
 起点课堂会员权益
起点课堂会员权益用户意图识别与关键词提取 Prompt 设计方法论(上)
Prompt 设计远非简单的语言拼凑,而是一项需要工程化思维的精密工作。本文揭秘了一套实战验证的 Prompt 设计方法论,涵盖关键词提取的8大防幻原则、思维链(CoT)的工程化应用,以及如何通过多模型交叉验证来提升泛化能力。从版本管理到结构化输出,这些经过千次测试总结的实战技巧,将帮助你打造出像代码一样严谨的智能对话系统。

最近在负责用户意图分析和关键词提取模块的 Prompt 设计工作。在这个过程中,我总结了一套较为完整的 Prompt 设计方法论,并整理了实际操作中容易遇到的“坑”与解法。
本系列复盘计划分为两篇:
- 第一篇(本文):Prompt 的设计架构、关键词提取策略与思维链实践
- 第二篇:如何科学评估 Prompt 的效果与定义准确率
在正式进入具体方法之前,我想分享一个核心认知:Prompt 设计需要具备“工程化的严谨性”。
它既不是简单的自然语言拼凑,也没有复杂到不可掌握。一个优秀的 System Prompt 往往长达几千字,需要像打磨代码一样去迭代。在实践中,我发现一个非常有效的技巧是多模型交叉验证:利用 GPT 系列、Gemini 以及国内表现优秀的千问(Qwen)等不同模型进行测试。通过模型间的“性格”差异,可以更快发现 Prompt 的逻辑漏洞,提升结果的泛化能力。
以下是我在实战中总结的八个关键步骤。
一、Prompt 的版本管理:像代码一样维护
Prompt 不是一次性工作,它像产品功能一样,需要持续迭代。每一次微小的修改(甚至是一个标点符号)都可能引起输出效果的波动。因此,建立严格的版本管理是基础:
- 快照记录: 保存每一个版本的完整 Prompt 内容。
- A/B 测试: 详细对比不同版本的输出效果,特别是针对“边界案例(Edge Cases)”的表现。
- 变更日志: 记录修改原因(例如:修复了把“润色”误判为“闲聊”的问题)和优化点。
这不仅是为了追踪变化,更是为后续(第二篇将提到的)准确率量化评估提供数据基础。
二、明确意图类别与任务边界
在动笔写 Prompt 之前,必须先“观测数据”。意图分类不是拍脑门决定的,而是一个基于真实用户数据不断收敛的过程。
目前,我们将通用对话的意图主要归纳为以下几类,你需要为每一类提供清晰的定义:
- 核心类: 信息获取、内容创作、任务执行
- 交互类: 闲聊/情感陪伴、角色扮演
- 辅助类: 决策辅助、测试/边界探索
- 异常类: 错误/负面反馈、意图不明
实战经验:
很多时候,“内容创作”和“意图不明”容易混淆。如果用户发送了一段非常长的文本,大概率属于“内容创作”(如需要总结、改写),此时需结合上下文谨慎判断,避免草率归为“意图不明”。
三、模式匹配与触发规则
为了让 AI 在几毫秒内做出准确判断,我们需要定义高优先级的“提问模式”和“关键词锚点”。这相当于给 AI 的逻辑判断加了“快捷键”。
1. 高优先级提问模式
- 方法/策略类: “如何提升……”、“……的策略是什么”
- 事实/标准类: “某产品的注册流程”、“法案第 42 条”
- 隐式创作类: “这个标题感觉不合适”(暗示修改)、“季度工作报告”(暗示生成)
2. 关键词触发规则(Mapping)
- 含“润色、改写、总结、起标题” $\rightarrow$内容创作
- 含“公司名、产品编号、定义” $\rightarrow$信息获取
- 含“代码、表格、Excel、转换” $\rightarrow$任务执行
四、核心攻坚:关键词提取的“防幻觉”工程规范
在意图识别之外,关键词提取(Slot Filling) 往往是后续检索和执行的关键。但在实战中,AI 很容易犯两个错误:一是“无中生有”(生成原文中不存在的同义词),二是“抓不住重点”(提取了一堆形容词)。
针对这些痛点,我制定了 “关键词提取 8 原则”,能显著提升提取的精准度:
1)去噪原则: 严格过滤无意义的口语词汇(如“帮我”、“一下”、“请问”)。
2)词性硬约束: 仅提取名词、专有名词、名词短语。动词、形容词和虚词通常对检索帮助较小,直接剔除。
