
 起点课堂会员权益
起点课堂会员权益AI PM 进阶笔记【6】:5大模块+4个交付物,AI-PRD产品落地不踩坑
AI产品的开发逻辑正在颠覆传统PM的认知框架。本文深度解析AI Agent全生命周期实战方法论,从重构PRD文档到部署优化,揭秘5大核心模块的落地策略。无论你是面临转型困境的资深PM,还是刚入局的AI产品新人,这套融合Agent Story设计、提示词工程与模型调优的实战指南,都将彻底刷新你对AI产品开发的理解。
很多传统PM带着老思路做AI:PRD写得逻辑缜密,原型画得像素级精准。结果开发出来的产品,要么答非所问,要么工具调用出错。最后只能感叹“AI太难做”。
本质是一套AI Agent全生命周期实战指南。它从产品定义到硬件部署,讲透了AI PM该有的新玩法。我把核心内容拆成5大模块,每块都带“痛点+解法”。不管你是AI PM新手,还是转型中的老兵,都能直接用。
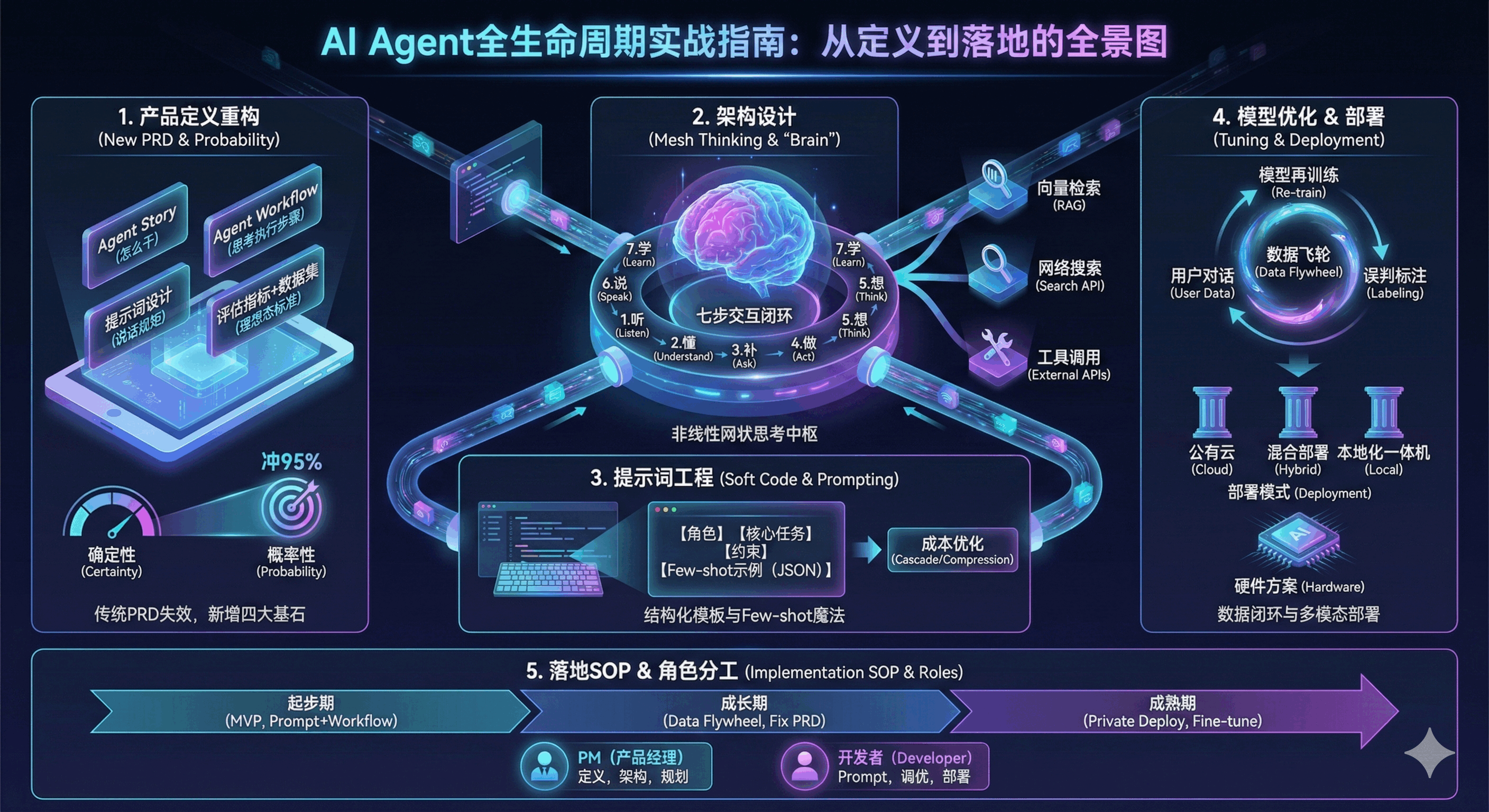
一、先踩坑再破局:AI产品的5大核心模块
1. 产品定义:传统PRD没用了,AI要加4个新模块
大家容易踩的坑:拿传统PRD套AI产品。最后开发出来的东西,和预期差了十万八千里。核心问题很简单:传统软件是确定的,AI是概率性的。
AI PRD必须加这4个模块(实战总结):我们复盘发现,少了任何一个,后续都容易出问题。新增核心内容:
- Agent Story:把“用户要什么”改成“Agent怎么干”。
- Agent Workflow:明确Agent的思考和执行步骤。
- 提示词设计:给模型定好“说话规矩”。
- 评估指标+数据集:AI是概率模型,得定“好”的标准。举个例子,传统用户故事是“查物流”。
- Agent Story要写:用户说“鞋到了吗”,Agent先关联最近订单,再调物流API。
别用平庸数据,要定义“理想态”:很多人直接用历史客服数据训练,这是大错。那些数据里藏着大量低质量回复,只会越训越差。
正确做法:筛选高质量样本,标注“理想回答”。比如人工响应<5秒,AI目标就得设成<2秒;人工解决率80%,AI要冲95%。
选型别瞎选,看这6个维度:
- 做技术选型时,要平衡性能、成本和可扩展性。
- 关键维度:性能、适配性、可扩展性、稳定性、成本、合规。
另外,LLM产品别搞瀑布流,要Demo驱动。快速做Demo拿反馈,比写100页PRD管用。
2. 架构设计:AI不是线性流程,是“网状思考”
传统软件是“用户点一下,系统动一下”的线性逻辑。AI Agent不一样,它会自己思考、自己调用工具。这部分就讲透它的“大脑”怎么运转。
传统vs AI开发:差在“快速迭代”。
传统流程是PM→开发→Demo→反馈,周期长。AI开发靠“提示词即代码”,改一行Prompt就能迭代。
Agent通用架构:核心是“连接工具”。Agent核心就像个中枢,连接向量检索、网络搜索等工具。完整架构分四层:数据层、模型层、应用层、用户层。
还有个七步交互闭环,记下来就能用:1. 听(接收指令)→2. 懂(识别意图)→3. 补(追问信息)→4. 做(调用工具)→5. 想(决策)→6. 说(回复)→7. 学(记录)。
工具调用原理也简单:先注册能力,再拆问题,生成命令执行。
复杂场景怎么设计?看这2个案例:
场景1:修改订单地址(高风险)。要用到意图路由、槽位管理、风险确认三个组件。
流程:用户提需求→识别意图→补全信息→二次确认→调用API。
场景2:查订单物流(普通)。直接走“识别意图→提关键词→调API→返结果”就行。
交互上别只做聊天框,要Chat+GUI。比如报修时,弹出卡片让用户选时间,省一半沟通时间。
