
 起点课堂会员权益
起点课堂会员权益RAG技术:实现智能客服与知识库的核心方法
RAG技术正在重塑企业级AI问答的底层逻辑。从智能客服到知识助手,这种先检索后生成的方案如何通过分片、索引、召回等关键环节,解决大模型处理海量文档的痛点?本文深度拆解RAG技术的完整工作流与核心价值,带你看懂向量数据库与Embedding模型如何协同实现精准问答。

RAG技术概述与价值
很多企业内的知识助手、智能客服用的都是用rag这项技术,它的全称是retrieval augmented generation, 翻译过来就是检索增强生成,先从资料库里检索相关的内容,再基于这些内容来生成答案,也就是说它先检索再生成,所以叫做检索增强生成,rag是目前最常用的AI问答方案之一
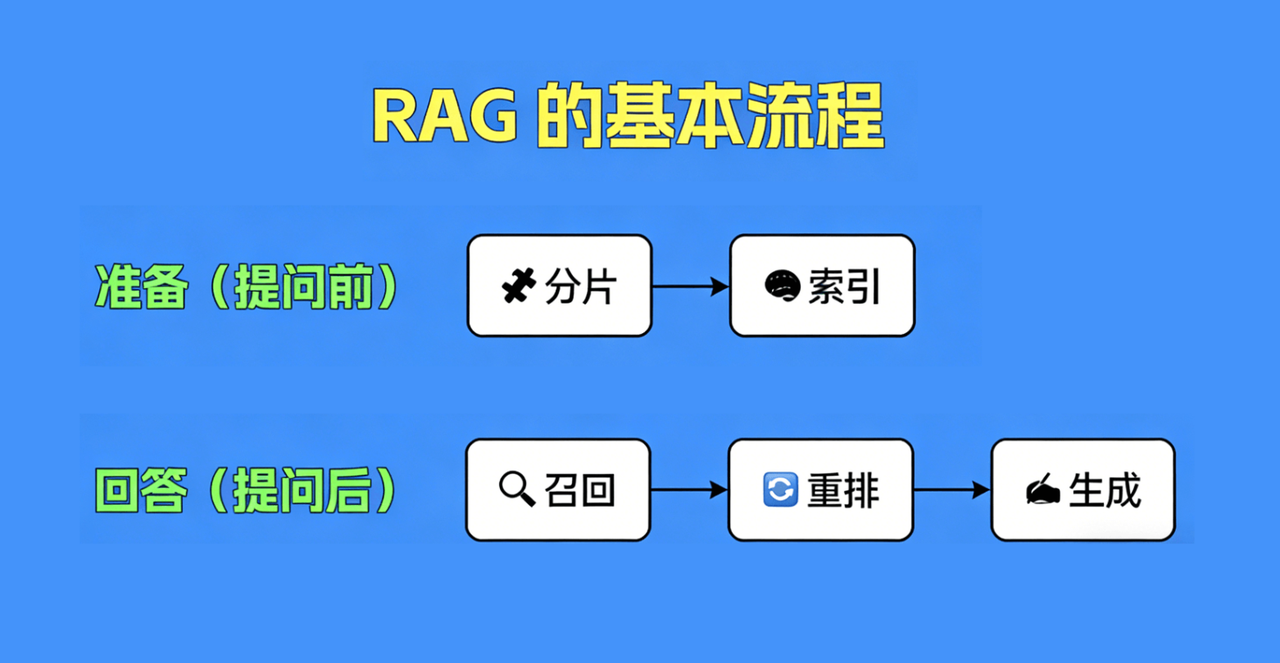
RAG基本流程与核心环节
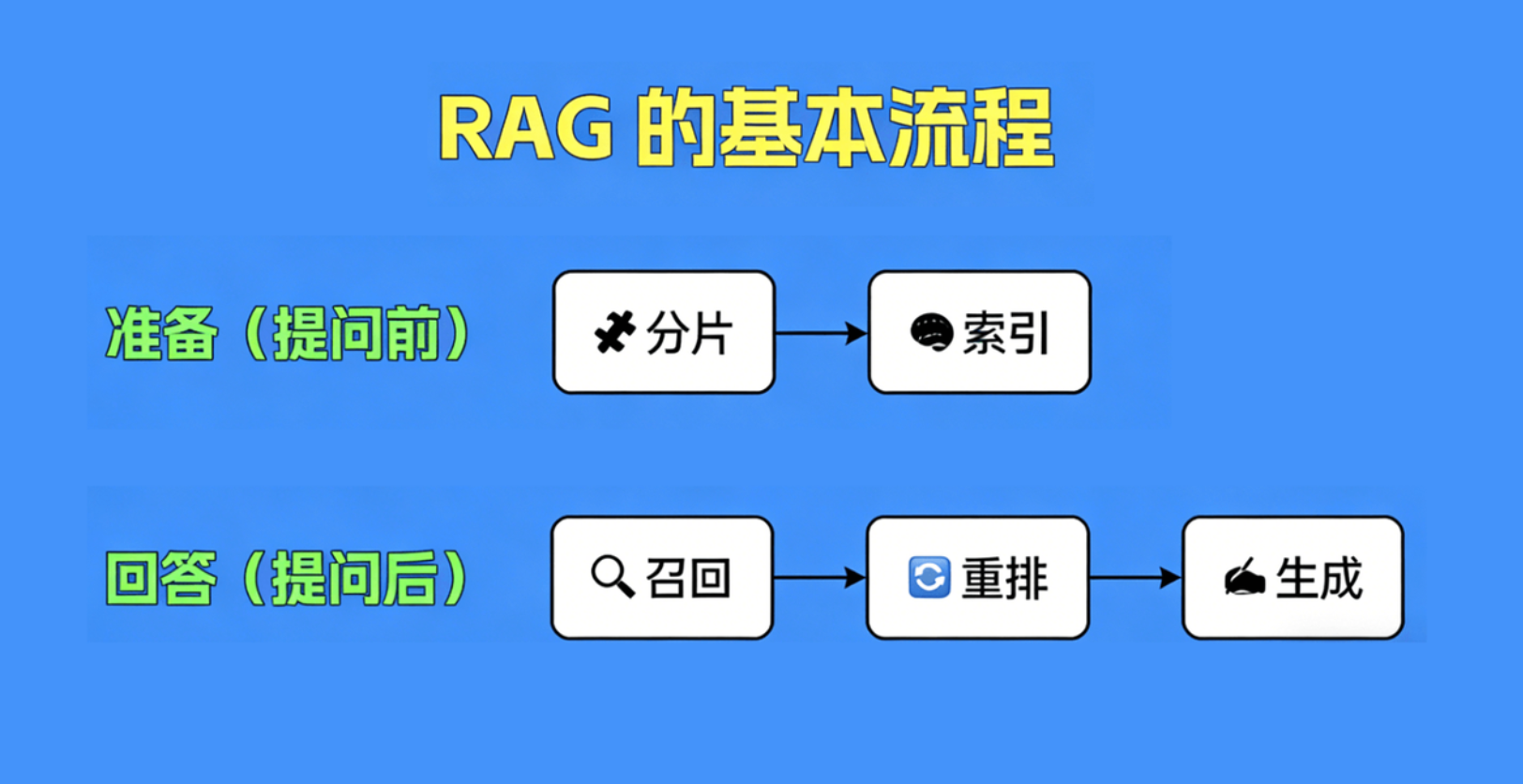
1、数据准备:获取并预处理原始文档。
