
 起点课堂会员权益
起点课堂会员权益智能体产品落地实践:20%的智能+80%的苦工
智能体产品落地过程充满挑战,需明确产品定义、选择合适架构、优化上下文策略、持续监控迭代。本文分享实践经验,探讨具体挑战与解决方案,助您更顺利地推进智能体产品落地。

我很喜欢的一句名言,出自物理学家费曼:如果我不能创造,我就不能理解。
让我用一个词来形容智能体产品的落地过程,那应该是:”痛苦”。遍地都是坑,奇怪的bug,推翻重来的架构和策略,以及测试时的自我怀疑。但回过头看,这些坑让我对智能体的理解从理论走向了实践,对许多概念的认知从抽象变得具象。犯错的好处就是让你去关注自己本来不会关注的细节。
一、实践经验
1. 明确产品定义是工程的起点
在技术实施前需要回答三个基础问题,这些问题的答案直接影响产品的落地实施和评估体系的建立。
- 产出物的具体形态是什么?
- 什么时候算成功,什么时候算失败?
- 验收标准/指标如何定义?
在我的项目中,智能体运行逻辑的多次调整根源于初期我对需求的认知不够清晰,导致”完成”与”正确”的标准始终处于模糊状态。
启示:如果这些问题没有答案,开发过程中所有人都会很痛苦,因为没人知道什么时候算”做完了”,什么时候算”做对了”。
尽管大模型驱动的各类产品,都存在输出结果难以预测和稳定控制的问题,但是设立一个动态的评估基准仍然很有必要。
不需要一次实现完美,但至少清楚的知道优化的目标和方向。对于需求和目标的定义决定了工程实施的效率,模糊的目标会导致频繁的返工。
2.成功不在于构建最复杂的系统,而在于构建最适合自身需求的系统
智能体的实现方式、实施架构层出不穷,工程化进展日新月异,但是不论是Dify、Coze这类低代码平台,还是Langgraph、Crew AI这些开发框架,又或者自己手写代码实现运行逻辑,都只是手段,最终都需要服务于产品目标,就像技术复杂度总是服务于业务价值。
聚焦解决问题,只有当增加复杂性能够显著提升产品效果时,才考虑增加复杂性。
实践中发现,过早引入复杂架构往往带来两个问题:
- 开发与调试难度指数级增长,重构和调整方向更困难
- 前期的稳定性与可控性大幅下降
项目中的编排方式选择的考量主要来自两个方面
- 任务复杂程度:如果任务复杂,高度灵活建议选择开发框架;任务步骤较为固定,建议选择低代码平台。
- 规则可维护性:如果规则不能穷尽,无法维护 建议选择开发框架;如果规则可以穷尽,有明显的规律,可以选择低代码平台。
启示:从简单的方案开始验证,在跑通逻辑闭环、业务价值得到确认后再进行技术迭代。
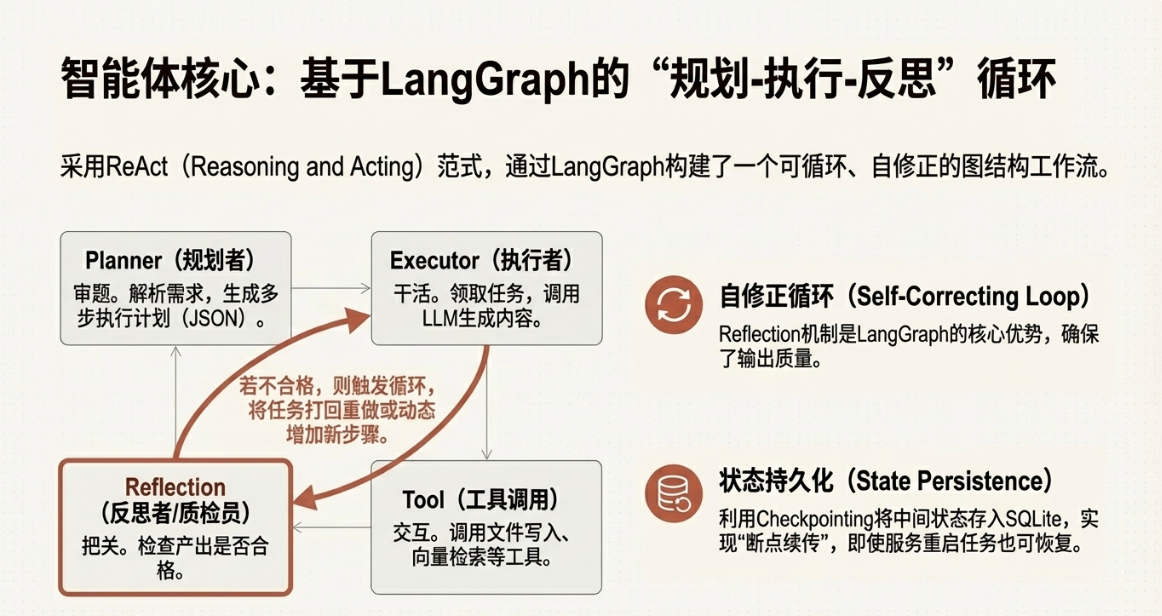
(在之前的项目中选择了langgraph框架实现智能体的编排逻辑)
3.上下文策略常常是个产品/业务问题,而不仅仅是个技术问题
尽管你可能已经看了无数讲解上下文策略设计的文章,但落到自己的项目上时,最终还是需要从实际需求出发,精雕细琢。实践证明,垂直场景需要更为定制化的上下文策略。
上下文设计的核心目标:
1、降低token成本 、提升响应速度
2、提供最精确的信息,以提升模型推理的性能,保证每一步任务质量
最终还是降本、增效、提质,这世界是一个巨大的降本增效!
