
 起点课堂会员权益
起点课堂会员权益多模态大模型与 AI 落地:从技术到实战的完整路径
多模态大模型正在重新定义AI与人类交互的方式。从基础的图像识别到高级的跨模态推理,多模态技术为医药、教育等垂直场景带来全新解决方案。本文将深度解析多模态技术的三个能力层次、四大核心技术模块,并分享AI产品落地的实战方法论与药企考试系统案例,为AI产品经理提供从技术理解到工程落地的完整指南。

一、什么是多模态大模型?
1.1 从”能看”到”能理解”
先问一个问题:
GPT-4 和 GPT-4V 的区别是什么?
答案是:GPT-4 只能处理文字,GPT-4V 可以处理文字 + 图片。
这就是多模态。
多模态大模型,就是能同时处理多种输入输出形式的大模型。
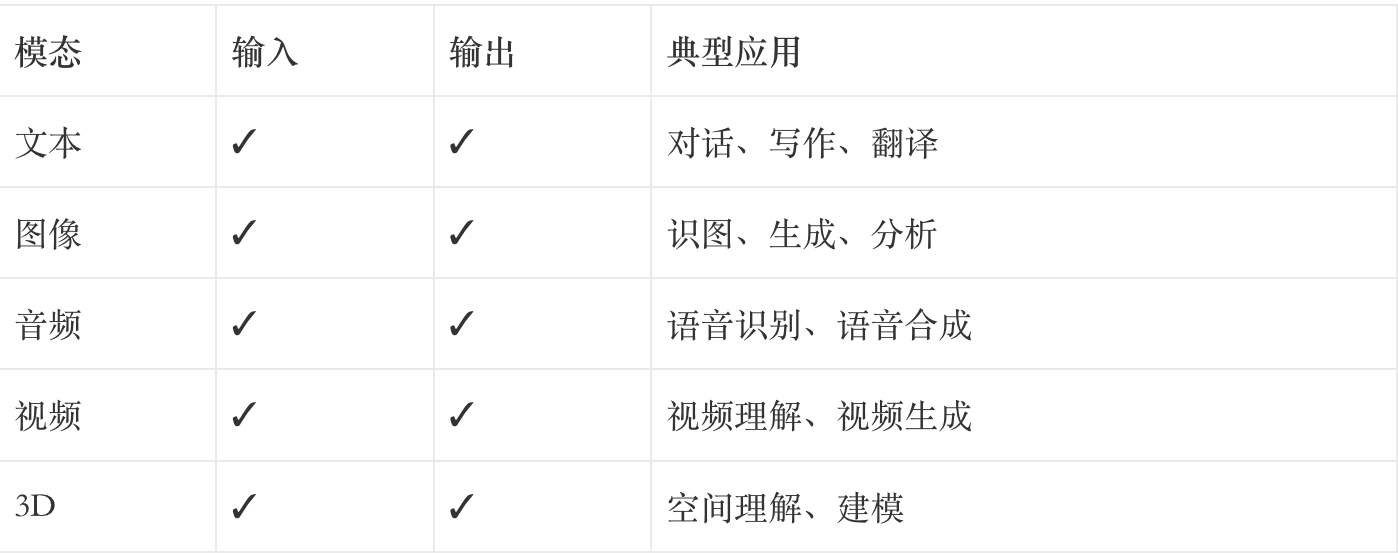
1.2 多模态的三种能力层次
很多人以为,多模态就是”能看图说话”。
太浅了。
我把多模态能力分为三个层次:
第一层:识别(Recognition)
- 能认出图片里有什么
- 能听出语音说什么
- 能看懂视频里的动作
这是最基础的能力,相当于”感知”。
第二层:理解(Understanding)
- 能理解图片的场景和意图
- 能听懂语音的情绪和暗示
- 能理解视频的因果关系
这是进阶能力,相当于”认知”。
第三层:推理(Reasoning)
- 能根据图片推理出前因后果
- 能结合语音和上下文做判断
- 能跨模态进行逻辑推理
这是高级能力,相当于”思考”。
在医药场景的应用:

1.3 为什么多模态是 AI 落地的关键?
