
 起点课堂会员权益
起点课堂会员权益医疗产品经理必看:RAG技术在AI问诊中的创新实践与突破
RAG不是“检索+生成”的拼接,而是“认知+协作”的重构。本文将系统解析RAG技术在AI问诊场景中的创新实践,从底层机制、场景适配到产品设计逻辑,构建一套可落地的医疗产品认知框架,帮助产品经理把握AI医疗的关键突破口。

一、RAG 是什么?—— 重新定义 AI 生成的 “开卷考试” 模式
1. RAG 的核心概念与技术本质
检索增强生成(Retrieval-Augmented Generation,RAG)是融合大规模语言模型(LLM)与外部知识检索的前沿框架。其核心逻辑是 “先检索后生成”:通过向量数据库实时调取专业知识库中的精准信息,作为 LLM 生成回答的 “参考答案”,使 AI 从依赖内部记忆的 “闭卷考试” 转变为可动态调用外部知识的 “开卷考试”。技术本质是 In-Context Learning 的工程化实现,通过 “检索技术 + 提示工程” 的有机结合,突破传统 LLM 的知识边界。
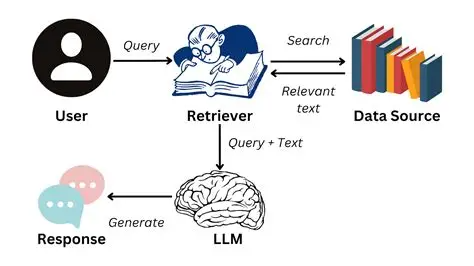
2. RAG 的核心技术流程
将医学指南(如 NCCN、UpToDate)、电子病历(EMR)等多源数据切割为 200-500 字的语义块(Chunk),保留标题层级结构(如 “糖尿病诊疗指南 – 用药原则”),便于后续检索定位。
利用 BERT、Sentence-BERT 等嵌入模型,将文本块转化为高维向量,存入 Milvus、FAISS 等向量数据库,构建语义索引。这种方式如同为每个知识点创建 “GPS”,能精准匹配语义相近的内容,比如 “高血糖” 与 “糖耐量受损” 即便词汇不同也能被关联。
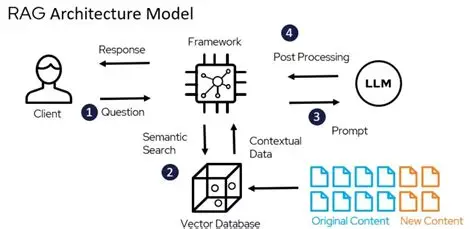
用户提问转化为向量后,通过余弦相似度匹配 Top-K 相关文本块,与问题拼接成提示词输入 LLM 生成精准回答。阿里健康的智能问诊平台就采用这种流程,当用户问 “肾脏损伤的糖尿病患者用什么降糖药” 时,系统会先检索指南、药品说明书等资料,再生成带溯源标签的回答。
二、RAG 如何破解 LLM 三大痛点?—— 从理论到实践的突破
1. 突破知识局限性:打造动态更新的 “超级大脑”
传统 LLM 的知识截止于训练数据,面对 2024 年新版《中国高血压防治指南》等最新内容时无法准确应答。RAG 通过实时加载外部知识库实现 “模型不变,知识常新”:

接入 2025 年 ADA 糖尿病诊疗指南后,对 “合并肾病的 2 型糖尿病用药” 回答准确率从 72% 提升至 94%,且支持指南发布后 48 小时内完成知识更新。
其 RAG 系统按 “教科书 – 指南 – 论文” 分层构建知识库,《哈里森内科学》等经典教材构建基础框架,最新临床研究按季度补充,确保慢性病管理建议的时效性。
2. 抑制生成幻觉:让 AI 回答 “有凭有据”
LLM 因概率生成特性易产生 “幻觉”,如将 “奥司他韦” 适应症错误扩展至普通感冒。RAG 通过双重约束机制解决此问题:
仅基于知识库中存在的权威信息生成回答,未检索到相关内容时提示 “信息不足”;在回答中嵌入知识来源,用户可点击溯源原文。
春雨医生智能助手回答 “心梗后用药” 时,会标注 “根据《2025 急性冠脉综合征诊疗指南》[P47]”“源自《新英格兰医学杂志》2025 年 3 月研究”,用户点击即可查看原文片段,药物咨询错误率从 22% 降至 4.1%。
其 GraphRAG 系统对 “降糖药禁忌症” 的回答,会同步展示药品说明书原文截图和指南对应章节,医生可交叉验证信息准确性。
3. 守护数据安全:医疗隐私的 “数字保险箱”
医疗场景中,患者电子病历、基因检测报告等敏感数据严禁上传至公共云端。RAG 支持本地化部署:
为三甲医院定制的 RAG 系统,将脱敏病历存储在医院本地 Milvus 向量库,仅授权科室医生访问,患者问诊数据全程不流出医院内网。
通过 AnalyticDB PostgreSQL 实现 “向量库 – 图数据库 – 关系库” 三库合一的本地化部署,对肿瘤患者病历采用 “字段级脱敏 + 权限分级” 管控,仅主任医师可检索完整诊疗记录。
三、RAG 在医疗问诊领域的深度应用 —— 重构智能诊疗流程
1. 智能问诊机器人:从 “症状匹配” 到 “临床推理”
1)应用场景:全流程问诊辅助
患者描述 “反复胸痛伴呼吸困难” 后,系统检索《胸痛诊治指南》与本院 3 万例相似病历,生成鉴别诊断列表(心绞痛、肺栓塞等),并通过多轮追问补充 “疼痛放射部位”“诱发因素” 等关键信息,最终推荐心内科或呼吸科分诊。
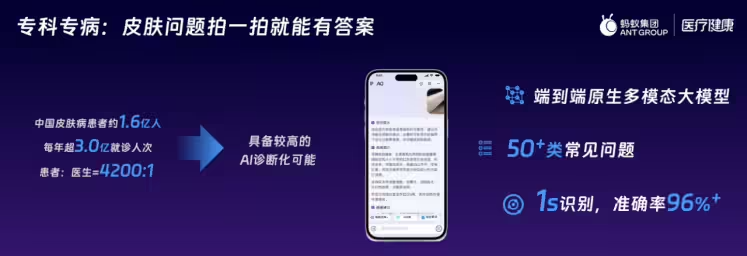
针对 “持续发热三天” 等模糊主诉,GraphRAG 系统通过知识图谱关联 “发热 – 伴随症状 – 可能疾病” 关系,主动追问 “是否咽痛”“有无皮疹”,将诊断范围从 20 余种收敛至 3-5 种,匹配准确率提升 67%。
2)技术原理:知识图谱增强推理
阿里健康采用 MedRAG 模型构建四层诊断知识图谱:
L1(疾病大类)→ L2(疾病子类)→ L3(具体疾病)→ L4(疾病表征),如 “心血管疾病→冠状动脉疾病→心绞痛→压榨性胸痛”;

通过临床特征分解和语义匹配算法,计算患者症状与图谱节点的相似度,向上遍历定位疾病大类,再向下匹配具体疾病。该系统在陈笃生医院慢性疼痛数据集上的诊断准确率,较传统 RAG 提升 11.32%。
2. 病历智能解析:从 “信息提取” 到 “诊疗建议”
1)应用场景:结构化病历处理
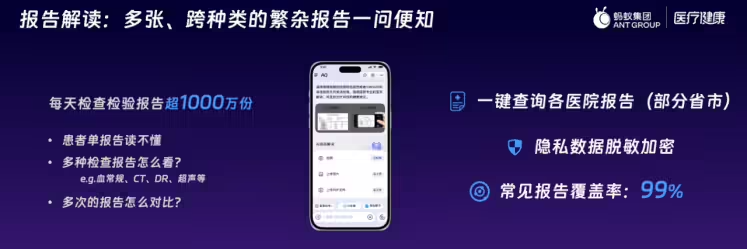
接收 “急性胰腺炎” 患者病历后,RAG 系统自动提取血尿淀粉酶数值、CT 影像描述等关键指标,对比《急性胰腺炎诊治指南》分级标准,生成 “是否需转入 ICU” 的可视化建议报告,急诊医生处理效率提升 40%。
针对糖尿病合并肾病患者的处方,同步检索药品说明书(如 “某 SGLT2 抑制剂禁用于 eGFR<30ml/min 患者”)与患者肾功能指标,自动标记 “剂量异常” 处方,医保拒付率下降 28%。