3. 提示词工程:这是AI的“软代码”,附实战模板
很多人觉得提示词是“玄学”,其实有固定模板。这部分是整套资料的精华,拿过去就能直接写Prompt。
System Prompt怎么写?按这个结构来。标准模板含5部分,少一个都容易出问题。
- 角色定义:比如“专业电商助手”,别模糊。
- 核心任务:识别意图、提单号、调工具、解数据。
- 核心挑战:应对信息缺失、工具失败等边缘场景。
- 约束:不准编数据、不准乱输出节点。输出控制:既要JSON(给系统看),也要自然语言(给用户看)。异常兜底要明确,比如“订单不存在”怎么回复。
- Few-shot的关键:给JSON示例。别只说“按格式输出”,直接给输入输出样例。模型学起来更快,出错率能降60%。再加点Few-shot示例,教模型处理边缘情况。
高级技巧:3个策略提升效果。不是随便写Prompt,背后有逻辑:
- 强化专业身份,避免回复口语化。加Checklist,强制模型按步骤思考(用思维链思想)。约束输出格式,减少下游解析错误。
- 成本优化:Prompt压缩+级联策略。有工具能把2428 tokens的Prompt压到331 tokens。压缩比7.3倍,延迟和成本都能降。
- 还能搞LLM级联:先用弱模型,搞不定再用强模型。这么做,强模型调用成本能省一半以上。
4. 模型优化:Prompt搞不定时,就走这步
如果Prompt调到极致,效果还是不行。那就要进入模型微调阶段,这是进阶玩法。
核心矛盾是:成本、安全、灵活性怎么平衡?
三种部署模式,按公司情况选:
- 公有云:启动成本低,扩展性强。但敏感数据有合规风险,适合初创或非核心业务。
- 本地化一体机:数据隔离,延迟低。但初期投入大,运维复杂,适合金融、医疗。
- 混合部署:敏感数据本地处理,非敏感上云。兼顾安全和灵活,是企业级项目首选。
硬件方案:按模型规模选配置。SuperCube系列很常用,分3000/5000/7000三个规格。配置有Intel/AMD+NVIDIA,也支持国产海光+昇腾。百亿参数(70B)到千亿参数(671B)模型都能跑。
隐私敏感场景?用联邦小模型。不用汇集原始数据,就能分布式训练。特别适合金融、医疗这类多方协作的场景。
调优是个闭环,按步骤来不慌。完整流程:定目标→增数据→调参数→选损失函数→融模型→评效果。每一步都有讲究,比如超参数要调学习率和批次大小。微调效果很明显:参数填充准确率从44.3%冲到近100%。函数选择准确率从60%提升到95%以上,冗余调用也少了。
关键要建数据飞轮:用户对话→误判标注→模型再训练。
评测分三层,成本和效果兼顾:
- 代码自动评:查格式,快又省成本;
- 人工评:MVP阶段找专家看逻辑;
- 业务评:看转人工率、解决率这些真实指标。
5. 落地总结:按阶段落地,不同角色重点不同
这套资料不是理论,是AI Agent落地的SOP。不管是搭业务中台,还是做具体AI产品,都能用。
按阶段落地建议:
- 起步期:用提示词模板+架构工作流,快速上线MVP。
- 成长期:靠数据飞轮收反馈,修正PRD标准。成熟期:上私有化部署+模型微调,降本提安全。
按角色划重点:
- PM:重点看产品定义(PRD写法)、架构流程、分阶段规划。
- 开发者:重点学Prompt模板、模型调优、部署配置。
AI Agent 落地的标准作业程序 (SOP),而非单纯的理论介绍。它深入覆盖:
- 怎么写文档 (AI PRD);
- 怎么设计逻辑 (Slot Filling, Router);
- 怎么写代码/Prompt (JSON Output, Checklist);
- 怎么定标准和优化 (Ideal Data, Tuning);
