
 起点课堂会员权益
起点课堂会员权益从一张白纸到交付PRD:我的全自动 AI 产品工作流
AI正在重塑产品经理的工作方式——从单打独斗到与AI深度协作。本文揭秘如何通过问题拆解、思维训练和工作流沉淀,让AI真正成为你的产品搭档。看如何从权限边界到状态流转,让AI在PRD撰写、原型绘制等环节实现精准输出,最终释放你的决策判断力。

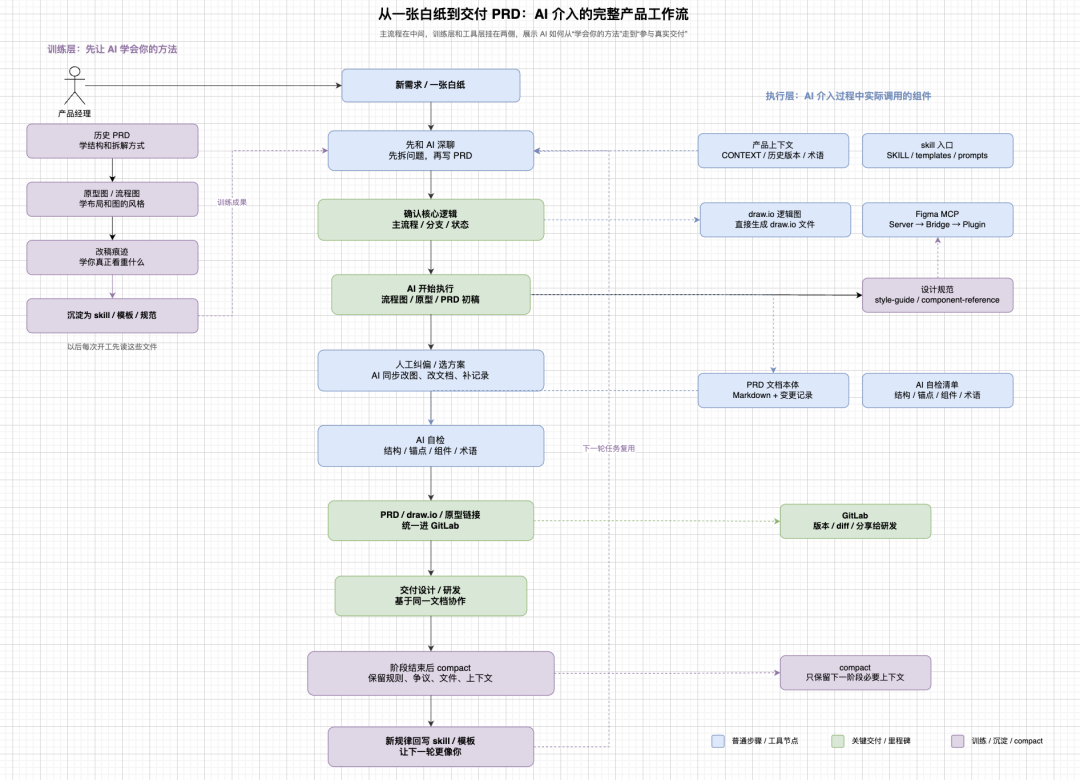
现在,一个新需求的启动,我最先打开的通常不是 Figma 或文档,而是先与 AI 来一场深度对话。
这里的目标并非让它立刻“写一份 PRD”,而是先把问题聊透:需求到底在解决什么?真正的约束在哪里?哪些看似是页面设计的问题,其本质却是权限、数据口径、状态流转或版本边界的问题?
