
 起点课堂会员权益
起点课堂会员权益大模型训练大纲
Transformer架构如何支撑GPT与BERT的差异化能力?MOE模型如何实现稀疏激活与动态分配的巧妙平衡?本文深度拆解大模型训练的7大核心流程与关键组件,从矩阵评估到框架选择,揭示AI研发过程中模型收敛与过拟合的本质差异,并解读MCP协议如何重塑AI与外部系统的连接标准。

1、两种模型架构设计
架构1-Transformer
Transformer核心3要素:自注意力机制、位置编码、前馈神经网络(FNN)
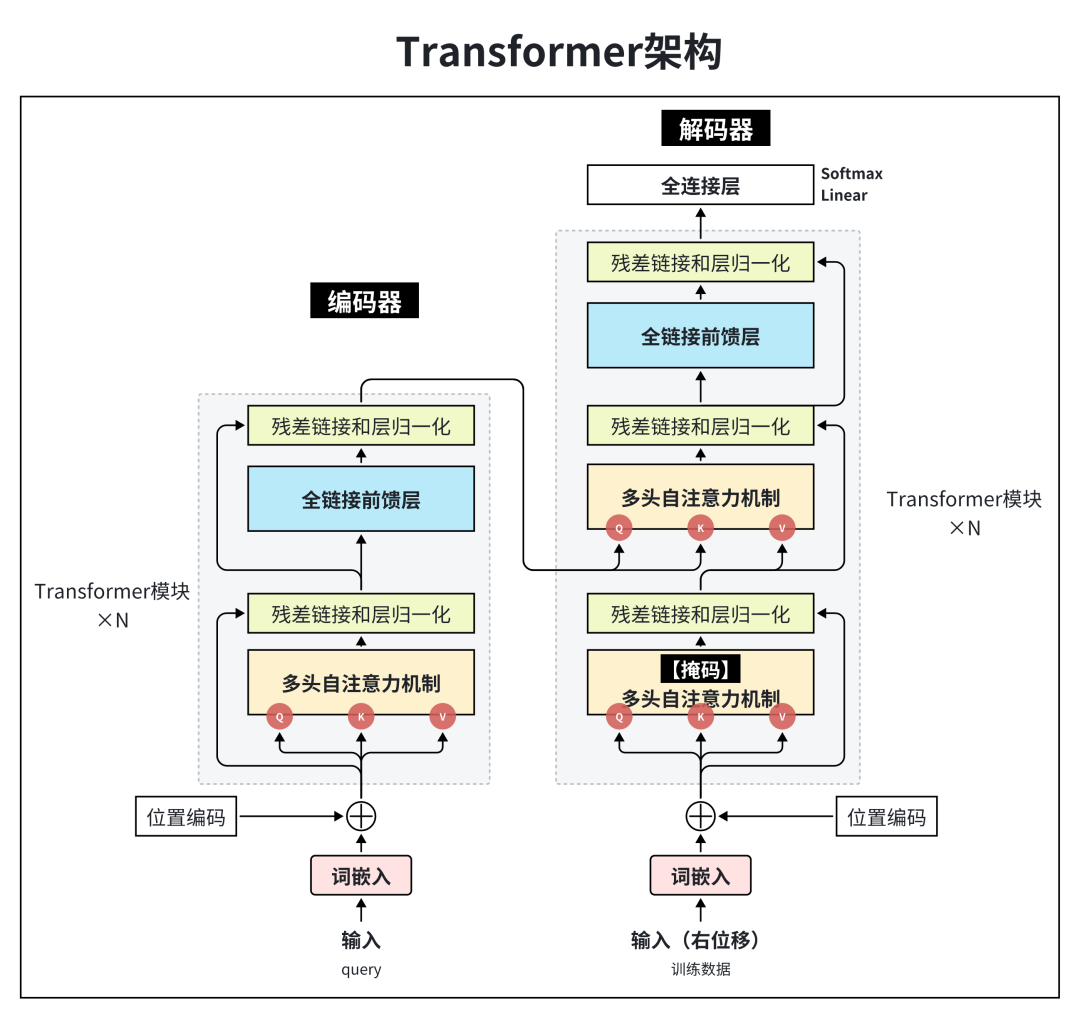
输入部分:
源文本【嵌入层】及其【位置编码器】
目标文本【嵌入层】及其【位置编码器】
编码器(Encoder)
由N个编码器层堆叠而成
每个编码器层由两个子层连接结构组成
第一个子层连接结构包括一个【多头自注意力子层】和【规范化层】以及一个【残差连接】
第二个子层连接结构包括一个【前馈全连接子层】和【规范化层】以及一个【残差连接】
解码器(Decoder)
由N个解码器层堆叠而成
每个解码器层由三个子层连接结构组成
第一个子层连接结构包括一个【多头自注意力子层】和【规范化层】以及一个【残差连接】
第二个子层连接结构包括一个【多头注意力子层】和【规范化层】以及一个【残差连接】
第三个子层连接结构包括一个【前馈全连接子层】和【规范化层】以及一个【残差连接】
输出部分:
线性层
Softmax层
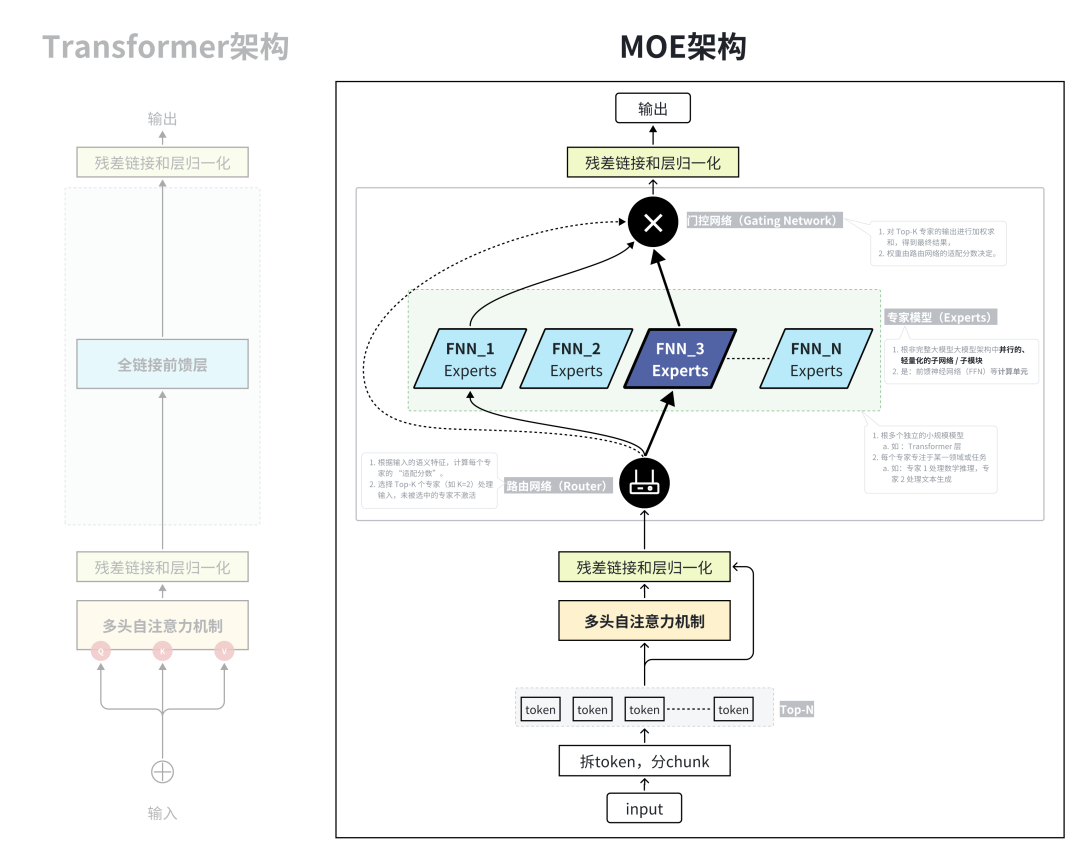
架构2-MOE(混合专家模型)
定义:MOE(Mixture of Experts,专家混合模型),是 “提升模型容量而不增加计算量” 的模型架构设计范式