2、分片:将文档切分成小的文本块。
3、索引:将文本块转换成向量并存储到向量数据库。
4、召回:根据用户查询,从向量数据库中召回Top N个最相关的上下文。
5、重排:对召回的上下文进行重新排序,提升相关性。
6、生成:将重排后的上下文和用户问题输入 LLM,生成最终回答
假设你想做一个智能客服,这个智能客服可以回答各种关于你们公司产品的问题,那应该怎么实现它呢?(以下场景用coze搭建的模拟客服项目)
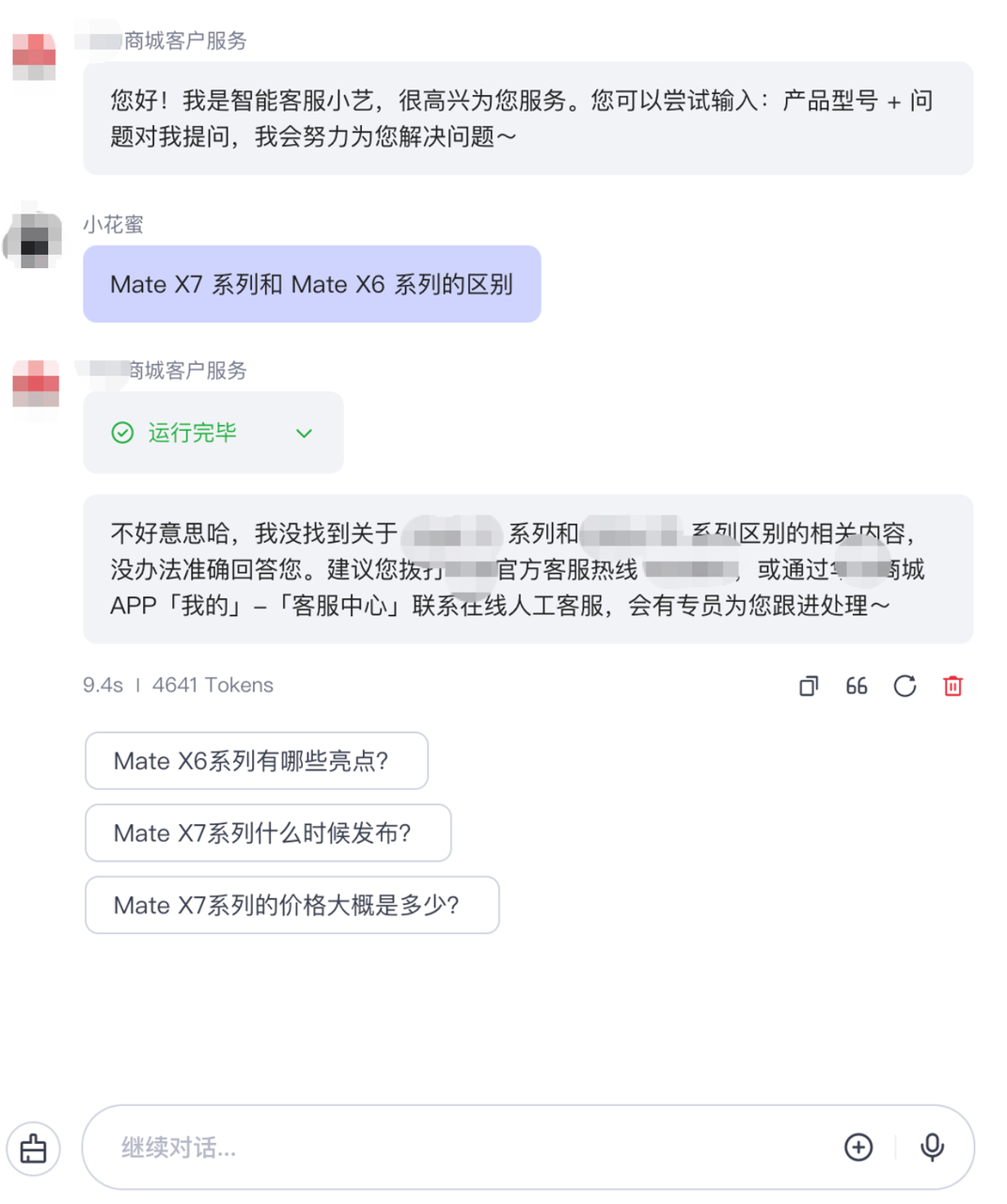
首先,这个客服的内部一定要有个模型,比如说是千问,DeepSeek这种的。
不过光有个模型可不够,因为模型可不知道你们公司的产品信息。但这个问题好办,在给模型发送问题的时候,我把产品手册一起发个模型不就好了?没错,这确实是一个解決方案。不过,如果产品手册的字数特别多,比如有个上百页乃至上千页的话,这就会带来很多问题。首先,模型可能无法读取所有的内容,因为每个模型都只能存储一定量的信息,我们通常称这个量为上下文窗口大小。

如果你的产品手册字数过多,超过了这个上下文窗口大小的话,模型就会读了,后面忘了前面回答的准确率也就无法得到保障。除此之外,模型推理成本也会很高,输入越多成本越高,每次回答问题的时候都要带上一本厚厚的手册,那成本可想而知。最后模型的推理速度也会受到影响,输入越多,模型需要消化的内容就越多,模型的输出就会越慢,一本上百页的手册扔进来,那大概率会对模型的推理速度产生严重的影响,看来直接把文档丢给模型是行不通的。

那我们是不是可以考虑只把文档中相关的内容发给模型呢?可以的,这就需要rag登场了,我们一起来看看rag是如何解决这个问题
RAG关键技术概念解析
首先rag会把文章切成多个片段,当用户提出问题后,我们就用这个问题在所有的片段中寻找相关内容。比如,在一份上百页的产品手册中,可能只有3个片段真正与用户的问题相关,我们就把这3个片段单独挑出来,把它们和用户的问题一起发给大模型。这样模型就只会感知3个相关的片段,而不是整个文档之前的问题也就会迎刃而解了,对rag就是这样的了,是不是很简单?
