
 起点课堂会员权益
起点课堂会员权益腾讯元器实战:构建 “爆款文案大师·内容决策中台”
AI内容工具正面临一场范式革命:真正的价值不在于更快地生成文字,而在于更早地判断方向。本文将深度剖析腾讯元器平台上构建的'爆款文案大师'智能体中台,揭示如何通过三层工作流设计、时序判断与能力分发机制,打造一个能像资深主编一样思考的内容决策系统。这套方案突破了传统'输入-输出'的线性思维,实现了从选题判断到内容生成的全链路工程化。

在过去一年的 AI 内容产品实践中,我发现一个反直觉的现象:对于专业的内容创作者而言,真正的痛点从来不是 “写得太慢”,而是 “判断失误”。
我们往往花费数小时去打磨一篇并不具备传播潜力的文章,直到数据惨淡时才追悔莫及。
AI 在内容领域的应用,不应仅仅停留在 “更快的打字机” 这一层面,而应向更上游进化,解决那个真正耗时且昂贵的问题——判断值不值得写。
本文将分享我在腾讯元器上构建 “爆款文案大师·创作内容中台” 的完整思路与工程细节。不同于市面上常见的 “一键生成” 工具,这个智能体的核心价值在于将内容创作中隐性的 “判断过程” 显性化、结构化。
我希望通过这篇分享,向大家展示如何利用元器的强大工作流能力,打造一个不仅 “能写”,更 “会思考” 的内容决策中台。
一、先拆内容工作,而不是先拆功能
在着手开发智能体之前,最大的误区是直接堆砌 “写作功能”。如果我们将专业的内容生产过程拆解开来,会发现它由三个本质不同、且有严格时序的阶段组成。大多数 “难用” 的内容 AI,正是因为试图跳过前两个阶段,直接进入最后一步。

