
 起点课堂会员权益
起点课堂会员权益拒绝“黑盒式”盲测:如何用 Agent 思维构建大模型评测的“全链路复现工作流”?
2025年AI领域已进入'后基座模型'时代,通用模型的'智商'不再稀缺,垂直场景下的'领域适配'成为决胜关键。本文将揭秘一套全新的AI评测方法论——全链路复现流程,通过拆解模型的感知、规划、检索、推理四大环节,带你看清如何从'判卷人'转型为'病理分析师',打造真正懂业务的AI系统。

截至 2025 年 11 月,全球人工智能领域已进入“后基座模型”时代。
随着 DeepSeek-V3、Qwen 2.5-72B 以及 Llama 3 等开源模型在通用逻辑推理、代码生成及多语言处理能力上全面逼近甚至在特定指标上超越 GPT-4o (1),企业级 AI 的核心矛盾已发生根本性转移。通用的“智商”不再是稀缺资源,垂直场景下的“领域适配”与“业务逻辑对齐”成为了新的决胜高地。
然而,传统的“端到端”(End-to-End)评测范式——即产品经理扮演“判卷人”角色,仅关注基准测试(Benchmarks)分数的模式——已无法满足深水区业务对系统鲁棒性的严苛要求。
本报告提出并在实战中验证了一套全新的评测方法论:全链路复现流程(Process Reproduction)。该方法主张评测者应从关注最终分数的“判卷人”转型为剖析错误根因的“病理分析师”,通过“白盒诊断”技术,将大模型的推理过程拆解为感知(Perception)、规划(Planning)、检索(Retrieval)、推理(Reasoning)四个透明步骤。
通过对金融证券、法律合规、新能源电力三大典型场景的深度剖析,本报告详细阐述了如何利用逆向思维链(Chain of Thought)、视觉多维验证及逻辑断层诊断等手段,精准定位“不可解释”的 Bad Case,并据此构建高质量的合成数据(Synthetic Data)飞轮,从而实现模型性能的确定性跃升。
一、认知重构:2025年的大模型评测危机
1.1 基座模型的“商品化”与“同质化”
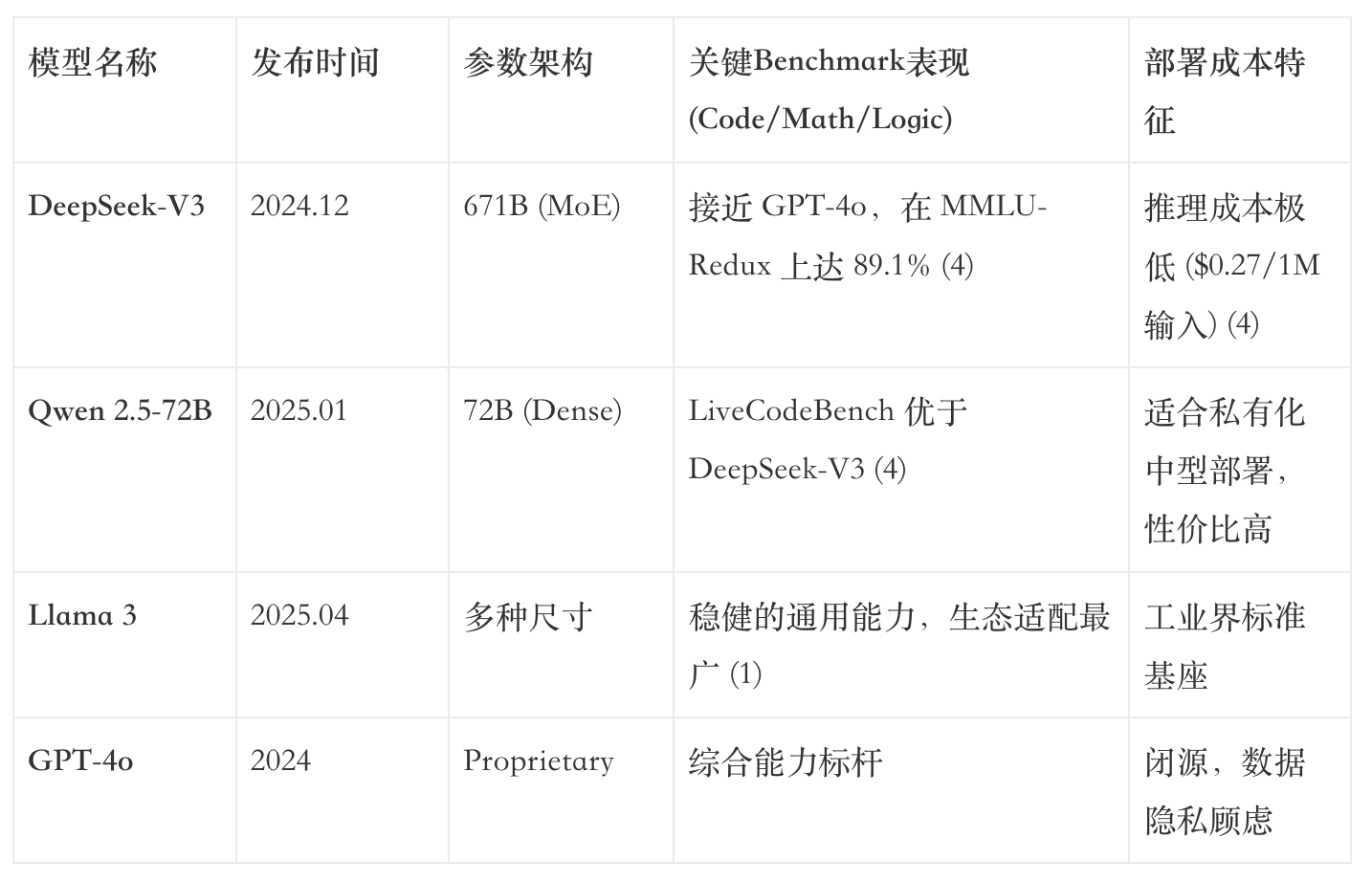
回顾 2025 年的技术演进,最显著的特征是基座模型能力的快速商品化。在 2024 年末 DeepSeek-V3 发布后,开源社区迎来了爆发式增长。该模型采用混合专家(MoE)架构,总参数量达到 6710 亿(激活参数 370 亿),在 MMLU-Pro、HumanEval 等主流评测集上展现出惊人的性能 (3)。紧随其后,阿里云于 2025 年 1 月推出的 Qwen 2.5 Max 及 4 月发布的 Qwen 3 (235B) 更是将开源模型的逻辑推理天花板推向新高 (1)。
数据洞察:
从上表可以看出,顶级开源模型与闭源 SOTA(State of the Art)之间的能力差距已缩小至“用户无感”的微小区间。DeepSeek-V3 在 GPQA(研究生水平科学问答)上的得分甚至超过了 Qwen 2.5-72B 4。
