
 起点课堂会员权益
起点课堂会员权益十分钟读懂RAG
大语言模型虽强,却面临幻觉、知识截止和上下文限制三大痛点。RAG技术应运而生,让AI能够'带书考试',通过分片、索引、召回和生成四步精准解决问题。本文将深入解析RAG的工作原理、应用场景与局限,助你掌握这套AI工程体系的核心逻辑。

2025年,大语言模型已经深刻改变了人类与AI的交互方式。它们知识渊博、能编写代码、举一反三,展现出令人惊叹的能力。然而,就像所有强大的工具一样,大模型也有其固有的局限性。
三大核心痛点
幻觉问题——不会也要编
当大模型遇到不确定的问题时,它不会诚实地说”我不知道”,而是倾向于”自信地编造”答案。这就像一个考生为了不留空白,宁愿编造答案也不愿承认不会。这种幻觉现象在生产环境中可能导致严重后果。
知识截止——只知旧事不知新
大模型的知识库是在训练时固化的。如果模型是2023年训练完成的,那么它对2024年发生的事件一无所知。
另外,企业的核心知识往往存储在内部系统中:客户资料、产品文档、业务流程等。这些数据既不能也不应该用于训练公开模型,但企业又迫切需要让AI理解和处理这些信息。
上下文长度限制——模型最大处理token上限
大模型是一个概率模型,通过将用户输入的问题-转化为token-向量化-函数处理向量-计算出下一个词的概率-最后一个接一个的输出被算法选中的词。
而至于为什么会有上下文限制,主要卡点在计算:
CPU计算:在大模型计算的过程中,会应用到多维的函数处理,以12288个Token为例,在函数处理过程中,会经历多次12288*12288维的向量处理,然后将处理结果进行降维,再继续进行向量处理…这个过程会有相当多;但系统每增加100个Token量级,CPU处理的量级都是指数级提升;
以注意力机制为例:在计算中,输入的每个Toeken(为了便于理解,假设一个词就是一个Token)都会与其他所有的字进行关联度分析,例如:Wizard Harry on the grassland。