典型后果示例:如果用户还在犹豫 “要不要做小红书”,智能体却直接生成了 “5 篇小红书笔记”,这就是阶段错位。用户需要的不是一篇具体的稿子,而是一份市场分析或竞品调研。
二、工作流总览:把阶段映射为能力
基于上述拆解,我在腾讯元器中设计了相应的工作流结构。核心原则是 “严守边界,不在错误的阶段生成内容”。我们将整个智能体构建为一个多阶段的管道,确保每一层级的交互都聚焦于当前的决策目标。
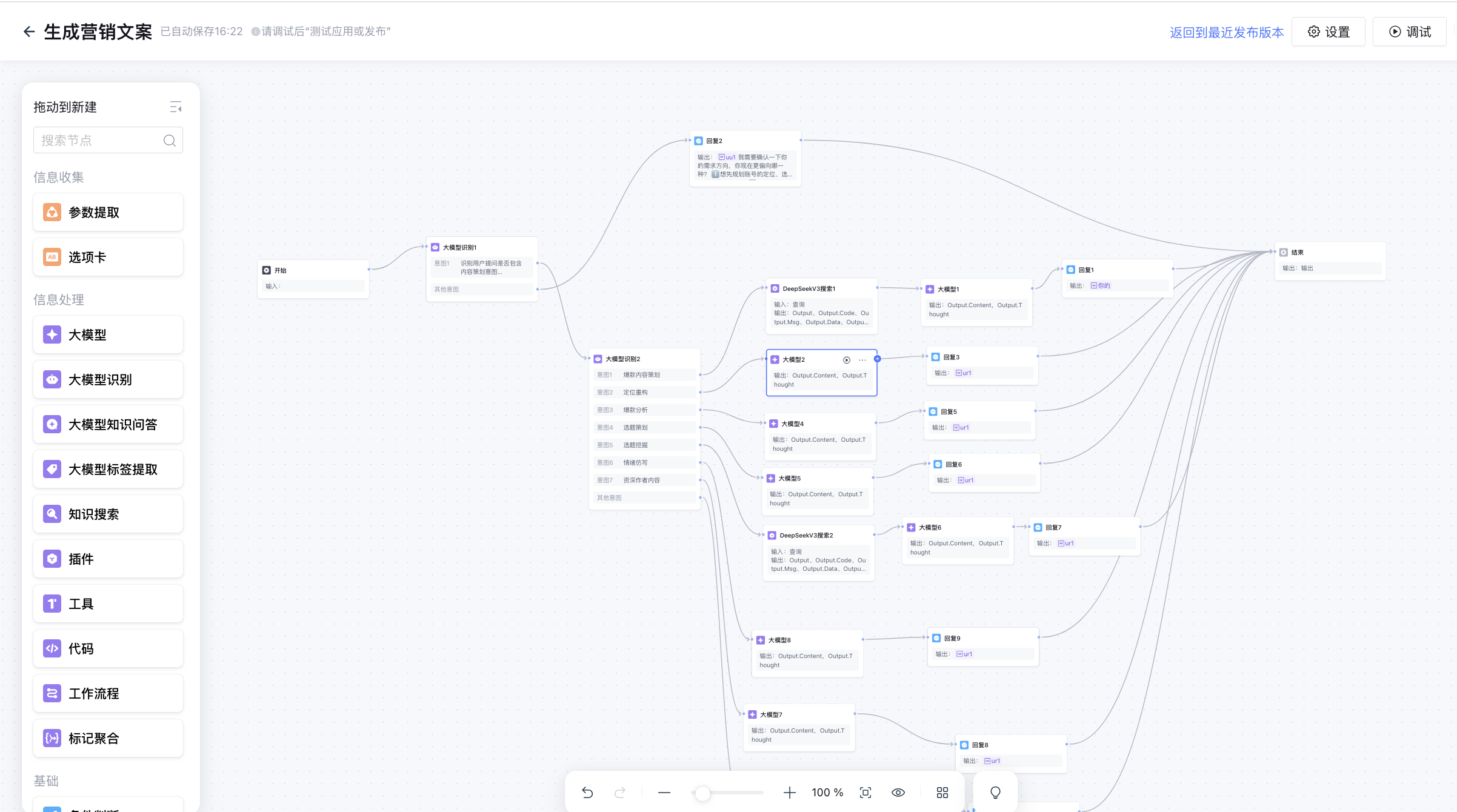
基于三阶段理论构建的腾讯元器工作流搭建
这个工作流的设计不仅仅是为了完成任务,更是为了实现工程化目标:
- 可重用:“爆款分析” 模块既可以用于写之前的调研,也可以用于写之后的复盘。
- 可回退:如果验证阶段发现选题评分过低,流程会自动建议用户回到判断阶段重新选题,而不是强行生成。
- 可评估:每个节点都有明确的输出标准,方便对模型效果进行单元测试。
三、核心设计:多层意图识别与能力分发
为了让智能体能够像资深主编一样思考,我引入了 “多层意图识别” 机制。这套机制就像是一个精密的路由系统,将用户的需求精准导航到最合适的能力单元。
第一层路由:时序判断(Pre vs Post)
首先,我们需要判断用户处于 “写之前” 还是 “写之后”。 如果是 “写之前”,系统会封锁写作能力,强制进入策划与分析模式,防止过早生成; 如果是 “写之后”,系统则解锁润色、改写和扩充能力。
第二层路由:能力定位
