
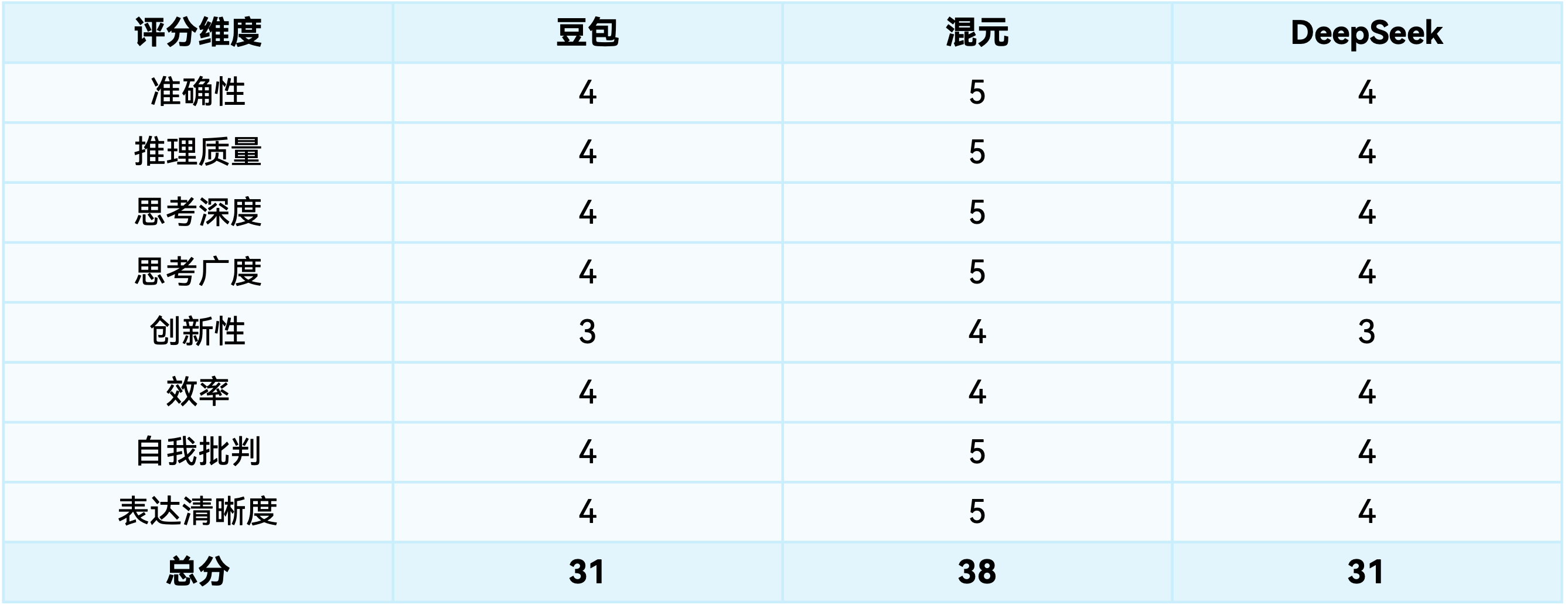
 起点课堂会员权益
起点课堂会员权益我们对三款国产深度思考大模型进行了多维度横评,结果竟然是……
在人工智能迅猛发展的时代,国产深度思考大模型正在逐步崛起,为各行业带来前所未有的变革。本文将对三款国产深度思考大模型进行多维度评测,从性能、应用场景、用户体验等多个角度剖析其优劣势。

从ChatGPT爆火开始,就不断有人用比较9.8和9.11的大小来评价大模型。然而,用这样简单的”陷阱题”来评判大语言模型的思维能力,就像用一道脑筋急转弯题来评价一位科学家的研究水平——过于片面且意义有限。真正的深度思考不是简单地输出正确答案,而是展现清晰、系统、多维度的思考过程。
在当前LLM技术竞争日益激烈的环境下,各大厂商纷纷推出“深度思考”模式。但这些模式的实际效果如何?它们在处理复杂问题时展现出怎样的思维特点?单一的正确率指标已无法满足我们对这些“思考型AI”的评估需求。
带着这样的思考,我们设计了一个多维度评测体系,对豆包(Doubao)、混元(Hunyuan T1)和DeepSeek R1三款国产大模型的深度思考模式进行了系统性横评。我们没有选择那些“9.8 vs 9.11”式的陷阱题,而是精心挑选了五类真正需要深度思考的问题:逻辑推理、数学问题、因果分析、反事实推理和元认知。通过对准确性、推理质量、思考深度、思考广度、创新性、效率、自我批判和表达清晰度这八个维度的评分,尝试揭示这些模型思考能力的全貌。
实验设计:多维度、多场景的思考过程评价体系
