
 起点课堂会员权益
起点课堂会员权益传统编程已死,AI Coding是普通人最大的红利
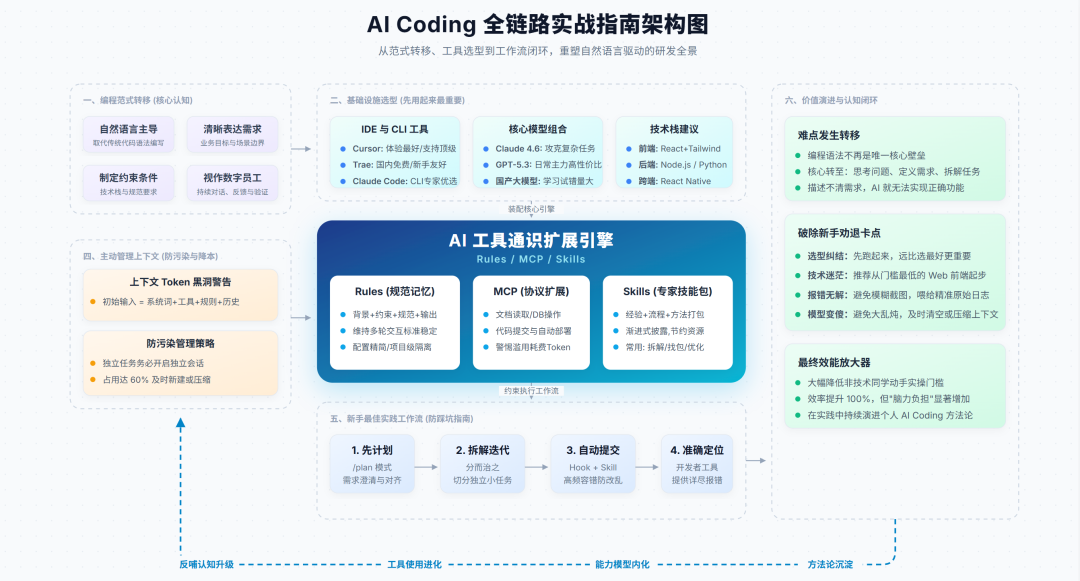
AI Coding正从"写代码"转向"说清需求"——编程语法不再重要,清晰表达需求、约束条件和预期结果才是关键。工具选择上"先用起来"比"选最好"重要:优先IDE(Cursor/Trae)而非命令行,优先Web而非App。模型才是灵魂,Claude 4.6最强但易封号,GPT-5.3性价比高,国产模型适合练手。技术栈建议Python/Node.js后端+React前端,配合MCP扩展实现自动化。真正劝退人的不是不会写代码,而是不知道从哪里开始。

这一波 AI 带来的技术平权极其猛烈,最直接的表现就是程序员的金三银四被干没了!
这并不是开玩笑,而是我结合多家企业的实际情况看到的现状,其背后的原因令人焦虑:很多以前需要依靠中高级程序员才能完成的任务,现在 AI 已经可以做了,而且做得更好、更快…
有人欢喜有人忧,既然门槛变低了,那么 AI Coding 对普通人的价值就极大了!
只不过,对于非技术同学真正去尝试 AI Coding 时,一定会遇到很多的问题,比如:
- 用什么工具;
- 选什么模型;
- 怎么描述需求;
- 如何迭代;
- 遇到报错怎么解决;
- 怎么部署到线上;
…

真实情况是看上去 AI Coding 门槛低,但多数同学是还没真正开始就卡住,很容易被劝退的。
因此,尽管 AI 大幅降低了编程的门槛,但要真正做出可用的工具,仍然存在一定门槛。基于这一点,本篇文章将逐一为大家梳理和讲清这些问题。
编程范式转移
首先,对于非技术同学,需要认定一个事实:当前的编程范式正在发生变化,从写代码 到 自然语言描述。
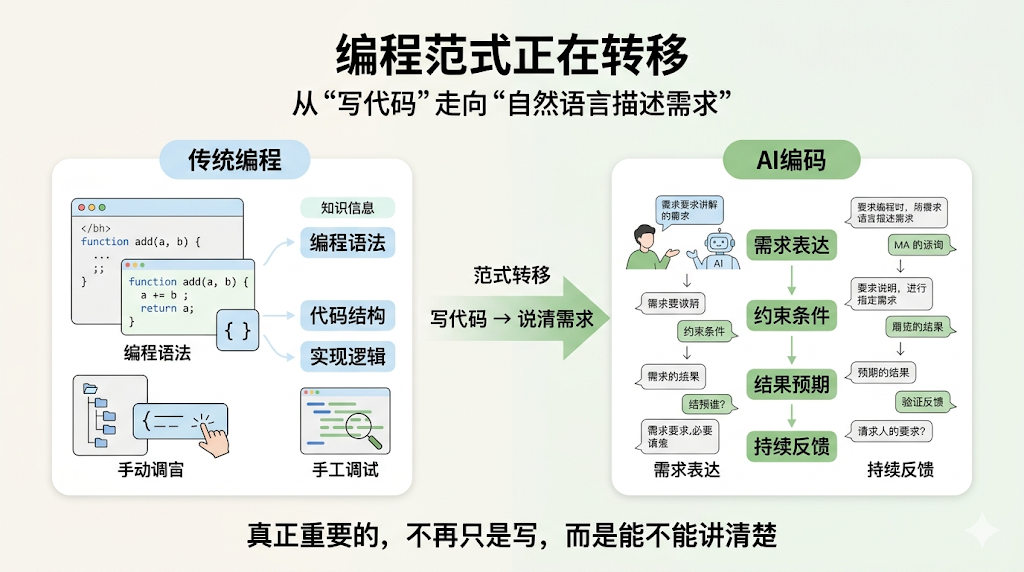
以前我们关注的是编程语法、代码结构、实现逻辑,而现在更重要的是能否清晰地表达需求、约束条件和期望结果,至于怎么实现全部交给 AI。
简单来说,现在的开发流程就是跟 AI 持续对话,不断的提出需求、验证、反馈结果。
换句话来说:编程能力开始变得不再重要,大家可以将 AI Coding Agent(Claude Code、Cursor)当成一种工具,甚至一个程序员员工使用即可。
后续极可能发现一个问题是:你描述不清楚需求,那么 AI 就做不出来,AI 做不出来的东西,多半真人也做不出来,AI 改不了的 BUG,也比期待真人能搞定…
所以,不会编程不要怕,你们跟程序员完全在同一起跑线上,有了这个觉悟就能进一步讨论了。
工具选择
现在AI编程工具非常的多,在工具选择上,新手很容易犯纠结。
