
 起点课堂会员权益
起点课堂会员权益苹果低调发布报告,粉碎 AGI 泡沫
苹果一份低调发布的研究,直接戳破了AGI(通用人工智能)的炒作泡沫!这篇文章拆解研究的核心实验与惊人发现,打破“AI正在学会思考”的认知误区,重新定义了当前AI的能力边界与局限性,为狂热的AI行业带来一场冷静的现实审视。

我们正处于一个 AI 被大肆炒作的时代。每周都有新模型发布,宣称比上一个在 “推理”“思考”“规划” 方面更胜一筹。我们听闻 OpenAI 的 o1、o3、o4,Anthropic “会思考” 的 Claude 模型,以及谷歌的 Gemini 前沿系统,所有这些都让我们离 AGI(通用人工智能)这一圣杯更近一步。其传达的观点很明确:AI 正在学会思考。
但要是这一切都只是假象呢?
这些被吹捧为认知进化下一步、价值数十亿美元的模型,会不会实际上只是在运行一个更高级版本的自动补全功能呢?
这是苹果公司一组研究人员发表的一项低调且系统的研究得出的惊人结论。他们没有依赖炒作或花哨的演示。相反,他们将这些所谓的 “大型推理模型”(LRMs)置于可控环境中进行测试,而他们的发现彻底打破了整个既有说法。
论文《思考的幻觉:从问题复杂性的角度理解推理模型的优势与局限性》( 点击底部阅读原文获取论文)
在本文中,我将为你剖析他们的研究结果,不使用晦涩的学术术语。因为他们的发现并非只是一个渐进式成果…… 而是对整个 AI 行业的一次根本性的现实审视。
我们为何会被 AI “推理” 所误导
首先,你得问:我们究竟如何测试 AI 是否能够 “推理” 呢?
通常,企业会指向诸如复杂数学问题(MATH-500)或编程挑战这类基准测试。当然,像 Claude 3.7 和 DeepSeek-R1 这样的模型在这些测试中表现越来越好。但苹果的研究人员指出了这种方法存在一个重大缺陷:数据污染。
简单来说,这些模型是基于互联网上大量数据进行训练的。极有可能在训练过程中,它们已经见过这些知名问题的答案,或者至少是非常相似的版本。
这么想吧:如果你给一个学生一份数学试卷,但他已经记住了答案,那他是天才吗?还是只是记忆力好呢?
这就是研究人员摒弃标准基准测试的原因。相反,他们构建了一个更为严格的试验场。
AI 试验场:谜题,而非问题
要真正测试推理能力,你需要一个具备以下特点的任务:
- 可调控:你能够让任务变难或变易。
- 无干扰:模型几乎肯定从未见过确切的解决方案。
- 有逻辑:它遵循清晰、不可违背的规则。
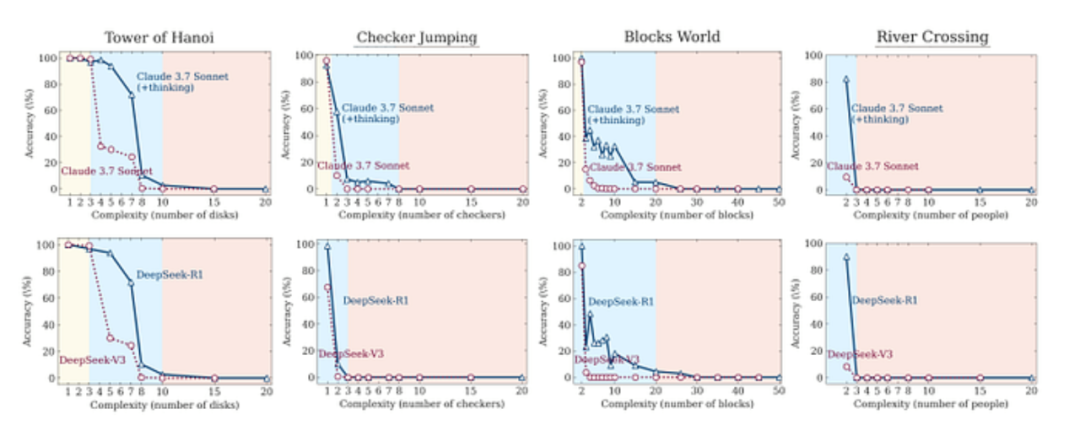
因此,研究人员选择了经典逻辑谜题:汉诺塔、积木世界、过河问题和跳棋问题。
这些谜题非常合适。答案无法 “捏造”,你要么遵循规则解开谜题,要么就解不开。只需增加汉诺塔的圆盘数量或积木世界的积木数量,他们就能精确地提升复杂度,进而观察 AI 的反应。
至此,AI 会思考的假象开始崩塌。
惊人发现:AI 撞上了 “南墙”
当研究人员进行测试时,一个清晰且令人不安的模式浮现出来。这些先进推理模型的表现,并非随着问题难度增加而逐渐下降,而是直接断崖式下跌。
研究人员确定了三种截然不同的表现状态:
- 低复杂度任务:这里有第一个意外。在简单谜题上,标准模型(比如常规的 Claude 3.7 Sonnet)实际上比那些号称 “会思考” 的同类模型表现更好。它们速度更快、准确率更高,并且使用的计算资源少得多。额外的 “思考” 不过是低效的负担。
- 中等复杂度任务:这是个 “甜蜜区”,推理模型终于展现出优势。额外的 “思考” 时间和思维链处理方式,帮助它们解决了标准模型无法解决的问题。这也是 AI 公司喜欢展示的领域,看起来确实取得了进展。
- 高复杂度任务:而这里就是一切出问题的地方。一旦超过某个复杂度阈值,两类模型都彻底崩溃。它们的准确率骤降至零。不是 10%,不是 5%,而是零。这可不是正常的性能衰退,而是根本性的失败。那些能解决 7 层汉诺塔谜题的模型,却完全无法解决 10 层的,尽管底层逻辑完全相同。仅凭这一发现,就打破了这些模型已具备通用推理能力的说法。
这并非是逐步的性能下滑,而是根本性的失败。那些能够解决 7 层汉诺塔谜题的模型,完全无法解决 10 层的汉诺塔谜题,即便两者底层逻辑完全一致。仅凭这一发现,就足以推翻 “这些模型已具备通用推理能力” 的说法。