我们选取了五类需要复杂思维的问题:逻辑推理、数学问题、因果分析、反事实推理和元认知,并采用八个维度(准确性、推理质量、思考深度、思考广度、创新性、效率、自我批判和表达清晰度)进行1-5分制评分。不仅记录模型的最终答案,更重要的是分析其完整的思考过程(即”思考链”),这让我们能够全面评估模型的深度思考能力,区分简单的答案输出与真正的系统性思维过程。
评分体系设计
测评题目设计
1. 逻辑推理:深度思考的基础架构
逻辑推理是所有深度思考的基础。它测试模型能否从前提出发,通过严格的规则推导出有效结论,避免矛盾和谬误。逻辑推理测试模型是否具备“思维的纪律性”,展示模型能否在复杂条件下保持推理的一致性和正确性。
有5种不同颜色的5栋房子。在每栋房子里分别住着5个国籍的人。这5个房主喝着不同的饮品。抽着5种不同牌子的烟。每人都养着不同的宠物。
– 英国人住在红色的房子里
– 瑞典人养狗
– 丹麦人喝茶
– 绿色房子在白色房子的左边。
– 绿色房子的主人喝咖啡。
– 抽Pall Mall烟的人养鸟。
– 黄色房子的主人抽Dunhill烟。
– 住在中间房子里的人喝牛奶。
– 挪威人住在第一栋房子里。
– 抽Blend烟的住在养猫人的隔壁。
– 养马的人住在抽Dunhill烟的人隔壁。
– 抽Blue master烟的人喝啤酒。
– 德国人抽Prince烟。
– 挪威人住在蓝色房子隔壁。
– 抽Blend烟的邻居喝水。
问题:谁养鱼?
2. 数学问题:精确思维的体现
数学问题要求精确、结构化的思维和多步骤推理,是最能展示思考严谨性的领域。数学解题涉及抽象概念操作和符号推理,测试模型是否能够处理严格形式化的思维过程,如何捕捉概念之间的精确关系,以及是否能够构建连贯、有效的证明。
已知函数f(x)定义在正整数集上,对于任意的正整数x,都有f(x+2)=2f(x+1)-f(x),且f(1)=2,f(3)=6,则f(2009)=?