分片
比如说是如何分片,如何选择相关的片段,这里面的学问都不少。所以呢,下面我把整理的整个rag流程具体来拆分一下,通常来说rag的整个流程分为两部分,一个是数据准备部分,这个是发生在用户提问前,我们要在这一部分里把相关的文档准备好,并完成相应的预处理,他一共是包含分片和索引两个环节,另外一个就是回答的部分,这一部分就发生在用户提问之后,在用户提问之后,我们便会触发回答问题的各个环节,分别是召回,重排和生成,接下来我们就看看他们是如何工作的
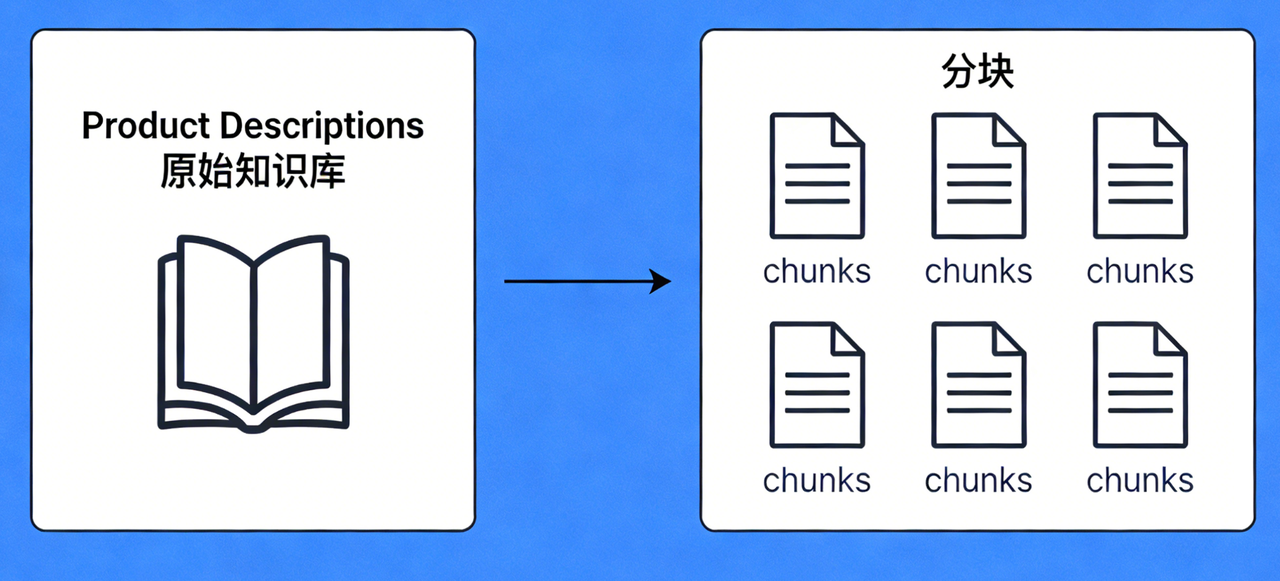
顾名思义就是把文档切分成多个片段。分片的方式有很多种,固定长度、语义感知、文档结构、关键词/主题、多粒度、混合分块;但不管怎么做我们最后都需要把一篇文档切分为多份,切好后这个环节就结束了,然后我们就要进入到下一个环节。
索引
索引就是通过embedding将每一个片段文本转化为向量,然后再将片段文本和对应向量都存储在向量数据库的一个过程为什么要把片段、文本和对应向量存在向量数据库,是因为这样方便快速检索和比较相似性。向量能更直观地体现文本间的关系,计算机处理起来效率高。用embedding模型把文本转成向量,是因为向量形式能把文本的语义信息数字化。就好比给每个文本一个独特的“数字指纹”,通过对比指纹的相似度,就能知道文本内容像不像,这样能更好地理解文本意思

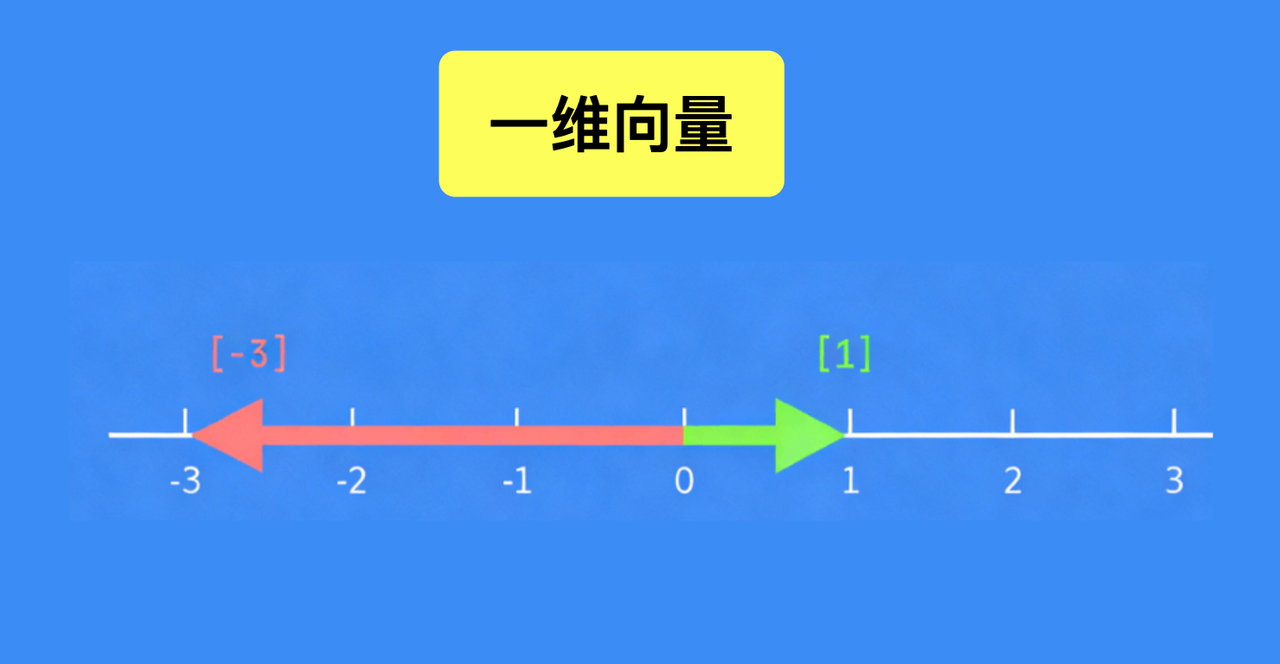