当这些讨论清晰,AI 才开始接手执行:撰写文档、绘制原型、补充流程图、整理变更记录;人的角色则转变为追问、纠偏和做决策。渐渐地,产品工作就不再是单枪匹马地拼凑信息,而是演变为一场持续推进的对话。
以下是我最近1个月沉淀出来的AI PRD的落地过程:从训练层到执行层,一步步渐进式实现。
这篇文章想要分享的,并非“AI 节省了多少小时”。
更重要的变化在于——在同等时间内,可以与 AI 讨论得更深,拿到更完整的信息,提前暴露更多边界,从而做出更优的决策。过去依赖个人经验的环节——翻竞品、补调研、写初稿、开评审、等返工——并没有消失,而是被前置、被加速,并且有了一个熟悉你工作方式的搭档全程参与。
这套方法并非凭空设计,而是在真实项目中一点点迭代出来的。AI 不是在“一次性生成”,而是在多轮讨论、推翻与校对中,真正学会了如何按你的方式工作。
一、从生成答案到“拆解问题”
刚开始用 AI 写 PRD,极易落入一个误区:把它当成一个高效的文字生成器。这样做虽然能得到一份看似完整的文档,但通常有两个致命伤:第一,文字像样,逻辑不一定扎实;第二,文档写完了,真正需要讨论的核心问题,才刚刚浮现。
AI对于产品经理的首要任务不是让 AI 产出答案,而是让它辅助拆解问题。这个步骤看似朴素,却几乎决定了最终产出的文档,究竟是“看起来像PRD的文字”,还是一份真正能驱动研发协作的有效文档。
比如,在最近我们在迭代 XX Agent 产品中(一款SaaS订阅制产品),需要处理多角色、多站点访问及新用户试用。表面看,这像是在做“站点切换器”和“成员邀请”的小功能,但与 AI 深入讨论后,问题迅速被指向了更底层:
- 角色绑定:角色是绑定在账号层,还是站点层?
- 身份共存:同一账号能否既是自有站点的拥有者,又在他人站点里担任成员?
- 额度归属:成员在共享站点里发起分析,消耗的是谁的额度?