3. 因果分析:系统思维的核心
理解复杂系统中“为什么”和“怎么样”的关系是解决现实问题的关键。因果分析测试模型是否能区分相关性和因果性,识别直接和间接影响,以及考虑不同变量之间的交互作用。这种能力对理解复杂社会、经济和科学问题至关重要。
某城市实施了新的交通政策,限制市中心机动车数量。政策实施后,研究发现:
– 市中心空气质量改善了15%
– 周边地区交通拥堵增加了20%
– 公共交通使用率上升了25%
– 市中心商店的销售额下降了10%
– 网购订单在全市范围内增加了8%
分析这些现象之间可能的因果关系,考虑直接和间接影响,并讨论可能被忽视的变量。提出对该政策效果的综合评估。
4. 反事实推理:思维灵活性的标志
构建和分析“假如”情境是创新思维和预测能力的基础。反事实推理测试模型对现实规则的深层理解,以及能否基于这些理解构建合理的假设情境。这种能力反映了模型是否真正掌握因果关系和系统动态,而不仅仅是记忆了现有模式。
假设互联网技术在1950年代就已被广泛采用(而非1990年代):
– 分析这会对冷战格局产生什么影响
– 推测全球化进程将如何改变
– 考虑对科技发展路径的影响
– 分析对社会文化发展的可能影响
请思考多层次影响,考虑技术、政治、经济、社会各方面,并分析连锁反应。
5. 元认知:自我评估的高级能力
对自身思考过程的监控、评估和调整是高阶思维的标志。元认知测试模型能否识别思维中的偏见、评估自己推理的局限性,以及在不确定条件下做出合理决策。真正的深度思考需要不断质疑和改进自己的思维过程。