答案很简单:用户不会为了 AI 而 AI。
用户要的是解决问题。
而真实世界的问题,很少是单一模态的。
举个例子:
患者拿着检查单问:”医生,我这个指标正常吗?”
这个问题涉及:
- 文本:患者的问题
- 图像:检查单上的数据和参考范围
- 知识:医学知识库中的正常值范围
如果只能用文字交互,患者得手动输入所有数据——体验极差。
多模态的价值,就是让 AI 交互更接近人类交互。
二、多模态大模型的核心技术
2.1 视觉语言模型(VLM)
这是目前最成熟的多模态技术。
原理: 把图片编码成向量,和文字向量一起输入大模型。
代表产品:
- GPT-4V
- Claude 3
- Gemini 1.5
- 通义千问 VL
- 文心一言 4.5
在医药场景的应用:
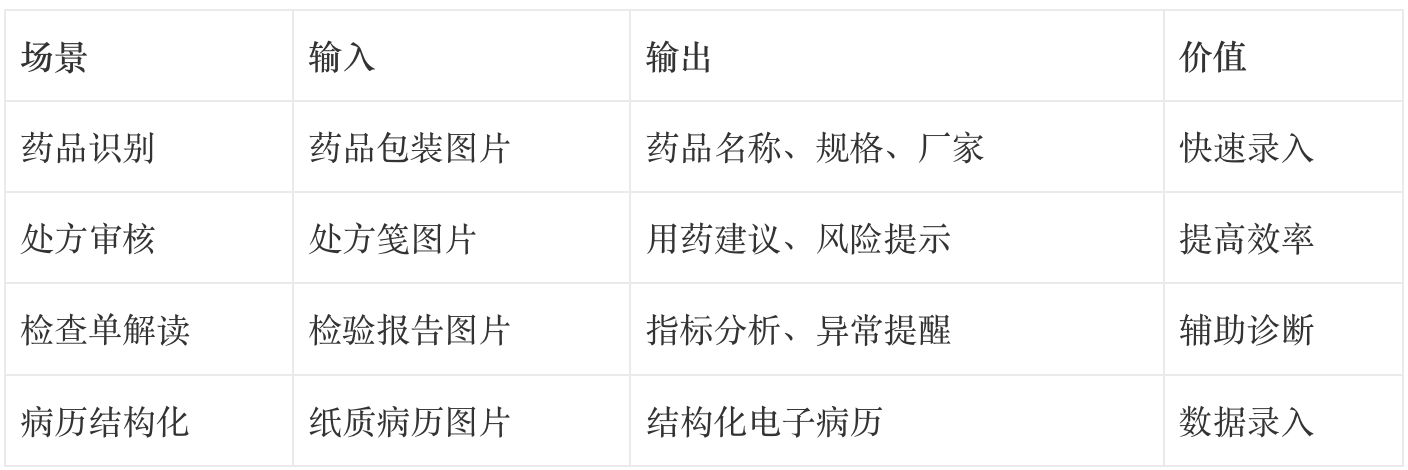
2.2 语音交互技术
这是最自然的交互方式。
技术栈:
- ASR(语音识别):语音→文字
- TTS(语音合成):文字→语音
- 语音情感识别:语音→情绪状态
在医药场景的应用:

2.3 视频理解技术
这是正在爆发的方向。
能力:
- 视频内容理解
- 动作识别
- 场景分析
- 时序推理
在医药场景的应用:
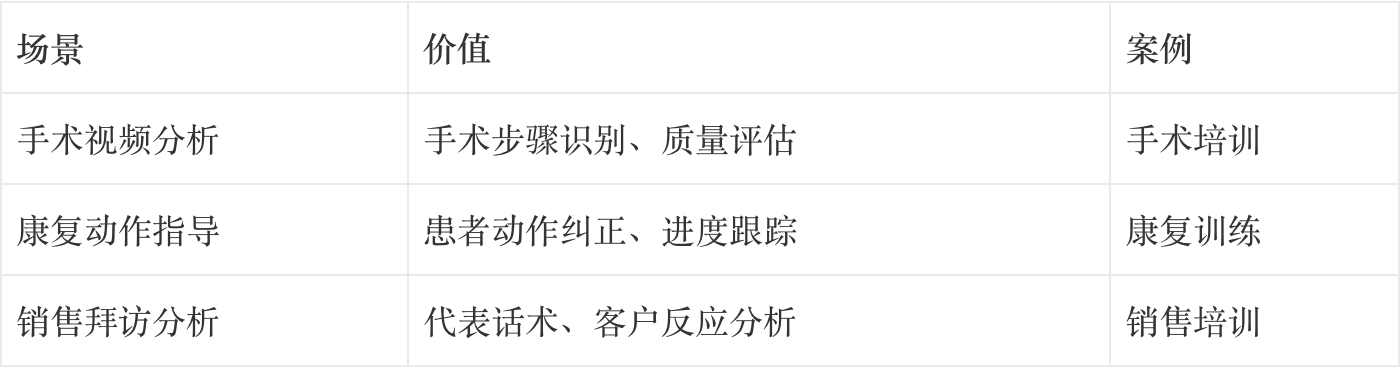
