实现低成本的一个技术——“KV缓存”说的就是这里的 K 矩阵和 V 矩阵。这一点我们先按下不表,之后讲DeepSeek的时候再展开。
评价翻译质量的指标是BLEU。BLEU的核心思想是看机器翻译的结果跟人工翻译结果在“词语片段”上有多少重合度,然后对重合度进行加权平均,最终输出一个0~1的数,越靠近1说明翻译效果越好。实际中往往会再乘以100以符合百分制的习惯。Transformer在公认较难的英德翻译问题上的BLEU得分为28.4,比同时期的行业最佳高2分。
Transformer的编码器和解码器分别发展出了BERT和GPT。所以说Transformer是大模型的爸爸
欢迎来到2017
Transformer的提出源自2017年谷歌研究团队发表的论文Attention Is All You Need。
到此,恭喜你对大模型知识的理解来到了2017年。此时幻方量化开始全面应用深度学习技术进行交易,距离DeepSeek-R1发布还有5年。
AI Heroes

左:Attention Is All You Need的 8 位作者;右:论文中的Transformer架构图
这篇开创性的论文由来自Google Brain和Google Research的Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Łukasz Kaiser, Illia Polosukhin共同完成。论文中特意提到所有人对论文的贡献均等,排名不分先后
离开谷歌后的创业者。八位作者陆续离开谷歌后,全都成为 AI 领域的创业者。
- Ashish Vaswani 和 Niki Parmar:先后创立 Adept AI和 Essential AI,后者获 Thrive Capital 800 万美元投资。
- Noam Shazeer:创立 Character.AI,开发能模拟名人对话的 AI 角色,用户量超 2000 万,估值 10 亿美元。之后重回Google任Gemini联合负责人。
- Jakob Uszkoreit:跨界生物科技,创立 Inceptive,用 Transformer 设计 RNA 药物。
- Llion Jones:创办Sakana AI,专注于开发受自然启发的基础模型,利用进化算法和多智能体协作优化生成式 AI。
- Aidan Gomez:创办 Cohere,专注于企业级 NLP 模型,估值 22 亿美元,客户包括 Salesforce 和 Oracle。
- Łukasz Kaiser:加入 OpenAI。
- Illia Polosukhin:转向区块链,创立 NEAR Protocol,试图用 AI 优化去中心化应用。
—“Attention is all you need”
—“Indeed, it’s all we need”
——后记
如果有帮助,还望点个赞,谢谢~
本文由 @夜雨思晗 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图由作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务

















请问c1如果是向量内积的话为什么会是一个向量?不应该是一个数值吗
有学习到
有帮助就好嘿嘿~