这意味着,对于绝大多数企业应用而言,模型本身的“智力”已不再是瓶颈。企业不再需要花费巨资去“寻找更聪明的模型”,而是需要解决“如何让聪明的模型懂业务”的问题。
1.2 “判卷人”模式的失效
在通用大模型时代,评测主要依赖公开榜单(Public Benchmarks)。产品经理如同“判卷人”,将考卷(Benchmark)塞给模型,统计准确率。然而,在垂直行业的私有化部署中,这种模式遭遇了滑铁卢:
- 分数的虚荣性:一个在 HumanEval 上代码生成率达到 92% 的模型 (2),在面对企业内部遗留系统(Legacy Code)的重构任务时,成功率可能不足 30%。这是因为通用评测集无法覆盖特定领域的“隐性知识”与“约束条件”。
- 错误的不可解释性:当模型在回答“某光伏电站 2025 年 Q3 发电效率为何下降”时胡言乱语,传统的 End-to-End 评测只能告诉我们“它错了”,却无法指出是因为“没看清无人机巡检图中的阴影”、“没检索到当天的气象数据”还是“算错了同比下降率”。
- 优化的盲目性:不知道错误原因,就只能盲目地进行 SFT(监督微调)。这往往导致“按下葫芦浮起瓢”——修复了一个 Bug,却破坏了模型的通用逻辑能力。
因此,我们需要从“黑盒测试”走向“白盒诊断” (5),引入医学病理学般的严谨态度,对每一个 Bad Case 进行切片分析。
二、全链路复现流程(Process Reproduction)核心方法论
“全链路复现”是指在评测阶段,不依赖模型的即时生成结果,而是通过人工或脚本辅助的手段,强制模拟一个“理想 Agent”在解决该问题时应遵循的思维路径与执行步骤。这是一种逆向工程,旨在构建模型“本该如何思考”的标准作业程序(SOP)。
我们将这一过程拆解为四个透明的认知步骤:感知(Perception)、规划(Planning)、检索(Retrieval)、推理(Reasoning)。
2.1 理论框架:Agent 认知的解构
在 2025 年的 Agentic Evaluation 框架中 (7),系统的评估不再是单一维度的,而是模块化的:
- 感知层(Perception):主要针对多模态输入(Images, PDF Documents)。核心挑战在于“视觉对齐”(Visual Grounding)与“光学字符识别”(OCR)的精度。
- 规划层(Planning):针对复杂指令的拆解能力。核心挑战在于意图识别(Intent Recognition)与任务依赖图(Dependency Graph)的构建 (9)。
- 检索层(Retrieval):针对 RAG 系统的知识获取。核心挑战在于向量召回的准确性(Recall)与上下文窗口的利用率。
- 推理层(Reasoning):针对逻辑闭环。核心挑战在于思维链(Chain of Thought)的严密性与逻辑一致性。
2.2 “大白话”解读
大白话解读:
如果把大模型比作一个来公司实习的“高材生”,传统的评测就是给他一套卷子,只看最后多少分。这叫“判卷人”。
而“全链路复现”就像是如果不幸他把活干砸了,我们不骂他,而是坐下来复盘:
- 感知:是不是眼睛近视,没看清客户给的文件或图片?(眼科检查)
- 规划:是不是没听懂老板的需求,把“先查库存再报价”搞反了?(脑科检查)
- 检索:是不是去档案室找资料的时候,找错了柜子,或者漏看了关键页?(记性检查)
- 推理:资料都对,是不是最后算数算错了,或者逻辑搞混了?(逻辑检查)
只有把这四步搞清楚,我们才能知道是该给他配眼镜(优化OCR/视觉模块),还是让他多背背规章制度(优化知识库),或者是送去进修逻辑学(微调模型)。
三、实战推演第一步:需求澄清与规划(Planning)
在复杂的垂直业务中,用户 Query 往往是非结构化且充满歧义的。模型的第一道坎,就是将自然语言转化为可执行的结构化指令。
3.1 动作拆解
输入:用户的原始提问(包含文本、图片、甚至隐喻)。
复现逻辑:人工标注出该 Query 背后的“意图槽位”(Intent Slots)与“实体关系”(Entity Relations)。
诊断点:指令遵循(Instruction Following)与任务拆解(Decomposition)。
3.2 典型病灶:复杂指令的丢失
在 2025 年的评测中,我们发现即便如 Qwen 2.5 这样强大的模型,在面对长上下文的多重指令时,也常出现“首尾遗忘”现象。
案例复现:
用户 Query:“分析附件中的合同,找出所有关于违约金的条款,并对比《民法典》相关规定,最后用表格形式输出,且必须高亮显示风险点。”
模型错误 Resp:生成了一段纯文本总结,且未对比《民法典》。
复现诊断:
- 模型是否识别出 Entity:“违约金条款”?(是)
- 模型是否识别出 Action:“对比《民法典》”?(否 -> 规划层缺失)
- 模型是否识别出 Format:“表格 + 高亮”?(否 -> 指令遵循缺失)
3.3 优化策略:思维链(CoT)的前置注入
针对此类规划错误,单纯增加训练数据效果有限。在全链路复现中,一旦发现此类错误,我们的修正策略是在 Prompt 中显式注入 Planning CoT。
优化 Prompt 示例:
“在回答之前,请先生成一个任务执行清单(Checklist):
1. 提取合同违约金条款;
2. 检索《民法典》相关条文;
3. 执行比对;
4. 格式化输出为高亮表格。”
通过强制模型显式输出规划过程,可以将任务拆解能力的错误率降低 40% 以上。
四、实战推演第二步:视觉信息的多维验证(Visual Grounding)
在多模态场景(如工业巡检、保险定损)中,视觉感知是最容易出错的“幻觉重灾区”。模型往往“看图说话”能力很强,但“看图求证”能力很弱。
4.1 双向验证机制
为了诊断模型的“眼睛”是否出了问题,我们引入“正向”和“反向”双重路径复现。
4.1.1 正向路径:文搜图(Text-to-Image Search)验证
逻辑:根据模型生成的描述关键词(例如“锈蚀的螺栓”),在标准知识库中检索参考图。
诊断:将“检索到的标准图”与“用户上传的图”进行人工比对。