第二句话是:Prince Harry on the grassland。起初在切分Token向量化时,两个Harry的向量是一致的,但是,在做了上下文Token关联后,两个Harry的向量发生了偏移,第一个Harry,代表的是吧哈利波特,第二个Harry代表的是英国王室的哈利王子。而在处理Harry这个Token时,是需要将Harry与前后所有的Token做关联度的计算,即计算1*5次。
解决方案
面对这些挑战,业界发展出了三种主要解决方案:
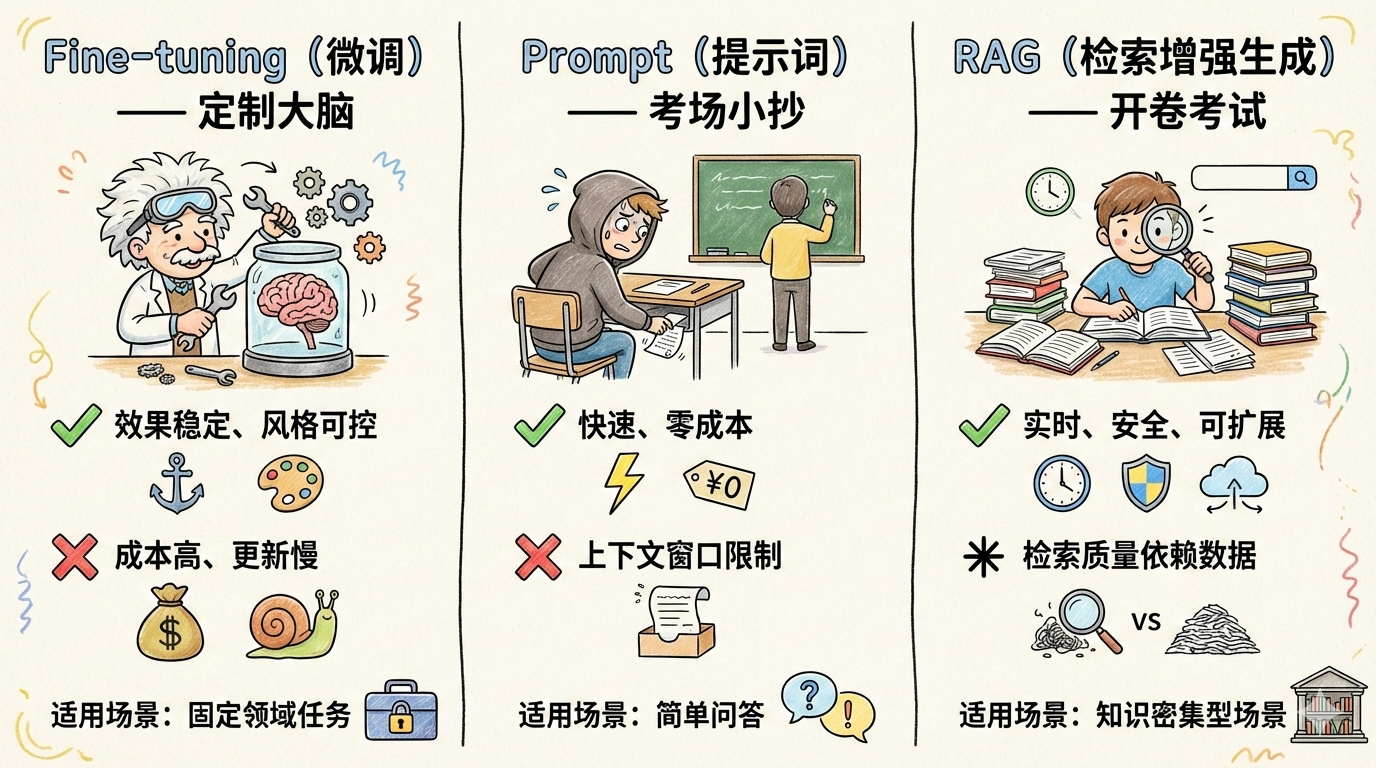
今天将深入探讨RAG技术——这个让AI能够”带书考试”的解决方案。
完整工作流程:让AI”开卷考试”
想象你在参加考试,但可以携带参考书。你不需要死记硬背所有知识点,只需要知道去哪里查找答案,然后用自己的话整理输出。
RAG就是让AI也能这样”开卷考试”。
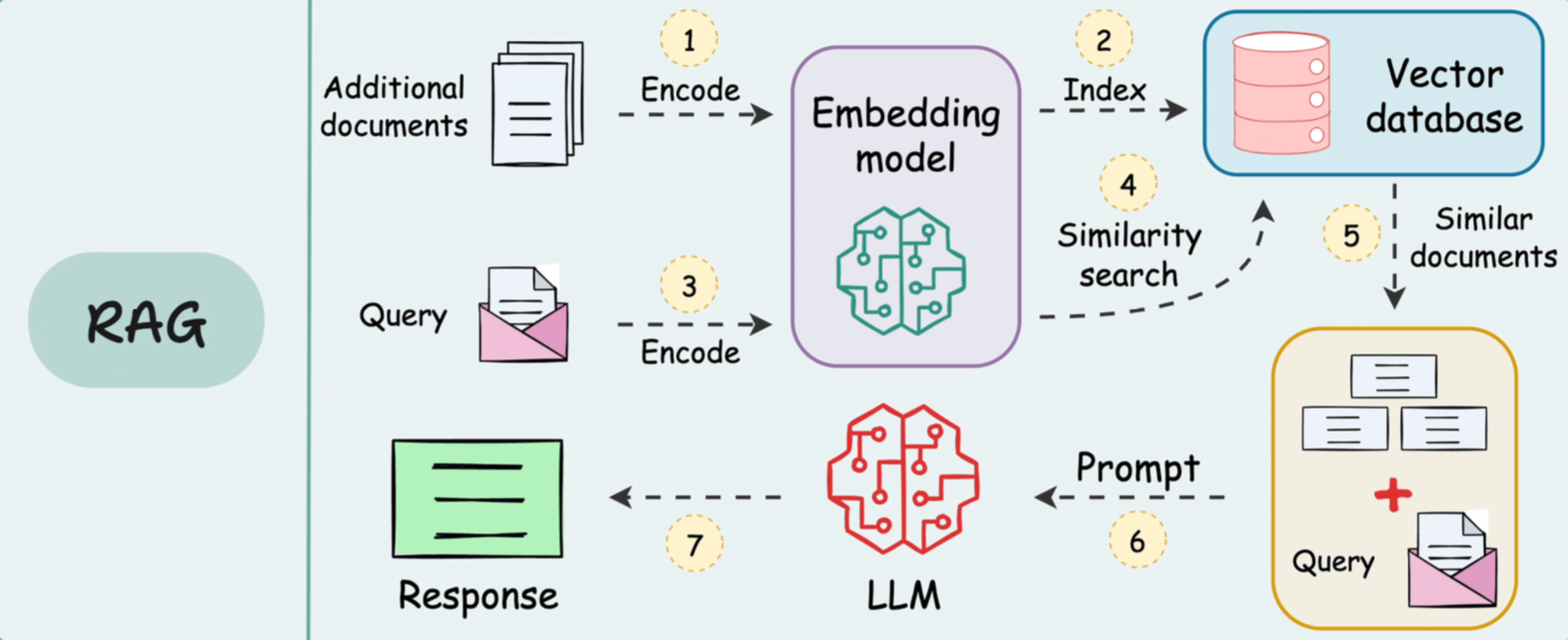
