
 起点课堂会员权益
起点课堂会员权益Andrej Karpathy 《Agent十年》访谈精读
从特斯拉到OpenAI,Andrej Karpathy始终站在AI浪潮的前沿。在这场关于“Agent十年”的访谈中,他不仅回顾了智能体技术的演进脉络,更抛出了对未来AI形态的深刻判断。本文将带你精读访谈内容,拆解Karpathy的核心观点,理解“Agent”如何成为AI下一个十年的关键词。

我们是唤醒“幽灵”,而非塑造“生命”
一、智能体时代的历史性转折
Andrej Karpathy(之后简称AK)认为,当前行业对LLMs演进的预测过于乐观,反对“Agent之年”的说法。他更倾向于将其描述为“Agent的十年”。尽管当前已有令人印象深刻的早期智能体(比如Claude与Codex),不过还是要注意,真正让智能体发挥作用还需要十年左右的时间。并且他还强调说:
AI代理的成熟需要解决多模态、持续学习和计算机使用等核心挑战,但是这短期并不能实现。
Agent应该只是受你支配的“初级员工”,它们现在因为“缺乏实践”(Fundamentally Don’t Work)而不能胜任真实工作。智能缺失、持续学习能力差、多模态能力与电脑的真实操控虽然最终是能够克服解决的,但这非常难。
回顾人工智能的发展:
1.深度学习崛起:AK职业生涯初期,深度学习是个小众的科目。AlexNet的出现改变了这一切,促使所有人开始针对特定任务进行神经网络的训练。
2.早期智能体的尝试(强化学习的失策):2013年左右的Atari深度强化学习是早期智能体的努力之一。AK人为这种专注于游戏和强化学习环境的做法是“失策”。他曾在OpenAI试图建立一个能在网页上操作、运行知识工作的智能体(Universe项目)。
Universe项目于2016年发布,是OpenAI的一个开源框架,旨在创造超过1000个环境(包括Flash游戏、浏览器任务和Slither.io或GTA V等游戏)来支持强化学习代理在“World of Bits”中训练。目标是开发一个能快速适应新环境的通用代理,但因为当时能力不够强(预训练模型不够强大等原因)没能实现AGI。 为后续Anthropic的Claude代理等奠定基础。
3.LLMs与表现能力:当前阶段重点关注LLMs(神经网路有关),且当前的Agents完全依赖于大语言模型。
对于AGI的愿景展望:当前AI是通过学习目前人类已有的数据信息进行训练的,并不是像动物演化一样需要各式各样的“硬件条件”——我们唤醒的是“幽灵”,而非塑造“生命”。AK表示:预训练是当前技术下能达到智能起点可行的“蹩脚的演化”(Crappy Evolution)。
LLMs是“人类智慧的精华”(Statistical Distillation of Humanity),而非“机械生命”的创造
二、Agent的认知核心和瓶颈
AK指出“预训练实际上在做两件事:收集知识 + 智能学习”。另一个角度来想,模型有时会过于依赖知识导致创新性被拖累。未来研究方向之一就是找到一种方法去去除部分知识,只保留“认知核心”。(最近的DeepSeek-OCR是上下文压缩技术,并不属于此范畴)
认知核心:剥离了知识但包含智能算法和问题解决策略的实体。(AK在nanochat项目实验中的概念)
nanochat项目实验:通过从FineWeb-EDU数据集预训练小型Transformer模型,探索如何在低参数规模下保留核心智能。
上下文学习(ICL)与工作记忆
模型最能够体现“智能”的部分——上下文学习(ICL)
ICL:通过预训练中的梯度下降自发产生的元学习。ICL本质上是在令牌窗口内进行模式补全(还有研究表明神经网络内部也存在ICL小的梯度下降循环)
AK把预训练中压缩的只是成为对互联网文档的“模糊回忆”。相比之下,ICL中使用的KV缓存就更像是工作记忆(Working Memory)。KV缓存极其在测试时发生的事情,每接收一个新令牌,存储的信息量要比预训练高3500万倍。
模型的认知缺陷与持续学习
目前LLMs在模仿复制人脑智能还是有很多缺点,尽管Transformer神经网络强大通用,不过除了皮层组织之外的海马体和杏仁体等还是未能探索。
模型最大的缺陷之一就是缺乏持续学习的能力。当前模型总是从头开始重启,缺乏将上下文通过蒸馏(Distillation)到模型“大脑”的阶段。
尤其是强化学习(RL),AK称这个方式不应该用来完成智能任务。RL仅通过最终奖励来指导整个轨迹,即使其中会包含错误的步骤也会上调权重,这种极其“片面的监督”是非常愚蠢且疯狂的。(比如,nanochat用简化的GRPO过渡工具来处理GSM8K数学问题)。
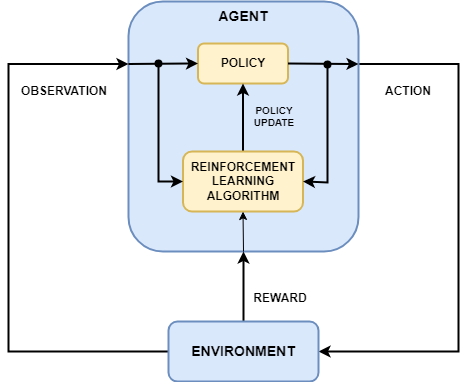
过程监督(Process-based Supervision,过程中的每一步进行反馈)因为动态分配权重困难而难以实现。如果用LLM裁判分配奖励,模型会找到对抗例子来作弊(“dhdidhsi”等荒谬输出可能获得100%奖励),本质上是把RL模型训练成了“提示词作弊”(Prompt Injection)模型
模型坍塌与认知核心规模
LLMs缺乏熵,在生成样本时会“无声坍塌”。如果模型持续训练用于自己产生的合成数据,会有更严重的坍塌。熵在信息论中指代可能选项的多少,熵越是高,LLM产出的结果越多样,反之则越少。在不断的训练中,模型会自发地把概率质量挤向极少数路径,最终坍塌成固定的结果。
