
 起点课堂会员权益
起点课堂会员权益大模型的能力边界:能做什么,不能做什么
大模型绝非万能钥匙,医药AI领域栽过的跟头比成功案例还多。本文从函数本质、Token机制到三类能力边界,系统拆解大模型在医疗场景的真实能力图谱,更给出产品经理必备的5条避坑指南——从架构设计到预期管理,教你用工程思维弥补AI短板。

做 AI 产品三年,我见过太多同行在大模型上栽跟头。
有人花半年做了一个”AI 医生”,结果连基本的用药禁忌都回答不准;有人给老板承诺”用 AI 替代 80% 客服”,上线后发现连用户最常见问题都处理不了;还有人把大模型当万能钥匙,什么场景都想往里塞,最后交付的东西食之无味弃之可惜。
问题出在哪?不是技术不行,是对大模型的能力边界认知不清。
今天把我对大模型能力边界的理解系统梳理出来,希望能帮你少走弯路。
一、大模型到底是什么?
1.1 一个被过度神化的”函数”
先说结论:大模型本质上是一个函数,y = f(x)。
输入 x(prompt),输出 y(response)。就这么简单。
但很多人把它想象成了什么?是无所不知的专家,是能理解一切的智者,是 AGI 的前夜。
醒醒。
大模型做的,是基于训练数据中学到的统计规律,预测下一个 token 是什么。它不理解”意思”,它只理解”概率”。
举个例子:
输入:感冒了应该吃什么药? 输出:建议服用对乙酰氨基酚或布洛芬…
模型不是在”理解”医学知识,它是在预测:基于训练数据中”感冒””吃药”这些 token 的共现模式,接下来最可能出现的 token 序列是什么。
这个认知很重要。因为它直接决定了大模型的能力边界。
1.2 Token:大模型的世界观
大模型不看”字”,它看的是 Token。
Token 是什么?你可以理解为”词元”,是模型处理文本的最小单位。中文里,一个 Token 大约对应 1.5 个汉字。
“我今天感冒了” → [“我”, “今天”, “感冒”, “了”] → 4 个 Token
大模型的一切能力,都建立在 Token 的预测之上:
- 它”理解”世界的方式:Token 序列
- 它”思考”的过程:Token 的逐步生成
- 它”输出”的结果:Token 的概率分布
所以,大模型的能力边界,本质上是由 Token 预测这个机制决定的。