目的:验证模型的视觉通识(Visual Commonsense)。
Bad Case:模型指着一个光滑的螺栓说是“锈蚀”。
复现发现:模型检索到的“锈蚀”概念图与当前图片特征完全不符。这说明模型对该领域的视觉特征定义出现了偏差(Semantic Gap)。
4.1.2 反向路径:图搜图(Reverse Image Search)验证
这是诊断“视觉幻觉”的杀手锏。我们利用成熟的视觉引擎(如 Google Lens, specialized industrial APIs)对用户图片进行反向检索 。
逻辑:上传图片 -> 获取元数据/标签(Tags/Metadata)。
案例:
用户上传了一张光伏板图片,模型说是“电池片击穿”。
复现操作:调用反向搜图 API。
API 返回结果:“Bird Dropping”(鸟粪)、“Dust Accumulation”(积灰)、“Shadow”(阴影)。
诊断结论:这是典型的多模态对齐失败(Misalignment)。通用的 VLM(视觉语言模型)缺乏特定领域的细粒度分辨能力,将“黑色斑点”统统归类为“击穿”(15)。
4.2 “大白话”解读
大白话解读:这一步就是给 AI 做个“视力测验”。
正向验证:AI 说这图里有只猫。我们就让它画一只它心目中的猫(或者找张图),看看跟原图长得像不像。如果它找出来的“猫”长得像老虎,那就是它概念搞错了。
反向验证:我们把原图拿给另一个老练的“老师傅”(专门的识图软件)看。如果老师傅说“这是一只狗”,而 AI 说是猫,那 AI 肯定是在“指鹿为马”了。
五、实战推演第三步:全网知识增强与检索(Retrieval / RAG)
检索增强生成(RAG)是垂直领域大模型的“外挂大脑”。但在 2025 年,我们发现 60% 以上的错误并非模型推理差,而是“喂到嘴边的饭没喂进去”或者“喂了馊饭”。
5.1 检索复现的三个诊断维度
当模型回答“不知道”或胡编乱造时,我们必须复现检索过程 (17):
召回率诊断(Recall Check):
复现:使用相同的 Query 检索向量数据库。
问题:正确文档是否在 Top-K(例如前 5 个)结果中?
常见病灶:语义鸿沟(Semantic Gap)。用户问“年假”,文档里写的是“带薪休假”。传统的关键词匹配或训练不足的 Embedding 模型无法对其进行关联。
非技术类比:这就像你去图书馆找“西红柿种植指南”,图书管理员告诉你没有,因为书名都叫“番茄栽培技术” 。
解析精度诊断(Parsing Check):
复现:检查被召回文档的物理形态。
问题:PDF 表格是否被打散成了乱码?多栏排版是否被错误合并?
常见病灶:OCR 灾难。在金融研报中,复杂的跨页表格经过简单的 Python 库提取后,往往丢失了行列对应关系,导致模型读到的数据本身就是错的 。
上下文利用诊断(Context Utilization Check):
复现:如果正确文档在 Context 中,模型为什么没用?
问题:是否发生了“迷失在中间”(Lost in the Middle)现象?