我们先搞懂最基础的向量,这是后续所有实用功能的前提。向量本身是个数学概念,核心特点是既有大小、又有方向——这个特性是它能帮我们处理信息的关键。
从维度上看,向量分一维、二维、三维甚至更高维度:一维向量可以直接对应到一条坐标轴上,比如向量“1”,我们画出来就是长度(大小)为1、方向朝右的线段;向量“-3”则是长度为3、方向朝左的线段,一眼就能区分两者的差异。
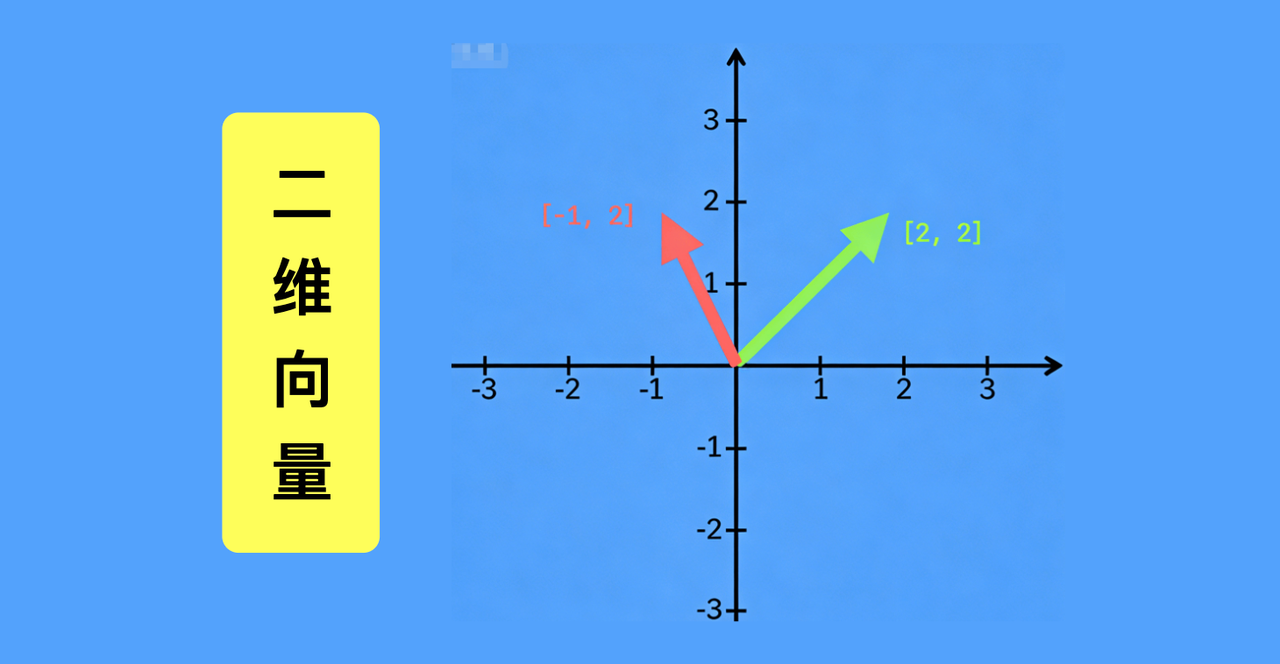
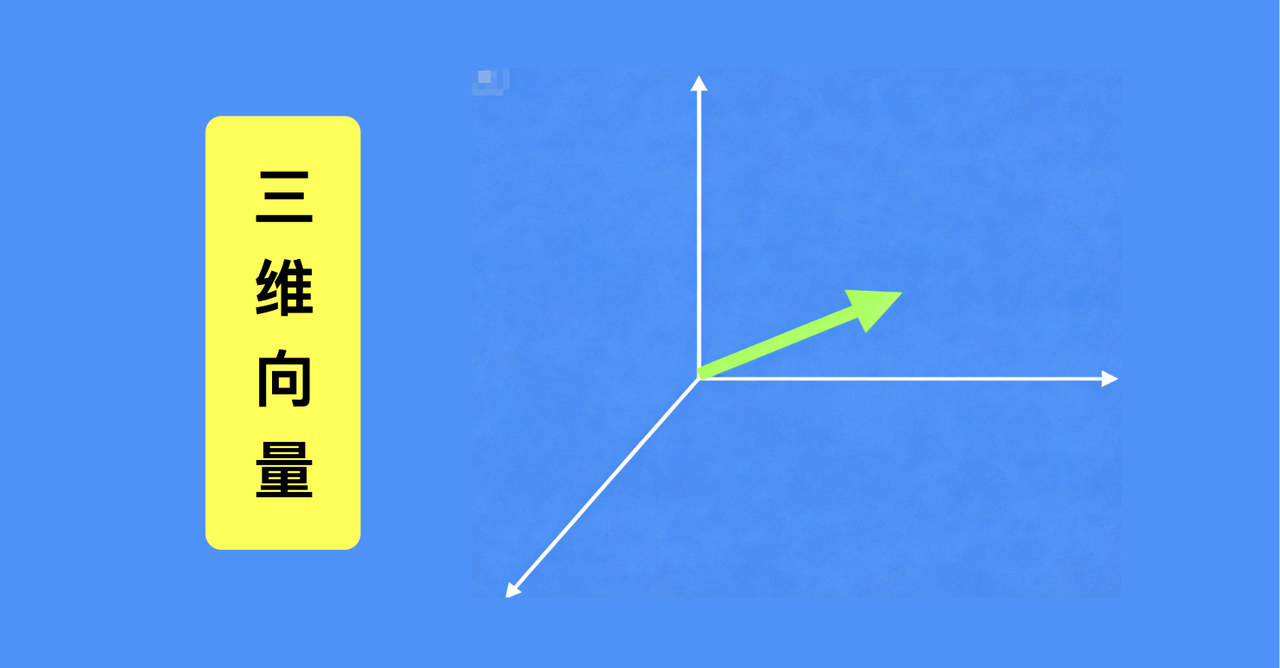
要表示二维向量,就需要用到平面直角坐标系,比如向量(2,2)、(-1,2),都能在这个坐标系里找到明确位置,精准定位其对应的信息属性。同理,三维向量需要三维坐标系承载。
这里要注意,维度可以无限提升,只是超过三维后,我们没法用视觉直观展示——但看不见不代表没用,反而高维度向量对我们更有价值。实际应用中,我们接触到的向量(比如在AI工具、数据处理场景里)往往是几百、几千维的,维度越高,向量包含的信息越全面,用它处理问题的准确率和可靠性就越强,能帮我们更精准地拿到想要的结果。
懂了向量,再看Embedding——它本质是个“转化工具”,核心作用是把文本信息变成向量,而这个转化过程,正是帮我们快速筛选、匹配有效信息的关键,能大幅节省时间和精力。