遇到的具体问题:由于前期上下文实现过于粗糙,带来了两个比较显著的问题。
- 成本控制失效:3-4次测试却消耗100万token(输入+输出)。
- 生成质量不高:生成的最终产物质量十分飘忽,格式的一致性难以保证,内容可用性也相当有限。
项目中的解决策略:下面总结了在之前项目中具体的上下文策略,但建议大家在实施过程中具体问题具体分析。
通过持久化存储生成的文件信息,临时保存的状态信息、上下文动态检索、精确隔离,确保每一步行动都能获得最相关、最精准的上下文信息。保证任务完成质量,同时控制token消耗。
1、上下文存储
(1)有2类信息会被存储进知识库持久化存储
- 用户上传的最初的需求信息
- 每一个节点生成的材料产物(包括不限于产品解析、评测方案、数据集等等)
(2) 以下被作为临时的状态信息 只在当前任务中存在,不会持久存储
- 生成的任务规划列表
- 每一步的工具使用情况
2、上下文选择
每个步骤都会根据完成任务所需要的信息选择性的注入3类上下文信息
- 静态注入:最初的需求信息和系统提示词固定传入每一步,作为纲领性指导,防止在任务过程中遗忘产品需求,或者偏离主题。
- 动态注入:注入这个节点完成当前步骤所需要的具体的提示词模版
- 动态检索:每一步在执行前,都会调用向量检索,从知识库中搜索这次任务所需要的历史上下文信息
3、上下文隔离
为了让用户提交的不同任务的产物不混淆,防止记忆污染,控制注意力,在本项目中实现了会话级别的隔离:尽管所有任务的产物都落到同一个知识库,但在库中会用每个任务独有的请求id 作为元数据标签,在搜索时进行区分和过滤,保证当前任务获取的历史上下文纯净。
启示:上下文工程不是一个单纯的技术问题,而是需要产品、业务深入参与的综合问题,在考虑业务目标、花费成本、任务质量的前提下综合设计实现。
4.持续的过程监控和迭代是关键
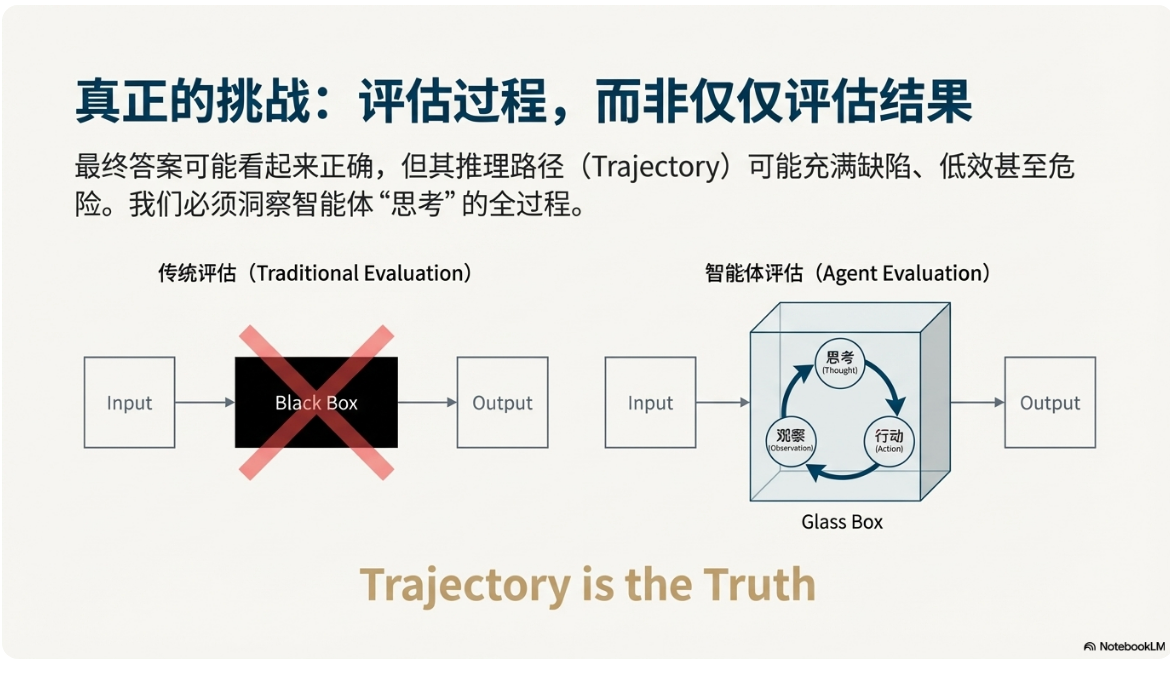
由于以下特性,传统软件的质量保证措施在面对智能体时失效了:
- 传统方法失效: 传统的质量保证(QA)方法适用于确定性系统,但对于 AI 智能体的细微且非确定性的行为来说,是远远不够的。
- 失败的隐蔽性: 智能体的故障往往不是系统崩溃,而是微妙的质量下降。即使 API 调用返回 200 OK,输出也可能看似合理但实际上严重错误,从而悄悄侵蚀用户信任。