哪个工具最好用?大家说法都不一样,有人说 Cursor 最好用,也会有人说 Claude code 最强,还有人说 Trae 性价比高。
实际上,这类问题很难有统一答案,因为每个人的背景、使用方式、用的模型、要做的任务都不一样,在实际的体感上会有很大差异的。
尤其是在社群里面讨论这类问题时,我一般保持沉默,因为这并不是最重要的,并且最终谁也说服不了谁,加上我偶尔会帮一下品牌做宣传,所以你懂的…
但对于新手来说,先用起来 远比 选最好的更加重要
因此,我的建议是,先从这些工具中挑选一款你最容易上手的,快速开始实践
在实际使用过程中,你会逐渐感受到不同工具之间的差异,也会慢慢形成自己的偏好。
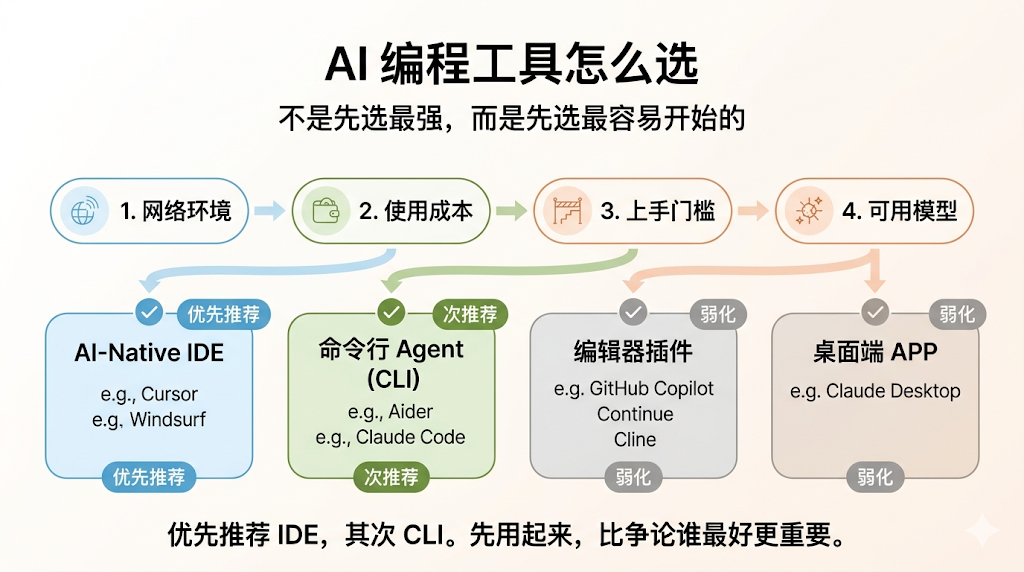
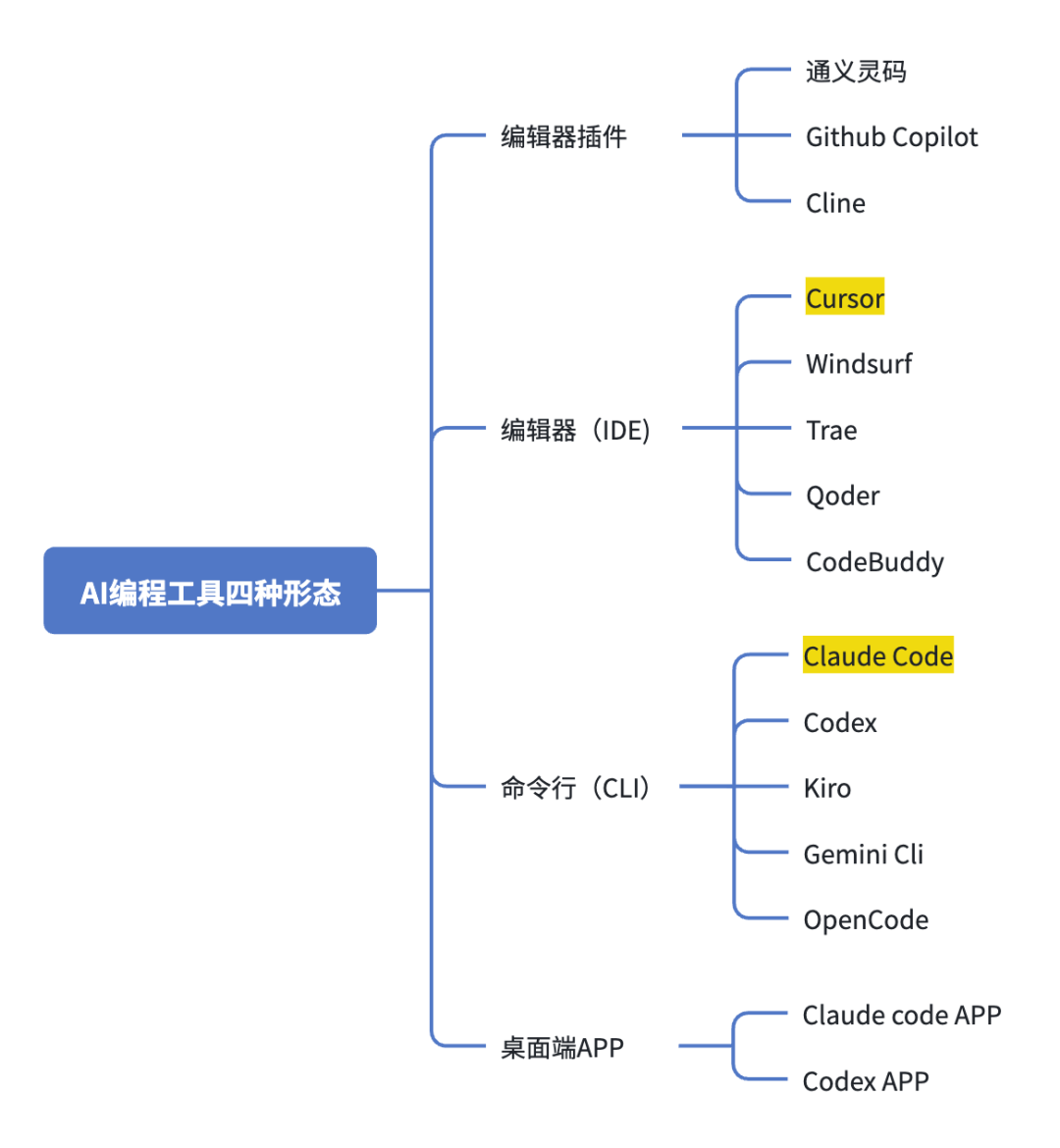
下面我们看下国内和国外主流的AI编程工具,不完全列举,这些工具主要分为四种产品形态:编辑器插件、编辑器(IDE)、命令行(CLI)、桌面端APP。
这里的决策逻辑是:1. 网络环境 2. 使用成本 3. 上手门槛 4. 能用的模型
首先不建议大家使用编辑器插件,这类体验略差,在长上下文时,卡顿比较明显。
如果你不能解决网络问题,能使用的工具和模型都会受到较大的限制,可选择的只有 Trae 国内版本、Qoder、CodeBuddy、CLI + 国内模型。
再说上手门槛问题,其实最低是桌面端 APP,对新手最为友好,但是Claude code APP 或者 Codex APP 都需要是官方的订阅用户才能使用,且需要网络条件。
因此,优先推荐编辑器(IDE),其次是命令行(CLI)
IDE 工具
因为编辑器(IDE)是可视化操作界面,很直观,打开就能用。而命令行(CLI)会有一些上手的门槛,需要熟悉命令行的基本使用。
Cursor、Trae、Qoder这些编辑器(IDE),都是基于 vs code 二次开发的,因此操作体验都差不多,真正影响我们选择的是能用的模型。
并且虽然网上现在都在吹 CLI,但个人觉得门槛低才是王道,所以 IDE 才是未来
CLI 真那么好,这么多年流行的就不是 VS 了
这里给个基本聚餐对比
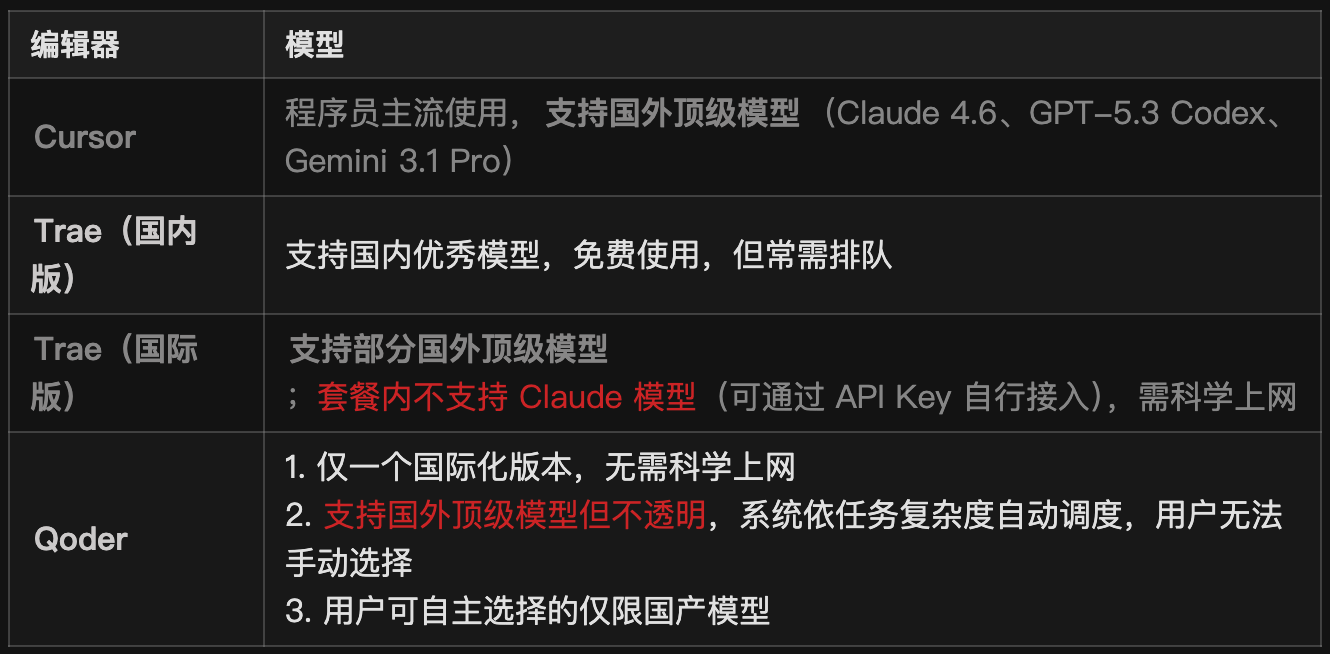
从上面表格中可以看出,支持模型最全面且能自由选择的当然是 Cursor。
CLI 工具
然后就是 CLI 一类的工具,大家耳熟能详的就是 Claude code、Codex,它们就没有可视化的操作界面,交互形式是通过在终端输入命令进行交互的。
这里选择的逻辑就很简单了,如果是 Claude Code 的订阅用户那就用 Claude Code,如果是 ChatGPT PLUS 订阅用户,那就用 Codex。