我们用二维向量举个通俗例子,一看就懂:假设“乔布斯喜欢吃面包”转化后的向量是(1,2),“乔布斯爱吃面包”的向量是(1,1),“天气真好”的向量是(-3,-1)。很明显,前两个句子的向量距离极近,后一个则很远。这背后的逻辑的是:语义越相近的文本,转化后的向量位置越近——这就是Embedding的核心价值,帮我们快速判断信息是否相关。
这个逻辑能直接帮我们解决“找信息难、找不准”的问题:比如你想知道“乔布斯喜欢吃什么”,不用手动翻找所有相关文本,AI会先通过Embedding把你的问题转化成向量,再自动匹配向量相似度高的内容,快速筛选出“乔布斯喜欢吃面包”“乔布斯爱吃面包”这两条核心信息。
最后,AI会把你的问题和筛选出的相关信息一起交给大模型,大模型就能直接给出精准答案——整个过程高效且准确,帮你跳过无效信息,快速拿到自己想要的结果。这就是向量和Embedding的实用价值,从信息转化到精准匹配,全程为我们高效获取有效信息服务。
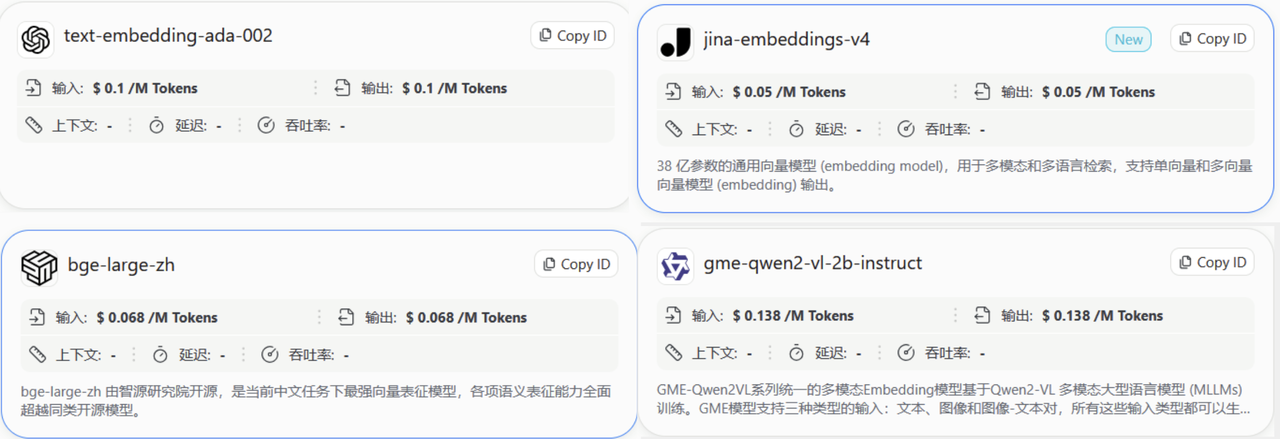
Embedding这个操作是模型来完成的,不过这个模型可不是我们通常所使用的GPT 4o、DeepSeek这样的模型,而是专门的embedding模型。以下是一些embedding模型(大家可以自行查询了解)
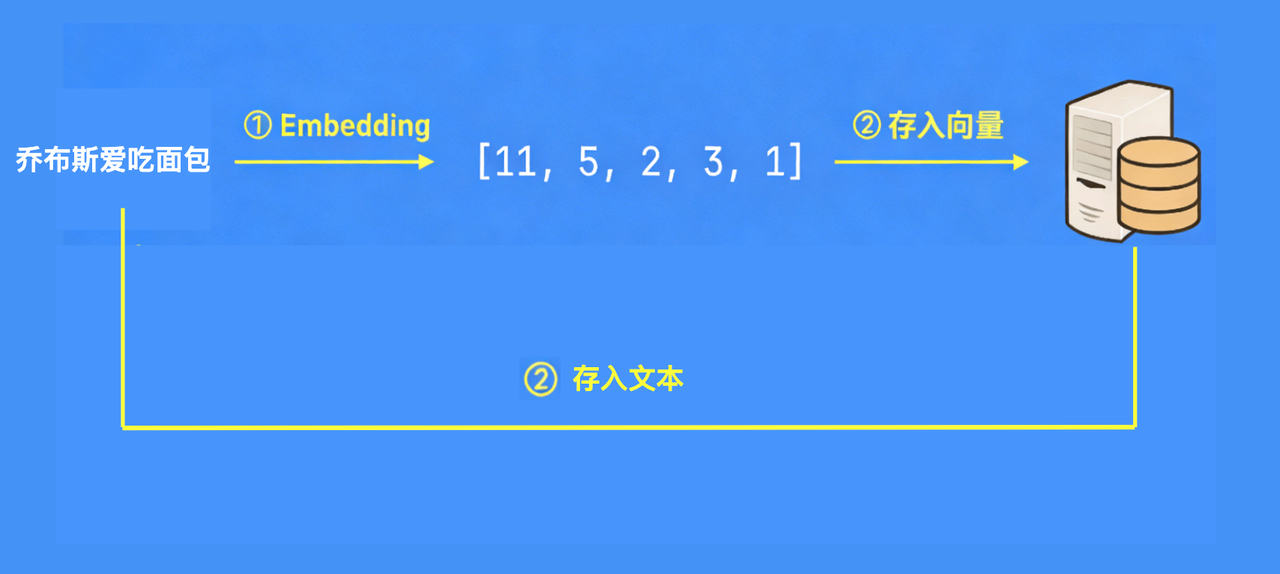
我们再来看看向量数据库。向量数据库就是用来存储和查询向量的数据库,它为存储向量做了很多优化,并且还提供了计算向量相似度等相关的函数,方便我们使用向量embedding后的向量呢,就可以放在向量数据库里面,方便后续查询。