RAG系统分为两个阶段运作:
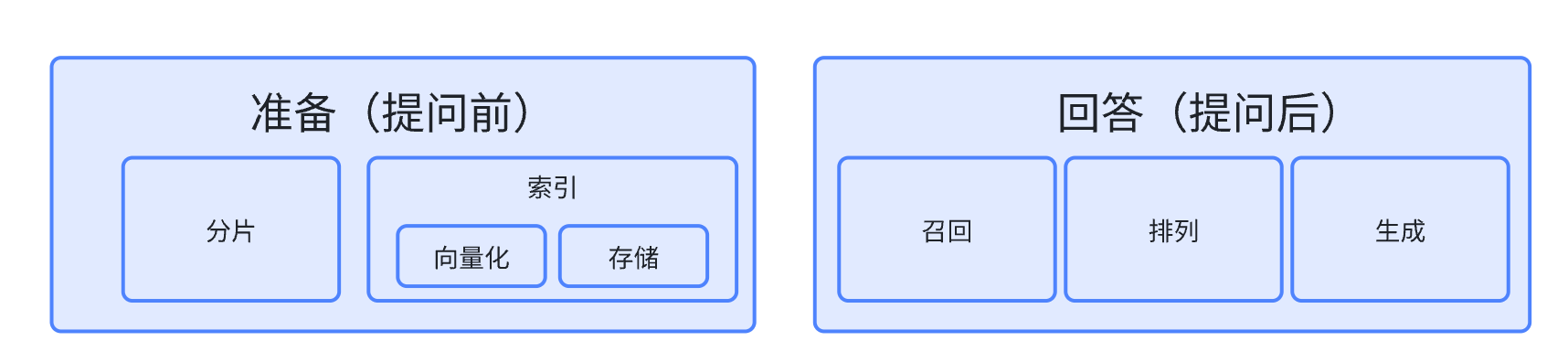
分片
将一个或多个文档,切分为小片段,有很多分片策略,例如:
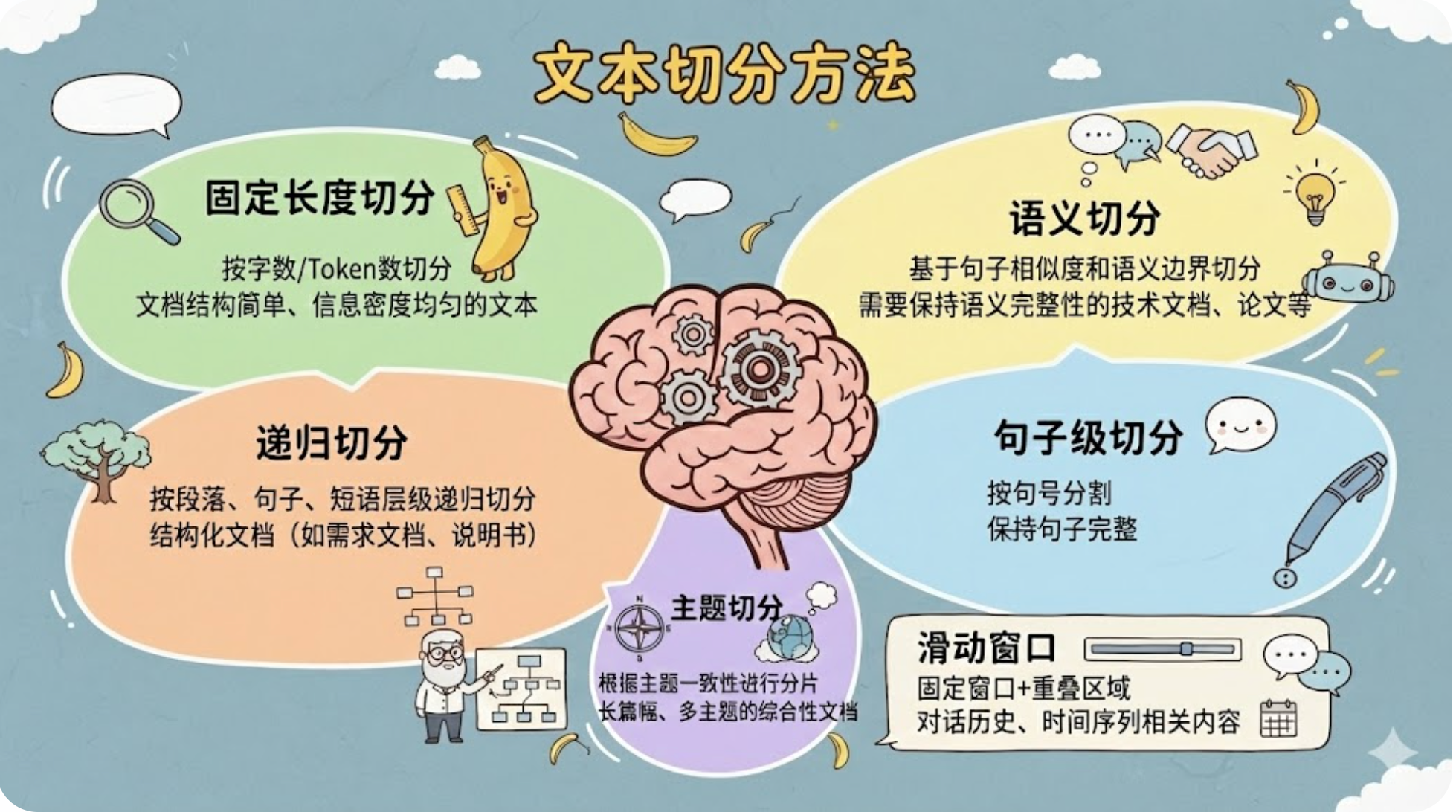
这些方式都是基础的分片方式,实际使用可以一个或多个综合使用。
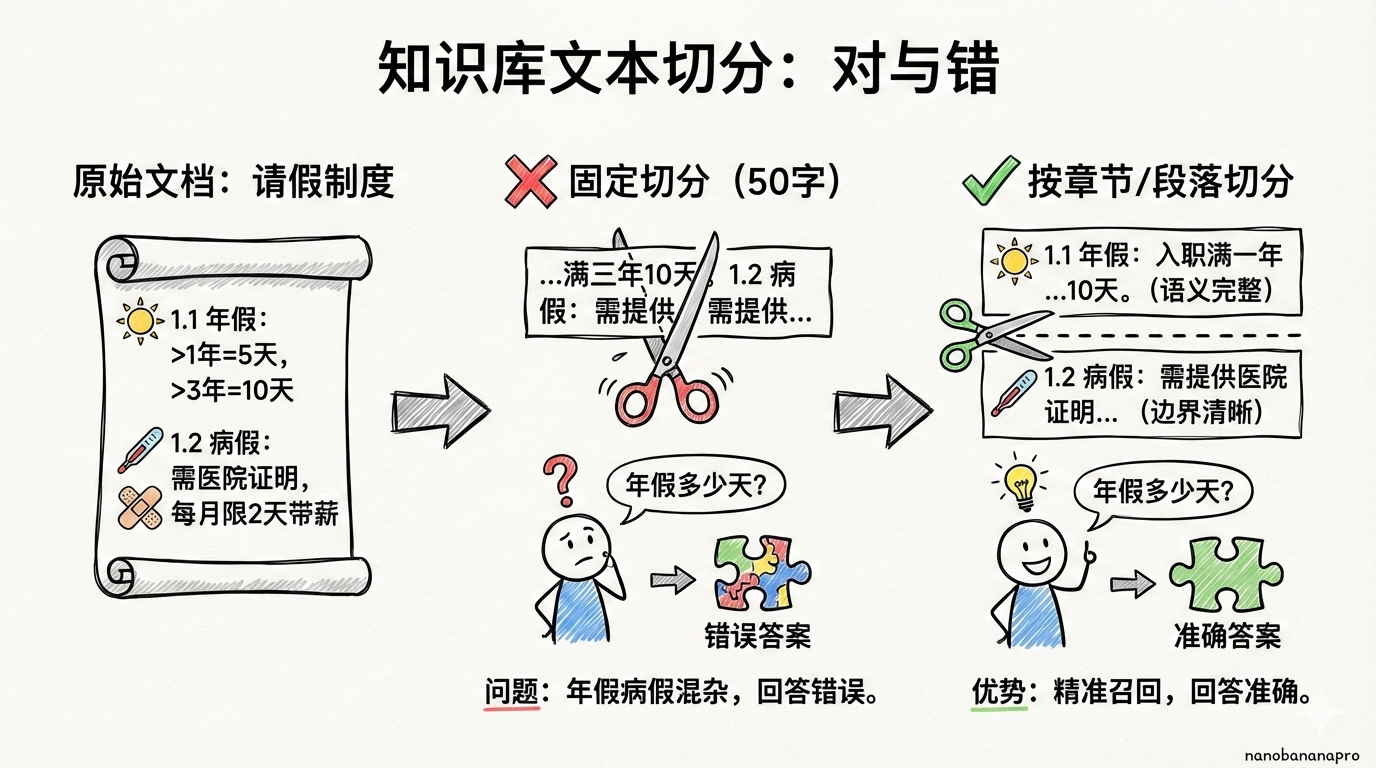
另外可以根据业务场景,增加特有的分片方式,例如商品信息,按照字段进行切片,可以切分出材质、产地、品牌等信息。
切分质量 = 检索准确性 = 回答质量
索引
索引又分为两步,向量化和存储。
向量化
将文本片段转换为数字向量;首先,需要理解什么是向量,在数学概念中,向量是指一个有大小,有方向的量。
以RGB为例,RGB是依靠三原色来描述一个颜色
- 鲜红色:[255, 0, 0]
- 纯蓝色:[0, 0, 255]
- 紫色:[128, 0, 128]