- 新用户路由:新用户登录后,是进入自己的空站点,还是一个预置了数据的示例站点?
- 入口显隐:“创建站点”的入口是永久显示,还是仅对特定角色可见?
这些问题若不预先厘清,PRD 极易写成“点击按钮、弹出窗口、页面跳转”的表层描述。而真正的风险在于,如果研发实现过半才发现,权限判断、额度归属、默认路由、空状态、示例数据和导航结构,那早已盘根错节。
因此,一个固定的工作习惯逐渐形成:新需求启动时,先不写 PRD,只与 AI 共同梳理问题。
一个典型的起手提示词如下:
先不要写 PRD。
你的任务是拆解这个需求,重点审视三件事:
业务规则可能绑在哪一层,哪些定义尚不清晰。
页面上每个动作背后依赖什么权限、状态或数据条件。
哪些边界场景若现在不讨论,未来一定会返工。
最后,请输出三份清单:
一份“待决策问题列表”。
一份“潜在争议方案列表”。
一份“直接动笔最易出错点”的预警。
这一步完成后,得到的并非一份答案,而是一张“问题地图”。沿着这张地图往下走,再去构建文档和原型,整件事的根基会稳固得多。
二、如何训练 AI,让它“像你一样思考”
当协作流程稳定后,关键不再是 prompt 写得多华丽,而是AI 是否真正学到了你的做事方式。这里的“像你”,不止是文风相似,更重要的是结构像、拆解方式像、改稿逻辑像。换言之,它不仅要写得像,还要改得像。
最初刚开始,我也尝试过每次对话都重新解释规则,但很快发现这种方式极不稳定。更有效的方法,是直接将过往的优质产出打包喂给 AI,让它自行总结、抽取规律,再回写成规则。
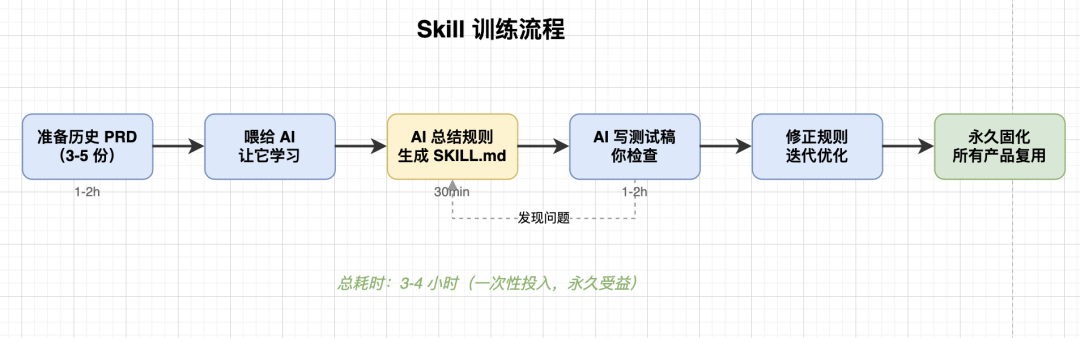
训练素材的价值排序如下:
- 历史 PRD:价值最高,因为它同时蕴含了业务拆解、文档结构和表达习惯。
- 真实原型图:价值次之,它教会 AI 如何组织页面布局、状态和交互区域。
- 流程图与逻辑图:帮助 AI 学习你的抽象粒度和叙事逻辑。