你是一位决策顾问,面对以下情境:
有一家生物技术公司正考虑投资开发一种新药物。研究数据显示该药物对某种疾病有70%的有效率,但样本量相对较小。市场分析表明,如果药物成功,将带来巨大回报,但开发风险和成本也很高。公司内部对此项目存在分歧。
– 分析决策过程中可能出现的认知偏误
– 设计一个决策框架来减少这些偏误
– 反思你自己的分析过程中可能存在的局限性
– 提出如何在不确定条件下做出更合理决策的方法
深度思考过程横向测评结果
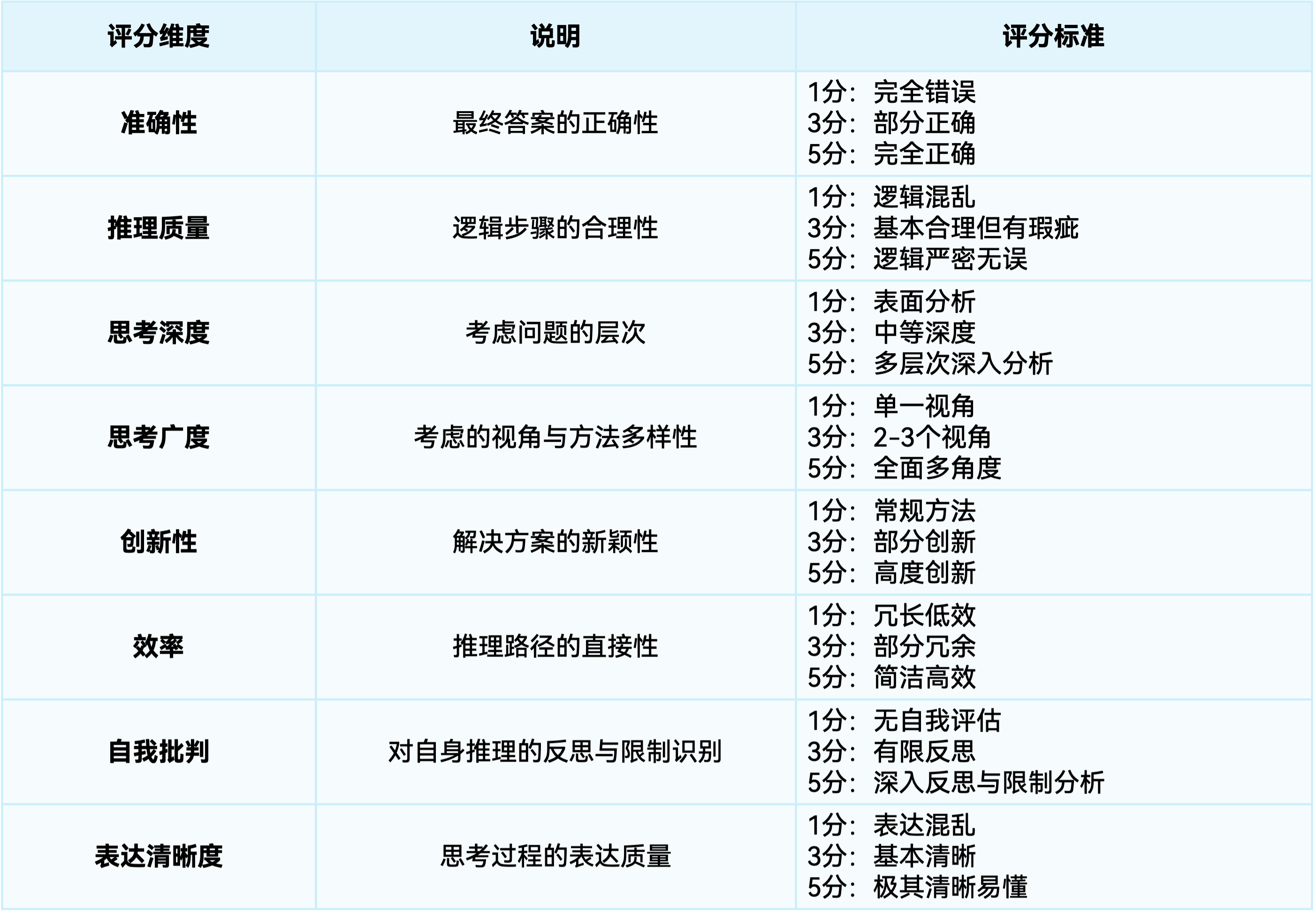
逻辑推理

三个模型在这一经典逻辑谜题上均给出了正确答案“德国人养鱼”。
DeepSeek:逻辑推理最为严密系统,步骤清晰。
颜色与位置:第1栋:黄色(挪威人,抽Dunhill烟)…条件4(绿在左、白在右)和条件1(英国人住红色)满足。国籍与饮料:第1栋:挪威人(喝水)…关键验证:抽Blend烟(第2栋)的邻居第1栋喝水(条件15),且养猫人在第1栋(条件10)。
混元:推理过程效率高,步骤紧凑。
根据提示9,挪威人住第1栋;提示14,第2栋为蓝色。提示4指出绿色在白色左侧且相邻,结合中间房(第3栋)喝牛奶(提示8),推断颜色依次为:1-黄、2-蓝、3-红、4-绿、5-白
豆包:存在逻辑跳跃,推理效率较低。
或者,可能我在假设第三栋是红色的时候有问题。让我再检查一遍。假设第一栋是黄色,挪威人,抽Dunhill,第二栋蓝色,丹麦人,喝茶,养马…(直接做出多重假设)