2.4 多模态融合技术
这是未来的方向。
核心思想: 不是简单拼接多种模态,而是让模型真正理解模态之间的关系。
举个例子:
输入:一张 X 光片 + 患者主诉文字 + 医生语音备注 输出:综合诊断建议
模型需要:
- 理解 X 光片的影像特征
- 理解患者的症状描述
- 理解医生的语音备注
- 综合三者进行推理
技术难点:
- 不同模态的信息可能冲突
- 需要跨模态的注意力机制
- 需要大量的多模态训练数据
三、AI 落地的核心方法论
3.1 场景选择:从简单到复杂
很多人做 AI 落地,一上来就想做”颠覆性创新”。
结果往往是:投入大、周期长、效果差。
我的建议:从简单场景开始,快速验证,逐步迭代。
场景选择矩阵:
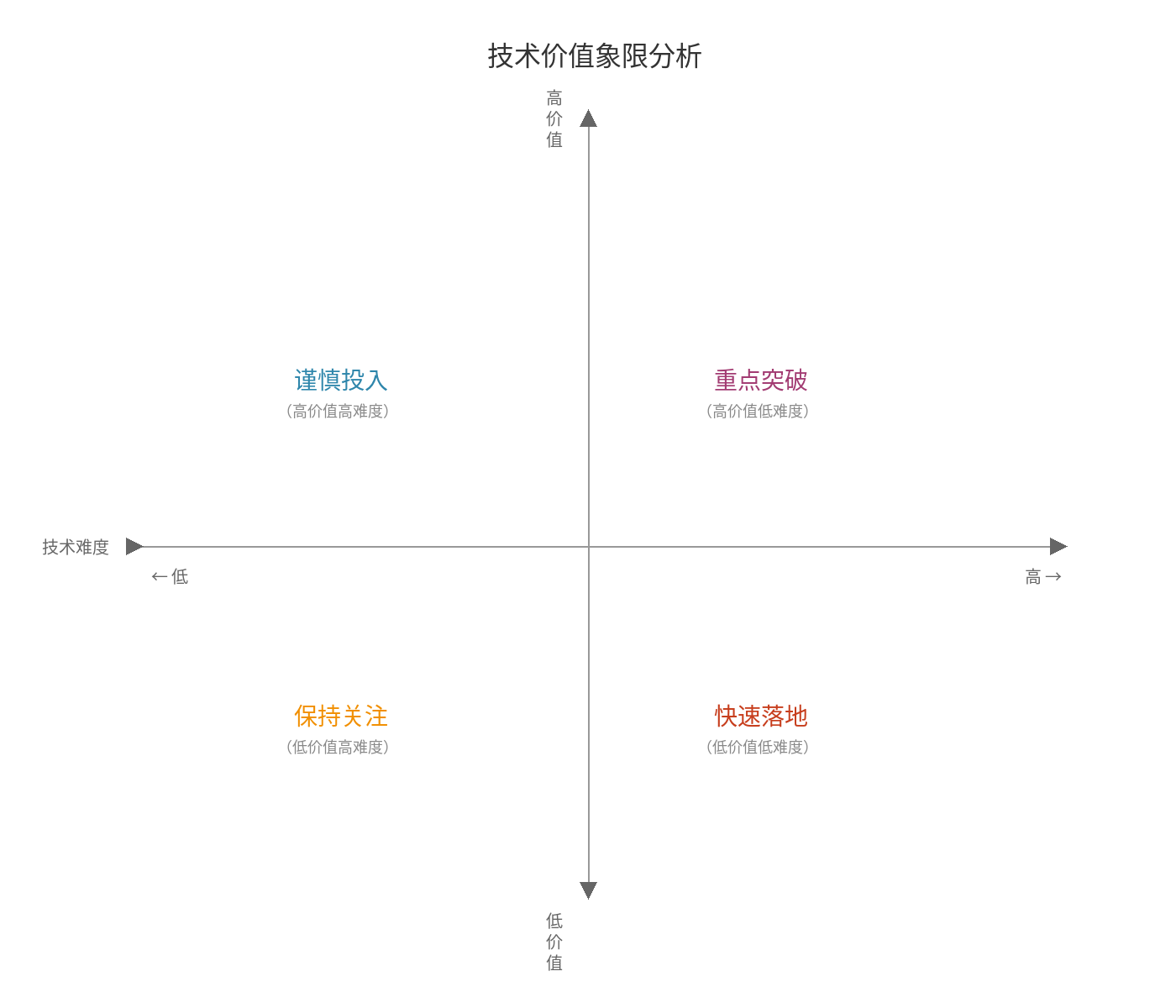
医药数字化场景分类:
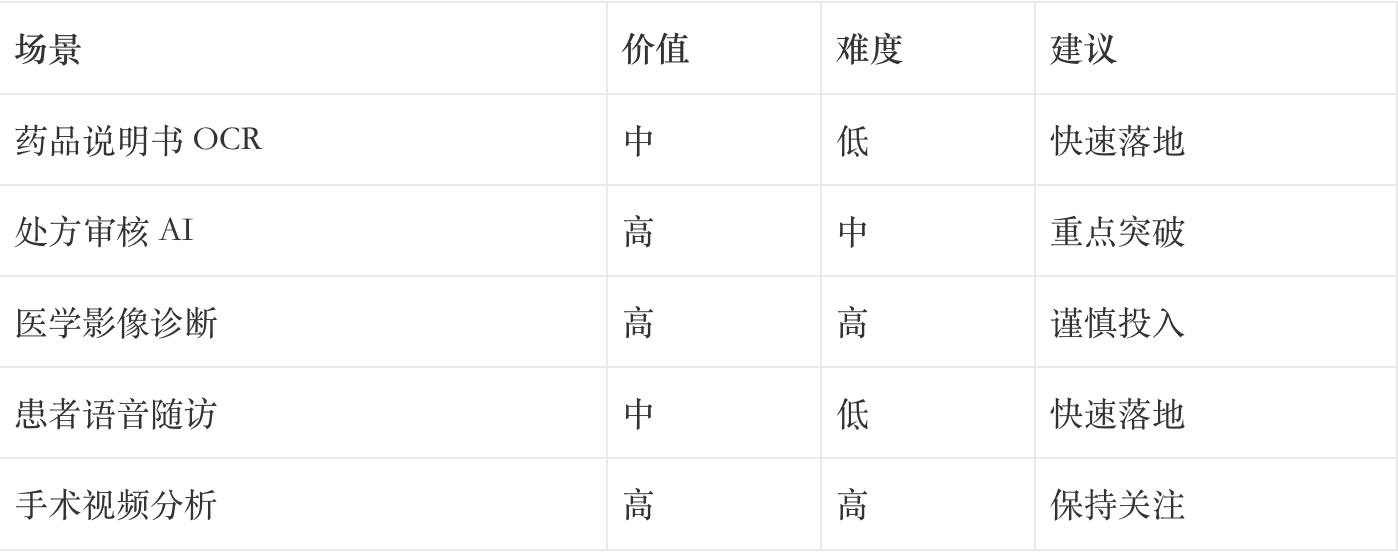
3.2 技术选型:自研 vs 外购
这是每个 AI 产品负责人都要面对的问题。
我的决策框架:
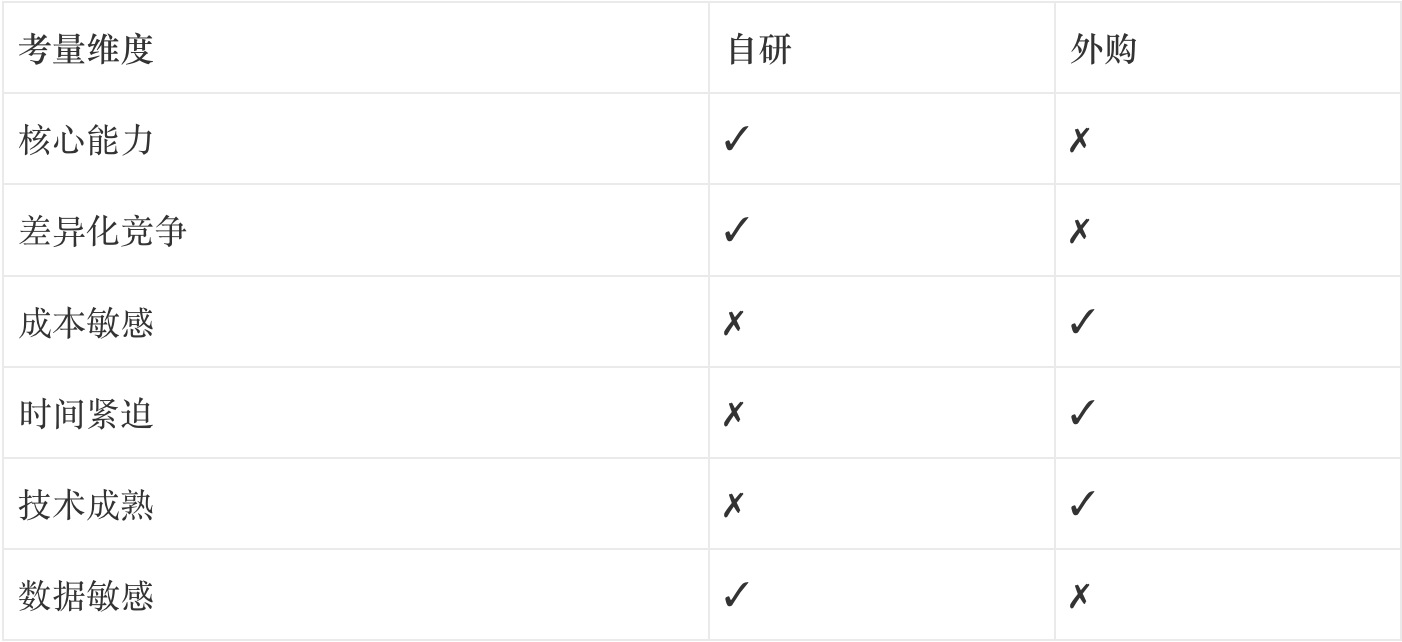
我们的选择策略:
- 核心能力自研: 如医药知识库、患者数据模型
- 通用能力外购: 如 OCR、语音识别、大模型 API