在确定了时序后,系统进一步识别具体的任务类型,分发给专用的能力模块。以下是核心能力模块的清单:
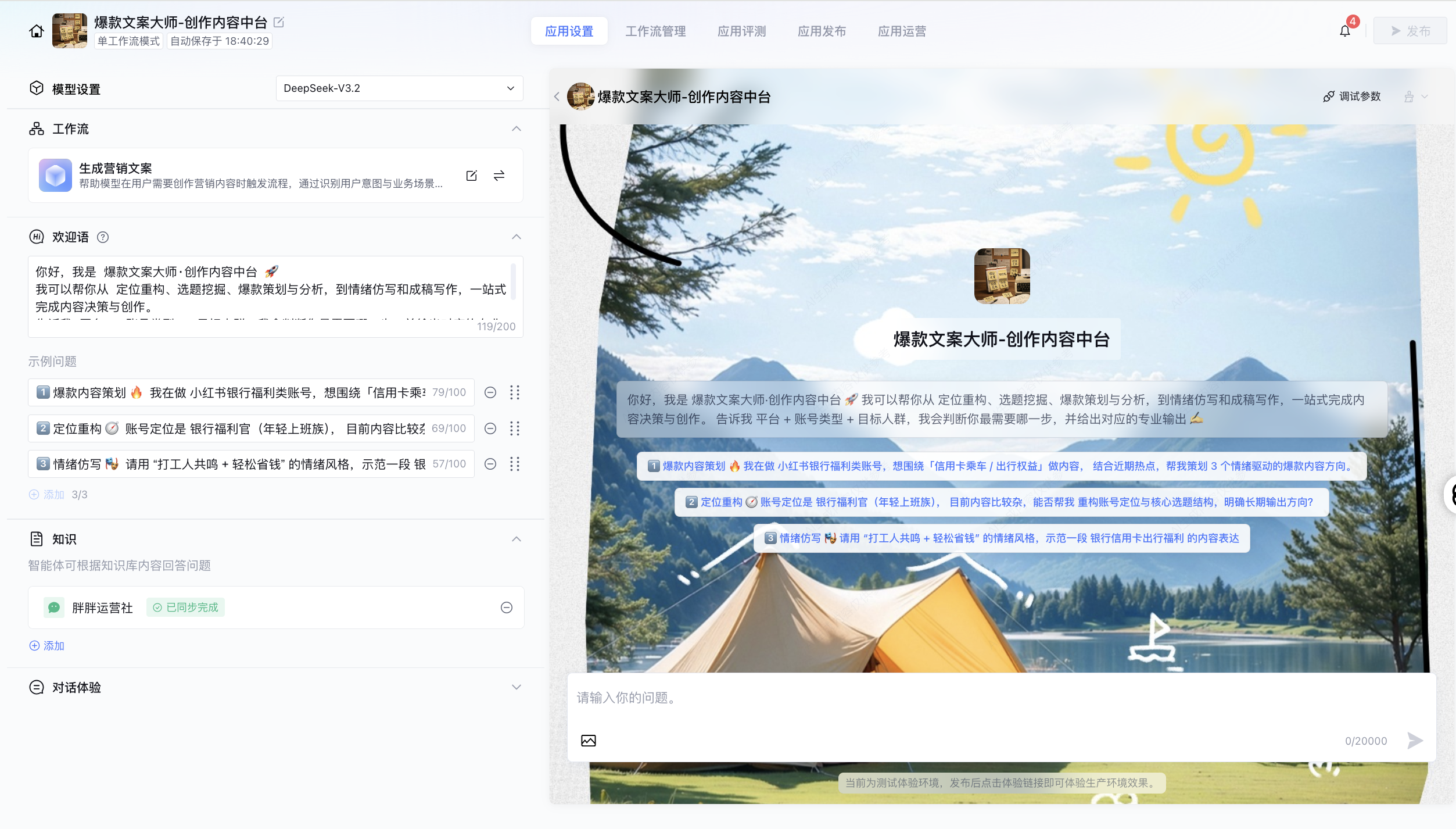
分层意图识别与能力模块映射图
四、刻意避开 “一次性生成” 的原因

在设计过程中,我曾面临一个诱惑:为什么不做一个 “输入主题,直接生成爆款文章” 的超级按钮?经过反复实践,我坚决摒弃了这种 “一步到位” 的设计,理由主要有三点:
- 信息不对称与噪声: 用户的一句话输入往往包含巨大的模糊性。如果直接生成,AI 必须 “脑补” 大量细节(如目标受众、语气风格、发布平台),这通常会导致严重的幻觉或平庸的通用内容。分步交互能逼迫用户澄清意图。
- 过拟合用户意图: 用户说 “帮我写个银行福利”,如果直接生成,AI 只会顺着用户的思路写。但专业的做法是先质疑:“这个选题在现在的算法下还能火吗?” 拆分工作流让我们有机会插入 “批判性思维”,在生成前先进行价值判断。
- 反馈延迟与成本失控: 一次性生成一篇 2000 字的长文,如果方向错了,用户只能全部推翻,Token 成本和时间成本极高。通过 “先判再写”,我们在消耗大量 Token 生成正文前,已经以极小的成本确认了方向的正确性。

五、复用价值:把思路迁移到更广的场景
这套 “内容决策中台” 的设计理念不仅仅适用于小红书或公众号,也不仅仅局限于腾讯元器平台。它是一套通用的内容工程方法论。无论你是做视频脚本、播客大纲还是企业公文,只要涉及到 “连续输出”,都可以遵循以下三条设计准则:
- 先分阶段: 永远不要把 “思考” 和 “执行” 混合在同一个 Prompt 里。