- 变更记录:最易被忽略,却是精髓所在。它反向揭示了你最在意的标准是什么。
“变更记录”是让 AI 从“模仿”走向“理解”的关键。只喂最终稿,AI 学到的是结果;而喂给它从初稿到终稿的演变过程,它才能学到判断力。
比如,看到“点击后跳转”被反复修改为包含“目标页面、参数保留、异常处理、成功反馈”的详尽描述,AI 才能真正理解,什么叫“研发能直接执行的需求粒度”。
训练流程通常分三步走,更像带新人,而非写指令:
- 喂养样本:让 AI 总结结构、词汇和风格偏好。
- 验收测试:让它生成一份某一具体业务模块的文档或原型(如“邀请成员弹窗”)来检验学习成果。
- 规则沉淀:将测试中发现的偏差,回写为具体规则,固化到 skill 和模板中。
一个好的测试用例,能轻易暴露 AI 的真实理解水平。如果它只写出“填写邮箱后发送邀请”,说明只学了皮毛;如果它能将弹窗的触发条件、角色边界、字段校验、多重反馈等一一拆解清楚,才算真正“上道”。
这个过程中,最有价值的一步是“让 AI 自己复述它理解的规则”。只要它能用自己的语言清晰地阐述规则,就证明它真正内化了你的方法。
三、把方法沉淀为工作流
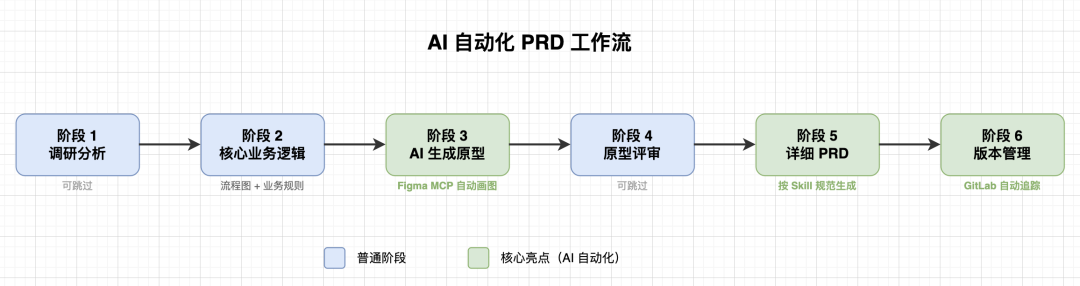
当 AI 开始“像你”之后,下一步就是将这套方法沉淀为稳定的工作流,摆脱临时的、碎片化的指令。
以下图为例,这是我目前真实的一套skill文件:

在实际业务中,一个成熟的自动化链路通常是这样的:
- 上下文读取:首先加载产品上下文,理解当前版本、术语、历史约束和目标。
- 逻辑梳理:接着梳理核心业务逻辑,必要时生成流程图或状态图。
- 原型构建:然后生成页面原型,此时不急于填充细节。
- 文档撰写:原型结构确认后,再撰写详细的 PRD。
- 版本维护:后续所有修订,直接在原文档上维护变更记录。
这个流程有个关键变化:PRD 不再是起点,而是逻辑和结构讨论清晰后的交付物。
