
 起点课堂会员权益
起点课堂会员权益PixVerse R1 世界模型,以及它的原理
PixVerse R1世界模型实现了真正的『言出法随』,用户指令可实时改变1080P视频流内容。其Omni多模态基座将文本、图像、视频统一编码为连续token流,配合Memory模块的自回归生成与IRE引擎的1-4步极速采样,突破了传统扩散模型的延迟瓶颈。本文深度解析视频路线与3D重建路线的技术差异,并探讨世界模型从模式匹配到物理规律理解的本质跨越。

PixVerse 发布了一个新东西,感觉…这是一场无限月读的梦境
画面持续生成,输入的指令可以即时改变画面内容
官方技术报告的说法是:无限、连续的视觉流式传输
分辨率最高 1080P,响应延迟秒级(现在的 Demo 只是 720P,算力实在有限)
下面这个,是官方宣传片,文末还有更多试玩录屏:
世界模型到底在说什么
在世界模型这块,老实说我只能算个门外汉,看到这个 PixVerse 的发布之后,我赶忙的去查看了相关的技术报告,以及询问各种行业专家,以求给大家带来更准确的描述
恰好的,昨天 Luma AI 的模型产品负责人来到 AGI Bar,我们聊了一会儿,他平时在湾区,对技术细节比较了解,前段时间刚融了 9 个亿的美金,做世界模型
这就很…及时了,我们聊了半个多小时的模型发展,也包括现在各家的进展,再结合我之前学习的各类报告,有了这篇文章
对于世界模型,杨立昆有个说法,大意是:
给定一个现在的物理世界的状态,比如这个杯子停在桌子边缘。再给定一个事件,比如:我把杯子推下去,会怎样对于人类的我们,可以想象:塑料杯的话,会弹起来;玻璃杯,则会摔碎