关键洞察:向量数值接近 → 颜色相近 → 空间位置相近
引入更多维度,例如利用向量来描述狗:
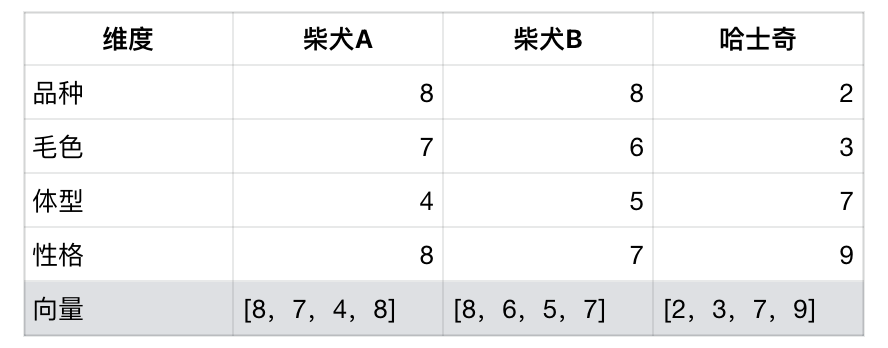
通过比较向量:
- ✅ 柴犬A vs 柴犬B:[8,7,4,8] ≈ [8,6,5,7] → 数值接近 → 很相似
- ❌ 柴犬A vs 哈士奇:[8,7,4,8] ≠ [2,3,7,9] → 数值差距大 → 不相似
而在真实的大模型中,维度会更高,例如GPT-3.5就是12288维,也就是一个Token会在12288维去做一个取值。
存储
将切片的文本和向量存储到数据库中。但是在存储过程中,单个的文本切片和向量存储可能还不够。

切分后,可能就是保留2段切片,“入职满一年可享受5天年假,满三年10天”和“入职即可享受5天年假,满三年10天。”
这个时候当用户问,刚入职1个月,有几天年假。用户是哪个部门的?适用于哪条规则,是回答5天,还是没有年假呢?