为了让这套链路顺畅运转,需要一套工具链的支撑。以下是我搭建的一套工具流:
入口(Claude Code CLI / Codex CLI):它的价值在于能直接在项目目录中工作,让 AI 读取 skill、上下文、历史 PRD 和版本库,实现真正的“情景感知”(最近CC总是挂,感觉Codex也不错~)。
原型工具(Figma + MCP):成功的关键并非“AI 随便画个图”,而是预先定义好设计规范和组件库。有了约束,AI 生成的才不是草图,而是风格统一、结构合理的设计稿。
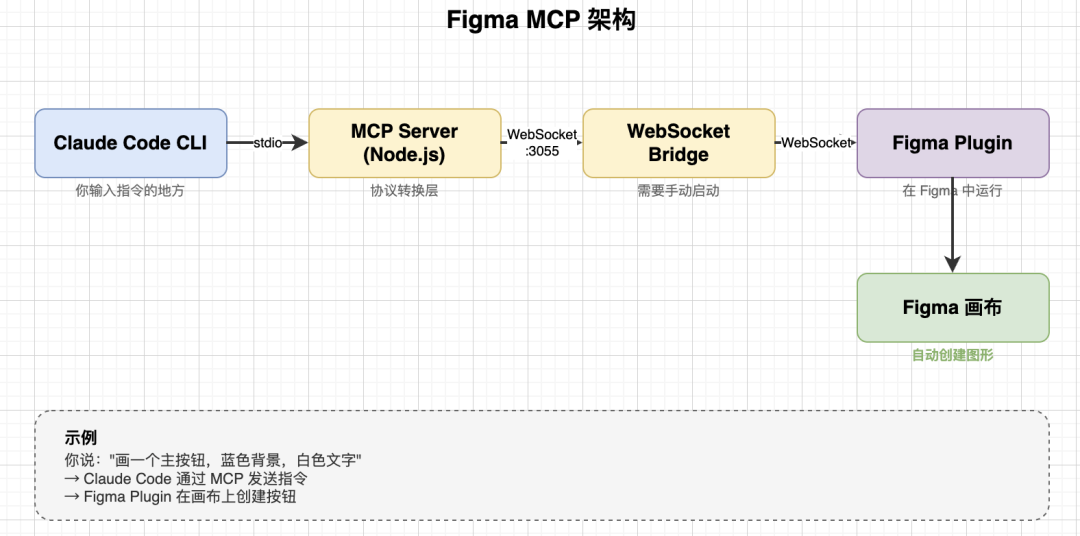
这里我用的是Claude Talk to FIgma这款MCP,通过自然语言就可以直接让AI去画好Figma图了。但是注意——最好先让AI用markdown格式在本地画好,你确认后再上Figma,这能节约很多token量。
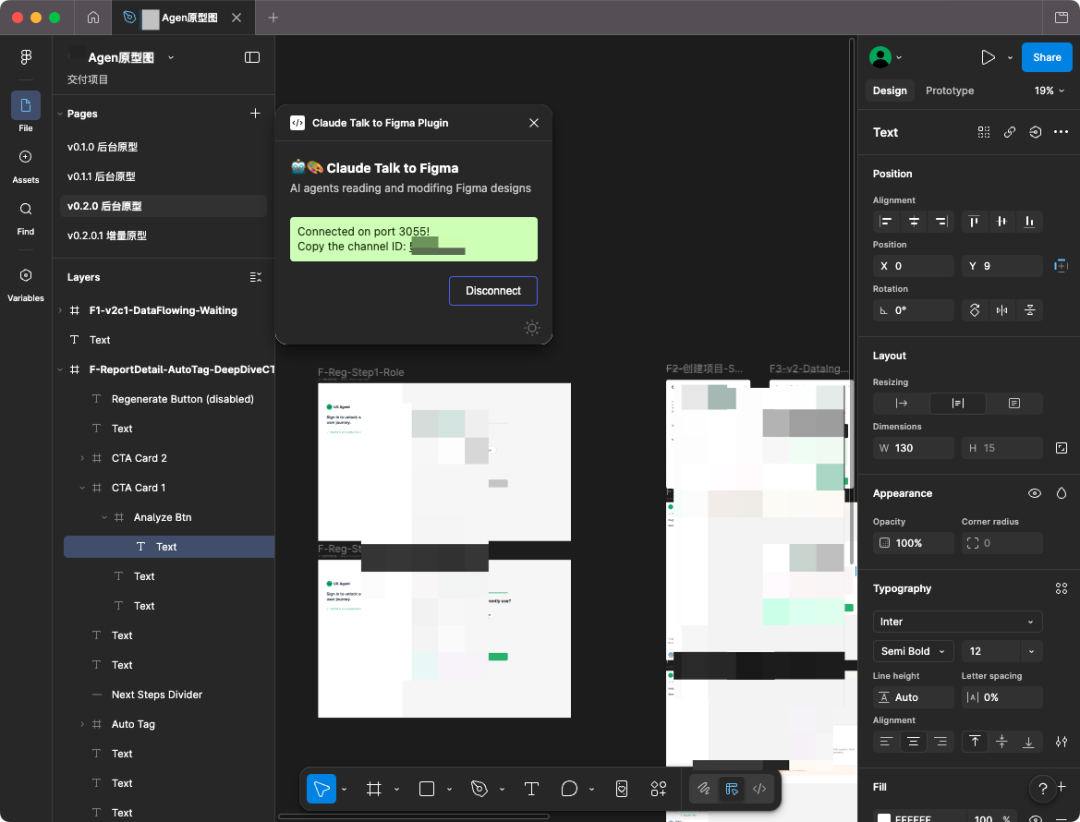
流程图工具(draw.io):我是从 Mermaid 切换到了 draw.io,是为了让 AI 生成的图表在节点样式、线条、颜色和层级上,更贴近人类产品经理的绘图习惯,保证了风格的稳定。
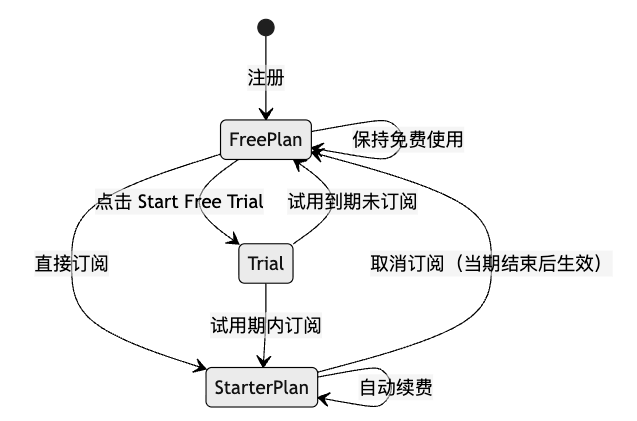
(mermaid画的,感觉可读性有点弱)
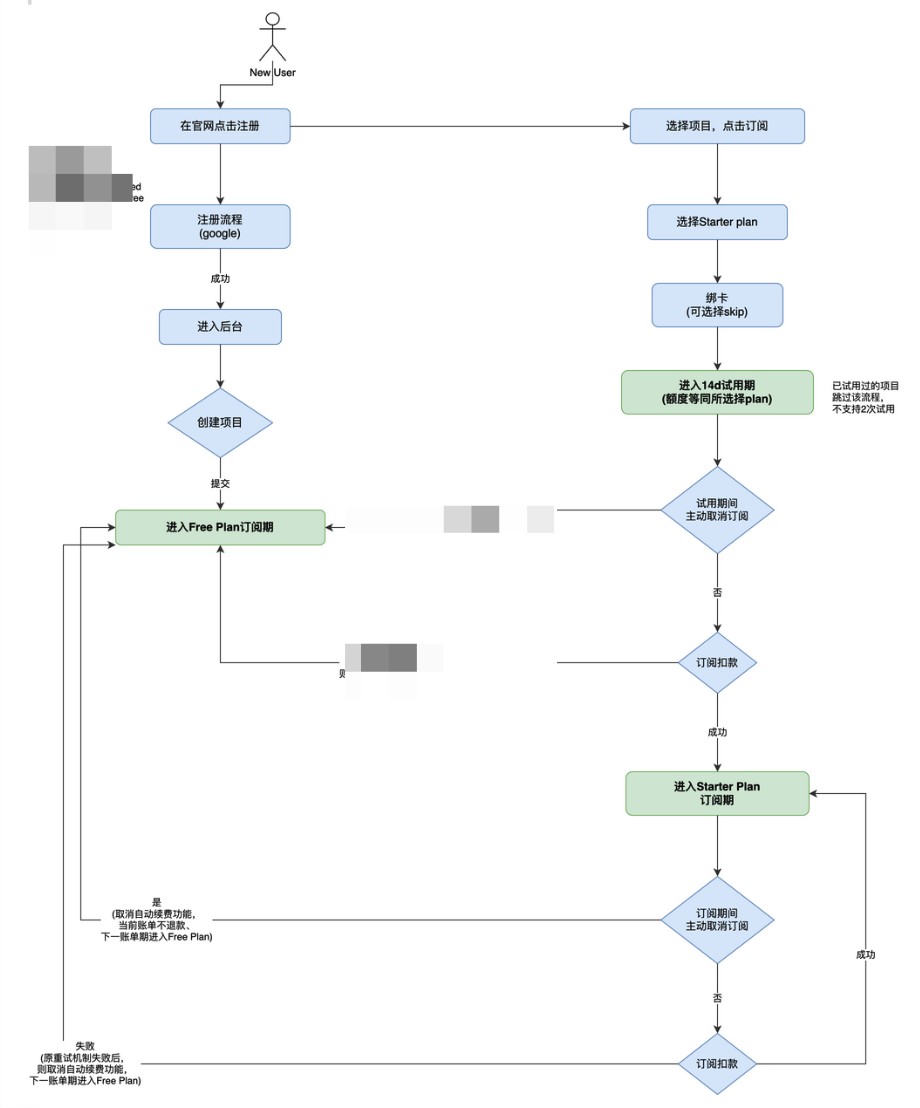
(draw.io画的,虽然略有交叉,但是可读性好了很多)
文档管理(GitLab):将 PRD 用 Markdown 纳入版本控制,带来了三大收益:
- 清晰的变更记录 (diff),无需口头解释修改点——以前我总要在群里艾特大家去看、也要手动维护一份变更记录,现在AI可以自己diff后生成变更记录
