
 起点课堂会员权益
起点课堂会员权益AI技术核心通识:机器学习、深度学习与大模型的底层逻辑(通俗版)
AI产品经理的技术通识课来了!机器学习、深度学习、大模型三大核心技术的关系与差异,往往让非技术背景的产品人望而生畏。本文用通俗类比+产品视角,帮你拆解技术底层逻辑,掌握与算法团队高效协作的关键,避免陷入‘技术黑箱’的困境。

在上一篇文章中,我们整理了AI产品经理的入门工具包,帮大家搭建了学习资源体系。从这一篇开始,我们正式进入“技术通识篇”——对于AI产品经理来说,懂技术不是为了写代码、调模型,而是为了理解技术边界、打通与算法团队的协作壁垒,避免提出“技术无法实现”的需求,也能精准判断“哪些需求值得用AI解决”。
提到AI技术,很多人会被“机器学习”“深度学习”“大模型”这些术语劝退,觉得背后是复杂的数学公式和算法原理。但实际上,我们只需抓住核心逻辑,用“通俗类比+产品视角”就能看懂。今天这篇文章,就带大家拆解这三大核心技术的底层逻辑,搞懂它们之间的关系、差异,以及对AI产品设计的影响。
一、先理清关系:从机器学习到大模型的演进逻辑
机器学习、深度学习、大模型不是孤立的技术,而是“包含与演进”的关系——深度学习是机器学习的一个分支,大模型是深度学习在“海量数据+强大算力”支撑下的进阶形态。我们可以用一张简单的流程图,看清它们的演进脉络:
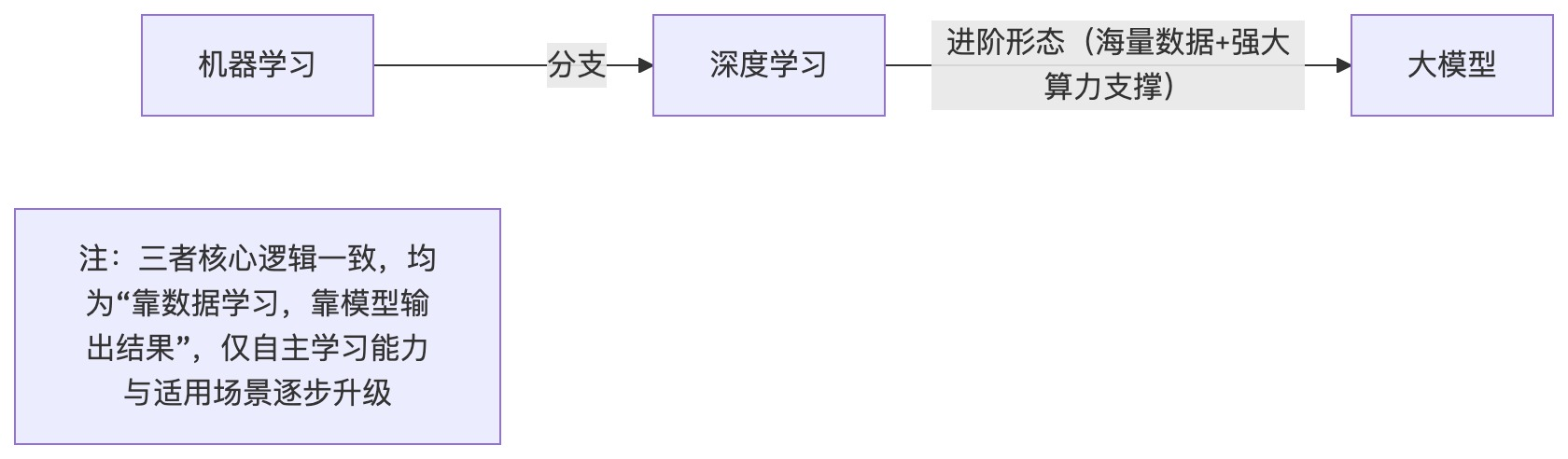
通俗来说,这三者的演进,本质是“机器自主学习能力的升级”:从“需要人帮着找规律”的机器学习,到“能自己提炼规律”的深度学习,再到“能理解、生成、推理的”大模型,机器越来越接近“类人智能”,但核心逻辑始终没变——靠数据学习,靠模型输出结果。
二、逐一看透:三大技术的底层逻辑(通俗类比版)
我们不用纠结数学原理,而是用“教机器做事”的类比,拆解每类技术的核心逻辑、特点,以及AI产品经理需要关注的重点。
1. 机器学习:教机器“从案例中找规律”
核心逻辑:就像教一个刚接触新领域的实习生做事——你不用告诉他所有规则,而是给他一堆“案例”,让他自己从案例中总结规律,再用规律处理新任务。
举个例子:想让机器识别“猫和狗”(分类任务),用机器学习的思路就是:给机器投喂成千上万张标注好“这是猫”“这是狗”的图片(案例),机器会自己总结规律(比如猫有尖耳朵、狗有耷拉耳朵,猫的脸型更圆、狗的脸型更长),之后再给一张新图片,机器就能根据总结的规律,判断这是猫还是狗。
从产品视角,我们需要关注这3个关键点:
- 依赖“人工特征工程”:在投喂案例前,人需要先帮机器“筛选关键信息”(比如识别猫和狗时,告诉机器重点关注耳朵形状、脸型),这一步叫“特征工程”。如果特征选得不好,机器学不到准确的规律,结果准确率就低——这也是机器学习的局限性,需要人大量介入。
- 适用于“单一场景”:一个训练好的“猫犬识别模型”,只能用来识别猫和狗,无法识别汽车、飞机,也无法回答用户的问题——场景通用性差,这也是早期AI产品“场景碎片化”的原因。
- 数据需求适中:不需要海量数据,通常几千、几万条标注数据就能训练出效果不错的模型,成本相对较低,适合早期AI产品落地。
2. 深度学习:教机器“自己提炼规律”
核心逻辑:相当于给实习生升级了“自主思考能力”——你不用再帮他筛选关键信息,直接给他一堆案例,他能自己一层层拆解、提炼核心特征,总结出更精准的规律。
还是以“猫犬识别”为例,用深度学习的思路:直接给机器投喂海量猫、狗图片,机器会自己拆解特征——第一层先识别“像素点分布”,第二层识别“线条、轮廓”,第三层识别“耳朵、眼睛、脸型”,最后汇总这些特征,判断图片中的动物是猫还是狗。整个过程中,人不需要介入“特征筛选”,机器自主完成。
深度学习的核心是“神经网络”,我们可以把它类比成“多层解题小组”:每一层小组负责处理一个层面的信息,层层递进,最终输出结果。层数越多、结构越复杂,机器提炼特征的能力就越强。
从产品视角,重点关注这3点:
- 无需人工特征工程:机器自主提炼特征,解决了机器学习“人要介入筛选特征”的痛点,能处理更复杂的场景(比如图像识别、语音识别)——这也是深度学习能推动AI普及的核心原因。