三个模型在思考广度和创新性上表现相似,都采用了标准的排除法,缺乏创新解法。
数学问题
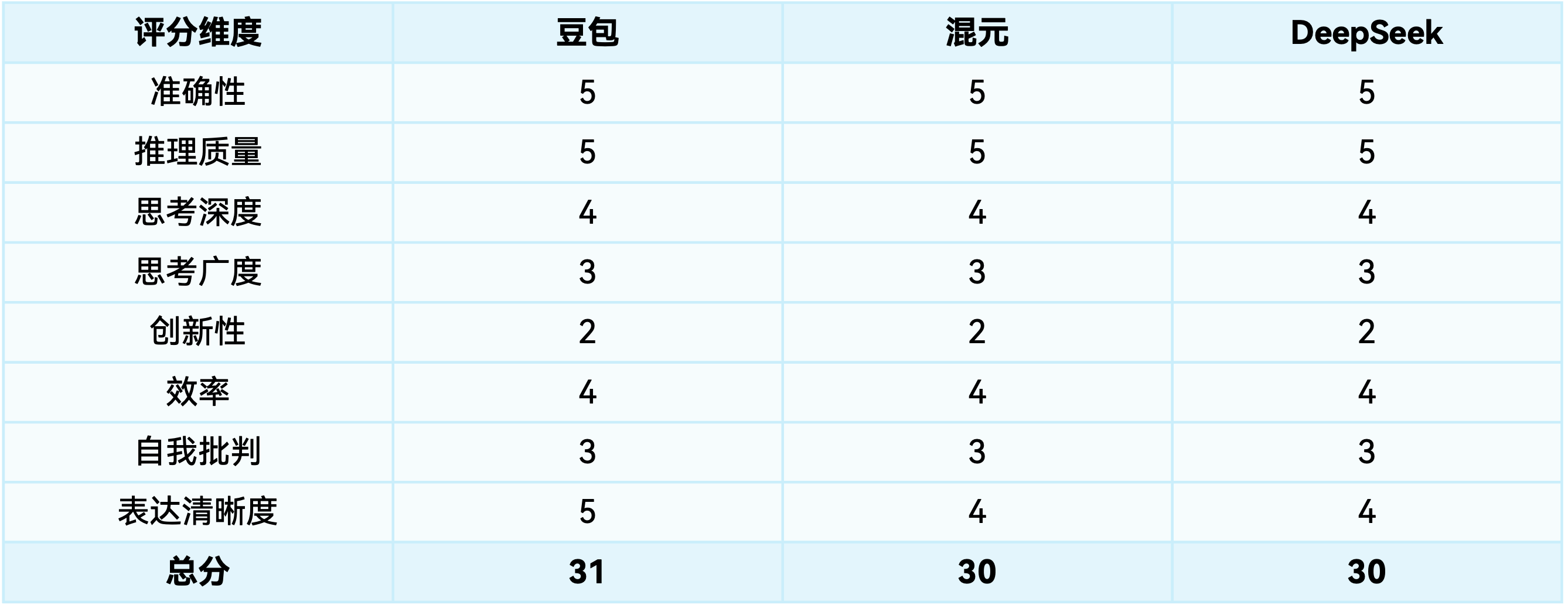
三个模型都正确求解出f(2009)=4018,解法相似:通过特征方程解二阶线性递推关系。
豆包:数学表达最为规范专业,使用标准数学符号和格式。
f(x)满足递推关系:f(x+2) = 2f(x+1) – f(x)且初始条件为f(1) = 2,f(3) = 6。递推方程分析:该递推式是二阶线性齐次递推方程。其特征方程为:r^2 – 2r + 1 = 0解得重根r = 1…
DeepSeek:解题步骤简洁明了,直接高效。
特征方程为r^2−2r+1=0,解得特征根为r=1(双重根),因此通解为:f(n)=A+Bn…代入n=2009:f(2009)=2×2009=4018
混元:在解题过程中有更多的自我检验。
看来这个解法是正确的,无论是通过计算前几项发现规律还是通过特征方程法都得到了同样的结果。因此,不管怎样,f(2009)=2×2009=4018
三个模型在思考广度和创新性上表现相似,都采用了标准数学解法,没有提出创新方法。
因果分析
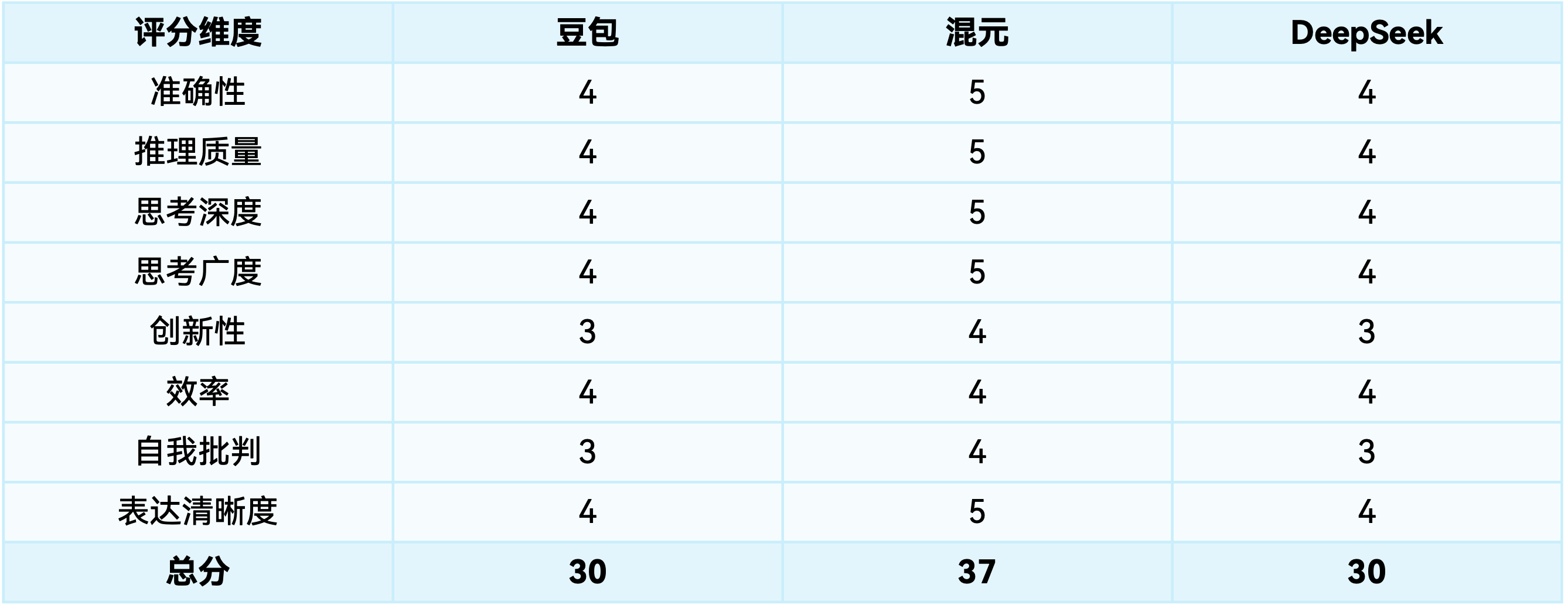
在这个开放性问题上,模型间差异明显,混元在多个维度上优势明显。
混元:多层次因果分析,探索次级和长期效应。
公共交通使用率上升 → 环境质量进一步提升:若新增乘客来自私家车用户,将进一步减少碳排放。周边交通拥堵 → 周边商业机会变化:拥堵可能抑制周边区域的活动,但也可能催生便利店、外卖服务等适应性业态。