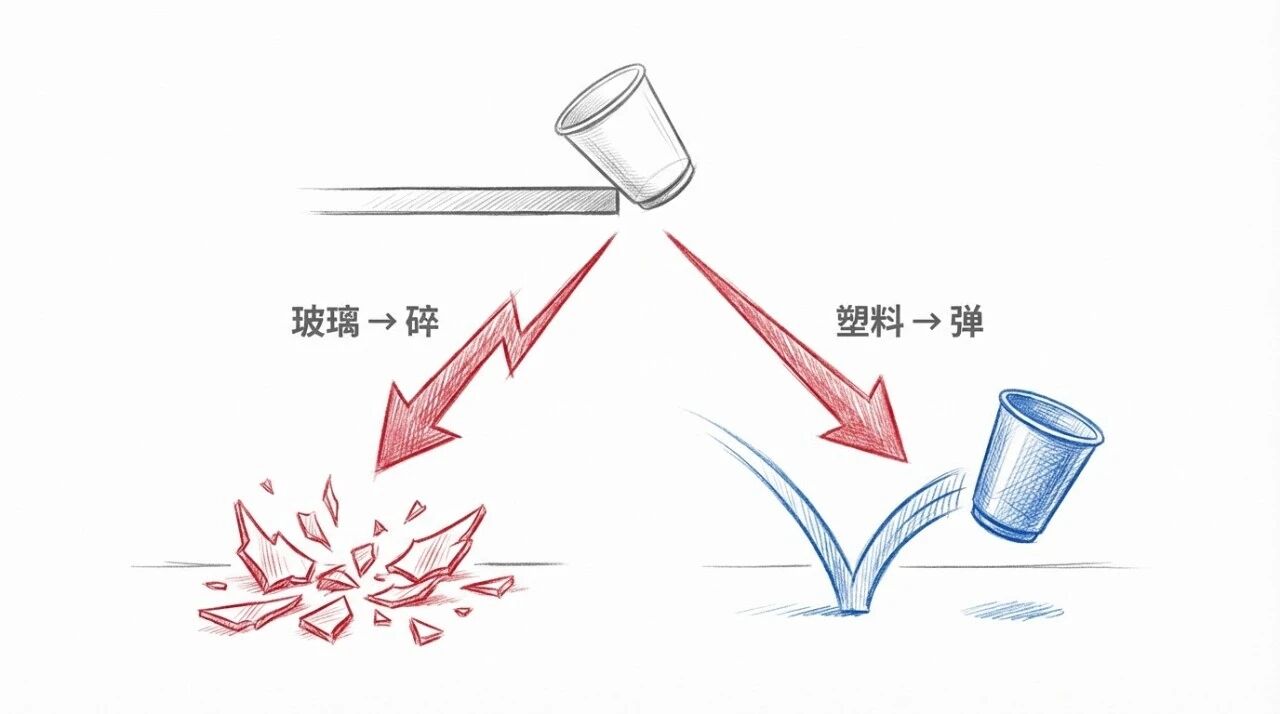
不得不说,人脑真的很厉害
现在的模型怎么知道这些?它得看过塑料杯摔在地上,看过玻璃杯摔在地上,看过各种杯子摔在地上的视频
但如果我能通过语言模型的知识,知道这是玻璃杯还是塑料杯,知道玻璃落地会碎、塑料落地会保持完整,然后根据这个推断去生成视频,那就不一样了
这个「杯子理论」,核心要表达的是:模型到底是在做模式匹配,还是真的理解了物理规律
两条技术路线
现在做世界模型的团队,技术路线上分成两派:视频路线和3D 重建路线
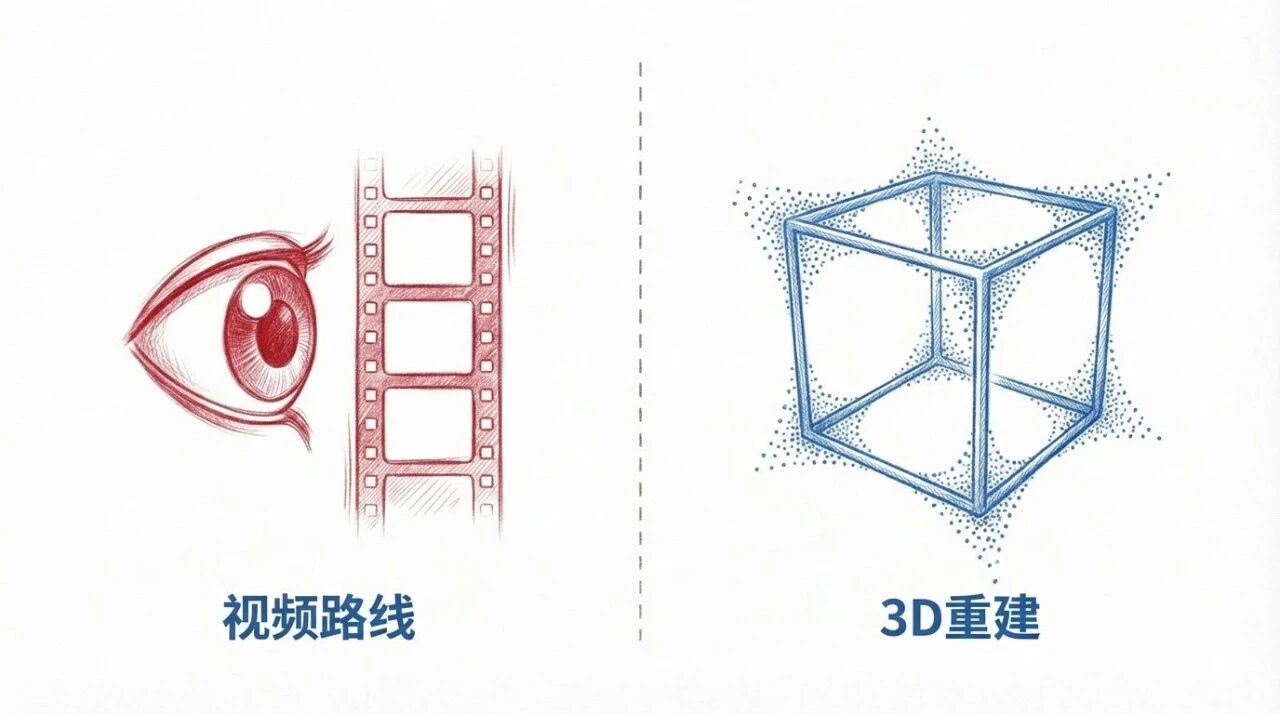
视频路线 vs 3D重建
视频路线
Genie 3、PixVerse R1、Luma 走的都是这条路核心思路是:通过足够多的视频信息,去理解 3D 的构成
比如怎么知道一个物体从正面看是什么样、从侧面看是什么样、从上面看是什么样。模型从大量视频中学习这些视角关系
讲道理,我觉得人脑是这么学习的
3D 重建
李飞飞的 World Labs 走的是另一条路用 Gaussian Splatting 把 3D 世界重建出来,人在里面走动,场景产生变化,这个有点像小扎之前提到的元宇宙
他们是直接用 Gaussian Splatting,把 3D 的世界给重建出来了。然后人在里面走,产生交互或者动作,去模拟出来
两条路线,各有侧重(只是目前来说)