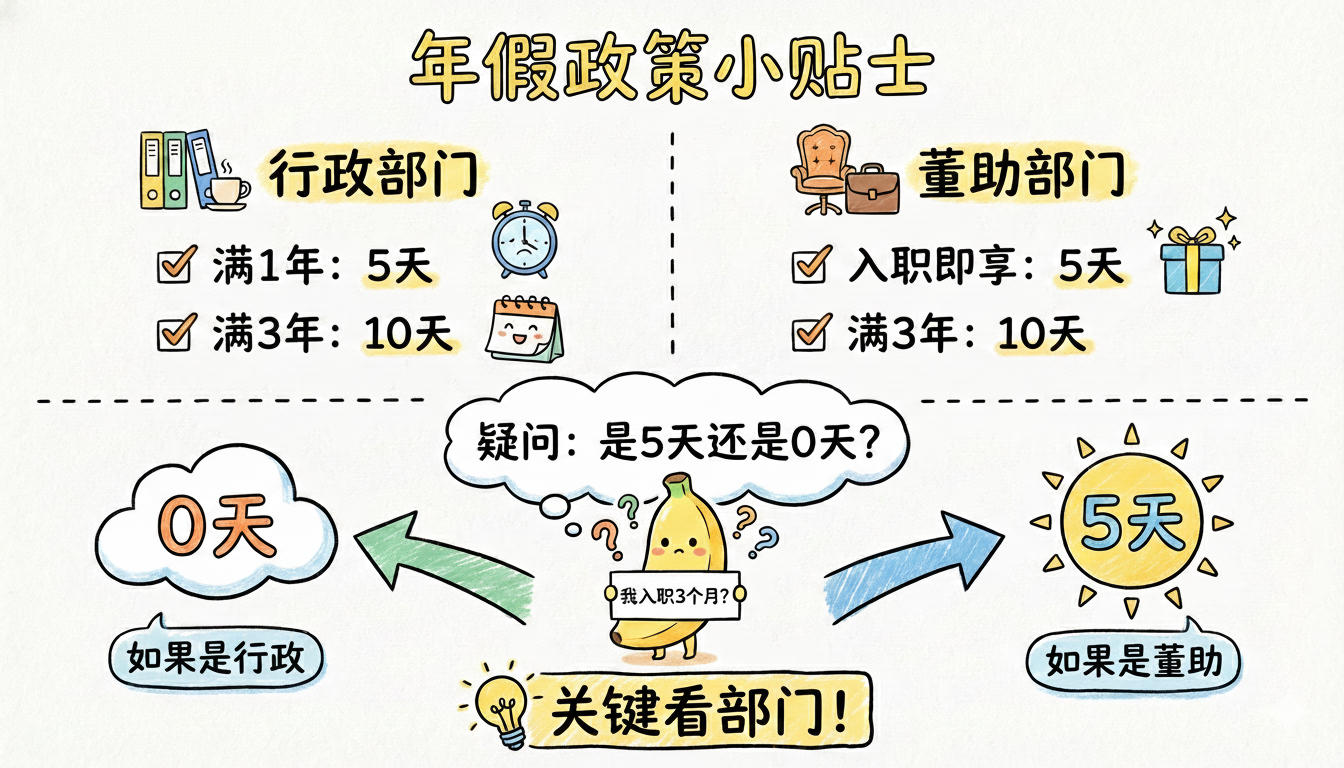
因此,除了文本和向量外,还会增加元数据,即记录信息的来源和出处。
常见元数据类型
- 来源信息:文件名、URL、作者
- 结构信息:章节、标题、页码
- 时间信息:创建时间、更新时间
- 业务信息:部门、产品、版本
召回
在数据库中找到与用户提问相关的文档片段。召回策略很多,这里讲几个最常用的策略。
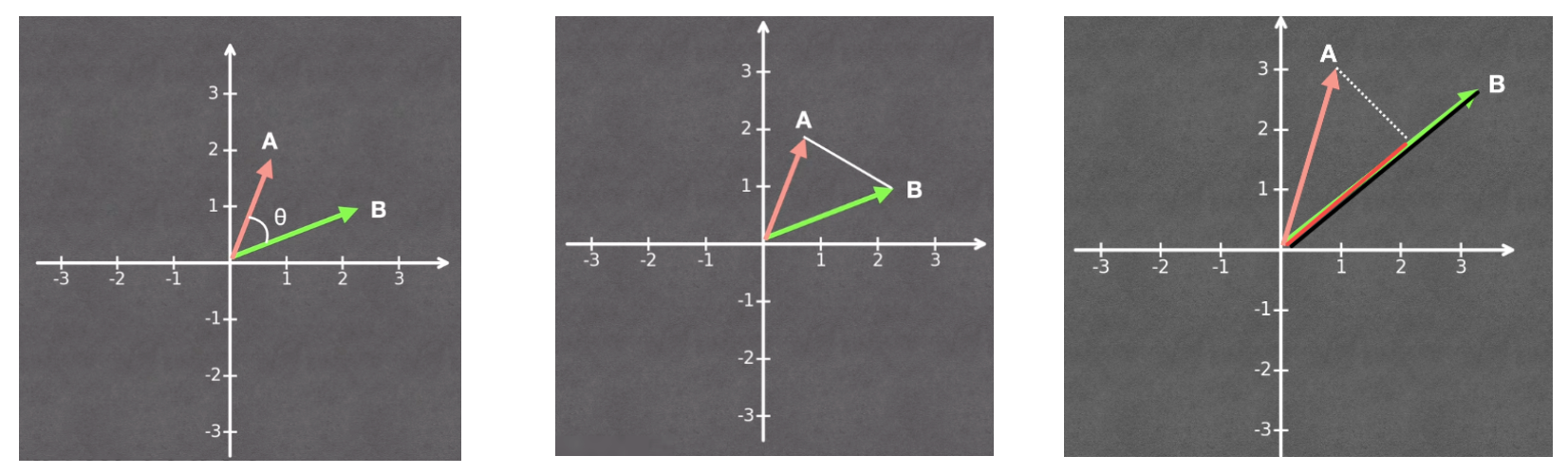
向量检索
将用户问题向量化–>计算问题向量与所有的相似度–>找到相似度最高的N个片段
向量计算相似度的方法,例如余弦相似度(计算向量之间夹角的余弦值)、欧式距离(计算两个向量的直线距离)、点积(综合考虑方向和长度,值越大相似度越高)
图召回
把文档中的实体和关系抽取出来,构建成图结构,也就是构建知识图谱。向量检索能够快速找到语义相近的信息,但是对于多层级逻辑,向量检索是无法一次完成的。
例如:在文档中,分别存了:张三的领导是李四,同事是小明,李四的领导是王总;另一个文档存了:李四的社会关系,大学同学是王五和赵六。
问:张三的领导和谁的大学同学?
