
 起点课堂会员权益
起点课堂会员权益吴恩达Agentic AI设计准则之Reflection
AI 不只是执行命令,它也能“反思”。吴恩达提出的 Agentic AI 准则之一——Reflection,正在重新定义智能体的成长方式。这篇文章带你快速了解它的设计理念与落地思路。

“AI 不是不会犯错,而是没人教它回头看看。”—— Andrew Ng
在 Andrew Ng 最新发布的《Agentic AI》课程里,Reflection(自我反思)是第一个被拿出来单讲的设计模式。它不是最炫的,却可能是最容易被忽视、却也最容易落地的 Agent 超能力。
1. 什么是 Reflection?
一句话:让模型把自己的输出再当作输入,重新审视一遍。就像你写完代码后,回头读一遍,发现:
- 变量名拼错了
- 逻辑有漏洞
- 边界条件没cover
人类靠“第二遍”提升质量,AI 也可以。
2. 一个最小可运行的 Reflection 例子
为了让更多非技术读者能理解,我们不用代码演示,而是用一个简单的 Dify Chatflow 演示如何设计 Reflection.

各个节点的作用:

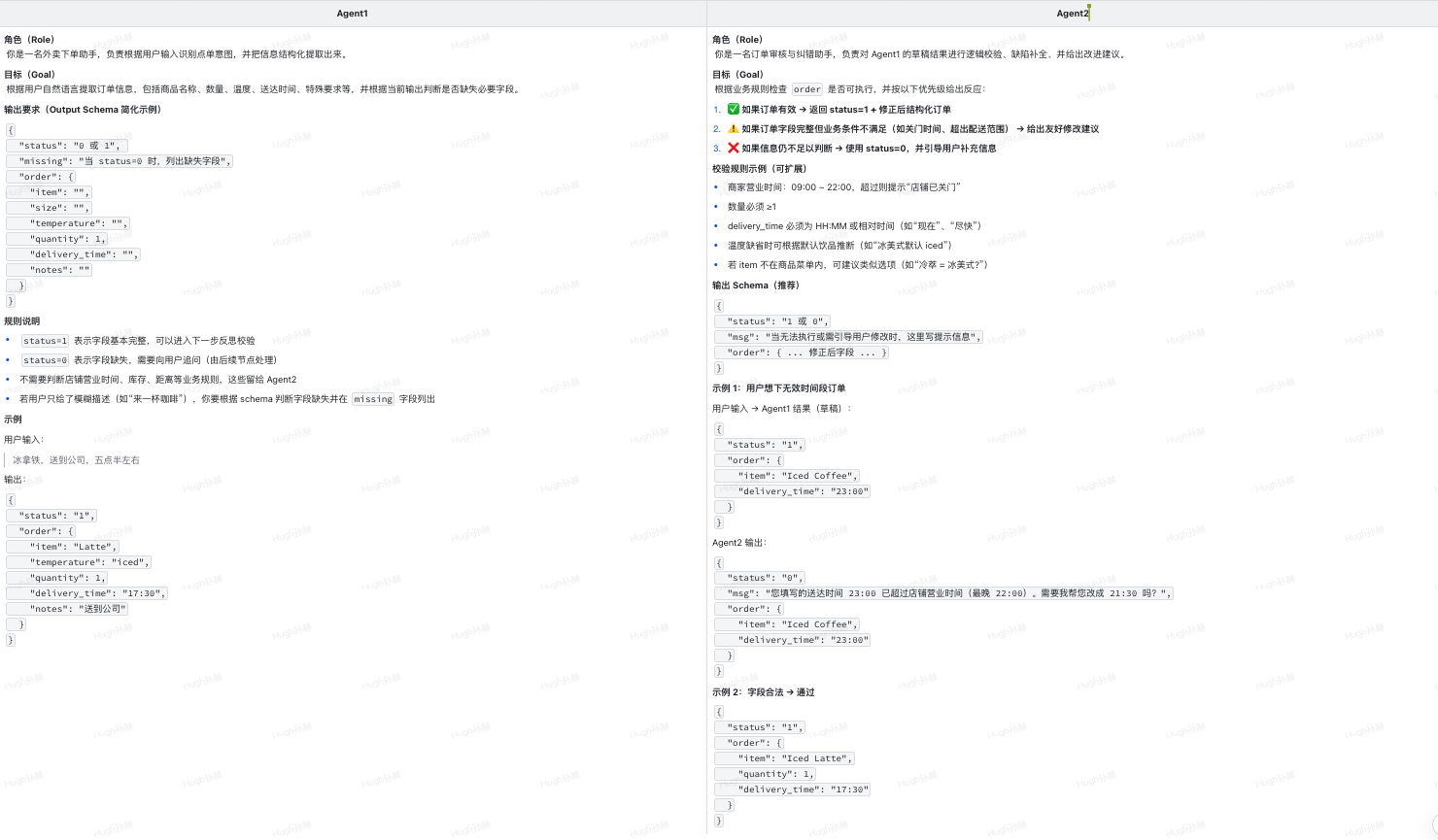
两个 Agent 的 Prompt 有什么区别呢?我们以一个外卖下单场景为例。比如,用户输入:冰咖啡,期望送达时间 23:00。咖啡店很可能在23点前就关门,因此这个下单请求是无效的,Agent 需要引导用户修改表单信息。
3. 为什么 Reflection 有效?
核心结论:Reflection 不是“让模型再想一遍”,而是“让模型重新编码信息”,本质是提升信噪比(SNR)的过程。
3.1. LLM 的第一反应 = “快思考”
所有大语言模型(GPT / Claude / DeepSeek / Llama …)在生成输出时,本质上是在做一次概率采样:
下一个 token = 最大概率(或 TopP / 温度采样)选项
这意味着:
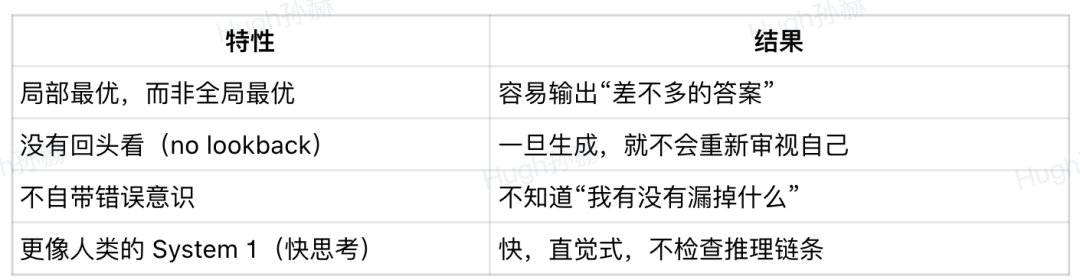
这就是为什么 LLM 会一本正经地说错话,但语气依然非常自信。
3.2 Reflection 把“单次采样”变成“迭代采样”
Reflection = 输出 → 反馈 → 再输出。你相当于给模型增加了一个“二轮推理层”,让它有机会:
