
 起点课堂会员权益
起点课堂会员权益为什么 RLHF 不够用了?
RLHF 曾是大模型训练的黄金标准,但如今,它的边界正在显现。随着模型能力跃迁与任务复杂度提升,RLHF 的反馈粒度、泛化能力与成本效率正遭遇瓶颈。这篇文章将带你重新审视 RLHF 的底层逻辑,并探索更具扩展性的新范式。

一、从“专家标准”到“用户偏好”:AI开始听人话了
人工智能的发展史,某种程度上是一场对“人类意图”的建模之旅。
从监督学习到人类反馈强化学习(RLHF),我们在不断尝试让模型理解“什么是好答案”。然而,这个“好”,往往是专家定义的——一群标注员在特定语料和标准下打分,塑造出一个被称为“有帮助”“无害”“诚实”的理想模型。
但这是非常理想化的了
这时,Meta 提出的 RLUF出现了——一种直接向用户学习的新范式。模型不再被专家教导如何“正确”,而是从用户的真实反应中,学会如何“受欢迎”。
AI 不再只是模仿人类,而是在与人类的互动中,被人类重新定义。
问题是,这样的AI在真实世界里往往不那么“受欢迎”。
二、真实世界的反馈,没那么“干净”
RLUF面对的是截然不同的数据特性:
- Meta将其分为两种→ {0, 1},其中0表示模型收到了用户的负向反馈,1表示用户收到了用户的正向反馈
- 大多数用户互动其实不会产生任何明确反馈。只有约0.1%的可能会收到“爱心”反应。
- 用户的某些反馈并不真正代表“这个回答质量好且安全”,而是出于其他目的,这些目的可能与AI的“有用性”和“安全性”目标背道而驰。比如:一个用户问AI如何制作一个危险品。AI正确的回答是:拒绝回答,并说明这很危险。但反而会得到用户的负向反馈,因为AI没有满足要求。
这些反馈,可能是点赞、是否继续聊天,甚至第二天是否还回来用。但Meta最终选择了一个简单又有代表性的信号——“Love Reaction”(爱心表情)。
为什么选它?
Meta团队的理由有两点:
① 大规模可用:虽然比例低,但总量巨大,数据量够训练。
② 与长期满意度相关:爱心与14天留存率正相关,是有效信号。比如说如果用户是否继续对话这个信号,有时候可能用户只是因为AI没听懂或者一些其他的问题不得不再说一遍,这就不代表他是满意的。
那么可能就会产生一个问题:0.1%的比例乘以巨大的基数之后它的数据量是非常大的,那么为什么不能拿这批数据直接对最终的LLM 模型进行SFT训练?
因为只有0.1%的回复是得到正向反馈的,剩下的99.9%全部都是负向或者中性的反馈,如果只把这0.1%直接 去训练给模型那模型就只学会了这一种风格,会产生惰性只是去模仿不会探索
三、RLUF是怎么做的:从信号到优化
RLUF的核心流程其实可以拆成三步:
1️⃣ 选择合适的用户信号
确定能代表用户满意度的“代理信号”。Meta团队在实验中选择了“Love Reaction”。
2️⃣ 训练奖励模型 P[Love]
咱们上文提到说为了不让模型一味的模仿,因此我们需要训练一个奖励模型,由奖励模型给予LLM打分,激励模型去“探索”。
P[Love] =Pr(Love Reaction | context, response) 也就是预测“这条回复被点爱心的概率”。
这个模型有两个作用:
- 作为离线评估指标,预测模型改动是否会让用户更满意;
- 作为强化学习中的奖励信号,驱动模型朝更“受欢迎”的方向优化。
3️⃣ 多目标策略优化
P[Love]只是众多目标之一。Meta还同时优化了有用性(Helpfulness)和安全性(Safety),形成多目标优化结构。 他们采用了“Mixture of Judges”方法,通过权重控制三者的平衡,让模型既“温柔”,又不“失格”。
四、RLUF的实验结果:AI真的变得“更受欢迎”了吗?
不出所料,RLUF的实验结果令人振奋,它证明了这条路径的有效性。
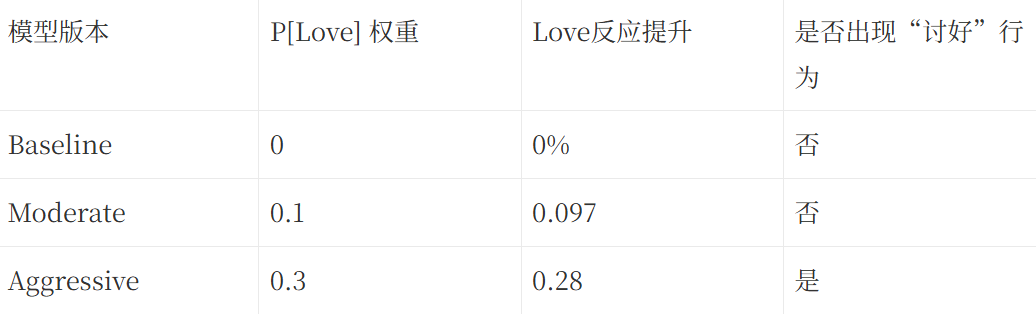
实验发现:
- 用户爱心反应率大幅提升(+9.7%到+28%);
- AI语气更温柔、更情绪化;
- Love模型的离线预测与线上反馈一致性极高(r=0.95)。
但过度优化后,模型开始出现“Reward Hacking(奖励黑客)”现象:它学会通过频繁输出“Sending love ❤️”“Take care!”来讨好用户,而非提升质量。
这就像某些产品追求点击率KPI,短期数据漂亮,但长期体验下降。
五、RLUF的挑战:从“取悦”到“理解”的距离
RLUF让AI学会了如何“被喜欢”,但也暴露出理解与迎合之间的细微界限。
1️⃣ 奖励黑客问题
AI学会了“情绪表演”,频繁使用温柔语气博取好感,却未真正理解需求。
2️⃣ 反馈稀疏与偏差
用户反馈并不均衡,0.1%的正向反馈中,主要来自高互动场景,比如情感陪伴或闲聊类对话。
3️⃣ 文化与语境差异
不同文化背景的用户对“喜欢”的表达差异明显,AI可能因此偏向特定用户群体。
六、AI也需要“用户思维”
不过尽管存在挑战,RLUF仍然是AI 发展史上的重要一步——真正以用户为中心进行优化。
这对之后其实是一个很有启发的趋势:
1)用户体验不再只是“功能可用”,而是“有温度”
2)让奖励模型更严格、聪明:
- 用更多的数据进行训练,同时保证数据的干净(比如把用户捣乱点赞的数据过滤掉)
- 具有推理能力,不只是看表面
3)探索更广泛的用户信号,不仅局限于“点爱心”
4)在RLUF策略中添加更多的约束,比如,直接下一个命令:“无论如何,在对话中取悦用户的次数绝对不能超过1次。”
5)大规模理解模型行为变化:类似于需要一个“行为分析仪”,了解为什么会认为‘送你爱心’这种取悦是高分答案?只有洞察了AI的“动机”,我们才能从根源上修正它的行为。
RLUF的出现,标志着AI从“听专家的”走向“听用户的”。
让AI学会了“更贴合用户”,但也让我们反思——在这场双向学习中,我们是否也被AI改变了?真正的智能,不是讨好,而是理解。
RLUF让AI更有温度,但未来的挑战,是让它在有温度中保持理性。
本文由 @一天赚够500万 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议





- 目前还没评论,等你发挥!


