
 起点课堂会员权益
起点课堂会员权益
Qwen3来了,DeepSeek R2还会远吗?
 产品经理的核心价值是能够准确发现和满足用户需求,把用户需求转化为产品功能,并协调资源推动落地,创造商业价值
产品经理的核心价值是能够准确发现和满足用户需求,把用户需求转化为产品功能,并协调资源推动落地,创造商业价值阿里凌晨发布新一代通义千问模型Qwen3,作为全球首个开源的混合推理模型,性能强大且性价比高,支持多种语言和广泛应用场景。而面对Qwen3及百度文心4.5 Turbo的挑战,DeepSeek静默以对,却让外界更加期待其即将发布的R2模型,一场AI模型的激烈竞争即将展开。

阿里开源新一代通义千问模型 Qwen3。
这是全球第一个开源的混合推理模型。
什么叫混合推理模型?简单说就像把DeepSeek的V3与R1糅合在一起,不必手动开关闭推理模式,就能同时进行普通思考和长思考。
Qwen3模型能力号称登顶全球,体现在几个亮点上。
01 大而全
这次共发布八个模型:六个Dense稠密模型:Qwen3-0.6B、1.7B、4B、8B、14B、32B;两个MoE模型:Qwen3-30B-A3B、旗舰版的Qwen3-235B-A22B。
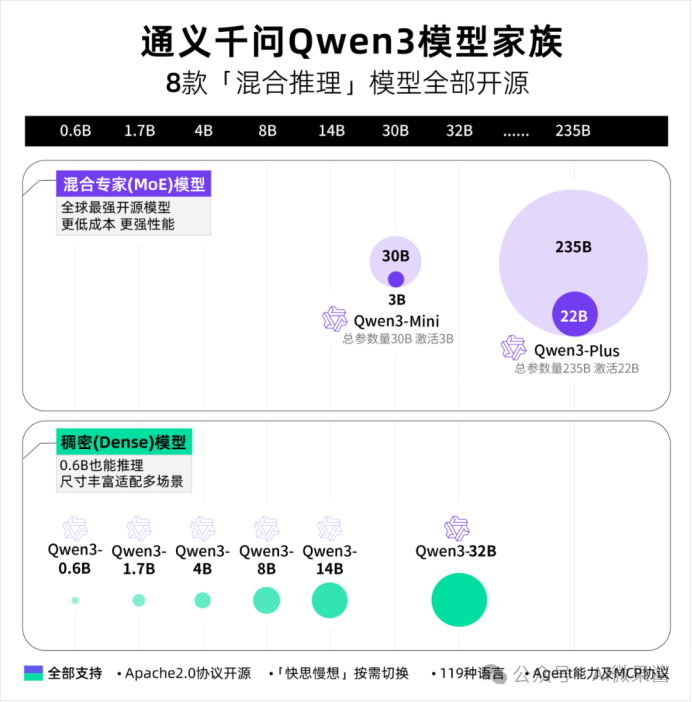
八个模型就像全家桶,小到0.6B,大到235B,满足全方位需求,无论个人日常使用或公司商用都没有任何限制。
02 顶级性能

Qwen3-4B的小模型能和之前的QwQ-32B不分伯仲;而Qwen3-30B-A3B对于QwQ-32B则是全方位的碾压。最强的旗舰版Qwen3-235B-A22B更是直接与世界顶级的OpenAI-o1、DeepSeek-R1对标。