MoE 是作为架构优化范式,叠加在 Transformer 上(主流方式是替换 Transformer 的 FFN 层为 MoE 层)
核心:是 “分而治之”, 让不同的 “专家模块” 处理不同类型的任务,再通过路由网络整合结果。
组件:
专家模块(Expert):多个独立的小规模模型(如 Transformer 层),每个专家专注于某一领域或任务(如专家 1 处理数学推理,专家 2 处理文本生成);
路由网络(Router):根据输入的语义特征,计算每个专家的 “适配分数”,选择 Top-K 个专家(如 K=2)处理输入,未被选中的专家不激活;
门控机制(Gating):对Top-K 专家的【输出】进行加权求和,得到最终结果,权重由路由网络的适配分数决定。
优势:
稀疏激活:每次仅激活少量专家(如 10%),计算量与专家数量无关,仅与激活的专家数量相关;
动态分配:不同输入会被分配给不同专家,模型可自适应处理多领域任务(如同一 MOE 模型可同时做数学题、写文案、翻译)。
在不显著增加计算量的前提下,提升模型的参数规模和任务适配能力。
2、两种Transformer模型
GPT
定义:
生成式预训练变换器Generative Pre-trained Transformer
深度学习-神经网络模型
Generative: 生成下一个单词
Pre-trained: 互联网文本预训练
Transformer: 架构
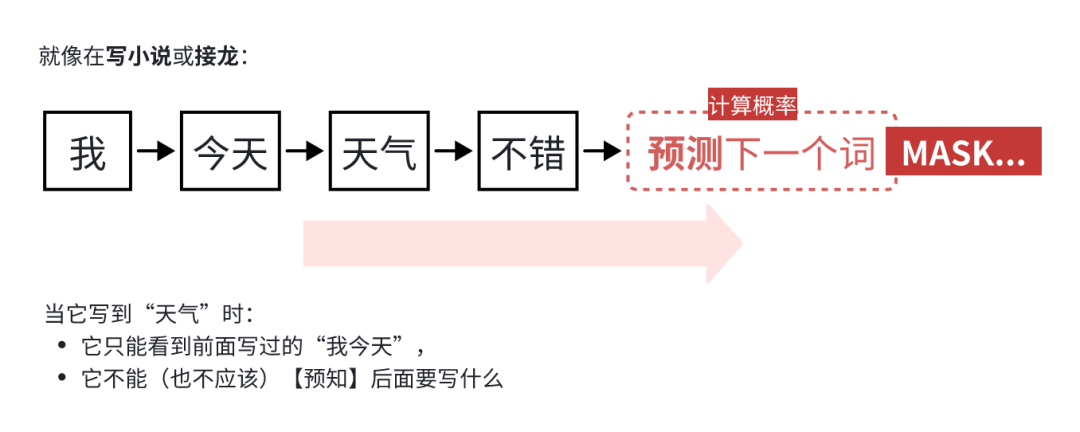
定位:生成式模型,核心任务是 “根据前文预测下一个词”,最终能输出连贯的文本。