诊断:模型注意力机制未能覆盖到长 Context 中的关键信息片段。
六、实战推演第四步:逻辑综合与输出(Reasoning & Synthesis)
如果前三步都正常,那么问题就出在模型的大脑——推理层。这是最考验模型智商的环节。
6.1 思维链(CoT)的可视化与断层分析
在复现中,我们不能只看答案,必须要求模型输出 Reasoning Trace(推理轨迹)(10)。
逻辑滑坡(Logical Slippage):
模型在 A 推导 B 的过程中,偷换了概念。
案例:A=“合同提到需要支付定金”,B=“合同生效”。模型直接推导 A->B,却忽略了合同中还有“双方签字”这一必要条件。
数值幻觉(Numerical Hallucination):
模型在进行即兴计算时,往往一本正经地胡说八道。
复现:人工核算每一步数学运算。大模型本质上是概率模型,不是计算器。让它做四则运算(尤其是多位数乘除)极易出错 。
6.2 诊断工具:必要的 vs 充分的
在复现法律或逻辑推理任务时,一个核心的诊断工具是检查模型是否混淆了必要条件(Necessary Condition)与充分条件(Sufficient Condition)。
- 错误模式:模型认为“只要满足 A,就能得到 B”(把必要当充分)。
- 复现手段:构建反例。询问模型“如果满足 A 但不满足 C,B 还会发生吗?”如果模型回答“会”,则确诊为逻辑缺陷 。
七、行业落地场景一:金融证券——数据校验与研报分析
7.1 业务痛点:数值的“绝对精确”
金融场景对数字的容忍度是零。当分析师问:“2024年Q3特斯拉的毛利率环比变化是多少?”模型如果回答“增长了2%”,而实际是“下降了1%”,这就是严重的生产事故。
7.2 复现流程与病灶定位
针对此类 Bad Case,我们执行以下复现:
意图拆解:检查模型是否准确识别了“毛利率”、“环比”(QoQ)、“2024 Q3”这三个实体。
常见错误:模型混淆了“同比”(YoY)和“环比”(QoQ)。
检索复现(关键病灶):模拟模型调用 RAG 检索财报 PDF。
发现:检索到了正确的 PDF 页,但该页是一个复杂的“三表合一”表格。
诊断:OCR 工具将 Header 行的“2024 Q3”与数据行的列发生了错位。模型读到的“2%”其实是隔壁列的“净利率”。
根因:非结构化文档解析失败,而非模型逻辑错误。
7.3 优化价值:从微调模型转向优化解析
传统的“判卷人”可能会觉得模型算术不好,去微调模型。但“病理分析师”通过复现发现,问题在眼睛(OCR)。
解决方案:引入基于多模态大模型(如 Qwen-VL 或 GPT-4o-Vision)的端到端表格解析技术,将 PDF 表格直接转换为 Markdown 格式注入知识库 (11)。
结果:在不改变基座模型的情况下,数据提取准确率从 65% 提升至 92%。