如果都不是的话,又想使用CLI,那就选择 Claude Code,至于如何用后面章节会说。
模型选择
工具的选择不重要,但是模型一定很重要,模型才是 AI 编程的灵魂
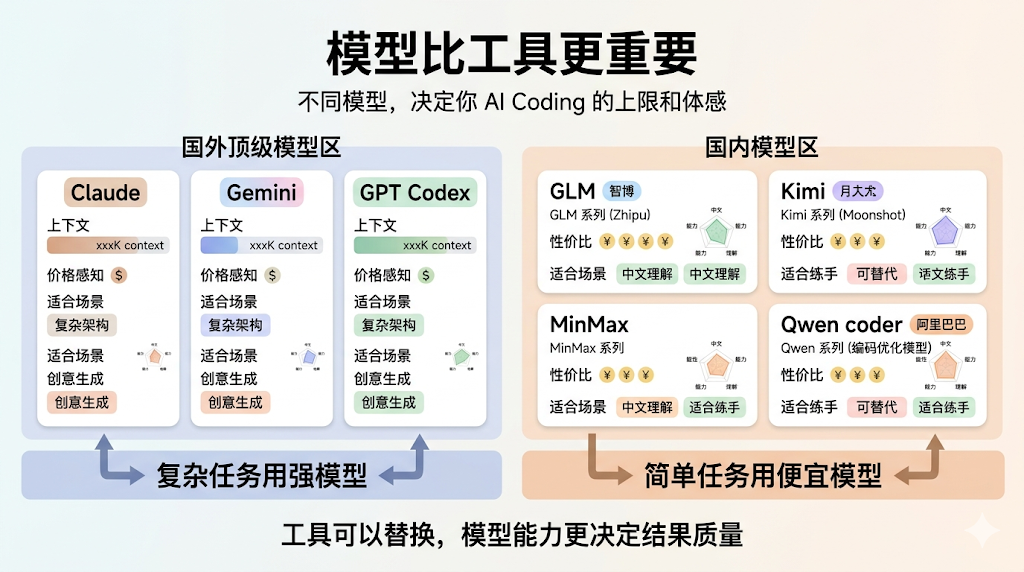
我们先看国外顶尖模型 Claude、GPT、Gemini,的一些核心参数:
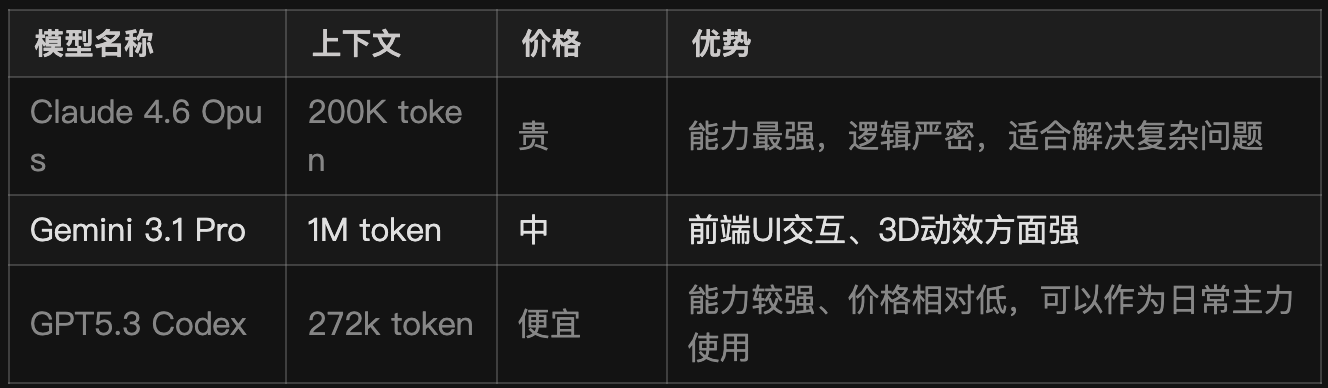
当前编码能力最强的模型是 Claude4.6 Opus / Sonnet,用这种顶级的模型,可以帮我省很多的时间,减少调试和来回沟通的成本。
只不过,它唯一的缺陷不是太贵,而是这家伙有点傻逼,喜欢封号!
如果确实想用Claude 的模型,可以考虑使用中转API,价格相对官网更便宜,额度也更多,但是存在不稳定的风险、速度相对更慢,模型存在以次充好,因此需要谨慎选择,建议一次性不要充值太多。
再看国内模型:
国内优秀模型:智谱的 GLM5、月之暗面的 Kimi k2.5、MinMax m2.7、Qwen3-coder 其实都挺不错的。
对于价格敏感或者有境外模型使用限制,虽然效果距离国外顶级模型仍然有一定差距(现阶段看起来很大,但代差几个月就没了),但是对于简单的功能开发,基本没啥问题,毕竟大家的目的是学习 AI Coding,又不是要翻天。
现在国内大模型厂商和云厂商都在推 Coding-Plan 套餐,性价比很高,且量大管饱,很适合作为尝试 AI Coding 的初始选择。
但模型厂商的套餐有个限制,只能使用他们家的模型。
相对而言,云厂商推出 Coding-Plan 套餐更有优势,可以使用多种模型,比如火山引擎的 Coding-Plan 国产主流的编程模型都能使用。
我日常是组合使用,因为 Claude Code 订阅的 Token 不够用,然后会使用国产模型作为备用,简单的任务就使用 GLM4.7/GLM5,复杂的任务或者方案设计等就用 Claude4.6 系列的模型。
PS:我个人现在编码量不大,但各位因为是学习目的,也不应该太大
接下来就是各位认为最有门槛和压力的地方了,其实他毫无难度:
编程通识
我们在做一个工具或者产品时,首先要明确一件事:它的产品形态是什么。
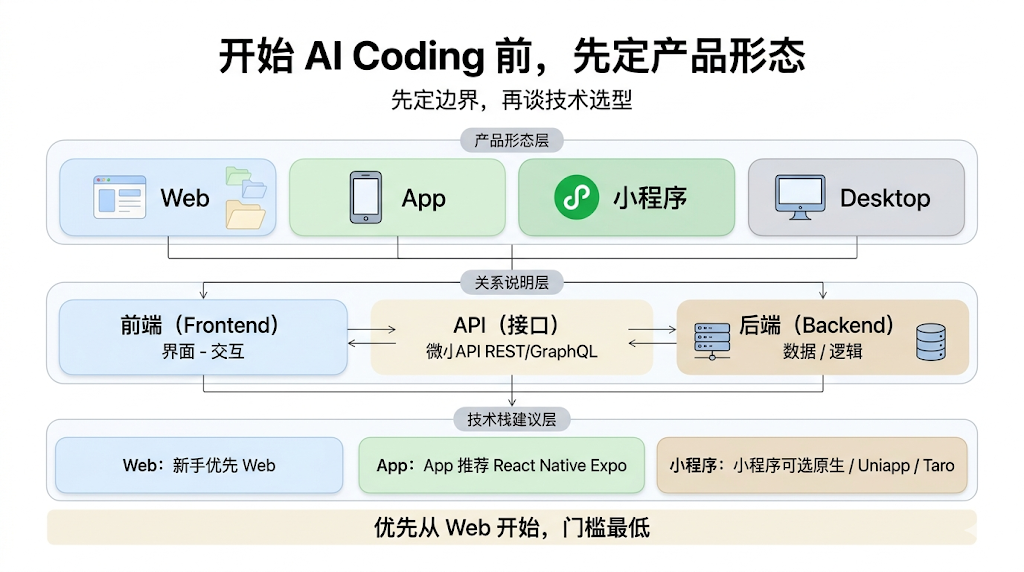
比如是 Web、App、桌面端应用、小程序、浏览器插件等。
因为产品形态不同,对应的技术栈选择会不同,程序的运行环境不同,调试工具也会有差异,最终的发布流程都会不一样。
这一点在 AI Coding 中其实很关键,因为你需要先给 AI 一个清晰的边界。如果一开始没有定义清楚产品形态,AI 很容易在技术选型上发散,甚至做出一套完全不符合你预期的实现方案。