- 与研发现有工作流打通,能轻易通过链接访问文档来AI Coding——以前都是写在在线文档或者Confluence中,研发还得手动导出pdf后再扔给AI Coding,现在可以通过内部Gittlab直联,真的超级方便!
- 连续的工作上下文,AI 能沿着版本历史继续迭代——如果上下文断了、临时需要切换模型等,有完善的git记录和变更记录,会很容易让新起的会话也找到准确的上下文,不用担心丢失。
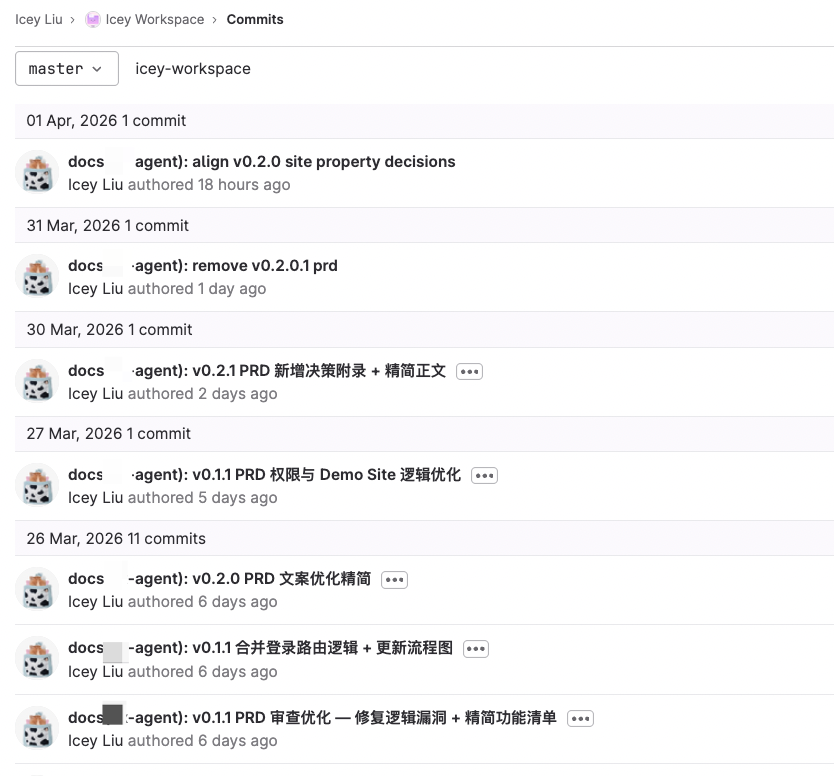
(gitlab自带的commit记录)
(需求文档内部也会自生成变更记录)
四、两个真实案例的启示
案例一:从“导航组件”到“账户体系重构”
这个迭代是在做一个关于“多角色、多站点”的需求,在几天内从 v0.1 迭代至 v0.9。
表面上是优化一个站点切换器,实则是对账户体系、权限、路由和新用户引导的全面重构。AI 在前期讨论中,不断将问题从表层拉回到底层定义,如“角色到底绑定在哪一层”、“额度跟着谁走”。当底层定义被校准后,上层的页面和文档逻辑才豁然开朗。
其实这个迭代中踩了很多坑,最开始自己没有把底层的实体结构想清楚,导致后续有大量的返工;后续在优化此前结构时,于是就和AI进行反复沟通和确认——如何基于业务需求找出最可扩展和稳定的结构,多轮review后确认找出了相对合理的解决方案。

案例二:从“接入引导”到“定义 Aha Moment”
在XX Agent产品中,我希望通过优化onboarding环节来快速让用户感受到产品的价值点。我和AI一起迭代了。
通过和AI对话和迭代了16 个版本后,我们共同探讨出一个关键分界线:数据上的接入成功不等于用户感知到的价值时刻;关键的价值点的体现在于用户看到首份报告后还想再生成第二份报告。
于是,整个流程被重新拆解为“三态验证过程”(没检测到、等待数据、数据流入),先快速地降低数据接入的门槛。