- 怎么部署落地(基础设施、部署模式),非常适合用于搭建企业级AI业务中台。
若你正在推进AI Agent项目,可按阶段精准参考:
- 起步期,借鉴提示词工程模板与架构工作流快速上线MVP;
- 成长期,通过数据飞轮收集反馈,结合产品定义模块
修正PRD标准;成熟期,落地私有化部署方案与模型微调策略,降低长期成本并提升数据安全。
按角色划分:
- PM重点关注产品定义(PRD写法)、架构流程图及分阶段规划;
- 开发者重点借鉴Prompt实战模板、模型调优数据及部署配置细节。
二、核心认知:传统PM做AI,差在“思维范式”

传统软件PM的核心是“消除不确定性”。一套PRD定死所有逻辑,输入A必出B,偏离就是Bug。
核心是把AI-PRD改成4个交付物:Agent Story、工作流、生成式UI、评测体系。这是PM从“功能定义者”变成“认知架构师”的关键。
然而,随着大语言模型(LLM)和Agent智能体架构的崛起,软件的底层逻辑已从“基于规则”(Rule-based)彻底转向“基于推理”(Inference-based)。AI产品本质上是概率性的(Probabilistic)。对于同一个输入,模型可能根据上下文、随机种子(Seed)或微小的提示词差异生成不同的输出。
这种非确定性特征导致传统PRD在指导开发时面临严峻的“认知失配”:原本用于规范确定性功能的文档,无法有效约束一个具备即兴发挥能力的随机性引擎 。
许多资深产品经理在转型AI时遭遇的“滑铁卢”——模型答非所问、工具调用失败、用户意图理解偏差——其根源均在于试图用旧地图导航新大陆。
三、PRD失效后:用Agent Story定义AI的“思考方式”
传统PRD是“消除歧义”,AI PRD是“管理歧义”。AI PM不再是扣像素,而是定义模型的思考方式。
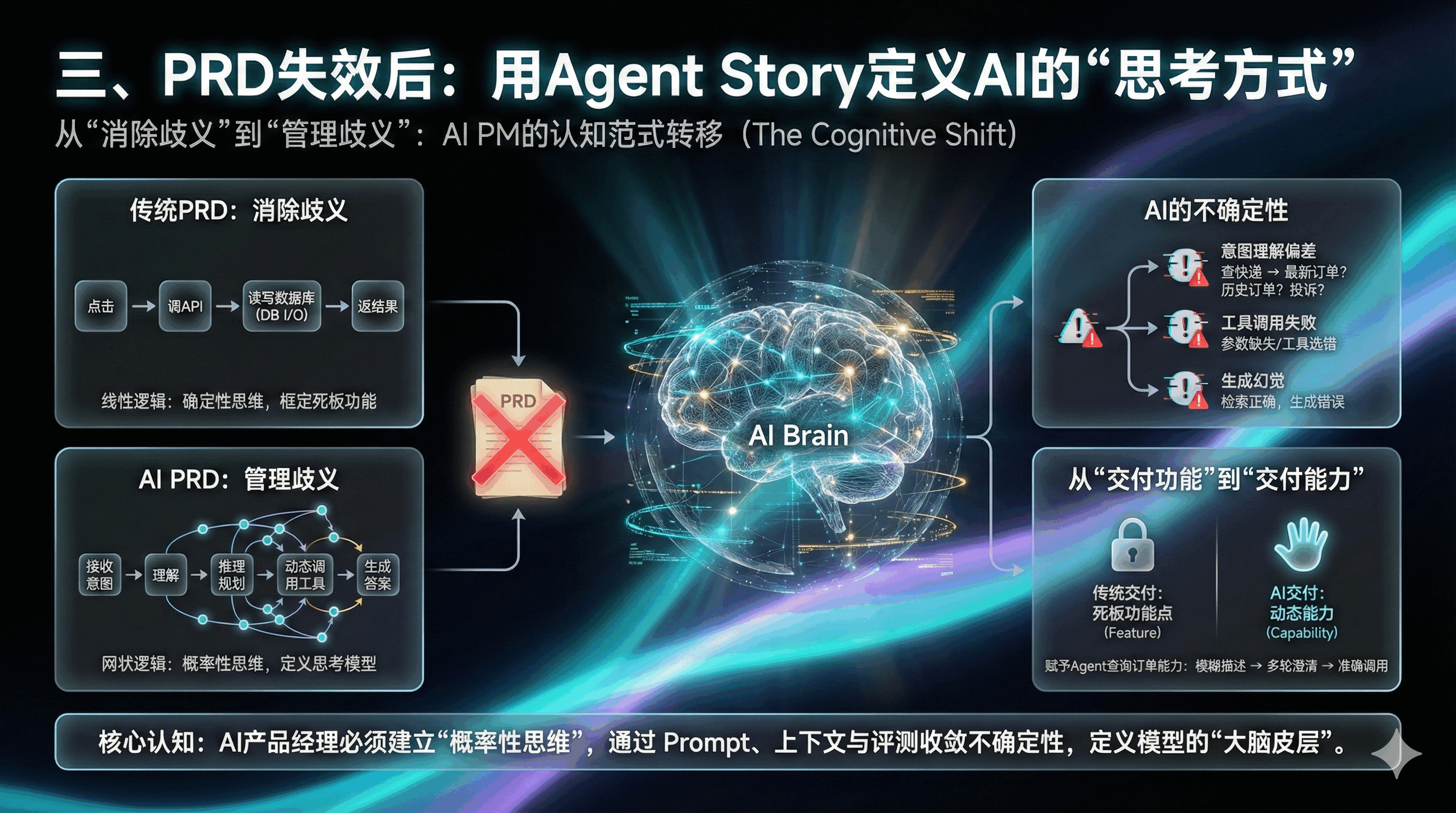
1. 确定性思维要丢:AI的“不确定性”无法消除
传统软件是线性逻辑:点击→调API→读写数据库→返结果。
AI Agent是网状逻辑:接收意图→理解→推理→调工具→生成答案。
每个环节都可能出变数,我们复盘过很多案例:
- 意图理解偏差:用户说“查快递”,可能是查最新或历史订单。
- 工具调用失败:参数没提全,或选错了相似工具。
- 生成幻觉:检索到正确信息,却额外编了错误内容。所以别用静态原型框定AI,要靠Prompt和评测收敛不确定性。
AI Agent的运行逻辑是网状且开放的:用户表达意图 -> Agent感知与理解 -> 推理规划(Reasoning) -> 动态调用工具 -> 生成回答 。
在这个过程中,每一个环节都充满变数:
- 意图理解的不确定性:用户的一句“帮我查下快递”,可能被模型理解为查询最新订单,也可能被理解为查询历史所有订单,甚至被误判为投诉物流慢。
- 工具调用的不确定性:模型可能因为参数提取不全而无法调用API,或者在面对多个相似工具时选择了错误的一个 。
- 生成内容的不确定性(幻觉):即使检索到了正确信息,模型也可能在生成回答时添油加醋,产生看似合理实则谬误的“幻觉” 。
因此,试图用一张静态的原型图或一段僵硬的逻辑描述来框定AI行为,无异于刻舟求剑。AI产品经理必须建立“概率性思维”,即承认系统的不完美,并通过提示词工程(Prompt Engineering)、上下文管理(Context Management)和评测(Eval)来收敛这种不确定性,使其落在用户可接受的体验范围内 。
2. 从“交付功能”到“交付能力”
在AI时代,我们交付的不再是死板的“功能点”(Feature),而是动态的“能力”(Capability)。