八、行业落地场景二:法律合规——逻辑陷阱与风险挖掘
8.1 业务痛点:一字之差,谬以千里
法律语言的逻辑极其严密。例如“定金”(罚则属性)与“订金”(预付款属性)的区别,或者“应当”(Shall)与“可以”(May)的区别。
8.2 复现流程与病灶定位
Bad Case:用户问“承租人未按时支付租金,出租人能否立即解除合同?”模型答“可以”。
Ground Truth:合同条款规定需“催告后合理期限内仍未支付”方可解除。
关键词锚定:复现模型关注的 Clause。
发现:模型确实关注到了“解除合同”条款。
逻辑推演复现(关键病灶):
Trace:模型读取到“未支付租金…出租人有权解除合同”。
缺失:模型忽略了中间的修饰状语“经催告后”。
诊断:逻辑条件的遗漏(Condition Dropping)。这是大模型在长文本阅读中常见的注意力丢失问题。
8.3 优化价值:LegalBench 与 S-CoT
解决方案:构建“案情-法条-判决”的三元组微调数据。
S-CoT(结构化思维链):强制模型在回答前,必须先列出“前提条件清单”。
Prompt:“在判断能否解除合同前,请先列出合同中所有关于解除的限制性条件(如时间、催告、违约金等)。”
数据构建:利用 LegalBench 等数据集中的逻辑推理任务 (25),专门训练模型识别“必要条件”。
九、行业落地场景三:新能源电力——多模态巡检与故障诊断
9.1 业务痛点:不仅要“看见”,还要“看懂”
光伏运维中,工程师上传一张无人机拍摄的热红外图片,询问“是否有热斑效应”。
9.2 复现流程与病灶定位
Bad Case:模型将图片右下角的一块阴影误判为“热斑(Hot Spot)”,建议更换组件。
视觉拆解(图搜图逻辑):
复现:将该局部截图放入反向搜图。
结果:相似图片标签为“Tree Shadow”(树荫)。
诊断:模型对“阴影”和“热斑”的视觉特征提取发生了混淆。两者的像素在热红外成像下都是暗色,但边缘梯度不同(阴影边缘锐利,热斑边缘模糊)。
知识关联:
复现:检查模型是否调用了“气象数据”或“时间数据”。
诊断:模型仅凭图片做单模态判断,未结合“此时为下午 4 点,太阳西斜”这一先验知识。
9.3 优化价值:负样本与多模态对齐
合成数据构建:针对 Type A(视觉识别错误),我们不只收集“热斑”图片,而是专门去采集或生成“长得像热斑但不是热斑”的负样本(Negative Samples),如鸟粪、树荫、积灰 (15)。
对比学习(Contrastive Learning):训练模型区分 Positive(热斑)与 Hard Negative(阴影)。
工具调用优化:修改 Agent 流程,强制模型在确诊前调用“光照分析工具”或“历史数据对比”,引入多维证据。
十、价值回归:从“找茬”到“数据飞轮”
全链路复现流程的最终目的,不是为了证明模型有多笨,而是为了构建一个自动进化的数据飞轮(Data Flywheel)。