特点:
构成:基于 Transformer 架构,但只用了 Transformer 的 Decoder(解码器) 部分。
单向注意力/自回归:训练和生成时,只能看到前文,看不到后文,比如写一句话时,模型只知道前面的字,要一步步猜后面该写什么。
即:只能看左边(过去),适合生成文本。
应用场景:
GPT 的核心特征就是基于单向自回归,具备强大的文本生成能力。
GPT 类模型常被用于对话、创作等生成类任务。
BERT
定义:
来自变换器的双向编码器表征, Bidirectional Encoder Representations from Transformers,
深度学习-神经网络模型
定位:
理解式模型,核心任务是 “理解文本语义”,擅长做文本分类、情感分析、命名实体识别、问答匹配等任务
不擅长直接生成长篇文本
特点:
基于 Transformer 架构,但只用了 Transformer 的 Encoder(编码器) 部分。
双向注意力:预训练时采用双向掩码(Masked Language Model) 策略,比如把一句话里的某个词盖住,模型能根据这个词的前文 + 后文来猜被盖住的词是什么。基于双向注意力,上下文全都要,适合理解句意,具备强大的语义理解能力
输出的是文本的 “语义向量”,常作为下游任务的 “特征输入”(比如 RAG 中的向量化就常用 BERT 类模型)。
应用场景:
BERT 类模型常被用于向量化、文本语义理解(文本匹配)等理解类任务
进行embedding,将 文本数据转换为 数值型的向量表示。
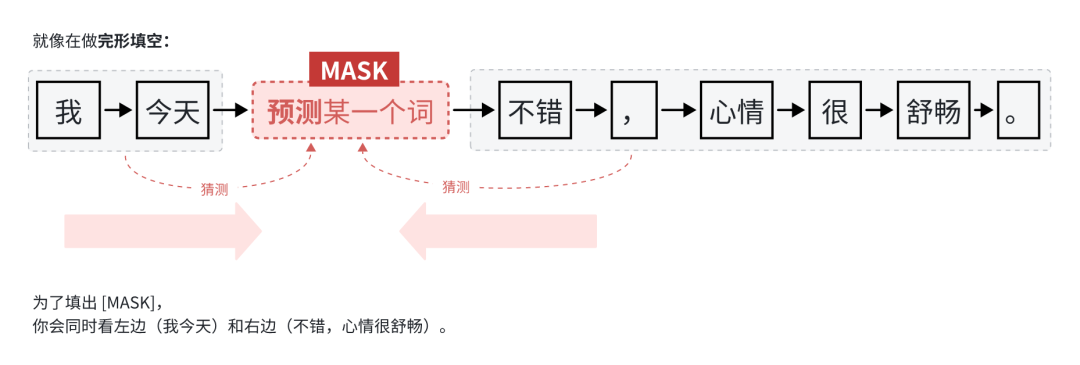
3、大模型训练流程