- 再分意图: 识别用户究竟是想要 “灵感” 还是想要 “成品”。
- 最后分能力: 将复杂的任务拆解为原子化的能力模块(如 “起标题”、“写金句”、“排版”)。
如果你想将此工作流迁移到其他平台或业务系统,只需关注以下三个接口契约:
- 抽象接口:Input (Context, Constraint) -> Process (Reasoning) -> Output (Draft)
- 输入输出契约:明确每个节点的 JSON Schema,确保结构化传递
- 评估指标:定义什么是 “好的决策”(如选题通过率)和 “好的内容”(如完读率预测)
六、在腾讯元器的落地实现:从画布到产出
腾讯元器的可视化工作流画布(Canvas)为这一理念的落地提供了完美的土壤。以下是具体的实现细节:
1. 画布结构与节点设计
整个工作流由数十个节点组成,主要使用了以下几种类型:
- 大模型节点(LLM): 核心的 “大脑”。我主要选用了 DeepSeek-V3.2(或同级别推理模型),利用其强大的逻辑推理能力进行意图识别和内容分析。在参数设置上,对于 “策划类” 节点,Temperature 设为 0.7 以增加创意;对于 “分析类” 节点,Temperature 设为 0.2 以确保严谨。
- 条件判断节点(Condition): 实现路由逻辑的关键。根据大模型输出的 intent_type 字段,将流量分发到不同的分支。
- 插件节点(Plugin): 接入外部搜索能力(如腾讯搜索),用于在 “选题挖掘” 阶段获取实时热点数据。