- 混合模式: 外购基础模型 + 自研微调
3.3 数据准备:质量比数量重要
很多人以为,AI 落地最大的瓶颈是算法。
错。
真正的瓶颈是数据。
数据准备的三个原则:
1. 质量优先
- 1000 条高质量标注数据 > 10 万条低质量数据
- 标注一致性比标注数量更重要
- 建立数据质量审核流程
2. 场景覆盖
- 覆盖典型场景
- 覆盖边界场景
- 覆盖长尾场景
3. 持续迭代
- 上线后持续收集数据
- 定期更新训练集
- 建立数据闭环
在医药场景的特殊要求:
- 数据脱敏(患者隐私保护)
- 合规审核(医疗数据监管)
- 专家标注(医学专业性)
3.4 评估体系:不要相信厂商的”准确率”
这是我最想强调的一点。
厂商说的“准确率 99%”,是在他们的测试集上的结果。
你的场景、你的数据、你的用户,可能完全不同。
建立自己的评估体系:
1. 离线评估
- 准备测试集(覆盖典型 + 边界场景)
- 定义评估指标(准确率、召回率、F1 等)
- 定期测试(模型迭代后重新评估)
2. 在线评估
- A/B 测试(新旧模型对比)
- 用户反馈收集
- 业务指标追踪(如转化率、满意度)
3. 人工抽检
- 定期人工审核 AI 输出
- 错误案例分析
- 持续优化方向
我们的评估流程:
模型上线 → 离线测试 → 小流量灰度 → 全量上线 →持续监控 → 定期复测 → 迭代优化
四、实战案例:AI 考试系统
4.1 项目背景
我们药企有 1000+ 员工,传统考试方式是:
- 纸质考试:组织成本高、阅卷工作量大
- 在线考试:只能考选择题,无法考实操
- 线下考核:效率低、难以规模化
需求:用一个 AI 系统,实现全场景、多模态的考试能力。
4.2 能力设计
基于多模态技术,我们设计了以下能力:
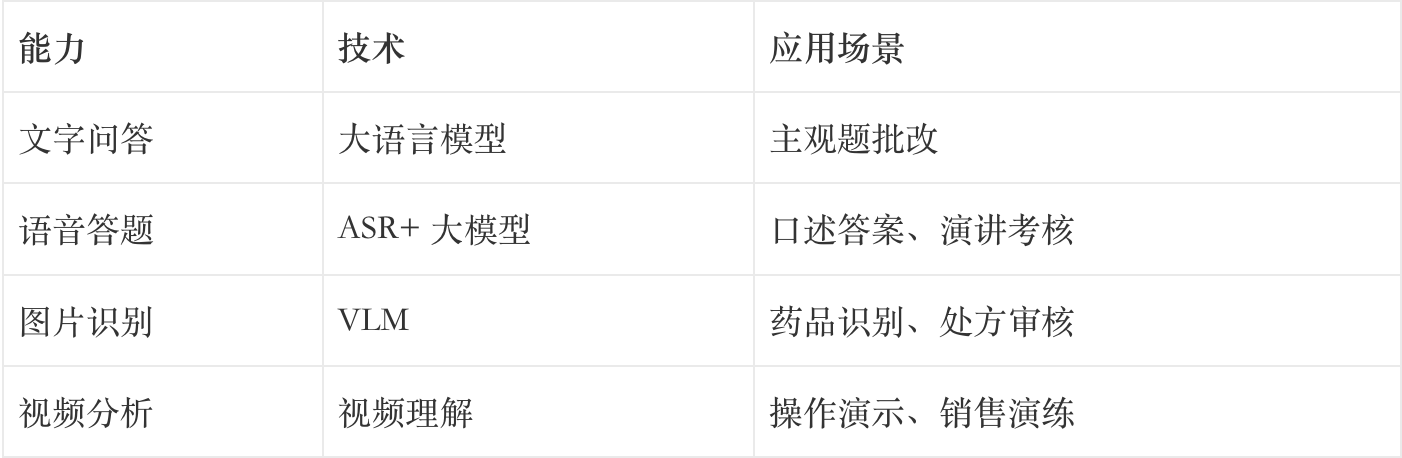
4.3 系统设计
考生端 → 答题(文字/语音/图片/视频)→AI 批改(多模态模型)→ 结果反馈 →人工复核(主观题/高分争议)→ 最终成绩
关键设计:
1)多模态输入支持
- 文字:直接输入
- 语音:实时转文字 + 语音分析
- 图片:上传 + OCR 识别
- 视频:上传 + 关键帧分析
2)智能批改引擎
- 客观题:自动批改
- 主观题:AI 初评 + 人工复核
- 实操题:视频分析 + 专家评分
3)反馈机制
- 即时反馈:答题后立即出分
- 详细解析:错题分析 + 知识点讲解
- 个性化建议:薄弱环节 + 学习推荐
4.4 上线效果
- 考试效率:提升 300%
- 阅卷成本:降低 80%
- 覆盖率:从 50% 提升到 95%