大模型训练流程
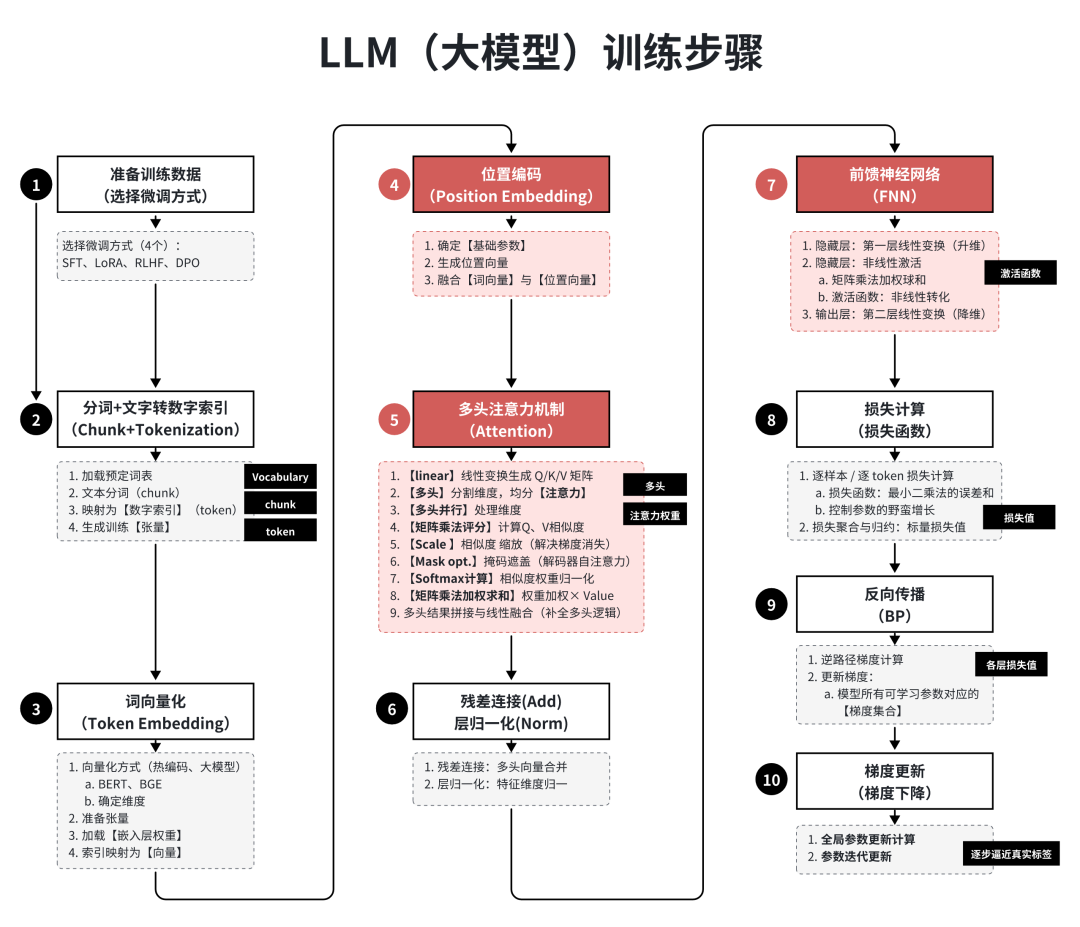
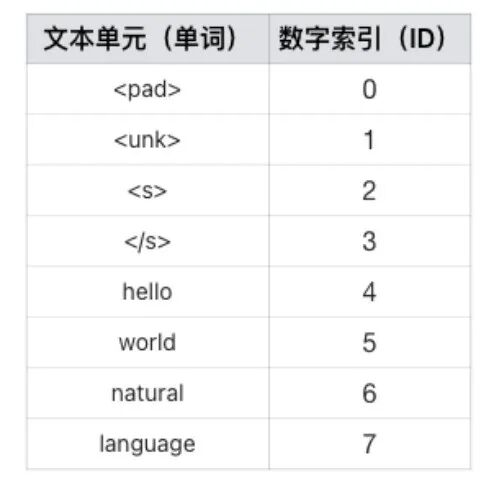
名词1:载预定义词表(Vocabulary)
预定义词表(Vocabulary):是模型可识别的最小语义单元(Token)与唯一数字索引的映射字典.。
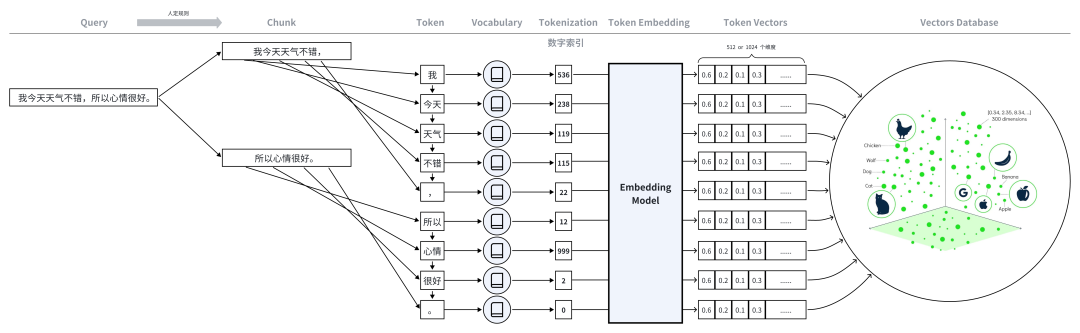
名词2:文本向量化
1、拆分文本:人工策略,将文本分成多个chunk块。
2、加载预定义词表(Vocabulary)
3、文本语义分析分词(chunk→token):将长文本(chunk)切分为模型可处理的最小语义单位(token),
4、映射为数字索引(Tokenization):对照词表,将每个token替换为对应的唯一整数,生成数字索引序列
5、生成辅助训练张量:生成attention_mask:标记有效token(1)和填充token(0),防止模型计算无效数据。生成token_type_ids(可选):区分不同文本片段(如prompt部分=0,response部分=1)。
名词3:多头注意力机制
用户输入信息,Attenetion计算,宏观来说一共三步:
第一步:计算相似度:Queryvs Key
第二步:权重归一化:Softmax
第三步:加权求和:权重×value
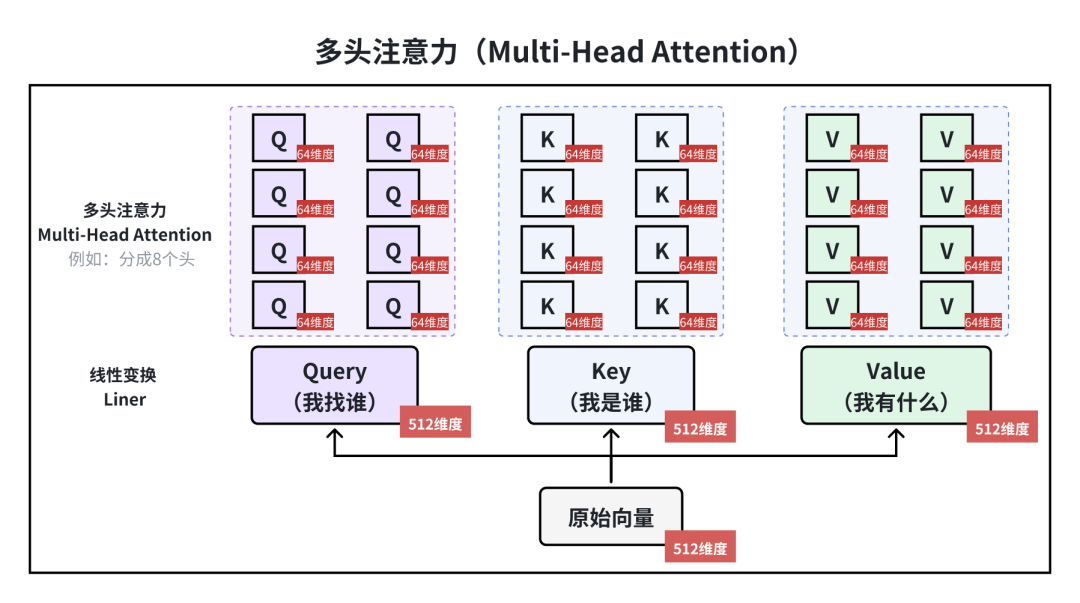
名词4:矩阵乘法
计算 Q 与 K 的相似度(矩阵乘法评分)
在一个头中,对 Q 和 K 进行矩阵乘法运算,矩阵中【每个元素】对应序列中一个词/tokne的 Query 与【另一个词】的 Key 的相互作用得分,表征两个词的关联程度。