二、大模型能做什么?
2.1 第一类能力:确定性任务
这类任务的特点是:有明确的标准答案,且答案在训练数据中高频出现。
比如:
- 翻译:”把这段话翻译成英文”
- 总结:”用 100 字概括这篇文章”
- 改写:”把这段话改得更正式一些”
- 分类:”这条评论是正面还是负面”
这些任务,大模型做得很好。为什么?因为训练数据中有海量类似样本,模型学到了稳定的映射关系。
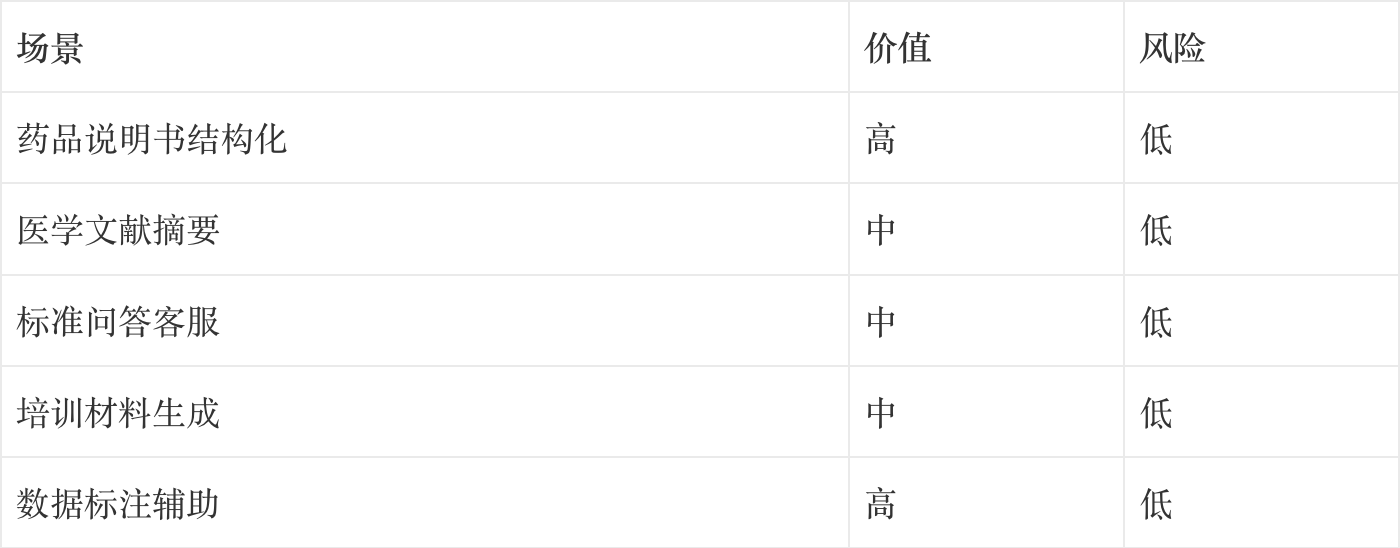
在医药场景的应用:
- 药品说明书的结构化提取
- 医学文献的摘要生成
- 患者咨询的标准问答
这类场景,大模型可以承担 80% 以上的工作量。
2.2 第二类能力:创造性任务
这类任务的特点是:没有标准答案,需要组合已有知识生成新内容。
比如:
- 写作:”写一篇关于 AI 医药的文章”
- 策划:”设计一个患者教育活动方案”
- 代码:”写一个数据清洗的 Python 脚本”
这类任务,大模型能做,但质量不稳定。为什么?因为”创造性”本质上是对训练数据的重新组合,模型无法真正”创新”。
在医药场景的应用:
- 营销文案的初稿生成
- 培训材料的框架搭建
- 患者教育内容的草拟
这类场景,大模型适合做”助手”,不适合做”主力”。人类专家的审核和修改是必须的。
2.3 第三类能力:推理型任务
这类任务的特点是:需要多步逻辑推导,且每步都依赖前一步的正确性。
比如:
- 数学计算:”1234 × 5678 等于多少”
- 逻辑推理:”如果 A 大于 B,B 大于 C,那么 A 和 C 的关系是?”
- 复杂决策:”根据患者症状和病史,给出诊疗建议”
这类任务,是大模型的传统弱项。
为什么?因为 Token 预测是”一步到位”的,模型无法像人类一样”一步步想清楚”。
但情况正在变化。DeepSeek-R1 等推理模型的出现,通过强化学习和思维链技术,让大模型具备了初步的推理能力。
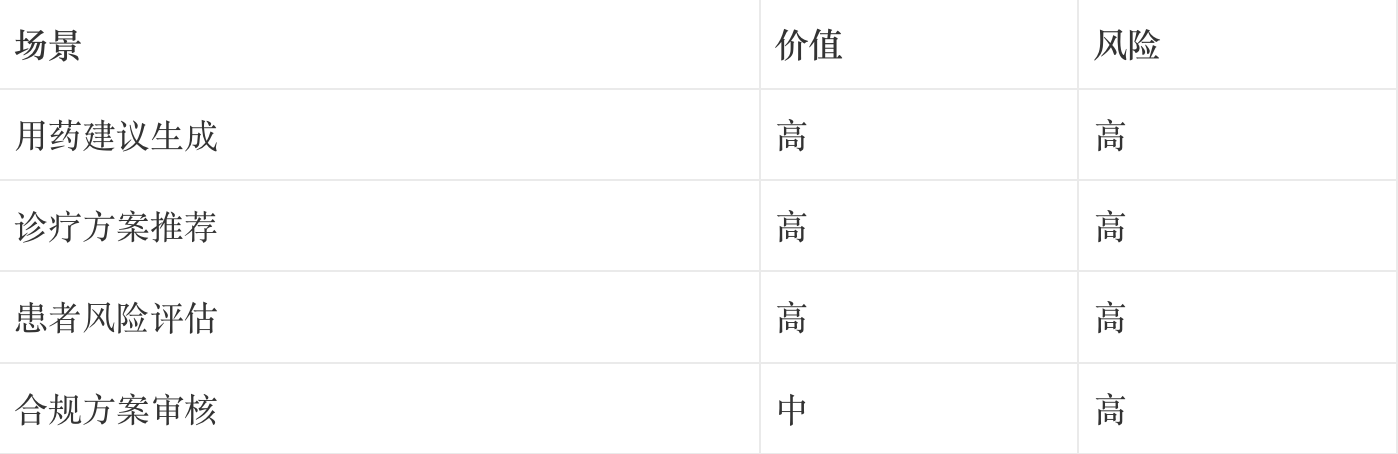
在医药场景的应用:
- 用药剂量的计算(需要谨慎验证)
- 临床路径的逻辑判断(需要专家审核)
- 药物相互作用的推理(必须人工复核)
这类场景,现阶段不建议完全依赖大模型。
三、大模型不能做什么?