3D 重建:空间一致性更强、可以导出资产视频路线:生成速度快、可以做实时交互;
PixVerse R1 的技术架构
伴随 PixVerse R1 发布的,还有一份技术报告,有兴趣的可以读一下

https://pixverse.ai/en/blog/pixverse-r1-next-generation-real-time-world-model
根据这份报告,PixVerse R1 由三个模块支撑:Omni、Memory 和 IRE
Omni:原生多模态基座
端到端的多模态模型,文本、图像、视频、音频被统一编码成连续 token 流
「原生」的含义是:多模态融合发生在模型底层,而非通过外挂编码器拼接。减少模态之间的接口误差
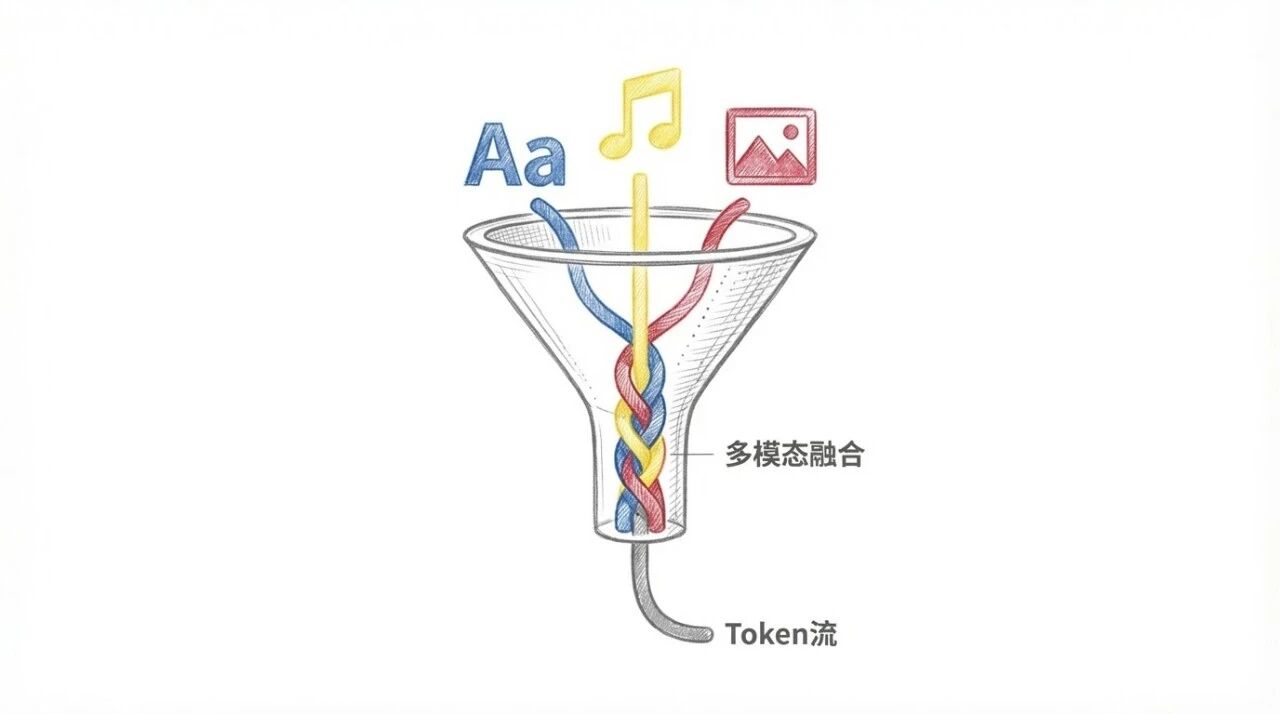
基座模型在大规模真实世界视频上训练,学习场景演化的规律
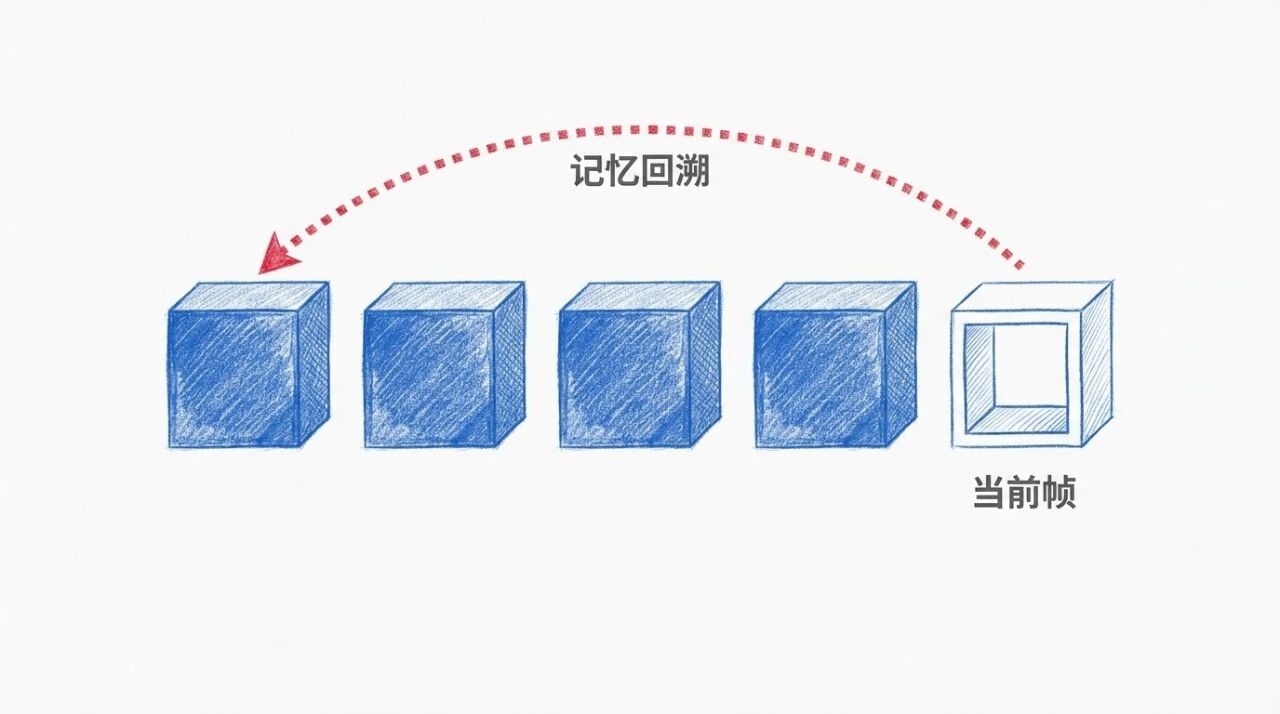
Memory:自回归流式生成
扩散模型生成固定长度片段,PixVerse R1 用自回归机制,逐帧预测,理论上无长度限制
自回归的经典问题是误差累积。PixVerse R1 加了记忆增强注意力机制:当前帧生成时,会参考前序帧的隐状态表示,维持长程一致性
聊到这里,朋友提了一个有意思的点:
自回归的图片模型从去年开始有了,Grok、GPT-4o Image、Gemini 的图片生成,基本上都是自回归加 Diffusion 的某种 Fusion 架构