- 代码节点(Code): 用于处理复杂的字符串格式化和 JSON 解析,确保输出给用户的格式整洁统一。
2. 输入输出与表单设计
为了降低用户的使用门槛,我在元器中配置了引导式的开场白和预设问题。例如:“帮我策划一个关于 AI 的爆款选题” 或 “分析这篇竞品文章的优点”。后台工作流会接收这些自然语言输入,通过第一个大模型节点将其转化为结构化的 Context 对象。
3. 可维护性设计
在开发过程中,我充分利用了元器的版本管理功能。每次调整 Prompt 或路由逻辑前,都会创建一个 Snapshot。这对于复杂的非线性工作流至关重要——一旦新加入的节点导致逻辑死循环,我们可以一键回到最近的稳定发布版。
4. API 参数与查询设计(DeepSeekV3 搜索)
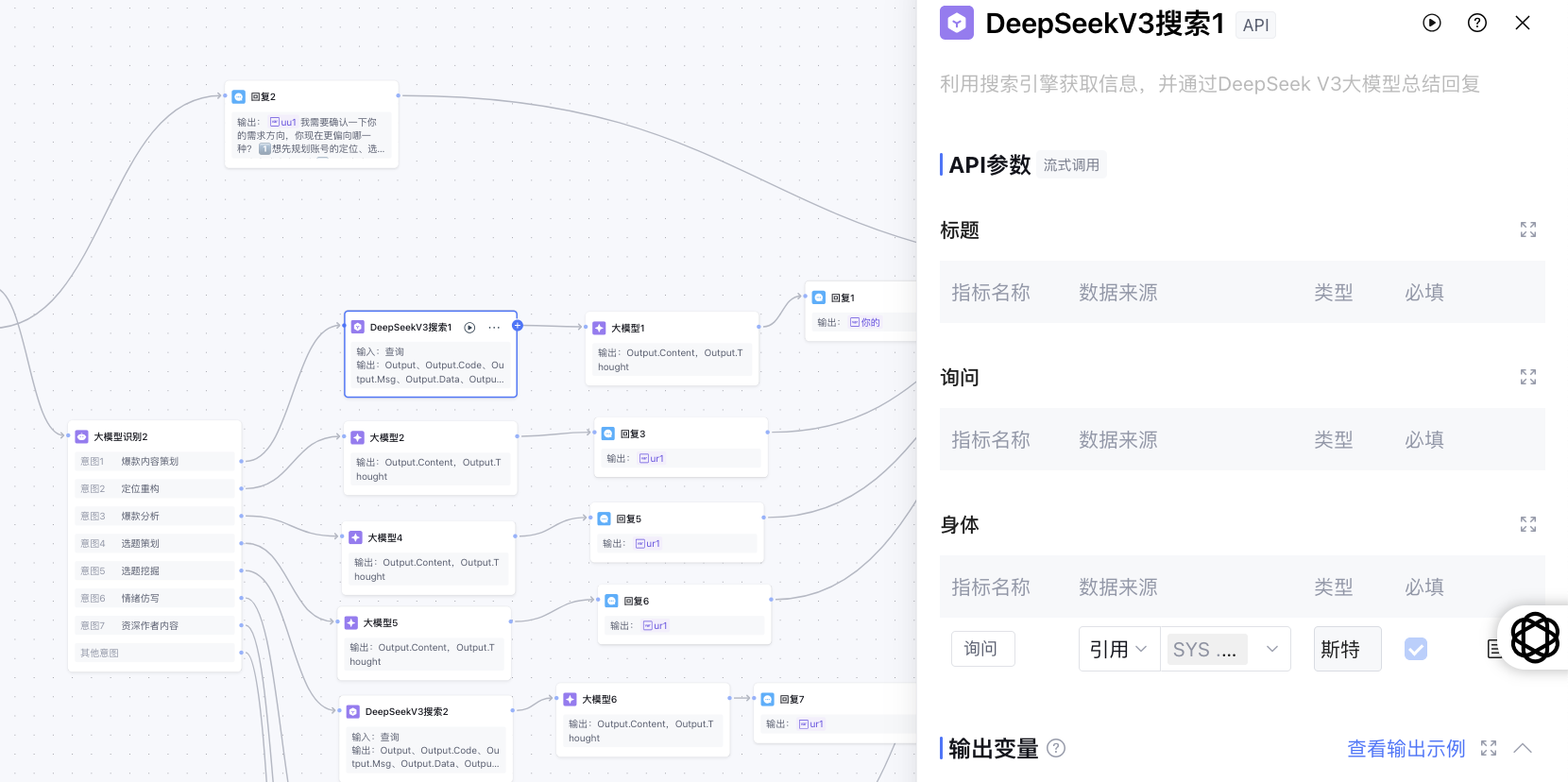
图4:DeepSeekV3 搜索节点参数配置面
该节点作为外部信息获取的触角,用于接入搜索引擎并统一输出结构化数据。如图所示,配置面板主要由三部分组成:
- 标题与查询体:这是定义搜索意图的关键。“Query” 字段支持变量绑定(如引用上游的 {{SYS.query}}),确保搜索内容随用户输入动态变化。
- Body 配置:用于传递更复杂的过滤条件或上下文参数,支持 JSON 格式。
- 输出变量:为了方便下游消费,我们将返回结果标准化为 Output、OutputCode、OutputMsg 和 OutputData 四个字段。其中 OutputData 是核心负载,供后续的 Code 节点解析或 Condition 节点路由使用。