其次,需要有一个基础认知:这个工具是纯前端就能搞定,还是需要后端能力,对于非技术同学来说,这部分不需要深入理解,建立一个基本概念即可。
一个完整的产品,通常由前端和后端组成。前端是用户可以看到和操作的界面;后端负责处理数据、业务逻辑、权限控制,以及调用AI等能力,两者通过接口(API)进行交互,也就是说没有数据要存,可能前端就搞完了。
无论你的产品最终是 Web、App 还是小程序,后端通常都是一套通用逻辑,而变化最大的其实是前端。也就是说,后端可以服务多个终端,而前端需要根据不同平台分别实现。
技术栈建议
下面我直接给建议,大家直接参照即可:
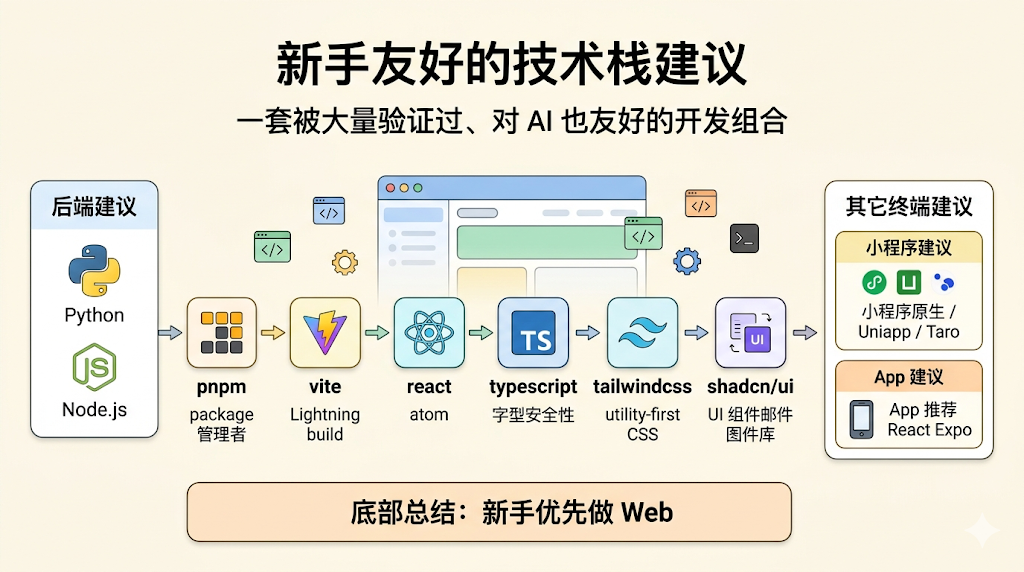
后端技术栈建议使用 Python 或 Node.js,这两者对 AI 都非常友好,生态成熟,环境依赖简单,AI 生成代码的质量和稳定性也更高。
前端 Web 技术栈推荐使用 pnpm + vite + react + typescript + tailwindcss + shadcn/ui。这是一套已经被大量验证过的组合:vite 启动和构建速度很快;react 是当前最主流且 AI 最熟悉的前端框架;typescript 可以减少低级错误;tailwindcss 对 AI 最为友好的 css 方案;shadcn/ui 避免重复造轮子,对AI友好,能感知到组件内部的实现逻辑;
前端小程序这块,如果不考虑跨端,直接使用原生开发即可,简单直接、稳定性最好。如果有跨端需求,可以选择 Uniapp 或 TaroJS,用一套代码适配多个平台,比如微信小程序、支付宝小程序。
App 开发这块,非常不建议新手使用原生语言(比如 iOS 的 Swift、Android 的 Kotlin 或 Java)。因为 iOS 和 Android 是两套完全不同的技术体系,一旦走原生路线,你需要维护两套代码,开发、调试和构建成本都会非常高。
更推荐的方案是使用 react-native 的 Expo,这套方案可以用一套代码同时支持多个平台,调试、预览和构建流程也非常简单,不需要折腾复杂的开发环境。
综上,我的建议是:优先从 Web 开始做项目,因为门槛最低、调试最简单、成本也最低。当你有明确的场景需求时,再去考虑小程序或者 App。
工具通识
无论我们选择的工具是编辑器(IDE)还是命令行(CLI),都离不开 MCP 的接入与配置、Skill 的使用、记忆文件的管理,以及上下文的管理。
它们并局限于某一款具体工具,而是具有通识性的基础知识,理解它们有助于我们更加高效的使用这些AI编程工具。

安装 MCP 扩展工具能力
MCP 是什么前面有系列文章,这里不再赘述,对应到编程场景下,MCP 能够帮我们解决哪些问题,有哪些 MCP 值得我们安装?