- 传统交付: “增加一个搜索框,支持按订单号查询。”
- AI交付: “赋予Agent查询订单的能力,使其能在用户模糊描述(如‘上周买的鞋’)下,通过多轮对话澄清意图,并准确调用物流接口。”
这种转变要求产品文档必须深入到模型的“大脑皮层”,去定义它如何思考、如何记忆、如何决策。这正是“Agent Story”诞生的背景。
四、Agent Story怎么写?套ITTO模型就行
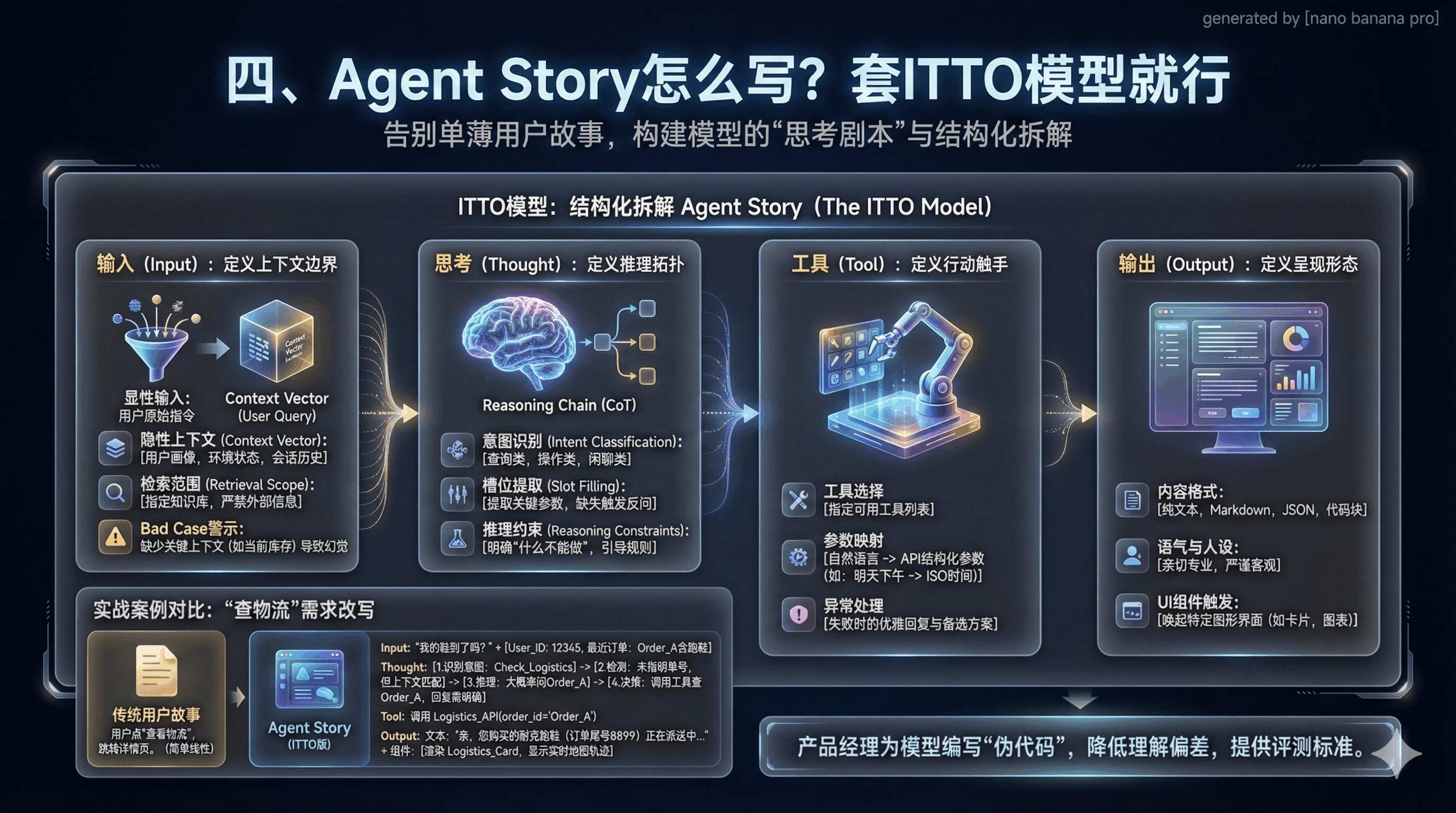
传统用户故事太单薄,只说“要什么”,没说“怎么做”。Agent Story要讲清模型的“思考剧本”,核心是ITTO模型。
一个合格的Agent Story必须基于ITTO模型(Input, Thought, Tool, Output)进行结构化拆解。这不仅仅是写给开发人员看的,更是写给模型看的“剧本” 。
输入(Input):定义上下文的边界
在AI语境下,“输入”绝不仅仅是用户说的那句话。它是一个包含多维信息的上下文向量(Context Vector)。产品经理必须在文档中明确列出模型决策所需的所有隐性信息 。
显性输入(Explicit Input):
用户的原始指令(User Query)。
- 隐性上下文(Implicit Context):用户画像(User Profile): 用户ID、会员等级、偏好标签;
- 环境状态(Environment State): 当前时间、地理位置、设备类型;
- 会话历史(Session History): 前几轮对话的内容,用于指代消解(Coreference Resolution)。
- 检索范围(Retrieval Scope): 针对该任务,RAG系统应该去哪些知识库(Knowledge Base)里找答案?(例如:“仅限查询《2025年退换货政策》,严禁引用互联网通用信息”) 。
Bad Case警示: 很多项目上线后发现模型经常胡说八道,原因往往是PM在定义输入时,忽略了提供“当前库存数据”作为上下文,导致模型只能根据训练数据中的过时信息进行猜测 。
思考(Thought):定义推理的拓扑结构
这是Agent Story中最具革命性的部分。PM需要定义Agent在行动之前的“内心独白”或推理链条(Chain of Thought, CoT)。这不再是黑盒,而是可被设计的产品逻辑 。
- 意图识别(Intent Classification): 明确Agent首先需要判断用户意图属于哪一类(如:“查询类”、“操作类”、“闲聊类”)。
- 槽位提取(Slot Filling): 定义必须从用户话语中提取的关键参数(实体)。例如,在“订机票”场景中,必须提取出发地、目的地、时间。如果缺失,Agent必须触发反问逻辑,而不是瞎猜 。
- 推理约束(Reasoning Constraints): 明确“什么不能做”。例如:“如果用户询问竞品价格,委婉拒绝并引导回自家产品优势。”
工具(Tool):定义行动的触手
Agent的能力边界由它能调用的工具决定。PM必须像定义API接口文档一样,精确定义Agent Story中涉及的工具调用逻辑 。
- 工具选择(Tool Selection): 指定当前场景下允许使用的工具列表。
- 参数映射(Parameter Mapping): 定义自然语言如何转化为结构化的API参数。例如:用户说“明天下午”,模型需要将其转换为 2026-05-21 14:00:00 的ISO时间格式 。
- 异常处理(Error Handling): 当工具调用失败(如超时、无数据)时,Agent该如何优雅地回复?是直接报错,还是提供备选方案?