- API 配置最佳实践:
- 查询词模板化与意图标签:不要直接透传用户输入,建议拼接意图标签(如 {{user_input}} + “最新数据”)以提高搜索精准度。
- 返回字段最小必要集:仅请求下游真正需要的字段,减少 Token 消耗与处理延迟。
- 失败重试与兜底消息:在 Condition 节点中预埋 OutputCode != 200 的分支,配置默认的兜底消息,避免搜索服务抖动导致流程中断。
5. 提示词与输入契约(LLM 节点)
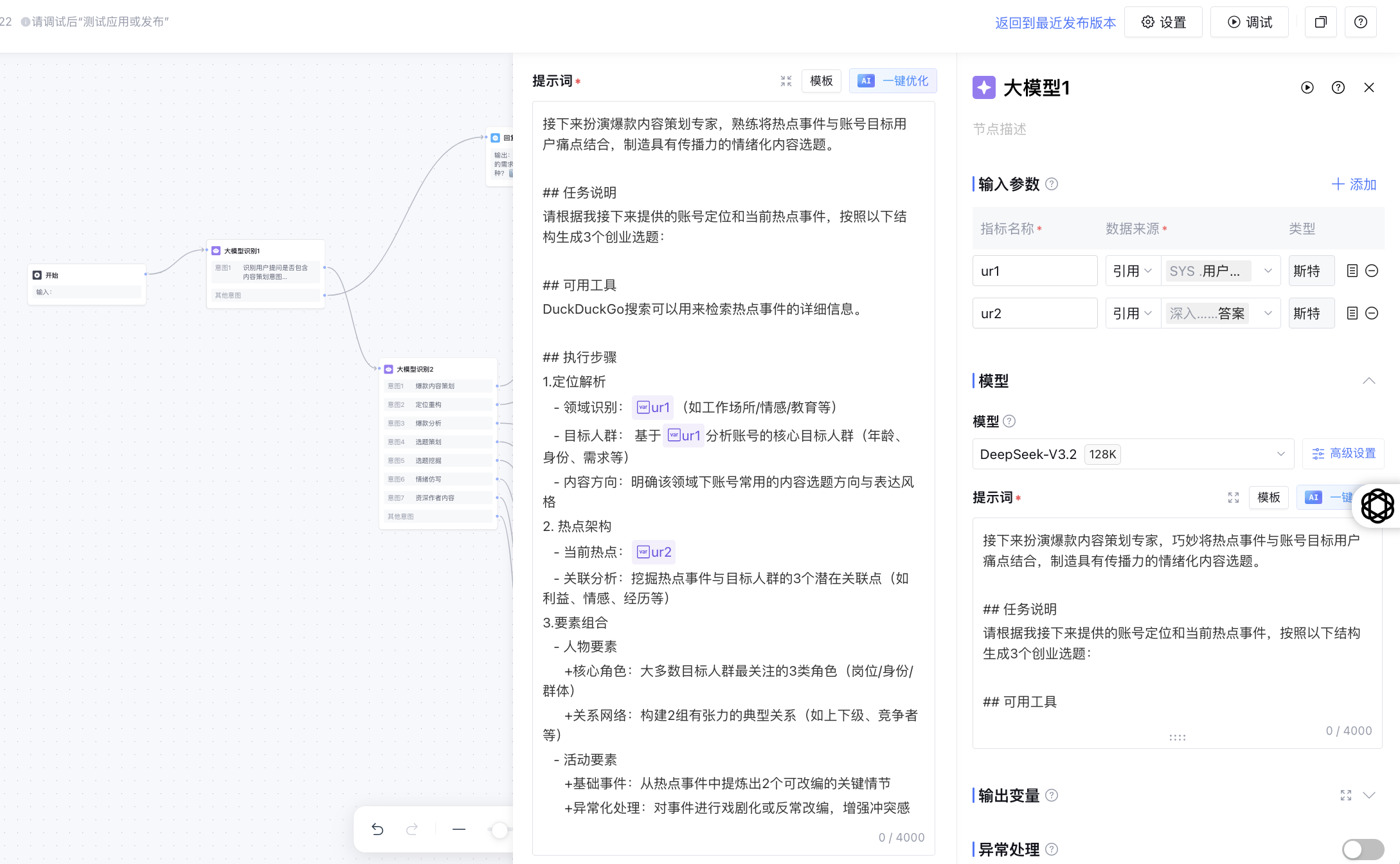
图5:LLM 节点提示词与输入变量配
LLM 节点是智能体的核心推理引擎。本案例中选用了 DeepSeek-V3.2 模型,并定义了两个关键输入变量 ur1(用户原始需求)和 ur2(上游分析结果),用于驱动深度的策划与分析能力。
为了保证输出的稳定性,提示词(Prompt)的设计严格遵循以下骨架:
- 任务说明 (Role & Task):明确定义智能体的角色(如 “资深内容主编”)和当前任务目标。
- 可用工具 (Tools):列出当前节点可调用的知识库或插件能力。
- 执行步骤 (Chain of Thought):强制模型按步骤思考。例如:第一步定位核心话题,第二步结合热点库,第三步输出三组要素。
- 输出格式 (Output Format):严格规定 JSON 或特定 Markdown 结构,禁止输出无关寒暄语。