其实,对应到传统软件开发流程中的每个环节,我们都可以借助 MCP 来扩展编程工具的能力。
比如:

这里仅列举了一部分常见场景,其它的场景大家可以自行探索。
目前主流的三方工具平台基本上都已经支持 MCP 服务,因此,凡是需要依靠我们手动去操作的场景,我们可以先想想是否能接入 MCP 服务,让 AI 与外部系统进行交互,实现自动化处理。
至于安装配置就很简单了,如果使用的是编辑器(IDE),通常会有 MCP 市场或可视化配置界面,如果是命令行(CLI)工具,建议通过 CC-Switch 来安装,也是可视化的操作界面。
至于具体的配置方法,参照 MCP 文档说明配置即可。
需要注意的是,不建议大家一股脑的安装很多不常用的 MCP,最好根据自己需要按需安装。
因为,MCP 工具会常驻上下文空间,每一次会话,我们安装的 MCP 提供的所有工具方法,都会作为上下文发送给大模型。
如果 MCP 安装过多,我们实际可以使用的上下文空间将会减少,并且非常消耗我们的 Token。
下面以Claude code为例,打开一个新的会话,在没有任何历史上下文的情况下,MCP就占据了 10% 的上下文空间,还有其它系统提示词和系统工具的占用,我们真正能使用的上下文空间只有 80%:
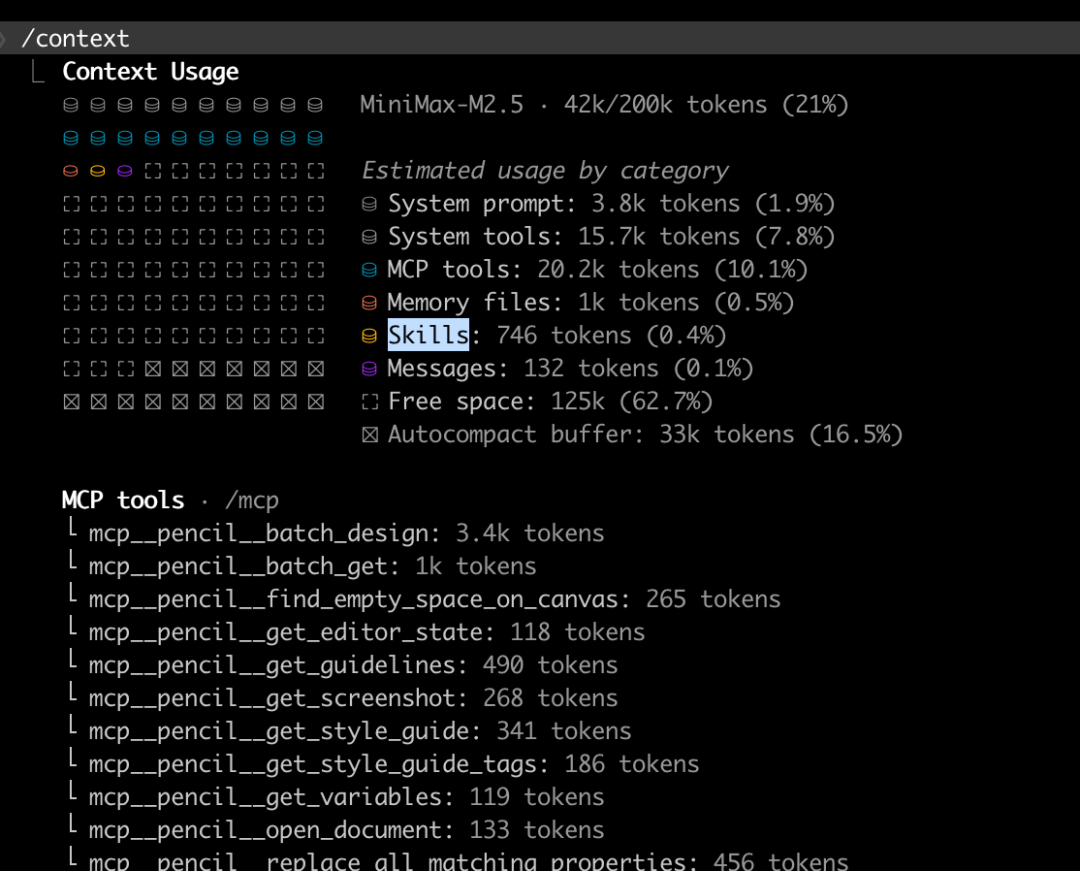
因此,在安装 MCP 时要注意节制。
安装 Skills
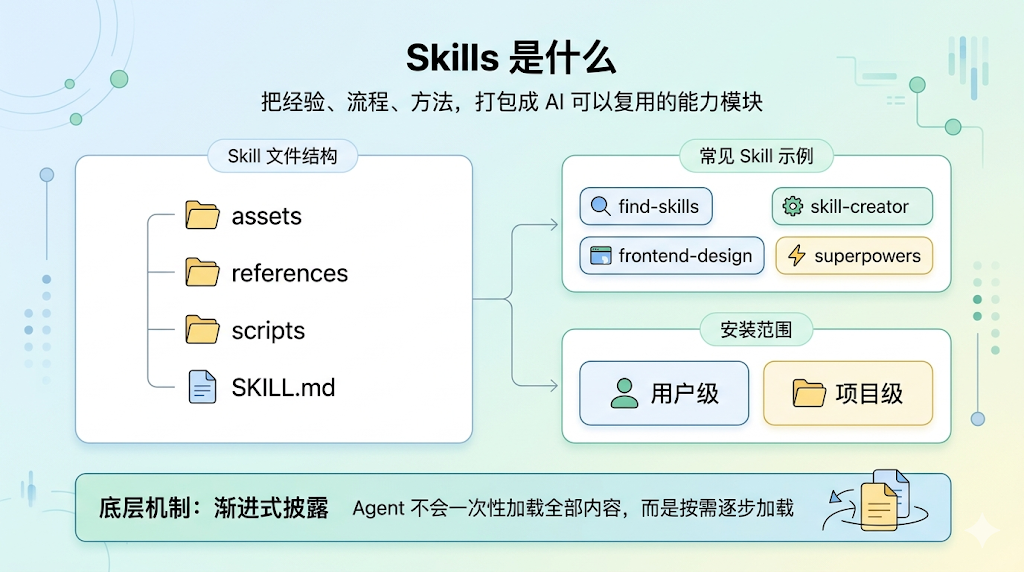
Skills 就是把我们的经验 + 流程 + 方法,打包成一个 AI 可以反复使用的专业能力模块。它跟 MCP一样,都是出自 Anthropic 公司,一个 skill 大致按照如下结构进行组织:
my-skill/
├── SKILL.md # 【必选】使用说明 + 元数据
├── scripts/ # 【可选】可执行代码
├── references/ # 【可选】参考文档
└── assets/ # 【可选】模板、资源文件
它有个最大特性就是渐进式披露,Agent 不会一次性把整个 skill 的内容加载到上下文中,每次携带只是所有 skill 的元信息,大模型明确了需要使用某个具体的 skill 时,才会依次加载这个 skill 中的内容或者脚本执行。
现在各行业的 Skills 非常的多,对应到编程场景下,我们仍然从实际使用场景出发,需要什么才安装什么。下面我看看一些对于我们非常有用的 Skill,以下几个是我认为比较重要的:
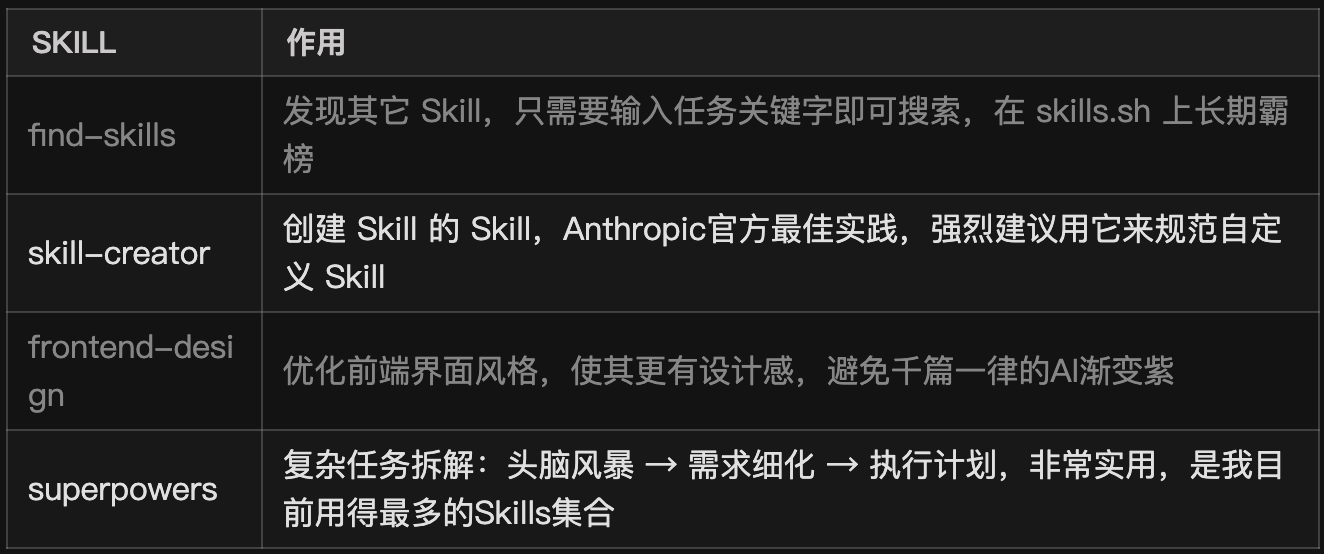
除此之外,大家也可以在下面的资源网上自行探索,这些网站上可以发现很多高质量的Skill,但还是要注意前面说的一个观点:从实际场景出发,按需安装,不要追求多。
尤其是类似功能的Skill,仅保留一个即可,如果安装多个,在执行时可能会存在冲突的情况,也会增加Agent的选择成本:
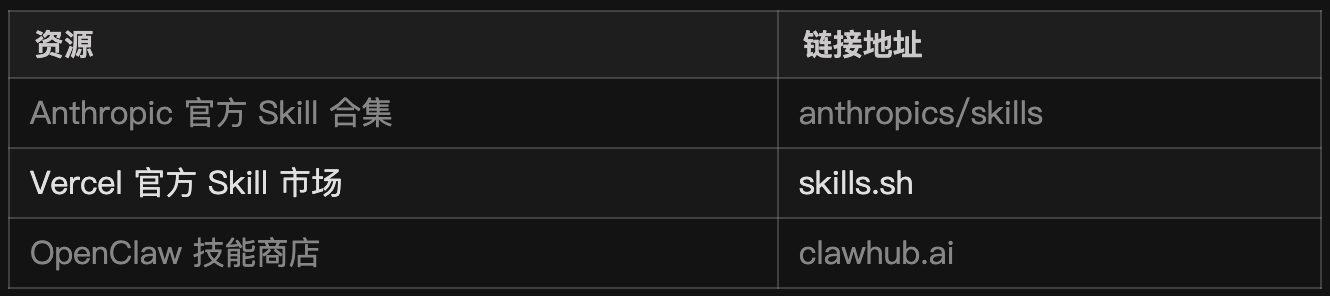
Skills 的安装方式有很多种,每种编程工具的安装方式都可能会有差异,这里介绍两种适配所有工具的安装方法:
- 通过 vercel 的 npx skill 命令来执行安装
- 通过 CC-Switch 来安装 Skill
在安装 skill 时,需要注意安装范围,分为用户级和项目级,用户级是指所有的项目都能使用这个 skill;项目级是指仅在这个项目中能使用,其余的项目是无法使用的。它们对应的安装路径为:
- 用户级skill~/.claude/skills~/.agent/skills
- 项目级skill[project_name]/.agent/skills[project_name]/.claude/skills
这里的建议是:对于通用的 skill 或高频使用的 skill 都建议安装到用户级,这样只需要安装一次,所有项目都能用;对于特定项目才会用到的 skill 就安装到项目中。