输出(Output):定义呈现的形态
AI的输出不应局限于纯文本。在Agent Story中,必须定义输出的多模态结构 。
- 内容格式: 纯文本、Markdown表格、JSON对象、还是特定的代码块?
- 语气与人设(Tone & Persona): 客服Agent需要亲切专业,法律Agent需要严谨客观。
- UI组件触发: 是否需要唤起特定的图形界面(如卡片、图表)?
2. 实战案例:“查物流”需求怎么改写?
传统用户故事:“用户点‘查看物流’,跳转详情页。”
Agent Story(ITTO版):
Input: 用户Query:“我的鞋到了吗?” + 上下文(User_ID: 12345, 最近订单: Order_A含跑鞋)。
Thought:
1. 识别意图为 Check_Logistics;
2. 检测到Query中未指明具体单号,但上下文中有“最近订单Order_A”匹配“鞋”这一实体;
3. 推理:用户极大概率在问Order_A;
4. 决策:直接调用工具查询Order_A,但在回复中需明确告知查询的是哪一单,以防误会。
Tool: 调用 Logistics_API(order_id=’Order_A’)。
Output: 文本:“亲,您购买的耐克跑鞋(订单尾号8899)正在派送中,预计今天下午送达。”;组件:渲染一个 Logistics_Card,显示实时地图轨迹。
通过这种ITTO结构的拆解,产品经理实际上是在为模型编写“伪代码”,这大大降低了开发过程中的理解偏差,也为后续的评测提供了明确的标准。
五、流程设计:线性流程图失效,改用“网状工作流”
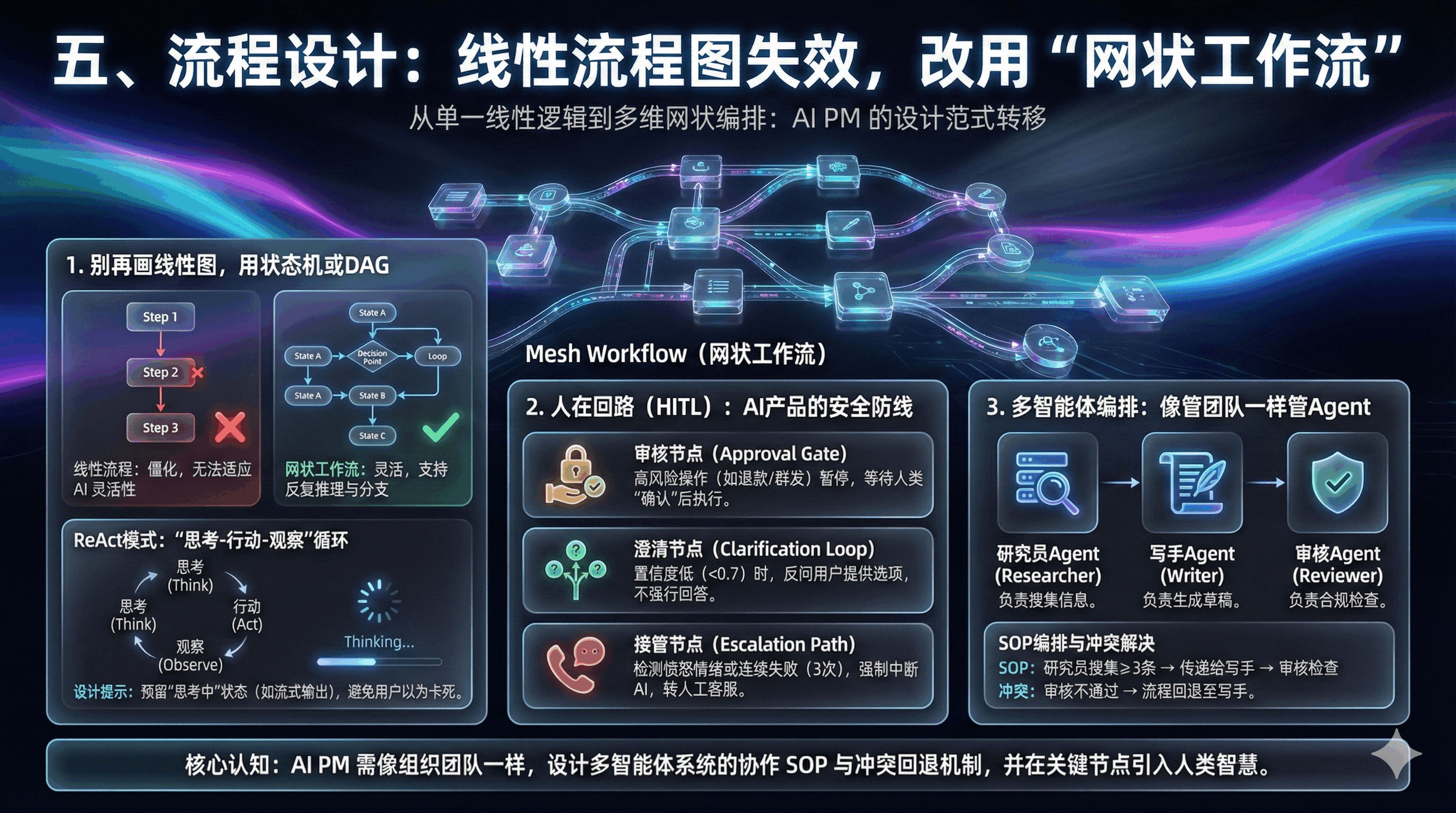
传统流程是线性的,一步一步走到底。AI流程是网状的,可能反复推理、调用工具。所以得用新的设计工具——Agent工作流。
1. 别再画线性图,用状态机或DAG
线性图撑不起AI的灵活性。要设计状态机或有向无环图(DAG),节点是能力,边是流转条件。
- ReAct模式:预留“思考-行动”循环。这是目前常用的工作流模式,核心是“思考-行动-观察”。
- 设计提示:别只设计“问”和“答”,要留“思考中”状态。比如复杂问题,要显示“正在查资料”,避免用户以为卡死。
传统的线性流程无法涵盖AI的灵活性。
AI PM需要设计基于状态机(State Machine)或有向无环图(DAG)的工作流。每一个节点代表一个Agent或一种能力,边代表流转的条件。目前业界最主流的Agent工作流模式是ReAct (Reason + Act)。PM在设计工作流时,必须预留出“推理-行动-观察”的循环空间 。
设计启示: 你不能只设计“问”和“答”两个节点。你必须设计中间的“思考状态”。如果这个思考过程很长(例如涉及多步推理和多次搜索),产品界面上必须有对应的“思考中”反馈(如流式输出思考过程),否则用户会以为系统卡死 。
2. 人在回路(HITL):AI产品的安全防线
AI PM需要在工作流中明确标注出哪些节点需要人类介入:
- 审核节点(Approval Gate): 对于高风险操作(如退款、发送群邮件),Agent生成草稿后,流程必须暂停,等待人类点击“确认”后方可执行 。
- 澄清节点(Clarification Loop): 当Agent的意图识别置信度(Confidence Score)低于设定阈值(如0.7)时,流程自动分支进入“反问模式”,列出可能的选项供用户选择,而不是强行回答 。