比如,我们还是以乔布斯喜欢吃面包这句话为例,在我们给这句话做了embedding之后,就得到了一个向量。然后我们需要把这个向量存入到向量数据库中。不过注意,我们要存的不仅有向量,还有原始的文本,所以原始文本也要发给向量数据库,因为只有这样我们才能够在通过向量相似度查询出相似的向量之后把对应的原始文本也抽取出来发给大模型让他处理。我们最终需要的还是原始的文本,向量呢,只是一个中间结果,所以一般的向量数据库表格里面至少都会有原始文本和向量两。向量embedding和向量数据库。
索引就是通过embedding将每个片段文本转化为向量,并且把片段文本和对应的向量都存储在向量数据库的过程。比如说,我们一开始要处理的是片段1,片段1处理完了之后呢,我们要处理片段2,以此类推,直到所有的片段都处理完毕,这整个索引的流程就都结束了。不管是分片还是索引,他们都发生在用户提问之前,属于要提前准备的步骤。下面我们就来看看用户提问之后发生了什么。
召回
首先是召回召回就是搜索与用户问题相关片段的过程,这个环节从用户问题开始。
首先,用户的问题会发给embedding模型。Embedding模型会将它转化为向量。然后,我们把它发送给向量数据库,让它查询与用户问题最为相关的10个片段内容。没错,召回的结果呢,就是10个与用户问题相关的片段。当然,十这个数字呢,并不是固定的,你也可以设置十五二十等等。具体是多少呢,不是很重要,只要数量不是很多都可以。那不管是多少向量数据库呢,都要返回与用户问题最相似的一批片段。那向量数据库是怎么知道哪些片段与用户问题最相关的呢?这就要计算向量相似度了。