在向量检索中,是检索不到的,或者检索错误。
但是,构建知识图谱,将组织架构和社会关系做关联,将角色、关系做关联,就能得到下面这个简单的知识图谱:
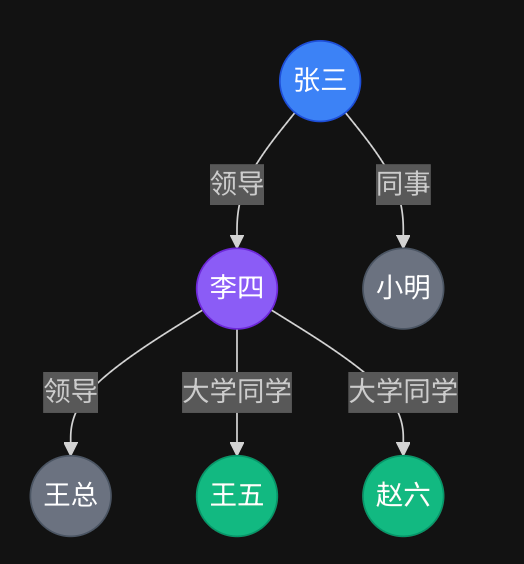
通过这个图谱的遍历,就能得出:
- 定位”张三”
- 沿”领导”边 → 李四
- 沿”同学”边 → 王五、赵六
再举个例子:文档有一句:**说明参见注释1。而注释1在附录。这个时候,你知道要怎么做知识图谱了吗?
推荐使用场景
- 人物/组织关系查询
- 多跳推理问答
- 知识图谱已有的领域
排列
对召回结果进行精细化排序
前面的召回可以理解为是初步找到相关的片段,但是质量不高,因此需要更加精准的将已经筛选出来的片段,再次进行精细排序,并找到最符合要求的几个片段。
为什么没有一开始就用精细排序呢?因为原始的数据量大,精细排序成本高、速度慢,因此采取先将数据筛选一波,再来做精细化处理。
生成
将精选的片段和用户问题一起发给大语言模型
大模型是文本进、文本出,不具备动手能力的。因此,需要将最终排列的内容与用户的原始问题,一起打包发给大模型,让大模型去处理文本信息,最终生成答案展示给用户。
应用场景:RAG能用在哪?