然后 skill的使用就很简单了,也分为两种形式,一种是显示触发,在会话中输入/[skill-name];另外一种就是自动触发,只需要通过自然语言描述任务即可,Agent 会自动调用对应的 skill。
让工具记住我们的规则
每种 AI 编程工具都支持规则的配置,只是存放的文件位置不同,下面表格列出了主流编程工具的规则文件存放路径:
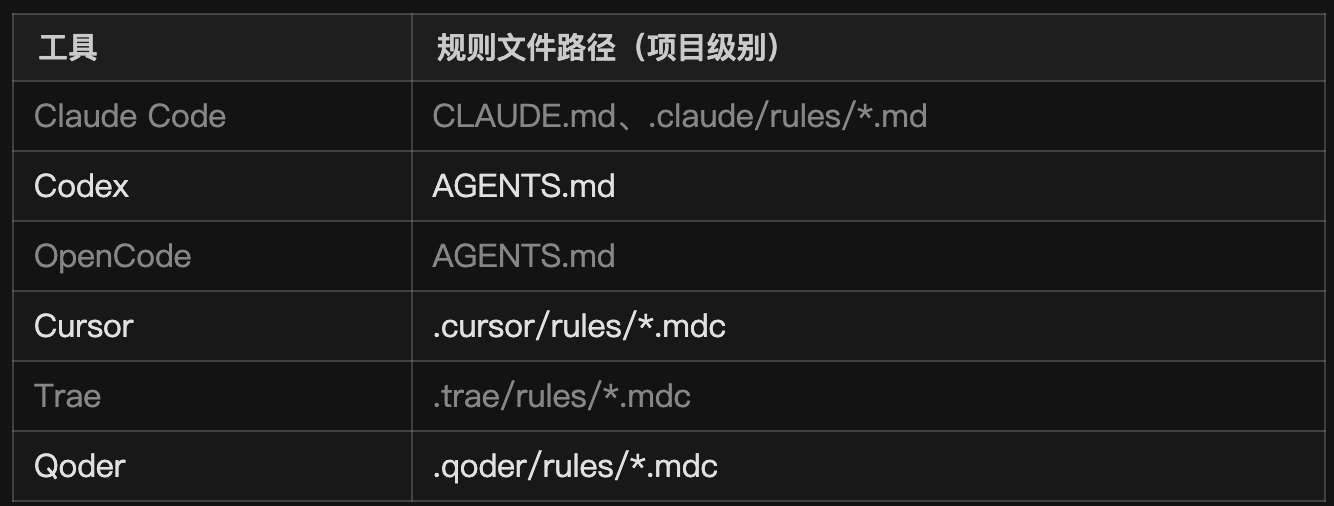
尽管形式不同,但它们作用都是一致的:让 AI 记住我们的项目规则或者个人偏好,比如代码风格、命名规范、输出格式、技术选型、团队约定等,从而在多轮交互中始终保持稳定。
那这些规则是怎么生效的呢?
其实也简单,在每次会话启动时,工具会自动读取对应的规则文件,并把内容加载到上下文窗口中,作为系统提示词的一部分,在整个会话期间持续存在。
了解完这些基本信息之后,我们在看这些规则中应该写什么?
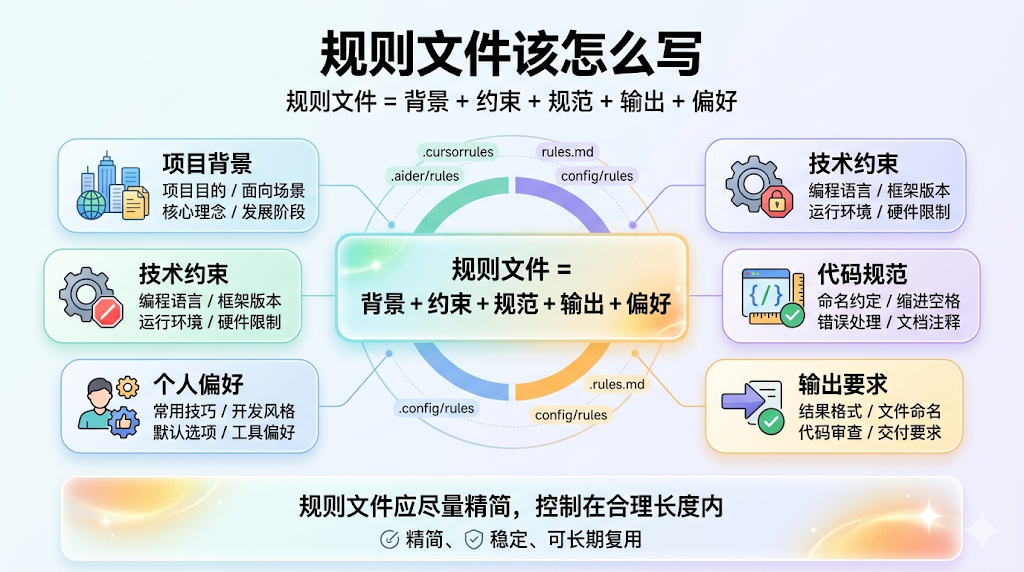
我总结的一套公式为:规则文件 = 背景 + 约束 + 规范 + 输出 + 偏好。
- 项目背景,让AI知道你在做什么,你的目标是啥
- 技术约束,明确项目使用的技术栈,防止AI自由选择
- 代码规范,定义命名方式、类型要求、组件长度、注释规范等
- 输出要求,约束输出内容结构和格式
- 偏好,让AI贴合个人或者团队习惯
举一个例子,仅供参考:
# 项目背景
# 技术约束
– 前端技术栈:pnpm + vite + typescript + react19 + tailwindcss + zustand + axios
– UI组件库使用shadcn/ui,不要重复造轮子
– 后端服务使用Supabase# 代码规范
– 使用 ES modules (import/export),不使用 CommonJS (require)
– 函数名使用 camelCase,组件名使用 PascalCase
# 工作流
– 提交前必须运行类型检查:npm run typecheck
– 测试命令:npm run test
– 优先运行单个测试而不是整个测试套件
# 输出要求
– 我不会看代码:因此不要给代码加注释,也不要生成组件说明文档,除非我特别要求
– 完成任务时,简单总结即可,不要长篇大论
– 不要留TODO
# 偏好
– 始终使用中文回复我
在 Claude code 中,我们可以直接使用/init初始化项目的规则,尤其是对于已经存在的项目很友好,CC 会自动去分析当前项目的情况,把项目的技术栈 + 规范 + 架构设计 更新到规则文件中,在此基础上,我们在做二次修改。
而其它工具也是类似,有些工具可能没有提供这样的系统指令,但是我们可以直接在对话中让 AI 帮我们生成规则文件。
需要注意的是,规则文件应该尽量保持精简,建议只保留需要频繁向大模型说明的内容,总行数最好控制在100行以内,如果内容太多,可以利用子目录的形式进行分发。
主动管理上下文
不同的模型有不同大小的上下文限制,当我们的上下文超过这个限制之后,内容将被截断,AI处理问题的能力表现将会下降。
因此,各类 AI 编程工具在上下文管理方面做了很多工程化的方面的设计。
每种工具处理方式不同,有的工具超出上限时会停止工作,界面提示“上下文已满”,有的工具会自动压缩历史内容,以维持持续的工作。
但是无论工具采用那种处理策略,我们都需要有主动管理上下文的意识。要做到这点,我们先理解一次会话的信息构成:
初始 Token 组成:初始输入 = 系统提示词 + 系统工具 + MCP工具 + Skills + 用户问题 + Rules + 对话历史
用户问题 : 我们输入的文字 + 主动添加的上下文(图片、项目目录、文件)
Rules: project rule + user rule + memories