3)“原文萃取”原则(关键): 所有关键词必须是用户提问原文中一字不差的词语。严禁 AI 进行同义改写或总结。
- Bad Case: 原文“奔驰”,提取“汽车”。
- Fix: 必须提取“奔驰”。这一条能有效防止 AI 幻觉,保证后续搜索匹配的精准度。
4)长度控制: 单个关键词长度一般不超过 10 个字(书名号内的专有名词除外),避免提取整句。
5)优先级排序(Ranking):
并非所有名词都重要,需要教 AI 区分权重,建议输出顺序为:
- 第一优先级:产出物/载体(如:表格、报告、思维导图、代码)——这是任务的核心目标。
- 第二优先级:核心人物/问题(如:马斯克、系统崩溃)。
- 第三优先级:核心实体/主题(如:Model 3、Python)。
- 第四优先级:补充性信息(如:时间范围、地点)。
6)自我检查(Self-Correction): 在 Prompt 中加入自检步骤:“检查提取的词是否在原文中出现?词性是否符合要求?如果不符合,请剔除。”
7)格式限制: 明确数量上限(如最多 5 个)并强制输出为 List 或 JSON 格式,便于代码解析。
8)正确示例(Few-Shot): 提供正反例对比,让 AI 学习标准。
五、执行步骤:引入思维链(CoT)
为了保证逻辑的可解释性和稳定性,不要让 AI 直接输出结果,而是要求它按照特定的思维链进行推理:
1)初步判断: 扫描文本,匹配上述的“提问模式”或“关键词规则”。
2)二次深度判断(关键步骤):
- 对于初判为“意图不明”的,重新审视是否存在隐式创作需求(如只有一段文字,可能是要求润色)。
- 检查是否命中了典型的“反直觉”案例。
3)关键词自检:按照“8 原则”提取并核对关键词。
4)最终决策:结合上述分析,输出最终的意图代码和结构化数据。
六、案例示范与错误修正
在 Prompt 中植入“错误修正(Error Correction)”案例,效果往往优于单纯的正确案例。通过展示 AI 容易犯错的场景,能帮助模型快速校准参数。
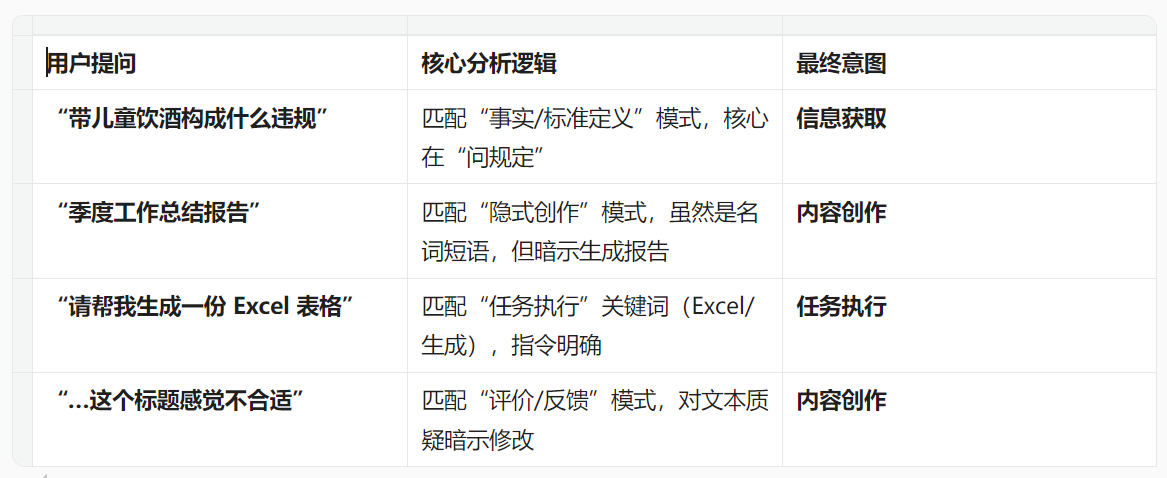
七、结构化输入与分隔符
在工程实践中,如何确保 AI 清晰地知道哪部分是指令,哪部分是用户输入,哪部分是历史示例,至关重要。
使用分隔符(Delimiters): 强烈建议使用清晰、不常用的符号(如 ### 或 — 或 “””)将 Prompt 的不同部分隔开。这能有效防止 AI 将历史输入内容误判为指令或规则。
示例结构:
[系统角色设定]###[意图规则和分类定义]###[案例示范(Few-Shot)]###[用户输入]: <用户实际提问>
强制结构化输出: 明确要求输出 JSON 格式(如 {“intent”: “…”, “keywords”: […]}),而不是自然语言描述。
八、 角色设定与禁止事项
一个好的 Prompt 应该先给 AI “穿上盔甲”,明确它的身份、职责以及不能做的事情。
1)明确角色(Persona): 在 Prompt 开头声明 AI 的身份(例如:“你是一个专业的意图分析引擎,专注于提供准确、简洁的意图分类和关键词提取。”)。角色设定有助于收敛 AI 的输出风格和范围。
2)设定禁止事项(Guardrails): 明确告知 AI 绝对不能做的事情,这能避免低级错误和不必要的长篇回复。
禁止项示例:
- “禁止输出任何解释性、道歉性或引导性的话语,仅输出 JSON。”
- “禁止自行创作或改写关键词。” “禁止闲聊或参与角色扮演。”
总结
Prompt 写作是一场持久战。从确立版本管理意识,到精细化打磨关键词提取的“8 原则”,再到引入思维链(CoT)进行逻辑加固,每一步都是为了让 AI 从“听懂”进化到“精准执行”。
明确意图类别、死磕关键词提取规则、建立错误修正库、结构化输出、角色设定与禁止项,是提升对话系统体验的核心要点。
在下一篇文章中,我将详细拆解如何定义“准确率”,以及如何建立一套科学的评估测试集,用数据量化 Prompt 的优化效果。敬请期待。
本文由 @产品不正经 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









意思意思是什么意思?
你说的啥意思