- 接管节点(Escalation Path): 当情感分析检测到用户愤怒,或连续三次交互未能解决问题时,强制中断AI流程,转接人工客服 。
3. 多智能体编排:像管团队一样管Agent
对于复杂任务,单个Agent往往力不从心。PM需要像组织团队一样,设计多智能体系统(MAS) 。
角色定义:
- “研究员Agent”负责搜集信息,“写手Agent”负责生成草稿,“审核Agent”负责合规检查。
SOP编排:定义Agent之间的协作SOP(标准作业程序)。例如:“当研究员Agent搜集到至少3条相关新闻后,将内容打包传递给写手Agent” 。
冲突解决:如果审核Agent认为写手Agent的内容不合规,流程应回退到哪一步?这些都需要PM在工作流中明确定义。
六、交互设计:别只做聊天框,Generative UI才是未来

“AI产品就是聊天框”,这是最大的误区。纯文字回复效率低,用户读着累。未来是LUI(语言交互)+GUI(图形交互)的混合模式。
1. 纯聊天框的坑:信息密度太低
举个例子,用户想订机票:
纯LUI体验:Agent发一大段文字列航班,用户找信息累。
混合体验:直接弹航班卡片,支持排序、筛选、一键预订。
想象一下,用户想订一张机票。
纯LUI体验: Agent吐出一大段文字:“为您找到以下航班:1. 国航CA123,8:00起飞,1200元;2. 东航MU456,9:00起飞,1150元……” 用户读起来非常累,且难以进行对比和筛选。
混合体验: Agent在对话框中直接渲染出一个“航班列表卡片”,用户可以像在携程App里一样点击排序、筛选,甚至直接点击“预订”按钮。
2. Generative UI:按场景动态生成界面
GenUI不是预先写死的,是AI按上下文生成的。不用画所有界面,只需定两件事:
1. 组件库:明确有表格、折线图、表单等哪些组件。
2. 触发逻辑:什么场景用什么组件。比如查价格对比,自动生成对比表格;查趋势,自动出折线图。还要定义加载态,避免用户等得焦虑。
PM在PRD中如何定义GenUI?你不必画出每一张可能的UI图,但你需要定义组件库(Component Library)和触发逻辑(Trigger Logic)。
- 组件定义:定义系统支持哪些原子组件(如:表格、折线图、地图、表单、确认卡片)。
- 生成策略:意图 -> 组件映射: “当用户意图为 Compare_Prices 时,生成 Comparison_Table 组件。”;数据填充: “将API返回的JSON数据填充到组件的 props 中。”
- 流式渲染(Streaming UI):考虑到LLM生成的延迟,PM需要定义组件的“加载态”和“渐进式渲染”效果。例如,图表的骨架屏先出来,数据点随着Token的生成逐个上屏 。
案例:数据分析Agent的GenUI设计。
用户Query: “分析一下上个季度的销售趋势。”Agent Output:
文本摘要:“上季度整体销售额增长了15%,主要由3月份的促销活动拉动。”;
GenUI组件:自动生成一个 Line_Chart,X轴为时间,Y轴为销售额,并高亮3月份的数据点。
PM规范: “若数据包含时间序列,强制使用折线图展示;若数据为分类占比,使用饼图。”
3. 交互不只是展示,还要喂数据给模型