向量数据库里面的数据。我们把用户的问题和对应的向量也放在这里。最后呢,要计算下每个片段与用户问题的向量相似度。向量数据库是专门用于存储和查询向量的数据库,为存储向量做了优化,并提供计算向量相似度等函数,需同时存储片段文本和对应向量,以便后续查询出相似向量后抽取原始文本
重排
下面我们进入到生成阶段,现在我们有了用户问题,也有与用户问题相关的三个片段,我们就可以把这两部分一起发给大模型,让他根据片段内容来回答用户问题,到此,整个流程就结束了。是不是还是觉得有点难懂,在实际工作项目中,作为AI产品经理可以现在coze、dify这样的平台自己先搭建一个chat bot尝试一下,就能感受到了。
总结
最后我在总结一下整个流程,整个流程分为两个部分
一个是准备部分,它发生在提问前,包括分片和索引两个环节
二是回答部分,发生在提问后,包括召回、重排和生成三个环节。
由于整个流程分为两个部分,所以呢,我们的整体流程也会有两个,首先看提问前的准备部分,首先我们把相关的资料做个分片,然后把所有的片段都扔给embedding模型,让它给每个片段都产出一个对应的向量。最后我们把向量存入到向量数据库中,到这里,提问前的准备流程就结束了,这就相当于我们的知识库构建已经完毕了,就等用户来用了
本文由 @哈密(AI产品) 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