图片模型上能看到对文字、对物理规律有更好的呈现
那大家猜测,用同样的架构在视频上实现,可能也能更好的理解物理世界规律
但自回归的视频模型,真的很难
国内最早探索这个方向,并产出成果的,应该是 Sand AI,曹越他们
Magi-1 开源&刷屏:首个高质量自回归视频模型,它的一切信息
PixVerse R1 的这次尝试,则是把这个东西,推向了一个新的高度
IRE:实时响应引擎
实现「实时」的关键模块
扩散模型通常需要几十步去噪迭代,延迟高。PixVerse R1 把采样步数压到 1 到 4 步

这里有三个技术点:
Direct Transport Mapping
网络直接预测目标分布,跳过逐步去噪
引导蒸馏
把 Classifier-Free Guidance 的条件梯度合并进学生模型,省掉推理时的额外计算
稀疏注意力
减少长序列依赖的冗余计算
产业背景
世界模型这个词,最早进入大众视野可能要追溯到 Sora

标题:视频生成模型,也是世界模拟器
Sora 的时候大家都觉得这是一个视频模型。但 OpenAI 当时说的是 World Model
他们当时说的 World Model,是指在视频的基础上,模型能够符合我们对于一个视频的正常预期。比如鸟飞是什么样的,原来的 Diffusion 模型很多东西跑起来不太符合客观规律。Sora 把这个事情做了
现在各家的布局:
Google Genie 3(2025年8月) 720p 分辨率,24fps 帧率,持续交互可达数分钟。还是基于 DiT 架构,做了一些改进