计算式:\text{score} = Q \times K^T
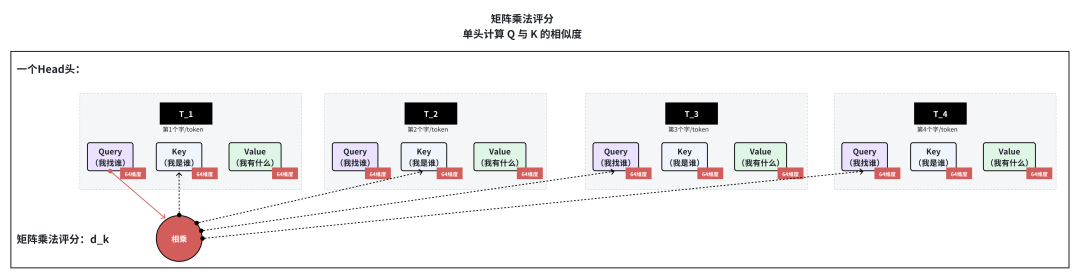
名词5、6:Scale、Softmax
相似度权重归一化(Softmax 计算)
对缩放后的相似度得分执行 Softmax 函数,将任意实数的得分转化为 0-1 之间的概率分布,概率值的大小表征对应 Key 对当前 Query 的重要程度。
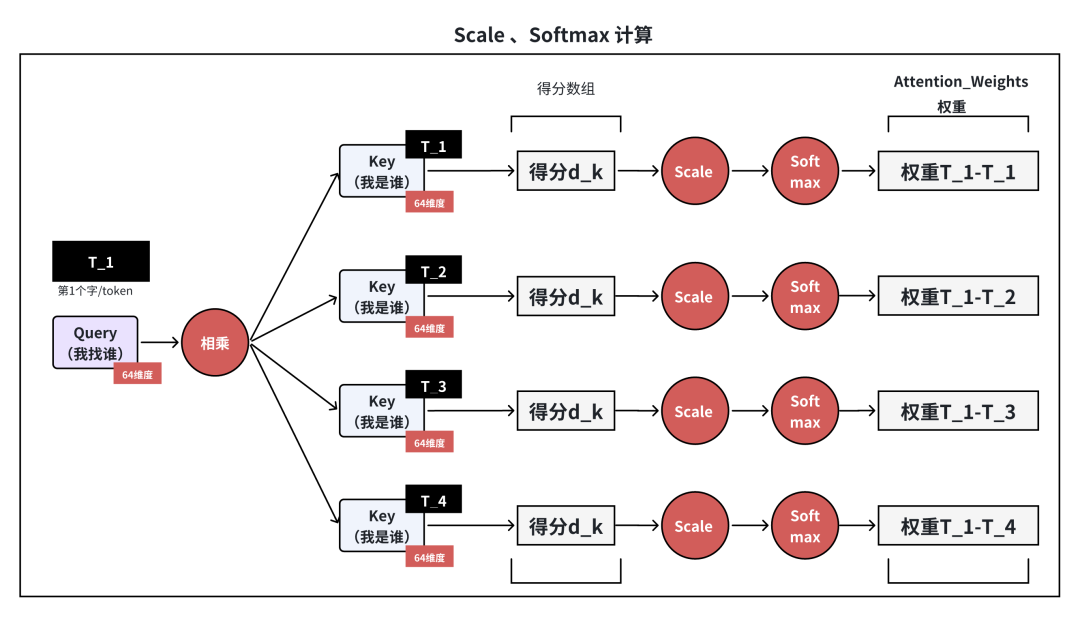
名词7:矩阵相乘权重累加求和
权重加权 Value(矩阵乘法加权求和)
将【归一化后的注意力权重】与【 Value 矩阵】进行乘法运算,得到融合上下文信息的向量表示。
意义:
信息整合:根据注意力权重的分布,为每个 token 融合序列中其他相关 token 的信息,权重越高的 token 贡献的信息越多。
上下文感知:每个 token 的最终表示不再孤立,而是结合了整个序列的语境,能够捕捉语义依赖(如“爱”在“我爱你”中融合“我”和“你”的信息)。
增强语义理解:有效处理多义词、长距离依赖等复杂语言现象。
名词8:损失函数
逐样本 / 逐 token 损失计算:
将预测概率分布与真实标签匹配,按损失函数公式计算【单样本 / 单 token 】的损失值,结合损失掩码屏蔽无效位置损失。
损失函数:
最小二乘法的【误差和】,控制参数的野蛮增长。
训练的本质就是:减小损失函数,往误差小的地方发展。

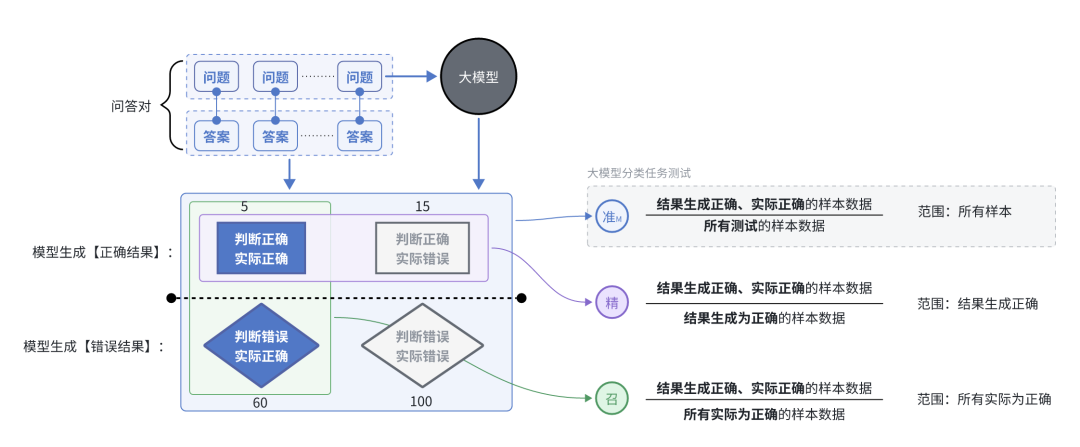