3.1 不能保证 100% 准确
这是最重要的一条。
大模型会幻觉,这是机制决定的,不是 bug,是 feature。
因为它做的是概率预测,不是事实检索。当它”不知道”时,它不会说”我不知道”,它会”猜一个最像答案的答案”。
在医药场景,这意味着什么?
- 它可能编造一个不存在的药品名称
- 它可能给出错误的用药剂量
- 它可能混淆两种相似的疾病
所以,任何涉及患者安全的场景,必须有人类专家复核。
3.2 无法访问训练数据之外的知识
大模型的知识截止于训练完成的那一天。
GPT-4 的训练数据截止到 2023 年初,它不知道 2023 年之后上市的新药,不知道最新的临床指南,不知道上周刚发布的政策。
在医药场景,这是致命问题。
医药行业知识更新极快:
- 新药不断上市
- 指南每年更新
- 政策频繁调整
解决方案:RAG(检索增强生成)。
把最新的药品信息、临床指南、政策文件放进知识库,让模型在回答时先检索相关知识,再生成答案。
这是我们做医药 AI 系统的标配架构。
3.3 无法真正”理解”上下文
大模型的”记忆”是有限的。
- GPT-4 的上下文窗口约 128K token
- 看似很长,但实际使用中会衰减
更重要的是,模型对长文本的理解是”注意力加权”的,不是”完整记忆”的。
在医药场景的表现:
- 患者病史很长时,模型可能遗漏关键信息
- 多轮对话后,模型可能忘记前面的设定
- 复杂文档中,模型可能抓不住重点
解决方案:
- 分段处理,不要一次性塞太多内容
- 关键信息重复强调
- 用结构化方式呈现(表格、列表)
3.4 无法承担专业责任
这是最容易被忽视的一点。
大模型不能为它的输出承担责任。
它给出的用药建议错了,谁负责?它做的诊断判断有问题,谁担责?它生成的合规方案有漏洞,谁背锅?