模型收到输入后,还会进一步调用工具获取更详细的信息:实际参与推理的 Token = 初始输入 + 所有工具调用结果
因此,我们只输入了一句很短的提示词,但是最终真实参与推理的 Token 可能高达数万,并且随着对话轮次增加,大模型输出的内容也会加入到上下文中,作为下一轮的输入,跟滚雪球一样,上下文体积越滚越大。
每个会话是一个独立上下文空间,一个会话中多轮对话共用的是同一个空间。
在AI编辑器(IDE)中,我们可以新建会话,也可以查看到每个会话当前上下文的占用和剩余空间。
在 Claude code 这类 CLI 中,新开会话是通过 /clear命令。
如果需要查看当前会话上下文占用情况,可以通过 /context命令,但是这种方式不够直观,我们可以通过/status-line命令自定义状态栏显示的信息,把上下文占用空间显示在会话输入区域下方,实时可见。
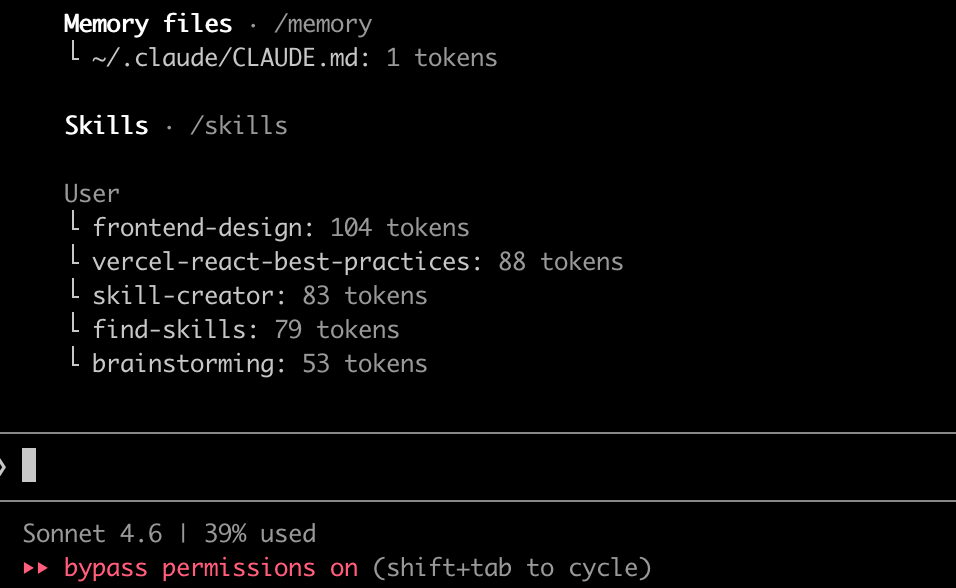
很多新手常常会在这里犯错,将所有的任务都堆在一个会话中进行,导致上下文占用一直处于高位状态,这会带来两个明显问题:
一是上下文中的冗余信息会分散模型的注意力,降低回答质量;
二是 Token 消耗会很大,增加使用成本;
因此,非常建议:
独立的任务使用独立会话, 不同类型或目标的任务分别开启新的会话。
如果当前会话的上下文占用达到 60% 时,就应考虑新建会话,避免后续性能下降。
如果一个任务的上下文占用超过60%了,但是任务还没有完成,这里有两种处理方案:
压缩当前会话上下文,Claude Code可以使用/compact命令,编辑器类工具点击”压缩上下文”按钮,在当前会话内继续工作。
让 AI 把当前任务进度、已完成内容、待解决问题整理成一份交接文档,然后在新会话中基于该文档接续工作
新手友好的最佳实践
下面我们在看 AI Coding中,已经被反反复复验证的一些最佳实践:
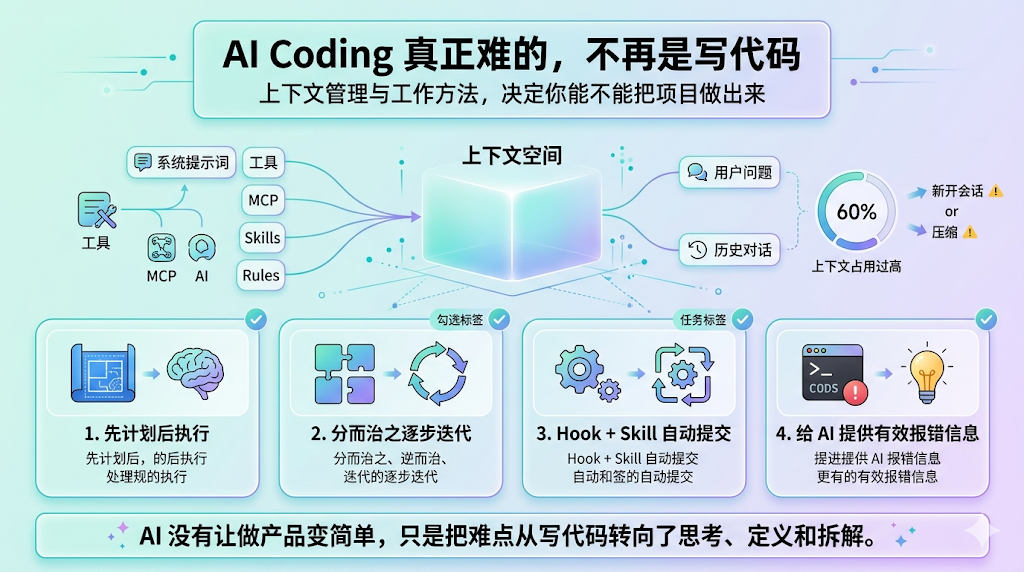
先计划,后执行
在让 AI 开始干活之前,先把需求聊清楚、把实现方案对齐。
很多时候,我们给出的描述是有歧义或信息不完整。如果一上来就直接让它写代码,十有八九结果都会偏离预期。
尤其是需求模糊时,AI 经常会自己脑补细节、替我们做决定,最后我们还得花时间纠正它,来回沟通很耗精力,也白白浪费 Token,尤其使用Claude 4.6 Opus这类模型,浪费的都是钱啊。
在需求澄清阶段,AI 会反过来问我们一系列问题,帮我们把遗漏的信息补齐,让需求变得更清晰。
同时它也会给出实现方案,我们可以先看看这个方案是不是我们想要的。如果发现哪里不对,就及时调整;确认没问题后,再让它基于已经澄清好的需求和方案去执行实现。
这样的好处是,一次性成功的概率会高很多,整个过程也更加受控,而不是被AI牵着走。虽然需求澄清阶段需要耗费一些时间,但是整体效率其实更高。
在Claude code中,我们可以切换到Plan模式,使用方式如下:
- 快捷键,在 Claude Code 终端中:Shift + Tab,终端底部会显示 plan mode on, 表示进入 Plan Mode。
- 使用/pan指令,在聊天框里面直接输入:/plan 为项目添加用户登录功能
其它工具也是类似,都有计划模式。
除此之外,这里也非常推荐一个Skill:brainstorming,它是suppowers技能集合中的一个Skill。它的工作流程如下:
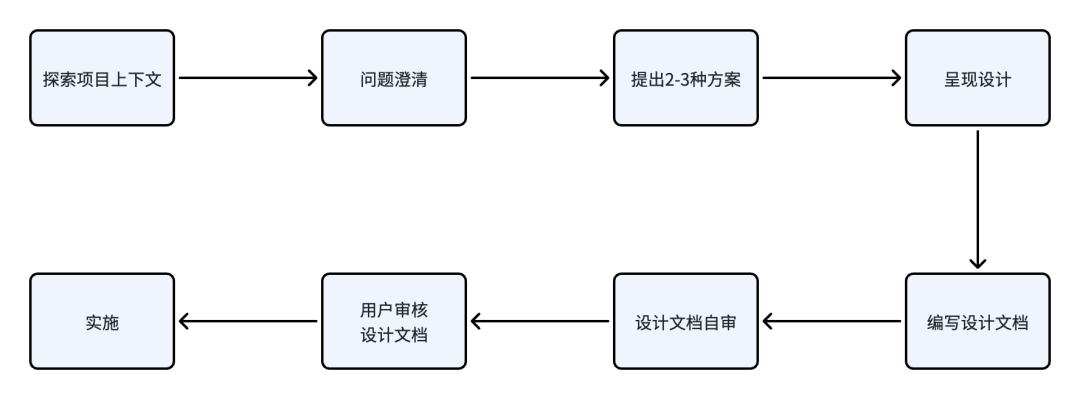
这个skill在问题澄清阶段,我的感受是比AI编程工具默认提供的计划模式问得更加细致并且每个问题都很关键,只是整体的交互流程耗时更长,但是是非常值得的。
这其实也非常符合AI Coding新的编程范式,我们应该聚焦在需求的定义、方案设计上
当然这种方式会增加token开销,对于需求明确或者很小的任务,我们可以直接使用普通模式。