4、大模型二分类矩阵评估(准召率)
二分类测试:
首先,准备测试集(例如100个)
其次,问题特征:
1、都是二分类的问题类型(有明确的对、错)
2、都是微调训练给大模型【有关于的业务理解能力】的问题(例如:业务规则逻辑)
3、每个问题有标准答案,有标准答案(正确的业务规则)
4、最后,基于这100条数据的回答,依据准确答案,评价大模型回答的结果。
大模型回复结果:
TP(真阳性):正类被正确预测为正类的数量;(问 “地球是圆的吗”,模型答 “是”,实际也对)
TN(真阴性):负类被正确预测为负类的数量;(问 “太阳绕地球转吗”,模型答 “是”,实际错了 → 模型 “虚报”)
FP(假阳性):负类被错误预测为正类的数量;(问 “水的化学式是 H₂O 吗”,模型答 “不是” → 模型 “漏报”)
FN(假阴性):正类被错误预测为负类的数量。(无核心参考价值)
5、大模型训练评估结果
模型效果达到预期:模型在【训练集】和【测试集】上都表现良好
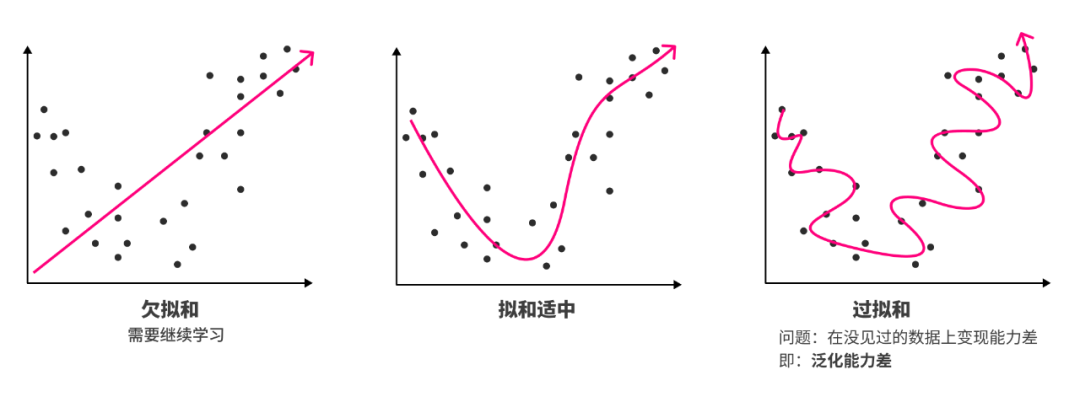
欠拟合:
欠拟合是指模型不能很好地拟合数据,即模型在训练集和测试集上的表现都很差。这通常是因为模型过于简单、数据量太小或特征选取欠佳等原因,无法捕捉到数据中的关键特征和模式。
过拟合:
过拟合指的是模型在训练数据上表现良好,但在新数据上的泛化能力较差。
通常是因为数据量太小、模型过于复杂或者特征选取过多等原因导致。
无法收敛:
模型不收敛 是指模型在训练过程中无法达到一个稳定的状态,即损失函数(或其他评估标准)不会随着训练迭代而减小或者改善。
这通常意味着模型无法有效地学习和适应数据,导致模型的预测结果不稳定或不可靠。