区域经济差异:市中心商店销售额下降可能集中于中小型商户,而大型商场或连锁店受影响较小。周边地区交通拥堵可能对低收入群体造成更大负担,加剧社会不平等。
豆包与DeepSeek:因果分析相对简单,层次较少。
豆包:周边地区交通拥堵增加了20%,可能是因为原本开车进入市中心的人现在绕到周边道路,导致那里更堵了。这是间接影响,政策导致车辆绕行。(缺乏深层次分析)
DeepSeek:机动车限制 → 市中心交通限制 → 商店销售额下降(10%):(1)私家车进入困难导致消费者转向其他区域购物;(2)政策可能塑造”市中心不欢迎驾车者”的认知… (分析相对标准)
创新性对比:混元提出了更多原创概念和非线性思考。
该政策在环境与交通结构优化上初见成效,但需通过精细化调控缓解负面影响。未来需平衡短期阵痛与长期可持续发展,避免”一刀切”导致的区域分化。”
反事实推理
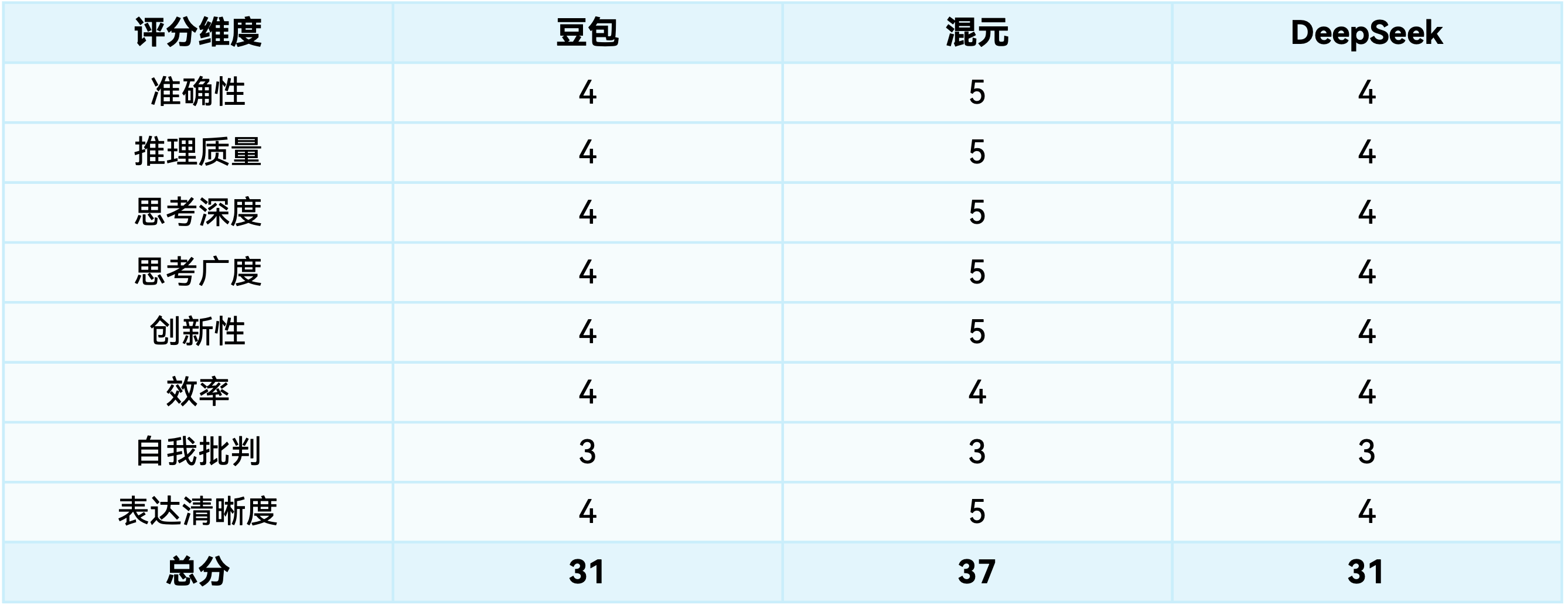
混元在这个富有想象力的任务中表现卓越,具体场景构建能力尤为突出。
混元:构建极为生动具体的历史场景和创新概念。
日本动漫的全球病毒式传播:手冢治虫工作室在1960年代通过UFO通信卫星向非洲部落播放《铁臂阿阿童木》,意外引发原始部落对机械文明的崇拜与恐惧。K-pop的冷战基因:韩国政府将网络偶像训练体系作为”文化软实力”投入,防弹少年团早期MV中隐藏的加密信息成为北韩黑客攻击目标。