分而治之,逐步迭代
在实践中我们发现,一次性让AI实现一个很大或者复杂的需求,实现的效果往往很差,容易留下很多TODO,产生bug,而且 AI 特别容易基于错误堆错误(将错误的代码作为上下文继续制造错误),最终陷入怎么做都做不对的死循环。
针对这种情况,我们通常的做法是需求拆解、逐步迭代,把大需求拆分成多个小需求,每个需求尽量独立,呈递进关系,然后把每个任务使用新的会话,让AI依次实现。
拆分的任务颗粒度越细,AI 完成度和质量越高, 同时也更利于人为审查和把控,问题出现时也更容易定位和修正。
利用Hook + Skill 自动Commit,防止改乱
新手在做 AI 编程时,一定会遇到这样的问题:好不容易实现了某个功能,却在下一次会话中被 AI 改坏了。因为没有版本记录,也看不懂代码,就无法手动还原,只能从头再来。
为此,建议通过 Git 频繁提交来管理版本。
核心思路很简单:每完成一个最小可运行的功能,就立即提交一次,而不是等所有需求都做完再统一提交。
这样一旦 AI 改坏了已有功能,我们也不用慌,直接回滚到上一个提交记录即可,无需手动一点点排查、重写甚至凭记忆还原。
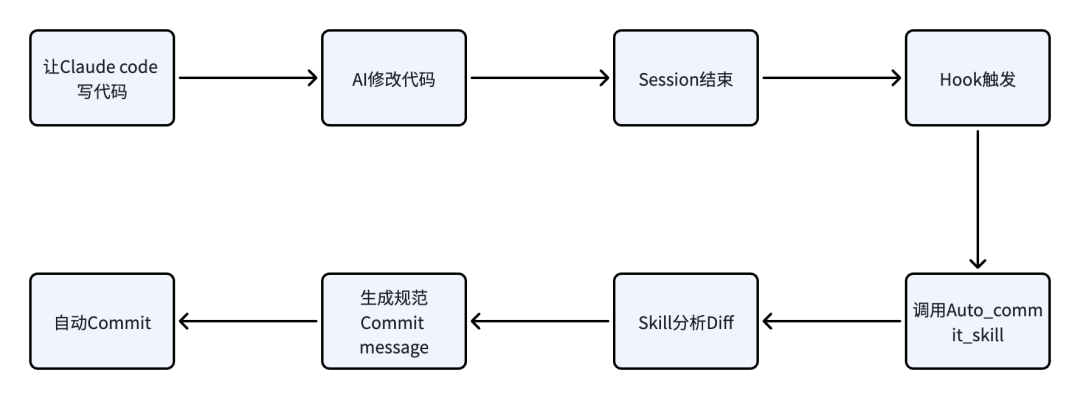
但频繁手动提交太过繁琐。在AI编程工具中,我们可以借助 Hook 机制来解决这个问题——每次会话结束后自动触发提交,整个过程无需任何手动操作。
那如何做呢?
这里以 Claude code 为例,其它的编程工具也是类似,我们直接让claude code 帮我们在当前项目中完成配置,可以这样跟它说:
请帮我在当前项目中配置 Claude Code hook,利用Hook + Skill来实现每次会话结束后自动提交代码
AI会帮我们自动完成配置,后面每次会话完成后,如果有代码修改,就会自动提交代码。其中hook决定在什么时机触发Skill的执行,而Skill则是负责具体做什么、如何做。
整个工作流机制如下:
给予有效的错误反馈
在AI 完成任务后,我们通常会在界面上进行功能验收。但很多时候,界面本身并不会提供足够清晰的错误信息。如果只是将这些模糊的反馈直接提供给 AI,往往难以准确定位问题,它大概率也修复不对。
实际上,浏览器中自带了开发者工具,这是获取详细错误信息的重要入口。通过开发者工具中的控制台(Console)或网络请求(Network)面板,可以查看更原始、更完整的错误信息,例如报错堆栈、接口返回内容以及接口请求状态等。
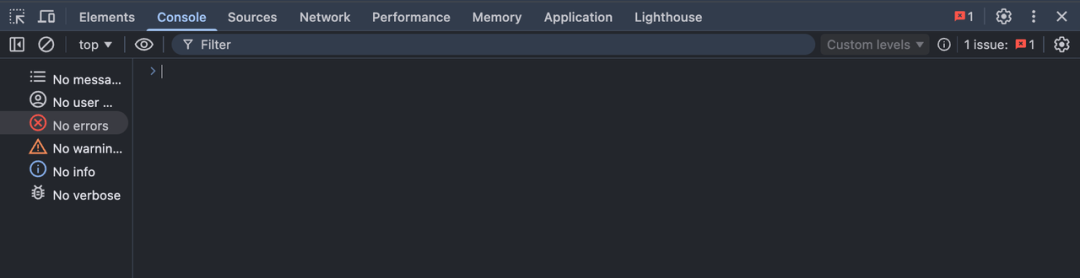
这些信息对于问题定位非常关键,可以明显提高一次性修复问题的成功率。
因此,在进行 Web 应用开发时,建议始终开启开发者工具。当出现报错时,优先从控制台或网络面板中复制完整的错误信息,再交给 AI 进行分析和处理。这样可以有效减少反复沟通,提高整体开发效率。
结语
到这里,篇幅已经很长了,具体实践案例我们下来再继续。
这里有个问题大家也可以思考下:在 AI 的协助下,我及身边的小伙伴效率都在 100% 的提升,但我们明显更累了,这是什么问题呢?
我们是认为 AI 并没有让“做产品”这件事变简单,而是把难点从“写代码”,转移到了“如何思考问题、定义需求和拆解任务”。
反正所有的结果就是,需要动脑子的地方变多了…
工具会越来越多,模型也会越来越强,但这些都只是放大器。真正决定结果的,依然是你是否能把一个模糊的想法,讲清楚、拆明白,并持续推动它往前走。
所以,与其反复纠结用哪个工具、选哪个模型,不如开始动手做一个自己的小项目。在实践中,你会自然理解工具之间的差异,也会逐渐建立起自己的 AI Coding 方法论。
所以,加油吧…
本文由人人都是产品经理作者【叶小钗】,微信公众号:【叶小钗】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