6、两种AI研发框架
2种框架:用于【大模型训练】的框架、还有【AI应用程序开发】的框架、
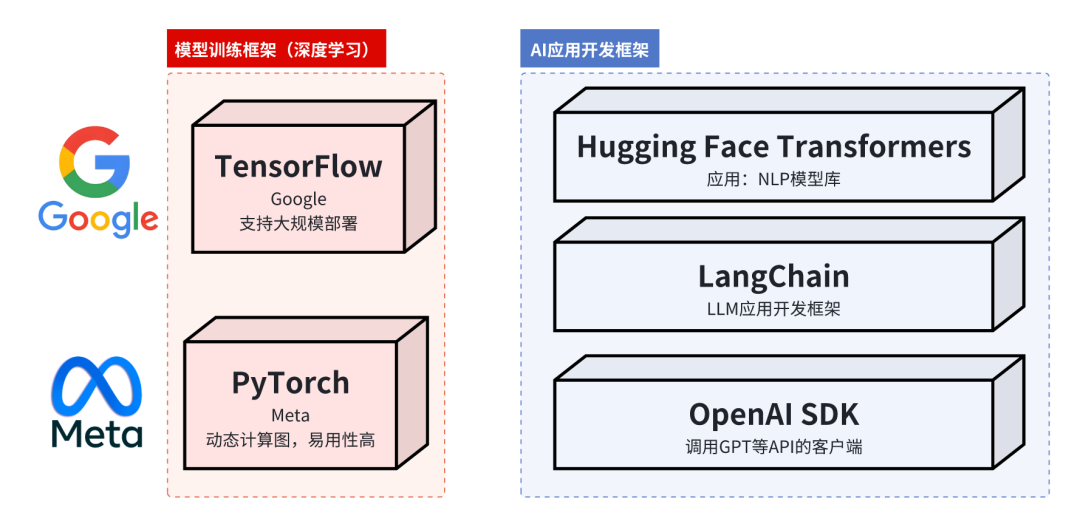
1、深度学习训练-框架:
TensorFlow (Google):最主流的工业级框架,支持大规模部署
PyTorch (Meta):研究领域最流行,动态计算图,易用性高
2、应用程序开发-框架:
Hugging Face Transformers:NLP模型库
LangChain/LlamaIndex:LLM应用开发框架
OpenAISDK:调用GPT等API的客户端
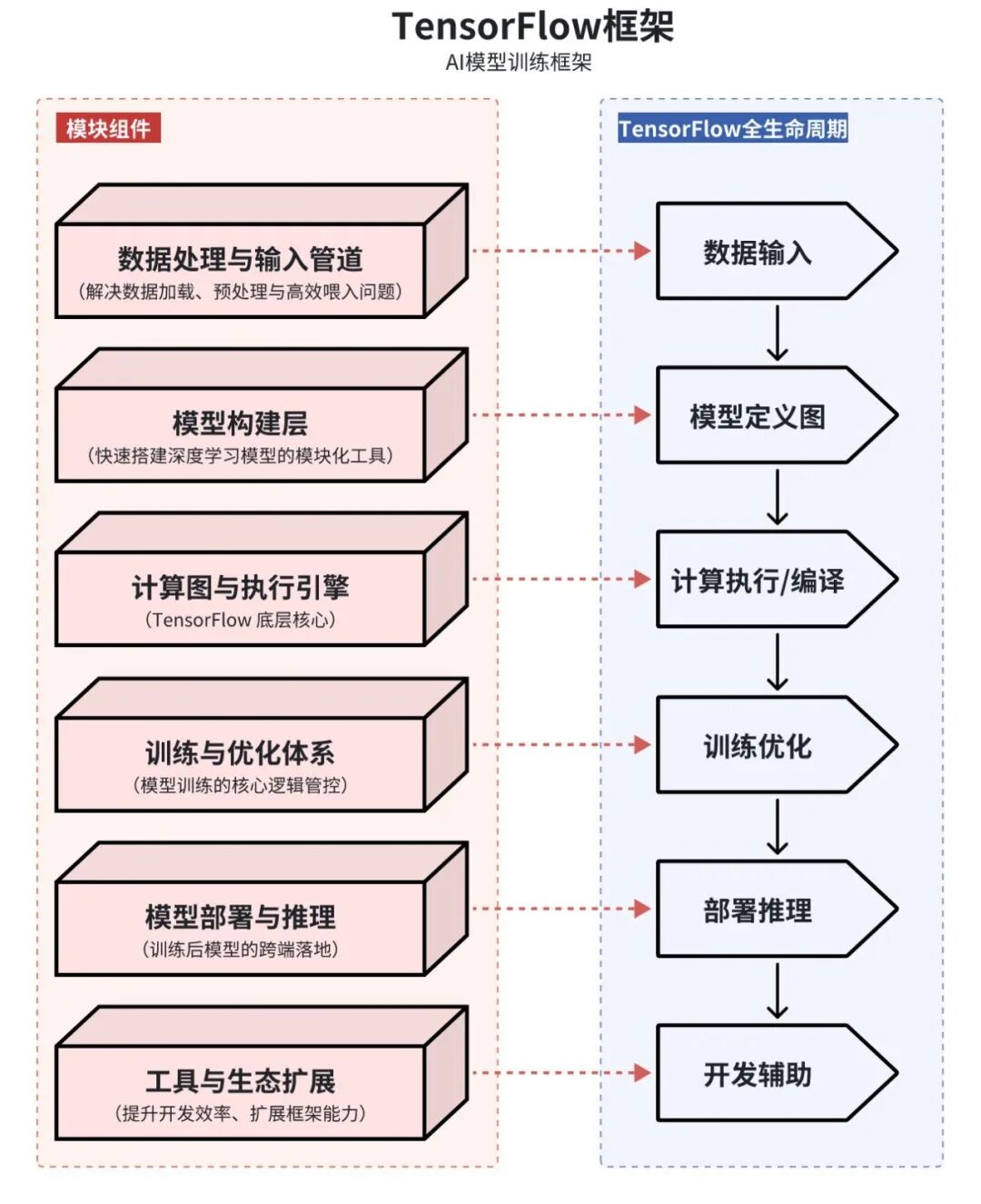
AI模型训练框架(以TensorFlow为例)
TensorFlow 是谷歌开源的【端到端】深度学习框架,
核心围绕“定义计算图→执行计算→部署模型”全流程设计,所有功能可拆解为6大核心模块,覆盖从开发到部署的全生命周期。
TensorFlow 是一套“从数据到部署”的全栈深度学习工具链,6大模块各司其职,既独立又能无缝协作,是工业级深度学习开发的核心框架。
特点:静态计算图。先定义计算图,后执行。部署是其强项。
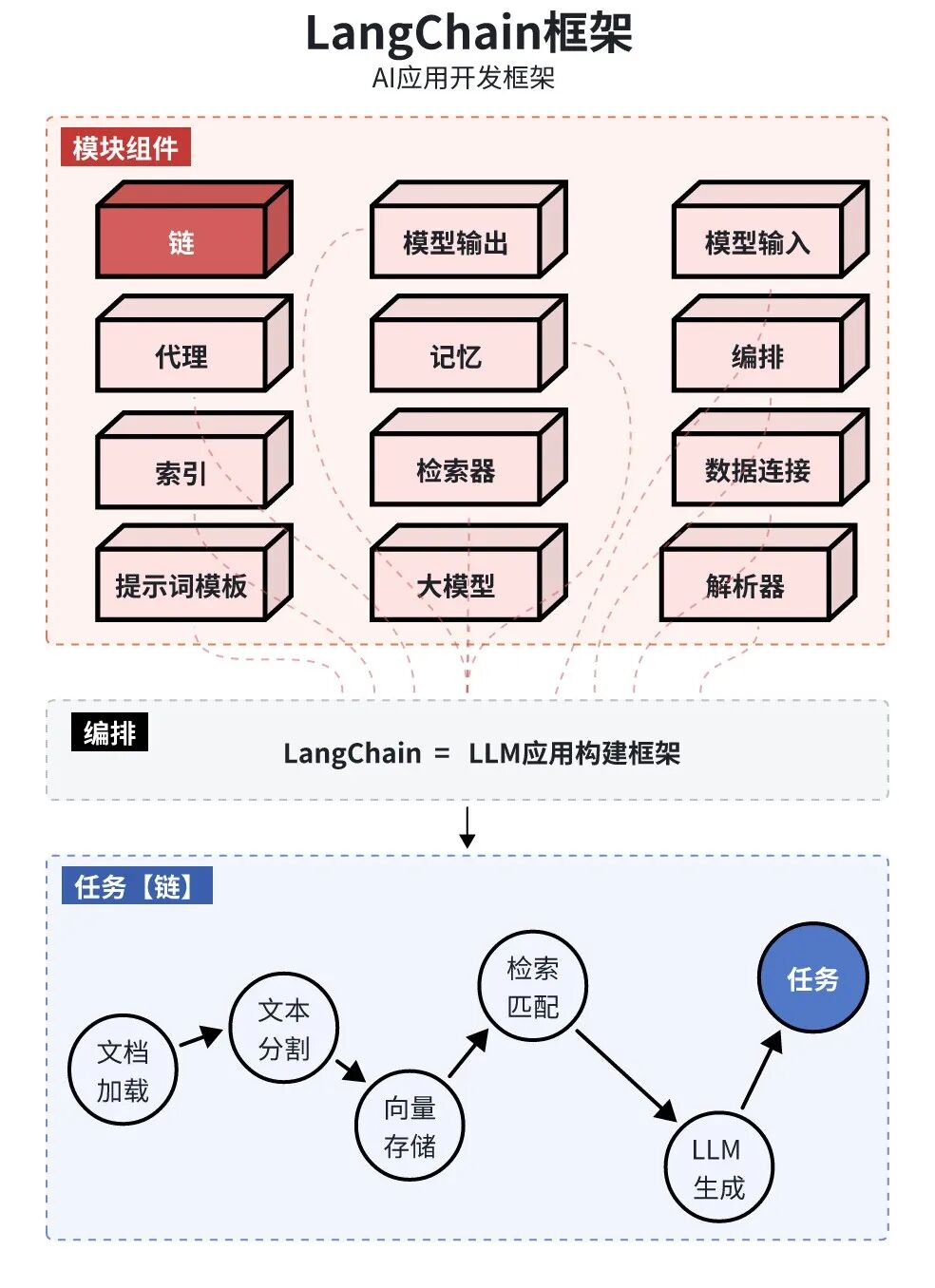
AI应用开发框架(以LangChain为例)
定义:开发框架,帮助开发人员使用语言模型构建【端到端】的应用程序。
构成:
提供一套工具、组件和接口,可简化创建由大型语言模型(LLM)和聊天模型提供支持的应用程序的过程。
模块组件(Components)和链(Chains)。
组件:是模块化的构建块,可以组合起来创建强大的应用程序;