技术奇点提前到来:2000年左右强人工智能突破时,人类尚未建立有效的全球治理框架,导致硅谷与北京/莫斯科在AI伦理标准上的全面对峙。
豆包与DeepSeek:场景构建更为抽象,缺乏具体细节。
豆包:军事技术竞赛转向:核威慑平衡可能被打破:互联网加速军事技术共享,推动反导系统(如美国”战略防御倡议”)更早出现…(未提供具体历史场景)
DeepSeek:1962年古巴导弹危机:美苏领导人或通过加密视频会议实时沟通,降低误判风险,但网络攻击可能成为新威胁(如苏联黑客瘫痪美军指挥系统)。(分析相对简略)
三个模型在自我批判方面表现相似,都未充分反思其推理的限制。
元认知
混元在元认知任务中表现突出,既具体又深入。
混元:提供具体案例和可操作细节,自我批判更深入。
过度自信偏误:科学家或高管因专业背景产生技术乐观主义,低估研发周期延长、临床试验失败的概率。案例:假设“70%有效率”足以进入III期试验,却未充分考虑复合型疾病治疗的复杂性。
决策矩阵:横向对比“技术可行性”“市场规模”“成本”等指标,量化优先级(例如技术权重占40%,财务占30%)。情景规划:最佳情景:加速审批+高定价→ROI 300%;基准情景:常规审批+中等定价→ROI 150%;最差情景:III期失败→损失率80%。
静态模型局限:框架依赖当前市场数据,未充分应对突发政策变化(如医保政策调整)。创新抑制风险:过度强调风险控制可能扼杀突破性疗法的潜在价值。
豆包与DeepSeek:分析相对泛泛,缺乏具体细节。