- 无法调试的错误: 智能体的失败可能是判断力的缺陷,而非代码缺陷。你无法像对传统代码那样设置断点来调试幻觉。
因此需要对智能体的运行过程进行监控,以实现:
- 应对非确定性的风险:持续追踪和评估可以让对于智能体运行的观察从“黑箱”(最终答案错误)升级到“玻璃箱”(“最终答案错误是因为”)级别的诊断。
- 评估整个决策过程:衡量智能体质量和安全性的真正标准在于它的整个决策过程(轨迹),而不仅仅是最终输出。
- 衡量业务价值:持续评估将 AI 锚定在用户为中心的指标和业务目标上。它确保评估回答了更复杂的战略问题:“我们是否构建了正确的产品?”
- 实现持续进化:持续评估和监控创建了“智能体质量飞轮”。这是一种自我强化的系统,可以驱动持续的改进。
二、产品落地中的具体挑战
问题的解决很难一劳永逸,就像所有需要生命周期管理的产品一样,智能体也需要在迭代中不断优化和成长。
整理了我在具体项目实践中遇到的2个具体挑战和解决方案,希望提供一些思路。
反思环节的验收标准
在智能体运行的反思环节,需要模型判断上一步的产出是否符合要求,并做出继续下一步/重做/扩展新步骤的决策。
核心挑战:验收标准严格度的平衡
- 标准过于僵硬:陷入循环重做,任务永远无法完成
- 标准过于松散:反思失去意义
改进方向:根据每一步的任务要求动态注入验收标准,调整继续、重做、扩展3种决策的权重。
上下文检索的效果优化
核心挑战:检索结果相关性低
改进方向:
- 优化文档分块的粒度与重叠策略
- 使用模型动态生成更有针对性的检索Query,而非用字段硬拼接query
三、如果重新开始
如果可以重新开始,我会更早采取的措施:
1. 最小可行路径优先
不追求初期设计的完美性,而是:用最简单方式跑通端到端流程,先验证可行性,后优化产品设计和交互体验,允许初期的实现比较粗糙。
2. 尽早建立过程可观测性
智能体的运行尝尝包括多个节点和步骤,如果不能实现对过程的监控,会对问题的解决优化造成很大阻碍,尽早为你的智能体接入监控工具/平台,建立关键指标看板,记录每次变更的性能影响。
3. 建立评测基准
为自己的智能体定义成功标准和验收指标,避免主观判断,建立优化前后的可比性。
本文由 @猫猫观察员的AI思考 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