提示模板(Prompt Templates)和值(Prompt Values)、示例选择器(Example Selectors)、输出解析器(Output Parsers)、索引(Indexes)和检索器(Retrievers)、聊天消息历史(Chat Message History)、代理(Agents)和工具包(Toolkits)等概念。
链:是完成特定任务的一系列组件。
编排:调用模块,设计操作流程
价值:
不用自己写代码处理 “文档加载→文本分割→向量存储→检索匹配→LLM 生成” 全流程,
框架已经封装好了这些模块,开发者只需要关注业务逻辑。
核心差异:LLM应用构建框架。核心是数据检索与工作流编
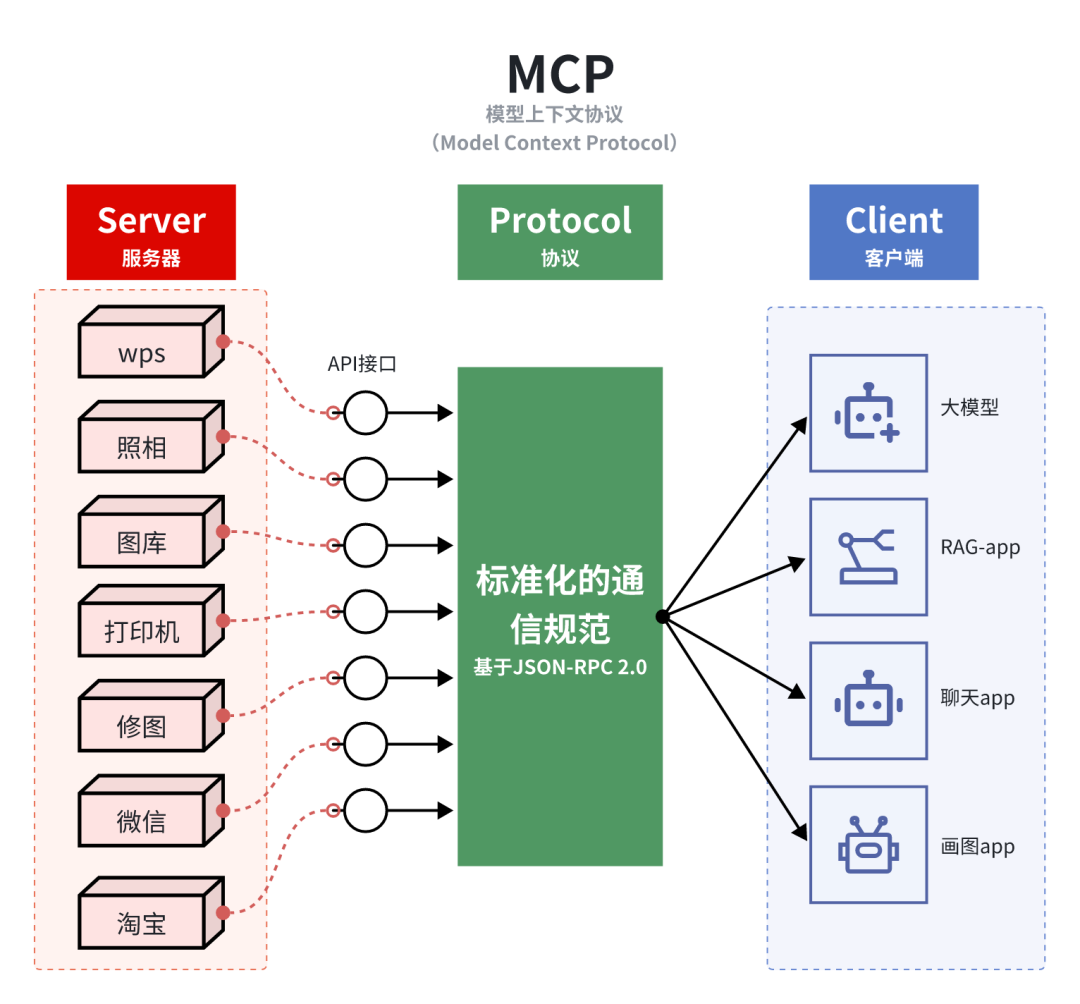
7、MCP协议
AI研发框架是:如何构建AI模型的工具
而MCP是:如何让AI模型安全访问外部世界的连接标准。
两者互补:框架提供AI能力实现,MCP提供环境集成能力。
定义:MCP模型上下文协议(Model Context Protocol)是Anthropic2024年11月,推出的【开放标准协议】,旨在标准化AI应用与数据源/工具之间的连接方式。它不是AI框架,而是连接协议。
目标:为LLM与外部数据源、各类工具及服务搭建标【准化交互接口】,建立统接口规范,解决AI模型与外部系统集成【效率低下】的行业痛点。如同: 万能转换器 或USB-C接口,解决模型与外部资源交互的诸多痛点。
本文由 @St.Zy_I 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