答案很明确:使用它的人和企业。
所以,在医药场景,大模型的定位必须是”辅助工具”,不是”决策主体”。
- 它可以生成建议,但不能做最终决定
- 它可以提供参考,但不能替代专家
- 它可以提高效率,但不能免除责任
四、AI 产品经理的应对策略
4.1 场景选择:有所为有所不为
基于大模型的能力边界,我把医药数字化场景分为三类:
推荐场景(大模型擅长):
谨慎场景(需要人工复核):
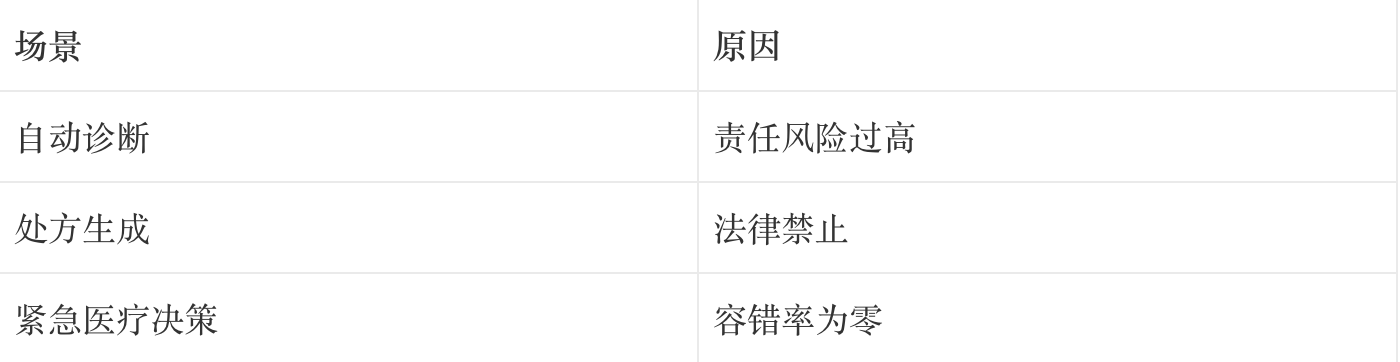
避免场景(现阶段不建议):
4.2 架构设计:用工程弥补模型不足
大模型有边界,但工程可以弥补。
我们的标准架构:
用户输入 → 意图识别 → 知识检索 (RAG) → Prompt 优化 →
大模型生成 → 结果验证 → 人工复核 (高风险场景) → 输出
关键设计原则:
1. 永远不要直接暴露大模型
中间要有意图识别、知识检索、结果验证,大模型只是整个系统的一个组件。
2. 高风险场景必须有人工复核
用药建议、诊疗方案等,必须专家审核。可以 AI 初审 + 人工复核,提高效率。
3. 建立反馈闭环
用户反馈要收集,错误案例要分析,模型输出要持续优化。
4.3 预期管理:对老板和用户都要诚实
做 AI 产品,最难的不是技术,是预期管理。
对老板:
- 不要承诺”AI 替代 XX%人力”
- 要说”AI 辅助,效率提升 XX%”
- 明确告知边界和风险
对用户:
- 不要说”AI 医生”,要说”AI 助手”
- 明确告知”仅供参考,请遵医嘱”
- 提供人工复核的入口
对团队:
- 培训团队成员理解大模型边界
- 建立 AI 输出的审核流程
- 制定错误应对预案
五、写给 AI 产品经理的 5 条建议
5.1 先理解技术,再设计产品
不要听厂商忽悠,不要看媒体炒作。
自己去学:
- 大模型的工作原理
- Token、Prompt、RAG、Fine-tuning 是什么
- 不同模型的能力差异
推荐学习路径:
- 吴恩达《AI For Everyone》
- 李宏毅《机器学习》
- 实战:用 Coze/Dify搭建一个智能体
5.2 永远不要相信 Demo
厂商的 Demo 都是精心设计的,展示的是最好情况。
你要测试的是:
- 边界情况(输入奇怪的内容)
- 长尾场景(不常见的请求)
- 持续使用(会不会越用越差)
- 并发压力(多人同时用会怎样)
5.3 建立自己的评测体系
不要相信厂商说的”准确率 99%”。
自己建评测集:
- 覆盖典型场景
- 包含边界案例
- 定期更新(模型会迭代)
- 有明确的通过标准
5.4 设计容错机制
大模型一定会出错,你要设计的是:出错之后怎么办。
- 用户反馈入口
- 快速修正流程
- 错误案例分析
- 持续优化机制
5.5 保持敬畏,持续学习
AI 技术迭代太快了。
今天的边界,明天可能就被突破。今天的最佳实践,明年可能就过时了。
保持敬畏:
- 不神化大模型
- 不低估风险
- 不盲目跟风
持续学习:
- 关注技术进展
- 参与行业交流
- 实战中迭代认知
结语
大模型是工具,不是魔法。
作为 AI 产品经理,我们的价值不是”用大模型做什么”,而是”知道大模型能做什么、不能做什么,然后在边界内设计最好的产品”。
希望这篇文章能帮你建立对大模型的正确认知。
本文由 @许与 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