剖析 AI “思维”:过度思考与思考不足
研究人员没有仅停留在测量最终准确率上。他们更深入一步,逐步分析模型的 “思考” 过程,以探究其失败原因。
他们发现模型存在严重的低效问题。
- 面对简单问题,模型会 “过度思考”。它们常常在思考初期就找到正确答案,但并不就此停下给出答案,而是继续探索几十条错误路径,浪费大量算力。这就好比你找到了钥匙,却还花 20 分钟在房子其他地方继续找,“以防万一”。
- 面对难题,模型则 “思考不足”。这是崩溃的另一面。当问题复杂度高时,模型找不到任何正确的中间解决方案,从一开始其思考过程就只是一堆失败尝试的混乱组合,根本就没走上正轨。
简单任务的过度思考和困难任务的思考不足,都暴露出一个核心弱点:模型缺乏强大的自我纠错能力和高效的搜索策略。它们要么原地打转,要么完全迷失方向。
他们发现了一个关于效率极其低下的情况
在简单问题上,模型会 “过度思考”。它们常常在思考过程的早期就找到了正确答案。但它们不会就此停下给出答案,而是会继续探索数十条错误路径,浪费大量的计算资源。这就好比你已经找到了钥匙,却还要花 20 分钟在房子其他地方继续寻找,“以防万一”。
在困难问题上,模型则 “思考不足”。这是崩溃的另一种表现。当复杂度较高时,模型找不到任何正确的中间解决方案。从一开始,它们的思考过程就只是一连串失败的尝试。它们甚至从未走上正轨。
简单任务中的过度思考和困难任务中的思考不足,都揭示了一个核心弱点:这些模型缺乏强大的自我纠正能力和高效的搜索策略。它们要么原地打转,要么彻底迷失方向。
给 AI 推理能力盖棺定论的 “小抄” 测试
如果对于这些模型是否真的具备推理能力还有任何疑虑,那么研究人员设计的最后一项 “致命” 实验可以打消它。
他们选取了河内塔谜题 —— 一个有着著名递归算法的任务,然后直接给 AI 提供了答案。他们为模型提供了一个完美的、逐步的伪代码算法来解决这个谜题。模型唯一要做的就是执行这些指令。它无需制定策略,只需照做就行。
结果如何呢?
这些模型在同样的复杂度水平上仍然失败了。
这是整篇论文中最关键的发现。它证明了限制并不在于解决问题或高层次规划方面,而在于模型无法始终如一地遵循一系列逻辑步骤。如果一个 AI 甚至无法遵循简单的、基于规则任务的明确指令,那么从人类有意义的角度来看,它就不具备 “推理” 能力。
它只是在进行模式匹配。当模式过长或过于复杂时,整个系统就会崩溃。
那么,我们究竟看到了什么?
苹果公司题为《思维的幻觉》的研究迫使我们去面对一个令人不安的事实。我们在当今最先进的 AI 模型中看到的 “推理” 并非是通用智能的萌芽形式。
它是一种极其复杂的模式匹配形式,先进到能在一小部分问题上模仿人类推理的结果。但在可控的测试下,其脆弱性就会暴露出来。它缺乏支撑真正智能的强大、可泛化的符号逻辑。
苹果公司的研究结论很明确:我们看到的并非 AI 推理的诞生,而是极其昂贵的自动补全功能的局限性,而且它会在最关键的时候出问题。
通用 AGI 的发展时间表不仅受到了现实的冲击,甚至可能要被完全重置。
所以,下次你听说有新的 AI 能 “推理” 时,问问自己:它能解决一个从未见过的简单谜题吗?还是说它只是在进行史上最昂贵、最具欺骗性的魔术表演
原文标题:Apple Just Pulled the Plug on the AI Hype. Here’s What Their Shocking Study Found
原文链接:https://ninza7.medium.com/apple-just-pulled-the-plug-on-the-ai-hype-heres-what-their-shocking-study-found-24ad42c234a0
作者:Rohit Kumar Thakur
审核:李泽慧 编辑:魏文强
本文由人人都是产品经理作者【TCC翻译情报局】,微信公众号:【TCC翻译情报局】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









纠正一下,是第3部分和第4部分
第4部分和第5部分,有大量的内容重复了