GenUI是交互入口,还要帮模型迭代。比如用户点了商品卡片的“不喜欢”。不仅要移除卡片,还要告诉Agent:“排除这类风格”。这就是RLHF数据闭环,让模型越用越懂用户。
Generative UI不仅仅是展示,更是交互的入口。PM需要定义组件内的交互如何反馈给Agent。例如,在生成的“推荐商品卡片”中,用户点击了“不喜欢”按钮。这个动作不仅要在UI上移除卡片,更要向Agent发送一个隐式的Prompt:“用户不喜欢商品ID=xxx,请在后续推荐中排除此类风格”,从而实现RLHF(Reinforcement Learning from Human Feedback)的数据闭环 。
七、评测体系:不做评测就上线,AI产品就是裸奔
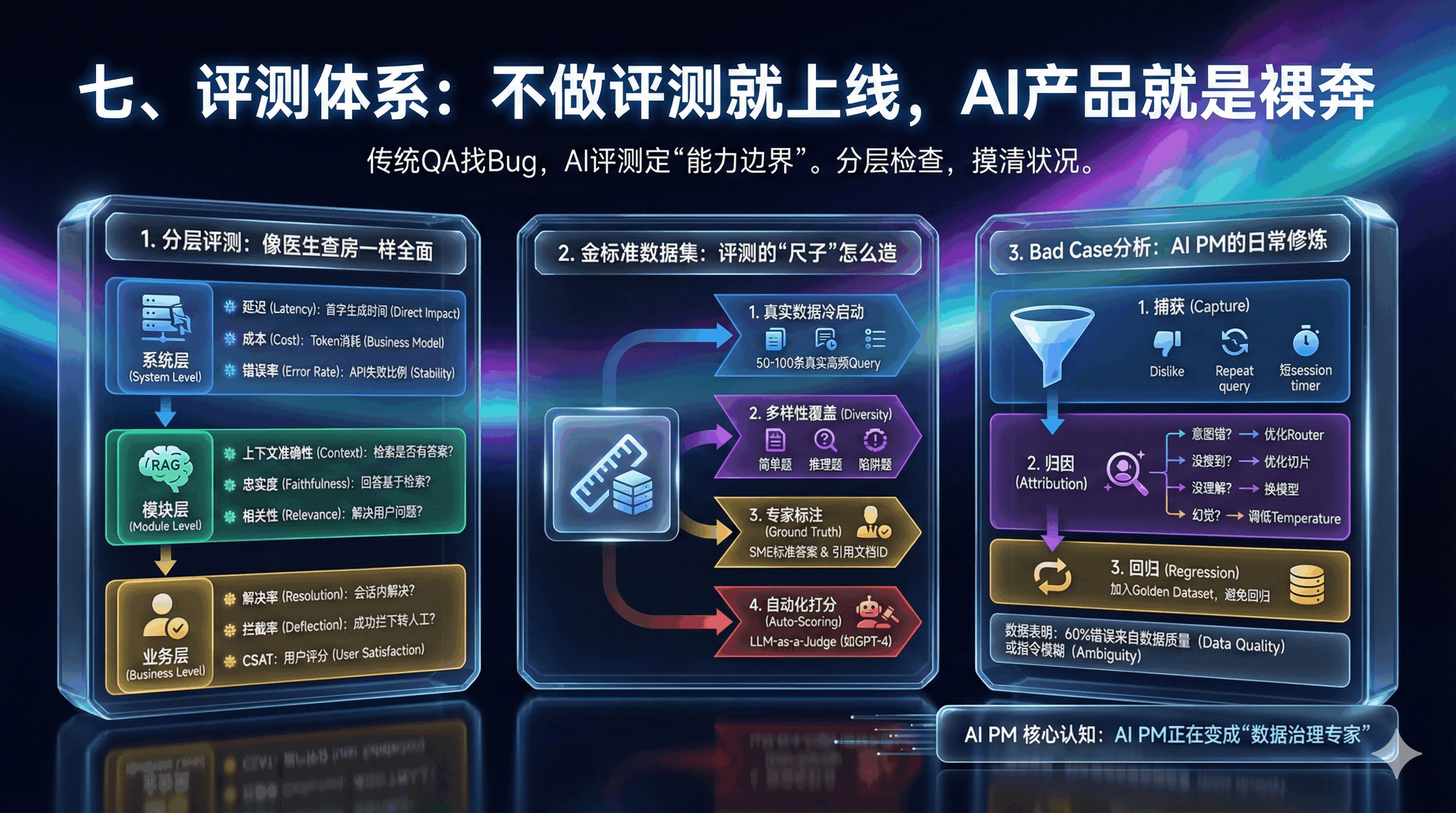
传统软件QA是找Bug,AI评测是定“能力边界”。就像医生查房,要分层检查,才能摸清系统状况。
1. 分层评测:像医生查房一样全面
系统层:查“基础体征”。
延迟:首字生成时间,直接影响用户体感。
成本:每次交互的Token消耗,关系商业模式。错误率:API调用失败或超时的比例。
模块层:重点查RAG的3个核心。RAG是目前主流架构,这三点必须测:
- 上下文准确性:检索的文档有没有答案?
- 忠实度:回答是不是基于检索到的内容?
- 相关性:回答有没有解决用户的问题?
业务层:看“最终效果”。
解决率:用户问题在会话内有没有解决?
拦截率:客服Bot成功拦下多少转人工需求?
CSAT:用户直接点赞或评分。
AI系统是一个复杂的黑盒,笼统地问“效果好不好”是毫无意义的。PM必须建立分层的评测指标体系 。
系统层:基础生命体征。
- 延迟(Latency / TTFT): 首字生成时间。对于流式输出,这直接决定了用户的体感等待时长。
- 成本(Token Usage): 每次交互的Token消耗。这关系到商业模式是否成立。
- 错误率(Error Rate): API调用失败或超时的比例。
2. 金标准数据集:评测的“尺子”怎么造
所有评测的前提是有一把“尺子”。这就是Golden Dataset(金标准数据集) 。
构建Golden Dataset的SOP:
- 真实数据冷启动:不要自己编造问题。从历史客服记录、搜索日志或内测用户提问中捞取50-100条真实的高频Query。
- 多样性覆盖:确保数据集包含:简单题: “退货政策是什么?”;推理题: “我这就去机场,来得及退货吗?”(需要结合时间、政策进行推理);陷阱题(Adversarial): “你们的产品太烂了,我要去竞品那里买。”(测试安全性和情商)。
- 专家标注(Ground Truth):让业务专家(SME)为每条Query撰写“标准答案”。这不仅仅是文本,还可以包含“必须引用的文档ID” 。
- 自动化打分:使用“LLM-as-a-Judge”技术(如使用GPT-4作为裁判),自动对比生产环境模型的回答与标准答案,计算得分。
3. Bad Case分析:AI PM的日常修炼
准确率到80%后,提升的关键在Bad Case。
Bad Case分析漏斗:
1. 捕获(Capture): 重点关注用户“点踩”、多次重复提问、转人工、或停留时间极短的会话。
2. 归因(Attribution): 像侦探一样还原案发现场。