随后,再通过自动生成的AI报告,让用户快速接收到首份有价值的AI报告,报告也进行了2层分层——轻量级 Quick Win 与完整版 Deep Dive,轻量级用于前期数据匮乏阶段快速先看到局部效果、完整版则用于给用户真正有深度和有价值的分析报告,确保在用户旅程的每一步,都有精准的状态定义和价值传递。
这两个案例共同揭示了这套方法的核心:先借助 AI 发现问题真正发生的层级,再让它沿着清晰的定义去构建产出物。
五、让系统稳定运转的四个tips
将 AI 用顺之后,重点从“如何让它写出第一版”转移到“如何让它持续稳定地写对”。这依赖于几个关键习惯:
1. 让 AI 反复自检,而非一次性生成
每版产出后,先启动一个自检流程,让 AI 按照预设清单(如结构、锚点对应、组件描述完整性、术语一致性等)进行审查。这能提前消除大量低级错误。
我一般都是说:你作为一个研发or测试or老板的视角,来反复review一下这些文档有没有逻辑漏洞、前后矛盾等等。一般会反复来个3轮左右,就会达到一个很好的准确性了。
2. 每发现一次规律,就回写一次规则
一旦某类问题重复出现,就将其升级为 skill 或模板中的一条永久规则,而不是依赖口头提醒。这是将个人经验“产品化”的过程,也是系统进化的核心。
3. 用 GitLab 管版本,告别附件满天飞
将文档纳入版本控制,让 AI 参与“起草”和“维护”的全过程。清晰的版本历史不仅方便团队协作,也为 AI 提供了连续的工作上下文。
以下就是我目前Gitlab仓库的结构:包含全局Claude.md(主要是全局的一些规范和说明)、Skills(里面有一个写prd的skills)、Products(和产品迭代的内容全放这里)。

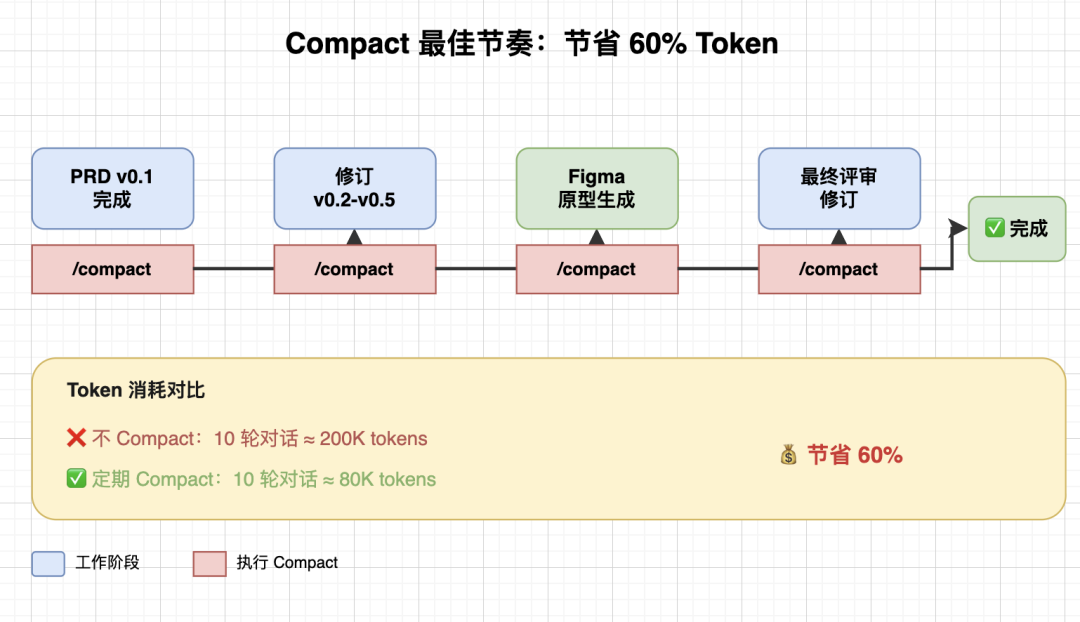
4. 大任务分阶段,完成后及时 compact(压缩上下文)