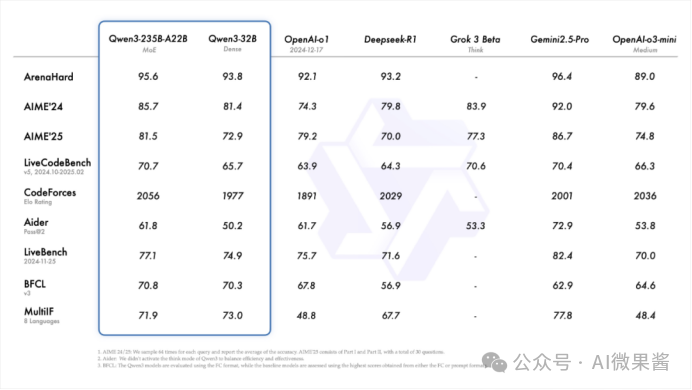
03 性价比高
更重要的是,便宜啊。旗舰版的Qwen3-235B-A22B部署成本只要DeepSeek-R1的三分之一。要知道,DeepSeek是以低成本撬开美国算力铁幕的,“卷”这个字,只有中国企业才能诠释得淋漓尽致。
04 更加开放
与国外的Claude3.7一样,千问3支持MCP协议,也是国内首个原生支持MCP的大模型。可以在Qwen3接入即梦、Gihub等工具,实现一模多用。
05 应用更广
相比上一代Qwen2.5支持29种语言,Qwen3支持多达119种语言,真正走向全世界了。
无论Qwen3,还是前段时间百度发布的文心4.5 Turbo,在性能和性价比上都宣称超过了DeepSeek-R1。不过,面对挑战,DeepSeek依旧静如处子。
沉默,往往是爆发前的状态,以DeepSeek过往开发经验,时候差不多了。
4月27日晚,全球最大AI开源社区Hugging Face的首席执行官,Clément Delangue在社交平台发布了一条耐人寻味的动态——三个眼睛的表情符号,同时附上DeepSeek团队在Hugging Face平台的官方资源库入口。
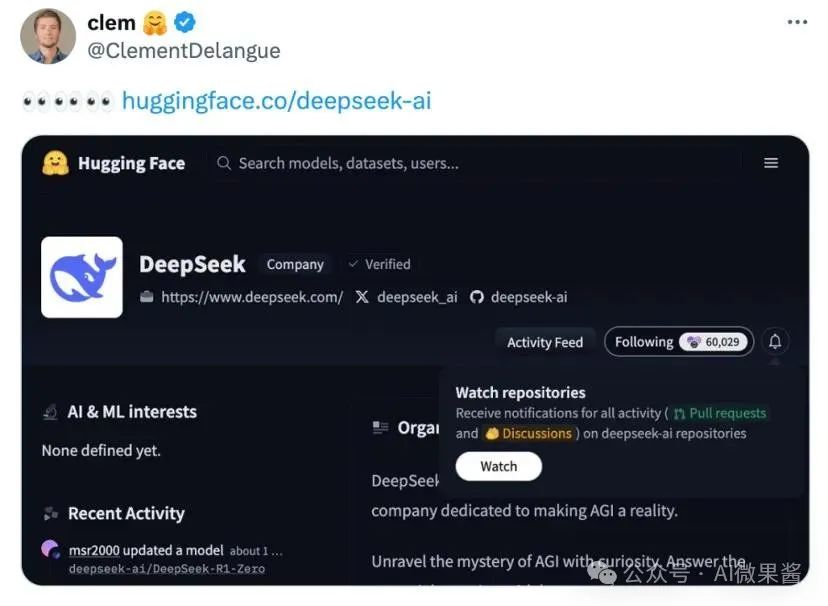
这则无声的寓言,是否预示着DeepSeek-R2进入了发布倒计时?
进而有网友贴出了所谓DeepSeek-R2大模型的详细技术参数。

1、拥有 1.2万亿参数,活跃参数为 780亿,采用混合 MoE架构。
2、成本比 GPT-4o便宜 97.3%(输入每百万次 0.07美元,输出每百万次 0.27美元)。
3、使用了 5.2PB的训练数据,在 C-Eval2.0测试中取得了 89.7%的得分。
4、视觉能力更强,在 COCO测试集上达到了 92.4%。
对于这些消息,DeepSeek尚未发表任何辟谣声明,不禁让人浮想联翩。
自从2月DeepSeek揭开AI时代大幕后,人工智能就进入以中美为逐鹿场,群雄并起的春秋时代,各路豪杰你方唱罢我登场。即将到来的5月,这场未来之争将进入更加激烈的阶段,DeepSeek R2无疑是那个最值得期待的主角。
雪莱说:冬天来了,春天还会远吗?
本文由人人都是产品经理作者【微果酱】,微信公众号:【AI微果酱】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!