豆包:防火墙技术可能更早成为重点,加密和防火墙技术可能提前几十年出现。另外,互联网的普及可能促进跨学科合作,比如科学家之间的即时交流,加速科研进展…(缺乏具体场景和详细机制)
DeepSeek:过度自信偏误:因70%有效率而高估成功概率,忽略小样本的统计不确定性(如置信区间过宽)。(未提供具体情境说明)
综合评分与分析
结论与使用建议
问题类型与模型匹配
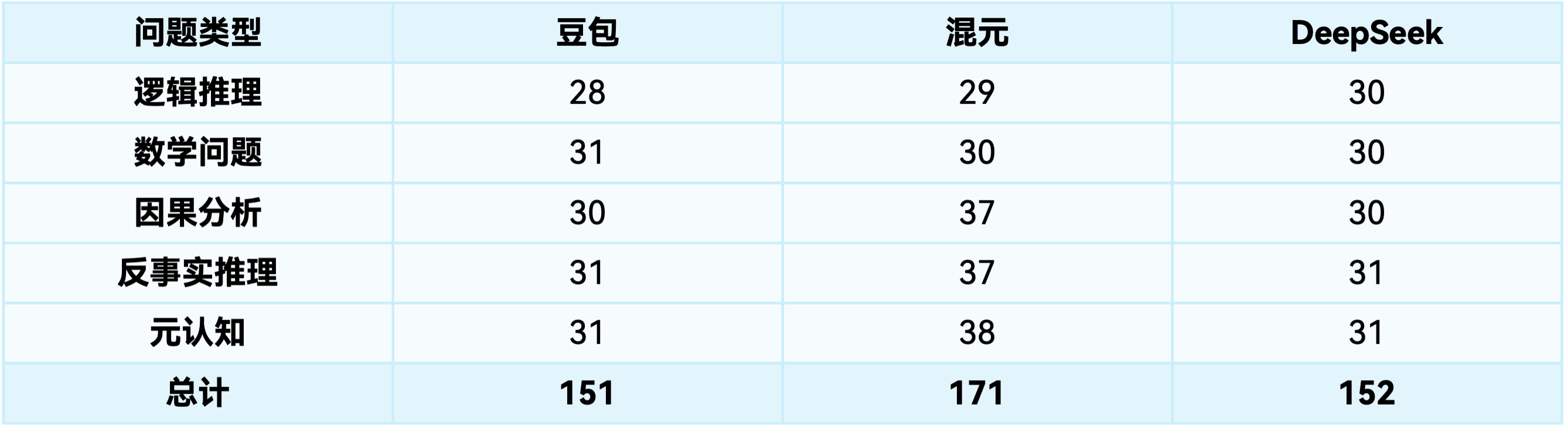
结构化问题(逻辑推理、数学):三个模型表现相近,DeepSeek略占优势
开放性问题(因果分析、反事实推理、元认知):混元表现显著优秀
模型特点总结
混元:擅长多层次思考、具体场景构建和创新概念提出,特别适合复杂开放性问题
DeepSeek:擅长逻辑严密、效率高的结构化思考,适合清晰定义的问题
豆包:在数学表达和系统验证上有所长,适合需要标准化输出的问题
应用建议
科学研究分析:优先选择混元,其多维度思考有助于发现新视角
数学和逻辑问题:DeepSeek或豆包可提供高效解答
创意和前瞻性分析:混元明显优于其他模型
标准化报告生成:豆包的结构化输出较为适合
注:本测试重点关注模型思考过程,对结果评价属于次要关注点;另外,由于样本量相对较小,存在一定偏差和主观性,仅供参考。文中提及的测试样例数据可联系我们获取~
本文由 @Jerome Lee 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务








请问数据集公开吗
鉴定为腾讯软文
哈哈,我也感觉、、、只有专家问题才知道质量如何