为避免上下文过长导致成本增加和焦点涣散,建议大家首先需要将复杂任务按里程碑切分。同时,在每个阶段完成后,再让 AI 做总结并压缩对话,保留核心信息,轻装上阵进入下一阶段。

在claude code里有一个/compact命令,则可以快速进行上下文压缩。
5. 复杂连接,直接写入Claude Code的Skill
每次写文档都需要连接Gitlab+配置很多东西,于是我直接让AI自己写了一个Skill,当我输入/后,直接就可以在对话框找到该条仓库连接的Skill,并且它会自动连接和找出最新的几条commit,节约了大量连接和给予上下文的时间。

同时,像Figma等MCP的连接,也可以直接让AI在Figma的Skill里写好自动的脚本,只要你说你要画原型图,它就自动会进行Figma的连接,无需再做什么复杂的配置。
写到最后
这篇分享,最想强调的发而不是工具本身,Claude Code CLI、Figma 插件、GitLab 固然重要,但真正决定产出质量的,是你是否将 AI 用在了“提高思考密度”这件事上。
如果只把它当成代笔,价值终归有限。真正的变革在于,当 AI 学会了你的风格、融入了你的上下文、参与了真实的迭代后,产品工作就从“单人兜底所有问题”,转变为“先将问题彻底谈深,再将方案精准落地”的新范式。
这不仅仅是效率提升,更是一种工作方式的进化。
如果把这篇文章的精髓压缩成一句话,那就是:
先将自己的产品方法论教会 AI,让它代替你完成繁重的体力活;而你,则应将全部精力,聚焦在更高价值的追问、判断与选择之上。
本文由人人都是产品经理作者【冰冰酱】,微信公众号:【冰冰酱啊】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









训练AI需要高质量的历史PRD,但很多团队的历史文档本身就不规范。如果输入的是垃圾,AI学到的也是垃圾,这个门槛其实不低。