AK认为LLMs极其擅长记忆化,这会分散了它们的注意力;人类不擅长记忆化,这反而是优势,因为会迫使人类寻找更一般的模式。未来的认知核心规模可能只需要约10亿参数。现有的巨大参数模型(比如阿里巴巴的Qwen3-Max系列、蚂蚁的Ring-1T、Minimax的abab6.5)是因为训练数据质量不高,目前大模型大部分只是在做记忆工作,而不是认知工作。
三、编程、自动化与AGI展望
AI应该是计算编程的延伸拓展,是一个能逐步把更多东西自动化的“自主性模块”。但是编程模型的缺陷也不少:过度防御、构建生产级别的代码、使用过期的API、误解代码等。

另一个方面来说,与编程模型的交互中的“自动补全”才是最理想的。只要输入很少的前面几个字母,就能够让编程模型进行小模块的补全。
目前来说,通用模型的API收入绝大部分是集中在Coding上的。
对于超级智能爆炸的预测,AK有着完全不一样的看法:智能爆炸已经到来,并成为自动化的延续,像电脑、手机等产品一样慢慢扩散并最终融入社会。而相当大的忧虑是在于对AI的失控和理解,最终诞生极为陌生的文明。
“自动驾驶”就是个最好的例子,本身这项技术远远没有完成,从演示到产品的巨大鸿沟需要不断在99%之后添加9,每一次都要有相当的工作量。
引用
Andrej Karpathy — AGI is still a decade away:https://www.dwarkesh.com/p/andrej-karpathy
Andrej Karpathy — AGI is still… – Dwarkesh Podcast – Apple Podcasts:https://podcasts.apple.com/us/podcast/andrej-karpathy-agi-is-still-a-decade-away/id1516093381?i=1000732326311
Andrej Karpathy’s AGI prediction:https://www.theneurondaily.com/p/andrej-karpathy-s-agi-prediction
Techmeme: Q&A with Andrej Karpathy on AGI still being a decade away…:https://www.techmeme.com/251017/p26
Andrej Karpathy — AGI is still a decade away – YouTube:https://www.youtube.com/watch?v=lXUZvyajciY
AGI is still a decade away, today’s AI agents are slop: OpenAI cofounder Andrej Karpathy – The Economic Times:https://economictimes.indiatimes.com/tech/artificial-intelligence/agi-is-still-a-decade-away-todays-ai-agents-are-slop-openai-cofounder-andrej-karpathy/articleshow/124716487.cms?from=mdr
Andrej Karpathy — AGI is still a decade away:https://simonwillison.net/2025/Oct/18/agi-is-still-a-decade-away/
GitHub – karpathy/nanochat: The best ChatGPT that $100 can buy.:https://github.com/karpathy/nanochat
Introducing nanochat: The best ChatGPT that $100 can buy. · karpathy/nanochat · Discussion#1:https://github.com/karpathy/nanochat/discussions/1
Andrej Karpathy Releases ‘nanochat’: A Minimal, End-to-End ChatGPT-Style Pipeline… – MarkTechPost:https://www.marktechpost.com/2025/10/14/andrej-karpathy-releases-nanochat-a-minimal-end-to-end-chatgpt-style-pipeline-you-can-train-in-4-hours-for-100/
Build ChatGPT Clone with Andrej Karpathy’s nanochat:https://www.analyticsvidhya.com/blog/2025/10/andrej-karpathys-nanochat/
GitHub – karpathy/micrograd: A tiny scalar-valued autograd engine…:https://github.com/karpathy/micrograd
Neural Networks: Zero To Hero:https://karpathy.ai/zero-to-hero.html
本文由 @天故有白 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