- 是意图识别错了? -> 优化Router的Prompt或Few-shot样本。
- 是没搜到文档? -> 优化切片策略(Chunking)或增加知识库覆盖。
- 是搜到了但没理解? -> 换更聪明的模型(如从GPT-3.5换到GPT-4)或优化CoT。
- 是产生了幻觉? -> 调低Temperature参数,强调“未知则回复不知道”的约束。
3. 回归(Regression): 修复后,必须将该Bad Case加入Golden Dataset,确保下次发版不会“按下了葫芦浮起了瓢”。
数据表明: 在成熟的AI项目中,60%以上的错误并非来自模型本身的能力缺陷,而是来自数据质量(Data Quality)问题(如知识库过时、冲突)或指令模糊(Ambiguity)问题。
因此,AI PM实际上正在变成“数据治理专家” 。
八、落地工具:别再用Word和Axure,这套工具更高效
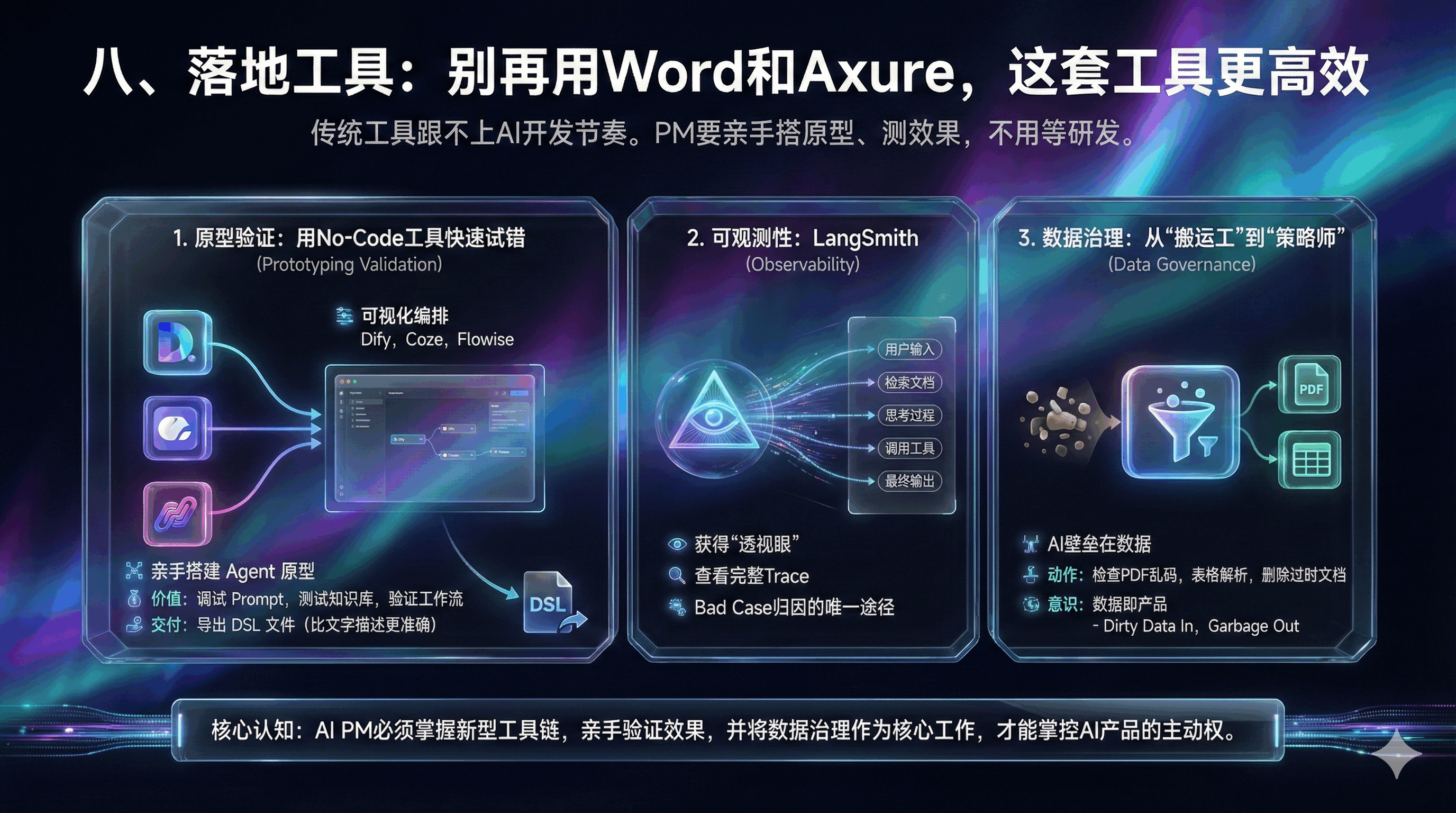
传统工具跟不上AI开发节奏了。PM要亲手搭原型、测效果,不用等研发。
1. 原型验证:用No-Code工具快速试错
Dify、Coze、Flowise这些工具都很好用。不要等研发写代码。利用 Dify、Coze、Flowise 等可视化编排平台,PM可以亲手搭建Agent的原型 。
价值: 你可以在Dify中调试Prompt,测试知识库的检索效果,验证工作流的逻辑闭环。
交付: 将调试好的Dify DSL(领域特定语言)文件导出,直接作为PRD的一部分交付给研发。这比任何文字描述都更准确。
2. 可观测性:LangSmith
利用 LangSmith 等LLM Ops工具,PM可以获得“透视眼” 。
价值: 查看每一次交互的完整Trace(链路)。你可以清晰地看到:用户输入 -> 检索到了哪几段文档 -> Agent的思考过程 -> 调用的工具参数 -> 最终输出。这是进行Bad Case归因的唯一途径。
3. 数据治理:从“搬运工”到“策略师”
AI产品的壁垒往往不在模型(大家都能调GPT-4),而在数据。PM需要花大量时间进行数据清洗(Data Cleaning) 。
动作: 检查上传到RAG的PDF是否乱码?表格数据是否被正确解析?过时的政策文档是否被删除?
意识: 数据即产品。Dirty Data In, Garbage Out。
九、结语:产品经理的进化——成为认知架构师

AI时代的到来,迫使产品经理的角色发生了根本性的裂变。我们不再仅仅是用户需求的翻译官,也不再仅仅是项目进度的管理者。我们正在成为系统的认知架构师(Cognitive Architect)。
我们需要用Agent Story来编排机器的思维逻辑,用Graph Workflow来构建非线性的业务流转,用Generative UI来重塑人机交互的界面,用严密的Evaluation体系来驯服概率性的野兽。
这“新四大件”——Agent Story、工作流、生成式UI、评测体系——构成了AI产品经理的新基建。这不仅是交付物的升级,更是思维方式的迭代。谁能率先掌握这套方法论,谁就能从“人工智障”的泥潭中突围,打造出真正具有工业级可靠性的AI产品。PRD已死,认知规范万岁。
本文由 @王俊 Teddy 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