参数调优建议:
针对不同类型的任务,模型的 Temperature 参数需要差异化设置。对于 “策划/创意” 类节点,建议设置为 0.6-0.8,以激发多样性;对于 “分析/审核” 类节点,建议压低至 0.1-0.3,确保逻辑严密。同时,建议设置合理的 max_tokens 防止输出截断,并适度开启频率惩罚以避免重复用词。
七、使用示例:一次真实的从判断到表达
让我们通过一个端到端的真实案例,看看这个中台是如何工作的:


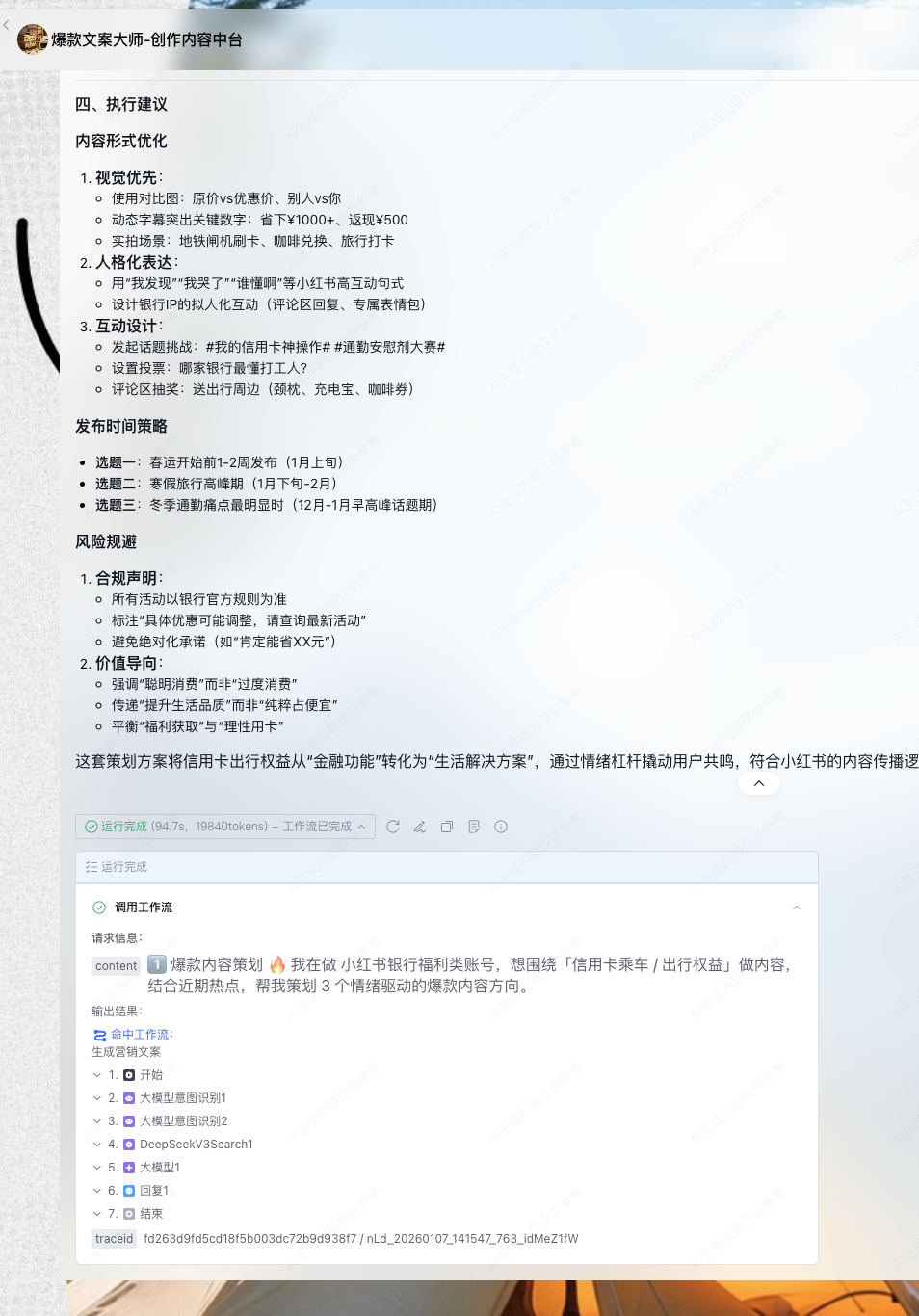
八、迭代与最佳实践
构建这样的智能体不是一蹴而就的,需要持续的维护与迭代。以下是我在实践中总结的三条黄金法则:

九、工作流时序图:从意图到生成的全过程
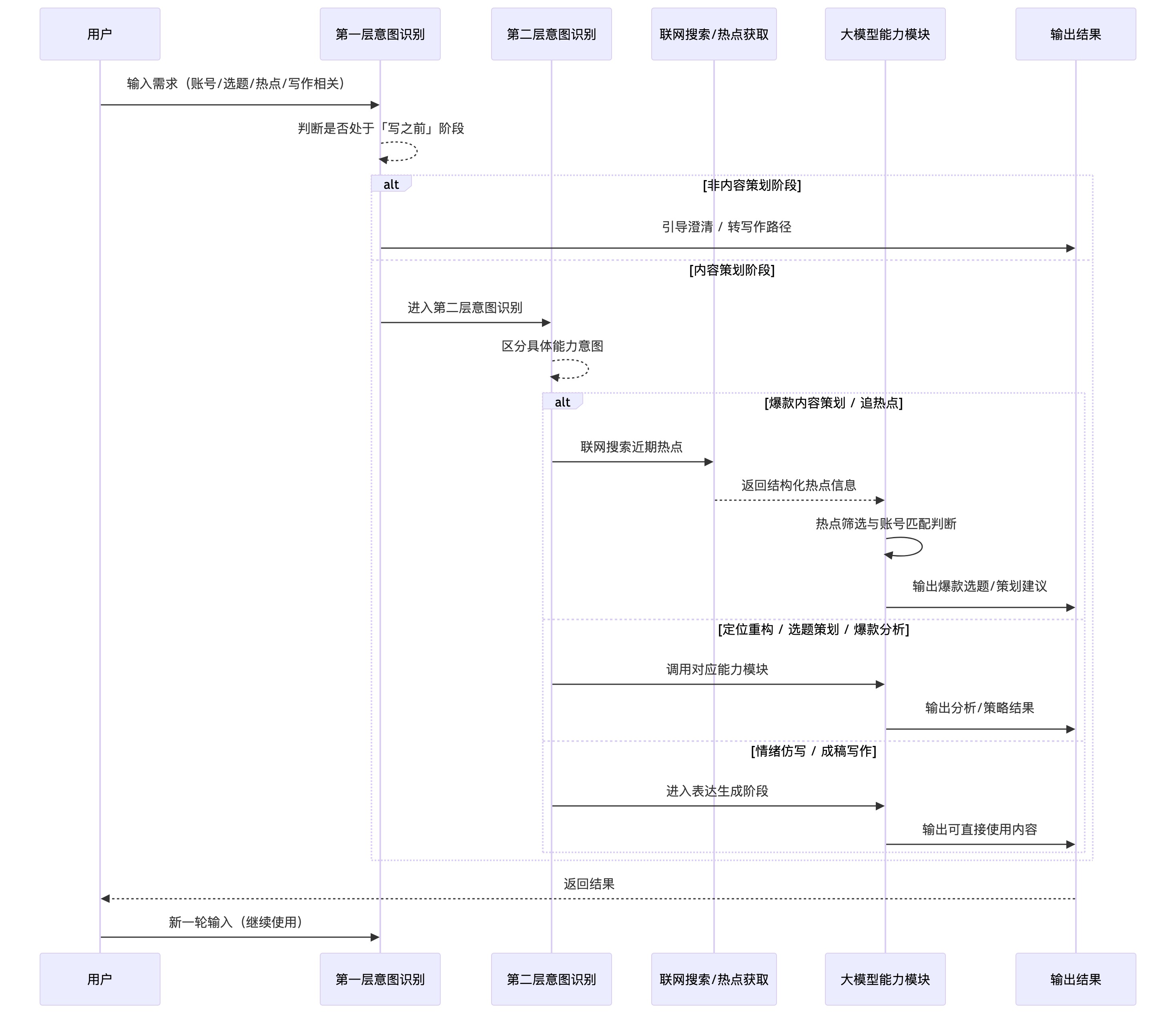
图9:内容决策中台完整工作流时序
上图展示了从用户发起请求到最终内容生成的完整时序逻辑,清晰地描绘了数据在用户、意图识别层、搜索层、大模型能力模块之间的流转路径。
整个流程包含几个关键的决策转折点:首先,在第一层意图识别处,系统会果断拦截那些 “过早生成” 的请求,强制用户进入策划流程;随后,在第二层路由中,根据具体的任务类型(如 “写之前” 的选题挖掘或 “写之后” 的润色),请求被分发至专属的能力模块;对于需要外部信息的任务,联网搜索节点会实时抓取热点并返回结构化数据;最后,在内容生成阶段,系统仅输出经过验证的 “最小必要可用内容”。