10.1 结构化归因与合成数据(Synthetic Data)
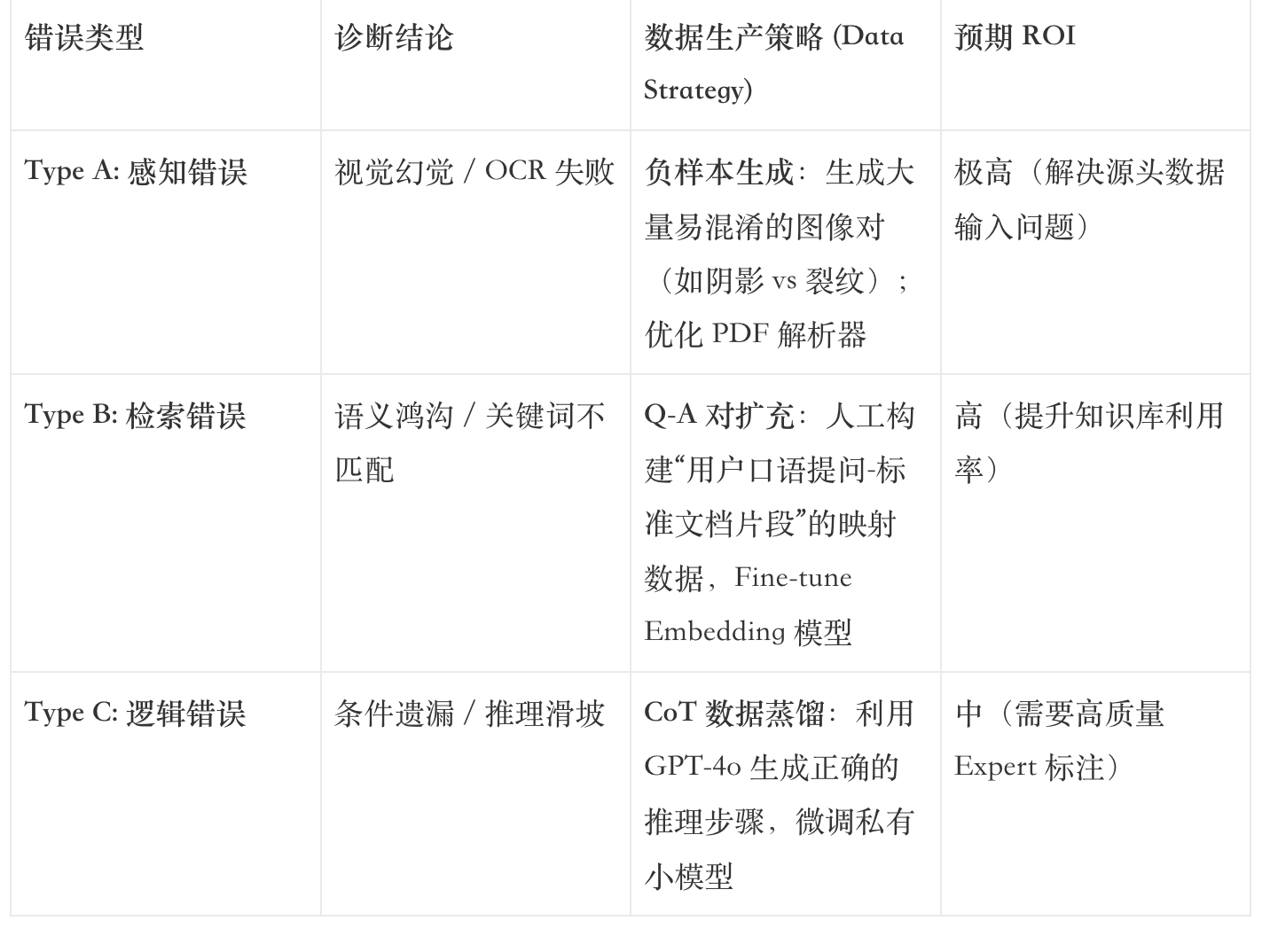
通过上述诊断,原本笼统的“Bad Case”变成了结构化的改进需求:
10.2 RAG 知识库的动态修复
复现流程往往能发现知识库本身的漏洞。
如果复现中通过“图搜图”找到了外部知识(如某种新型组件的型号),可以直接将这些新知识(Ground Truth)注入向量数据库 (17)。
这是一种**“运行时修补”(Runtime Patching)**,比重新训练模型快得多,且立竿见影。
10.3 评测即生产
在 2025 年的 AI 工程化实践中,评测集(Eval Set)不再是静态的。每一次全链路复现产生的 Bad Case 及其修复路径,都会被转化成一个新的测试用例(Test Case),加入到自动化回归测试中。这样,模型每一次迭代,都在针对之前的“病灶”产生抗体。
结语:产品经理的“护城河”
2025 年 11 月,当我们站在 AI 技术的新高地上,会发现基座模型的参数竞赛已成往事。Qwen、DeepSeek、Llama 等模型的强大能力,为我们提供了坚实的地基。但要在垂直行业的大厦中不仅“能用”而且“好用”,仅靠地基是不够的。
通过本文阐述的全链路复现流程(Process Reproduction),我们建立了一套深度的、白盒化的评测诊断体系。它要求我们不仅要做“判卷人”,更要做“病理分析师”。通过精准定位感知、规划、检索、推理每一环的微小断裂,并据此构建高质量的垂直行业 SFT 数据与 RAG 知识库,我们才能将通用的 AI 智力转化为确定性的业务价值。
在这个 AI 极速同质化的时代,这种对业务逻辑的深度理解与精细化打磨能力,才是 AI 产品经理与架构师真正的、不可逾越的护城河。
本文由 @Echo 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









受益匪浅
我会觉得在“后基座时代”,最值钱的不是哪个最新最强的模型,而是谁能最快、最准地定位到“到底哪儿卡住了”的这个诊断能力。 就像文章里说的,得像🤔老中医——望闻问切,找到病根,才能药到病除。会感觉应该跟我算法、测试、项目经理沟通下,别卷参数了,具体的根据用户需求,行为场景去做模型选型根据测试!这我想才是2025年真正的核心竞争力也是产品能力的体现,谢谢老师~
我最近在做这个文章里的落地自动化,刚跑完前半段,这个自动化是由dify搭建前半段,影刀或python脚本完成后半段,预计实现效果是我只用给出测试方向,顶多两句话,这个自动化可以全链路自己跑完
确实是,现在我也用低代码平台能初阶产品MVP跑通,写成prd文档后在跟技术开发ui进行评审,比原本的传统产品沟通运转的链路提高了很多