- 依赖“数据量+算力”:深度学习需要海量数据(几十万、几百万条)和强大的算力支撑,才能训练出精准的模型,成本比机器学习高——这也是早期深度学习产品多由大厂主导的原因。
- 场景适用性提升:虽然仍以“单一任务”为主(比如语音识别模型、图像分类模型),但处理复杂任务的能力更强,比如能识别不同角度、不同光线条件下的猫和狗。
3. 大模型:教机器“理解、生成与推理”
核心逻辑:相当于把实习生培养成了“超级学霸”——他不仅能从海量案例中提炼规律,还能理解语言、生成内容、进行逻辑推理,甚至跨场景处理任务,接近“类人智能”。
大模型的核心是“Transformer架构”(可以理解为“更高效的神经网络”),再加上“海量无标注数据+超强算力”的支撑。比如ChatGPT、文心一言这类大语言模型,训练数据涵盖书籍、网页、文章等海量文本,机器从这些数据中学习语言逻辑、知识体系,最终能实现“对话、文案生成、逻辑推理、翻译”等多种任务。
和机器学习、深度学习相比,大模型最大的突破是“通用性”——一个大模型能适配多个场景,不用针对每个场景单独训练模型。比如ChatGPT既能帮你写文案,也能回答知识问题,还能做翻译、编代码,这是之前的AI技术无法实现的。
从产品视角,重点关注这3点:
- 强通用性+多任务能力:打破了“一个模型对应一个场景”的局限,让AI产品能覆盖更多需求(比如大模型驱动的AI助手,既能做客服,也能做内容生成),降低了AI产品的落地成本。
- 存在“幻觉问题”:大模型的输出是“概率性生成”,不是100%准确,可能会编造不存在的信息(比如虚假知识点、错误数据)——这是AI产品设计中必须规避的风险,需要做容错机制(比如信息校验、人工审核)。
- 可微调适配垂直场景:通用大模型虽然能处理多任务,但在垂直领域(如医疗、金融)的准确率不足,需要通过“微调”(用垂直领域的数据训练通用大模型)适配场景——这也是大模型产品落地的核心方向之一。
三、核心差异对比:一张表格分清三者
为了让大家更清晰地对比三者的差异,我们从“核心逻辑、数据需求、场景适配、产品关注点”四个维度整理成表格,方便快速查阅:
四、产品视角的核心启示:懂技术,是为了更好地做产品
了解这三大技术的底层逻辑,不是为了成为算法专家,而是为了在产品设计、需求沟通、方案选型中做出更精准的决策。总结3个对AI产品经理最实用的启示:
- 需求决策:根据场景选技术:如果是简单场景、数据量少,用机器学习即可,成本低、落地快;如果是复杂单一场景(如图像、语音),用深度学习更合适;如果是多任务、通用型场景(如AI助手、内容生成),优先考虑大模型。避免“为了用大模型而用大模型”,造成成本浪费。
- 协作沟通:用“通俗语言”对齐需求:和算法团队沟通时,不用讲复杂术语,而是明确“需求目标+数据条件+效果预期”。比如“我们要做一个猫犬识别功能,现有1万张标注图片,希望准确率达到90%,用于宠物APP的图片分类”,算法团队会根据这些信息,判断用机器学习还是深度学习,以及如何设计方案。
- 风险控制:提前预判技术局限:知道机器学习依赖人工特征,就会提前预留“特征优化”的迭代空间;知道深度学习依赖数据量,就会提前规划数据采集方案;知道大模型有幻觉问题,就会在产品中设计“信息校验”“人工介入”的容错机制,避免用户受到错误信息影响。
五、总结:技术通识的核心是“懂边界、会协作”
对于AI产品经理来说,机器学习、深度学习、大模型的底层逻辑,核心就在于“机器如何从数据中学习”——从需要人辅助的机器学习,到自主学习的深度学习,再到通用智能的大模型,技术的演进本质是“降低人的介入成本,提升机器的自主能力”。
我们不用纠结于数学原理和算法细节,只需抓住“数据需求、场景适配、技术局限”这三个核心,就能在产品工作中精准决策、高效协作。下一篇文章,我们将拆解AI产品的完整技术链路——从数据到模型,再到部署迭代,帮你看清AI产品落地的全流程技术环节。
感谢读到最后!喜欢的话点个赞,认可的话赏个小红包,你的每一份支持,都能让我更有动力更新更多优质内容~
本文由 @why 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