2)技术原理:双库融合检索机制
包含医学指南、药品目录等权威文件,采用 MarkdownHeadSplitter 按标题层级切分,确保 “高血压 – 并发症 – 肾病” 等关联知识的完整性;
实时接入医院 HIS 系统,对患者过往数据脱敏后按 “疾病 – 症状 – 治疗” 维度构建索引。检索时采用 “语义检索 + 规则校验”,如查询 “二甲双胍禁忌症” 时,既匹配指南描述,又校验患者当前肾功能指标。
3. 科研辅助决策:从 “文献调研” 到 “证据合成”
1)应用场景:临床研究支持
输入 “司美格鲁肽在肥胖患者中的长期安全性”,RAG 系统同步检索 PubMed 近 3 年论文、FDA 不良反应报告,生成包含 “不同剂量组副作用发生率”“合并心血管疾病风险” 的证据矩阵,帮助医生快速撰写综述。
基于 5000 例脑卒中患者病历与《中国脑卒中防治指南》,GraphRAG 系统分析 “静脉溶栓时间窗与预后关系”,为科室制定 “6 小时内分层溶栓方案” 提供数据支撑,患者致残率下降 12%。
2)技术原理:多源数据协同检索
通过 Apache Tika 解析 PDF 文献、OCR 提取影像报告文本,统一转换为纯文本后分块向量化;
按 “临床指南> 随机对照试验 > 回顾性研究” 设置优先级,检索结果按 “证据等级 + 语义相似度” 排序,确保科研报告符合循证医学原则。
四、RAG 落地医疗场景的关键挑战与未来方向
1. 当前技术瓶颈
复杂诊断问题(如 “肺癌脑转移患者是否适合免疫治疗”)需整合病理、基因、药物等多维度信息,现有 RAG 在跨模态检索上仍需优化,阿里 GraphRAG 在这类问题上的准确率仅 78%;
春雨医生针对罕见病 “渐冻症早期分型” 的检索召回率仅 59%,因知识库中相关病例不足百例;
急诊场景需 10 秒内生成回答,对向量数据库检索效率提出更高要求。
2. 前沿发展方向
阿里正在测试的智能体架构,可自动判断是否调用 SQL 工具查询患者检验数据,或触发二次检索验证信息准确性;
融合医学影像、心电图等非文本数据,通过 CLIP 模型实现跨模态语义对齐,春雨医生已试点 “症状描述 + CT 影像” 联合检索系统;
在保护隐私前提下聚合多中心数据,阿里与 3 家三甲医院合作训练的嵌入模型,对罕见病检索召回率提升至 83%。
五、RAG 开启医疗 AI “精准化” 时代
从春雨医生的预问诊机器人到阿里健康的 GraphRAG 引擎,RAG 正推动医疗 AI 从 “通用助手” 进化为 “专科医生的智能搭档”。它不仅是技术框架的创新,更是诊疗流程的重塑 —— 通过精准检索临床指南、动态关联患者病历、实时校验诊疗建议,让 AI 真正融入医疗决策链条。随着向量数据库、知识图谱等技术的演进,RAG 有望成为智慧医疗的核心基础设施,开启精准医疗的新篇章。
本文由 @而立与拾遗 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