- 员工满意度:88%
关键成功因素:
- 多模态能力覆盖全场景
- AI 批改 + 人工复核保证准确性
- 持续迭代优化模型
五、AI 产品经理的能力模型
5.1 技术理解力
不需要你会写代码,但需要你能理解技术。
必备知识:
- 大模型的工作原理
- 多模态技术的边界
- 常见 AI 能力的技术实现
- 技术选型的权衡
学习路径:
- 吴恩达《AI For Everyone》
- 李宏毅《机器学习》
- 实战:用 Coze/星辰搭建智能体
- 跟进技术进展(论文、博客、会议)
5.2 场景洞察力
技术是手段,场景是目的。
场景洞察的方法:
- 深度访谈(用户、业务方)
- 现场观察(真实工作场景)
- 数据分析(行为数据、反馈数据)
- 竞品分析(同类产品、跨行业产品)
场景评估框架:

5.3 工程落地力
想法再好,落不了地就是空谈。
工程落地的关键:
- 技术选型(自研 vs 外购)
- 架构设计(可扩展、可维护)
- 数据准备(质量、数量、合规)
- 评估体系(离线 + 在线 + 人工)
- 迭代机制(反馈闭环)
5.4 预期管理力
AI 产品最难的不是技术,是预期管理。
对老板:
- 不承诺做不到的事
- 明确告知边界和风险
- 用数据说话(ROI、效率提升)
对用户:
- 不神化 AI 能力
- 明确告知 AI 的定位
- 提供人工复核入口
对团队:
- 培训技术认知
- 建立审核流程
- 制定应急预案
六、写给 AI 产品经理的建议
6.1 从”对话框”思维跳出来
多模态是趋势,不是噱头。
真实世界的交互,不是只有文字。
思考: 你的产品,能不能用语音?能不能看图?能不能理解视频?
6.2 先跑起来,再优化
完美主义是 AI 落地的大敌。
MVP 原则:
- 最小可行产品
- 快速上线验证
- 持续迭代优化
6.3 数据是护城河
算法可以买,数据买不到。
建立数据壁垒:
- 积累场景数据
- 建立标注体系
- 形成数据闭环
6.4 安全合规是底线
必须做到:
- 数据脱敏
- 合规审核
- 人工复核
- 责任追溯
结语
多模态大模型,让 AI 更接近人类交互。
但技术只是手段,落地才是目的。
作为 AI 产品经理,我们的价值不是”追新技术”,而是”用合适的技术,解决真实的问题”。
希望这篇文章能帮你建立多模态和 AI 落地的完整认知框架。
本文由 @许与 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自作者提供
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