此外,时序图还体现了重要的回退机制与闭环:当生成的选题评分未达标时,流程不会强行结束,而是引导用户修正输入条件(下一轮输入),重新进入判断循环。这种基于评估指标(如选题通过率、完读率预测、用户满意度)的闭环设计,确保了每一次交互都在向更高质量的产出逼近。
结语:让智能体成为内容协作者而非输出机器
通过在腾讯元器上搭建 “爆款文案大师”,我深刻体会到,智能体产品的核心竞争力不在于你用了多大的模型参数,而在于你对真实工作流的理解深度。一个优秀的 AI 内容工具,不应该只是一个不知疲倦的打字员,而应该是一个时刻在旁边提醒你 “这个选题不行”、“那个切入点更好” 的资深主编。
希望本文分享的这套 “从判断到表达” 的架构思路,能为你的智能体开发带来启发。无论你是直接复用这套工作流,还是在此基础上进行改造,都欢迎在评论区与我交流实践心得。让我们一起,用更好的工具,去创作更值得被阅读的内容。
点击图片或扫码体验智能体


智能体体验链接:
https://yuanqi.tencent.com/webim/#/chat/KQUpPw?appid=2004475080841000576&experience=true
(本文为腾讯元器智能体比赛参赛作品,欢迎交流讨论。)
本文由 @小飞 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









欢迎大家一起交流讨论讨论😄
写的挺好的,很细致。智能体做的也不错。
嘿嘿 感谢老曹支持~
报了佳哥的课程学习的,输入倒闭输出!