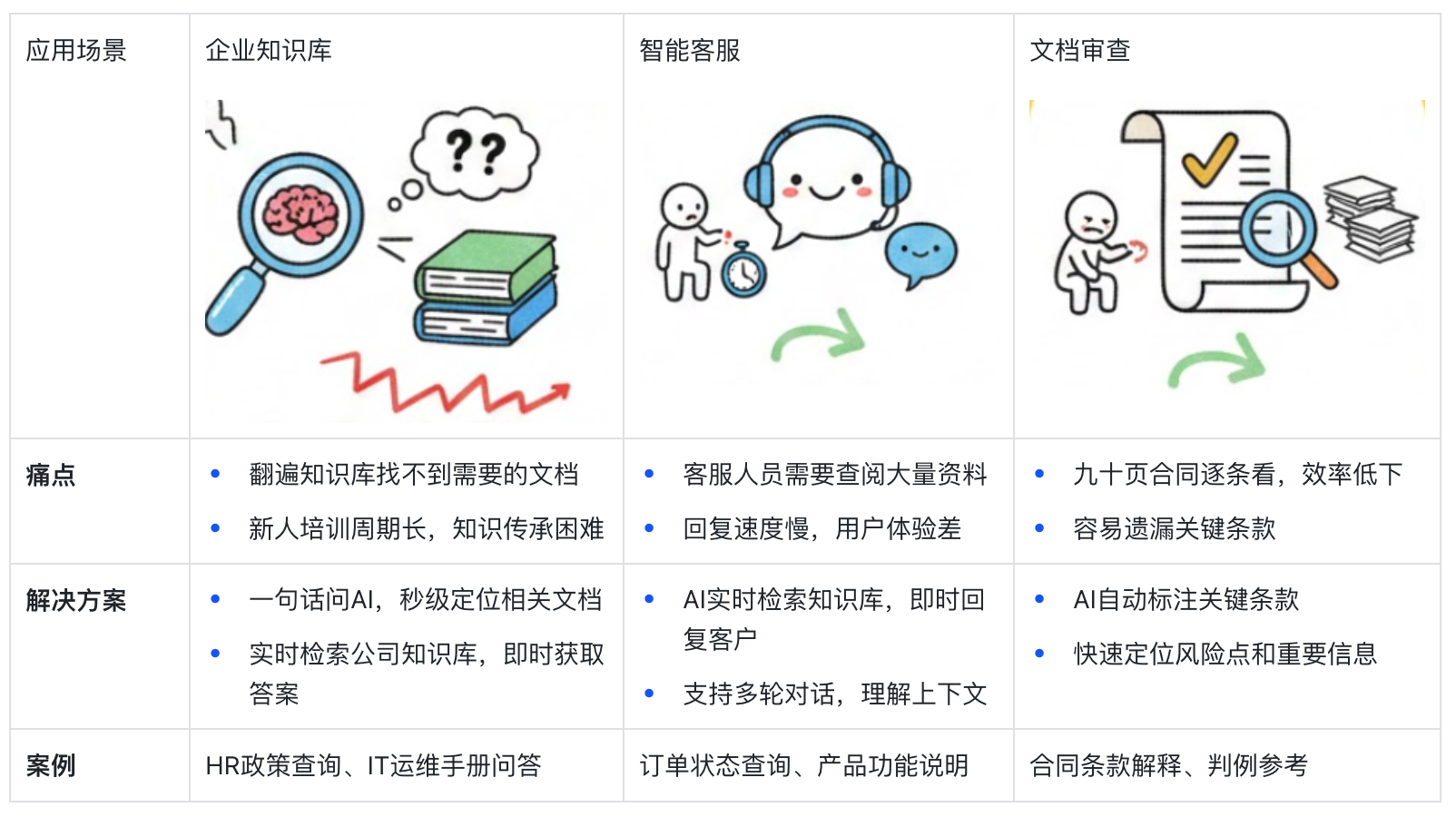
共同特点:知识密集·信息分散·需要精准检索
RAG的局限
RAG可以解决很多的问题,但是也有很多局限性。
首先,RAG的路程较长,每一步的失误或者误差,都会流向下一步,并逐步被放大,导致最后结果的错误;
另外,在处理上,过于的机械化,例如分块,会使得信息永久的被拆分成碎片,语义上无法理解1000和1K是一个东西,不能理解利润=收入-成本。
还有就是RAG的及时性和安全性,因为所有的知识要被完整的存储到一个地方,需要人及时地去维护最新信息的更新已经不被黑客攻击。
因此,在“外挂信息”上,有了新的解决方案——Agentic Search
Agentic Search存在的原因:上下文窗口的提升,原理是,不再需要对文档做切分,直接对完整的上下文,基于智能体的推理和智能导航,找到最优的信息。
总结
RAG不是”调模型”那么简单,而是一套完整的产品工程体系。作为产品人或技术人员,理解RAG的核心原理、掌握优化技巧、选择合适的技术方案,才能构建真正有价值的AI应用。
当你学会了RAG,结果发现有了新的技术革命,也不要恐慌,问问自己:
- 它解决的核心问题是什么?
- 为什么会有这个问题?
- 如果没有这个问题约束,会怎样?
想清楚这些,就能发现怎么更好地利用技术解决自己的问题了。
本文由 @诸葛铁铁 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