World Labs Marble(2025年11月) 李飞飞创立,首轮融资 2.3 亿美元。生成持久化、可下载的 3D 环境,支持导出 Gaussian Splats 和 Mesh 格式
NVIDIA Cosmos(2025年1月) 物理 AI 基础设施平台,已被下载超 200 万次。定位是服务自动驾驶和机器人训练
Runway GWM-1(2025年12月) 分化为三条产品线:交互式探索、机器人合成数据、人类行为模拟
PixVerse R1 刚刚发布,聚焦实时响应。公司2025年9月获得阿里巴巴领投的 6000 万美元融资,年化经常性收入约 4000 万美元
局限性
技术报告里提到两个约束:
误差累积 长时间生成后,早期的小误差可能逐步放大
物理精度与速度的权衡 为了实现实时,物理细节的渲染精度有所妥协
目前单次会话限时 5 分钟,算力消耗较大
还有一个更根本的问题,字节 Seed 团队 2024年11月的研究(ICML 2025 发表)指出:视频生成模型在分布外泛化上表现不好,缩放模型规模也没用。核心问题是模型可能并没有真正学会物理规则,只是在做模式匹配
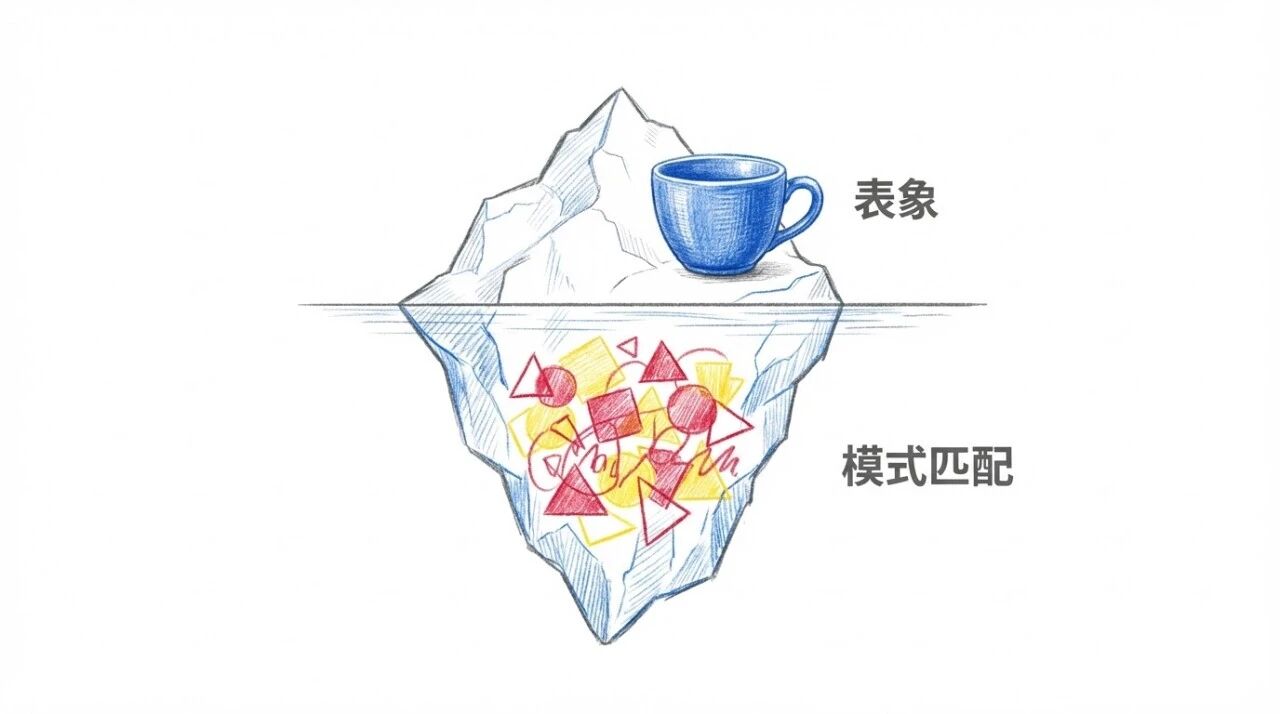
这也是杯子理论指向的问题:看过足够多杯子摔碎的视频,和真正理解「玻璃落地会碎」,可能是两回事
本文由人人都是产品经理作者【赛博禅心】,微信公众号:【赛博禅心】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