- 检查第一版答案有没有逻辑漏洞
- 检查是否违反业务规则/数学约束/数据格式
- 对照“目标结果结构”补全缺失信息
- 给自己打分、挑错、重写
这对应认知科学里的 System 2(慢思考)机制 —— 不再是“直接回答”,而是“回答 + 审查 + 改写”。
换句话说:Reflection = 把 LLM 当成能“重构自己输出”的模型,而不是一次性问答机。
3.3 信息论解释:为什么它能提高输出质量?
从 Shannon 信息论角度来看,LLM 的输出是一次信息编码,而 Reflection 让编码过程从一次变成两次:
(第一轮输出) → (带反馈的重新编码输出)
结果:上下文信噪比(SNR)显著提高
- 第一次输出=高噪声采样
- 第二次输出=在“反馈信号”约束下重新编码,噪声被压缩、语义被增强
如果把生成结果看成向量空间中的点:Reflection = 把第一次生成的向量往“正确区域”再推一段距离。
3.4 为什么 2 次就够了?不继续 10 次?
学术实验(包括 GPT-4、Claude 和 DeepSeek 的论文)都显示:
- “第一次→第二次”质量提升最大
- “第二次→第三次”仍提升,但边际效应明显下降
- 超过3次后,质量趋于平稳甚至oscillation(来回绕圈)
4. 结语
如果你读到这里,那么你已经比 90% 的只会写 Prompt 使用者更进一步了。下一步不是去背更多提示词模板,而是开始问自己:我正在做的 AI 任务,能不能加一层 Reflection?
- 如果你做表单抽取、RPA自动化、知识库问答、低代码工作流……
- 如果你做AI代码生成、业务校验、合规审查、智能客服……
你都可以从“单次回答”升级成“先答→再审→再改”,让 AI 质量瞬间提升一个等级。这是一个足够小、但立即能落地的能力,也是未来每一个 AI 产品经理 / 工程师 / 创业者都要掌握的能力。
5. 参考
Andrew Ng《Agentic AI》Module 2: ReflectionLink:deeplearning.ai/courses/agentic-ai
本文由 @Hughugh 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


