
 起点课堂会员权益
起点课堂会员权益DeepSeek 又改了”常识”:这次他们教 AI 像人一样”看书”
DeepSeek最新论文《DeepSeek-OCR 2: Visual Causal Flow》颠覆了OCR领域十年的CLIP统治,提出了一种全新的视觉因果流处理机制。该技术不仅将阅读顺序准确率提升了33%,更揭示了通向原生多模态的未来路径——让AI学会像人类一样‘跳读’文档。

我们读文档的时候,眼睛根本不是从左上扫到右下的。
我个人阅读文档的时候,先是快速扫了一下标题和作者,知道这是篇什么主题的论文。然后看摘要,抓主要结论。发现有张图表,就直接跳到图表看关键数据。最后才回到正文,按自己的逻辑顺序补充细节。
这个过程,大概花了 30 秒。但 AI 呢?它可能还在从第一个字慢慢往后扫。
人类有”阅读逻辑”,AI 之前没有。
被CLIP统治的十年
DeepSeek 今天发布了新论文《DeepSeek-OCR 2: Visual Causal Flow》,直指一个根本性问题。
论文链接:
Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
这篇论文的核心,其实是在质疑一个统治了 OCR 领域十年的”默认真理”——CLIP 架构。
2015 年 CLIP 问世,到现在已经十年了。这十年里,几乎所有视觉语言模型(VLM)都在用同一个假设:图像按从左上到右下的固定顺序处理。简单场景(比如单张照片、清晰扫描件)没问题,这个假设够用。
但复杂文档就崩了。
为什么崩了
为什么崩了?我来举个例子。
看一个带表格的文档。人类怎么读?先看表头,知道每列是什么。然后横向看第一行数据,读完回到表头,确认列名,再看第二行。如果有多列交叉,可能会先看完所有行的某一列,再跳到下一列。
但 CLIP 怎么处理?它假设顺序是固定的——从表格的第一个格子(通常是左上角)扫到最后一个格子(右下角)。这意味着什么?意味着它可能会读到第一行的第 5 列,然后突然跳到第二行的第 1 列,因为它们在物理位置上是相邻的。
语义顺序完全乱了。
表格还只是简单场景。公式呢?多栏布局的报纸呢?学术论文里的图表引用呢?这些都需要”按语义跳跃”,而不是”按位置扫描”。
CLIP 的固定顺序在干一件低效事——用线性序列去表达二维逻辑。
DeepSeek 的解法:弃用 CLIP,换上 LLM 式编码器
DeepSeek 直接把用了十年的 CLIP 编码器弃用了,换成了一个轻量级的 LLM——Qwen2-0.5B。
为什么要用 LLM?因为 LLM 天生支持”因果注意力”(Causal Attention),也就是从左到右的自回归生成。而 CLIP 用的是”双向注意力”,它能看到所有 token,但没有”顺序”的概念。
但 DeepSeek 没有完全放弃双向注意力,而是设计了一个”双流注意力”机制:
视觉 token 部分:保留双向注意力,用来全局感知图像内容(这是什么东西)
因果流 token 部分:使用因果注意力,用来决定”应该按什么顺序读”(怎么读)
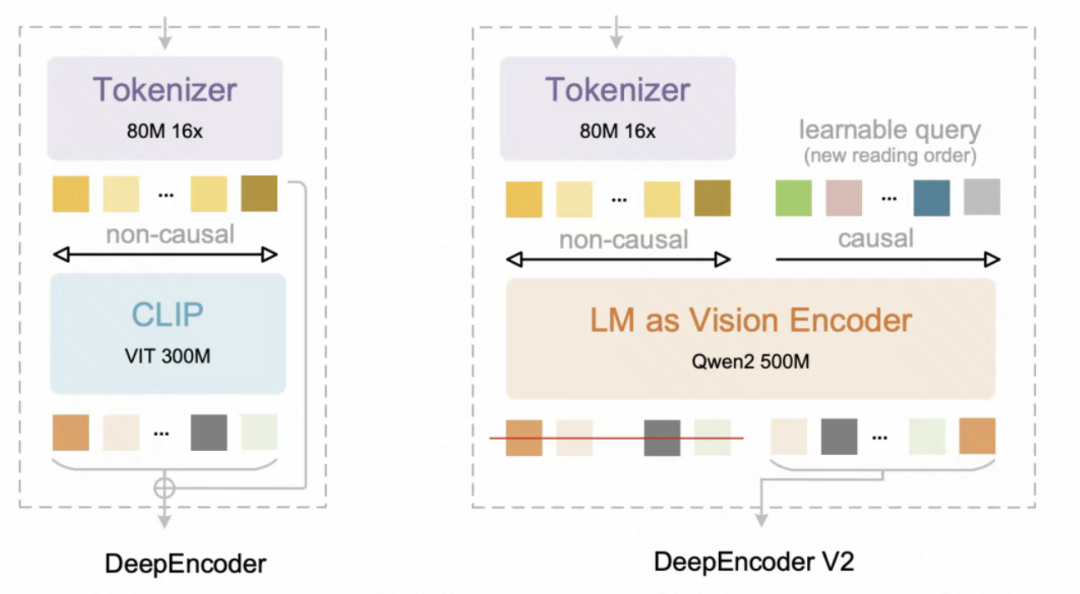
(deepencoder架构图)
具体怎么工作呢?
首先,图像经过 SAM-base 和压缩器,变成一组视觉 token。这些 token 通过双向注意力进行全局感知——就像你拿到一张文档,先”扫一眼”知道大概内容。
然后,DeepSeek 引入了一组”因果流查询”(Causal Flow Queries),这些查询 token 可以关注所有视觉 token,但只能关注之前的查询 token。每个查询 token 会根据自己的理解,”挑选”它认为应该下一个读取的视觉 token。
这就像你在读文档时的内心活动——”刚刚读了标题,现在应该去看摘要”、”看完摘要了,图表好像更有用,先看图表”。
最终,只有因果流 token 的输出会被送入解码器,生成最终的文本。这相当于编码器先帮你”排好阅读顺序”,解码器只需要按顺序执行就行了。
DeepSeek 把这个过程称为”两级级联因果推理”:
第一级:编码器内部通过因果查询对视觉 token 进行语义重排
第二级:LLM 解码器在有序序列上执行自回归推理
效果验证:91.09% 得分,阅读顺序提升 33%
DeepSeek 在 OmniDocBench v1.5 基准上做了测试。这个基准包含 1355 页文档,覆盖中英文的 9 大类别(杂志、学术论文、研究报告等),是当前最严格的文档理解评测之一。
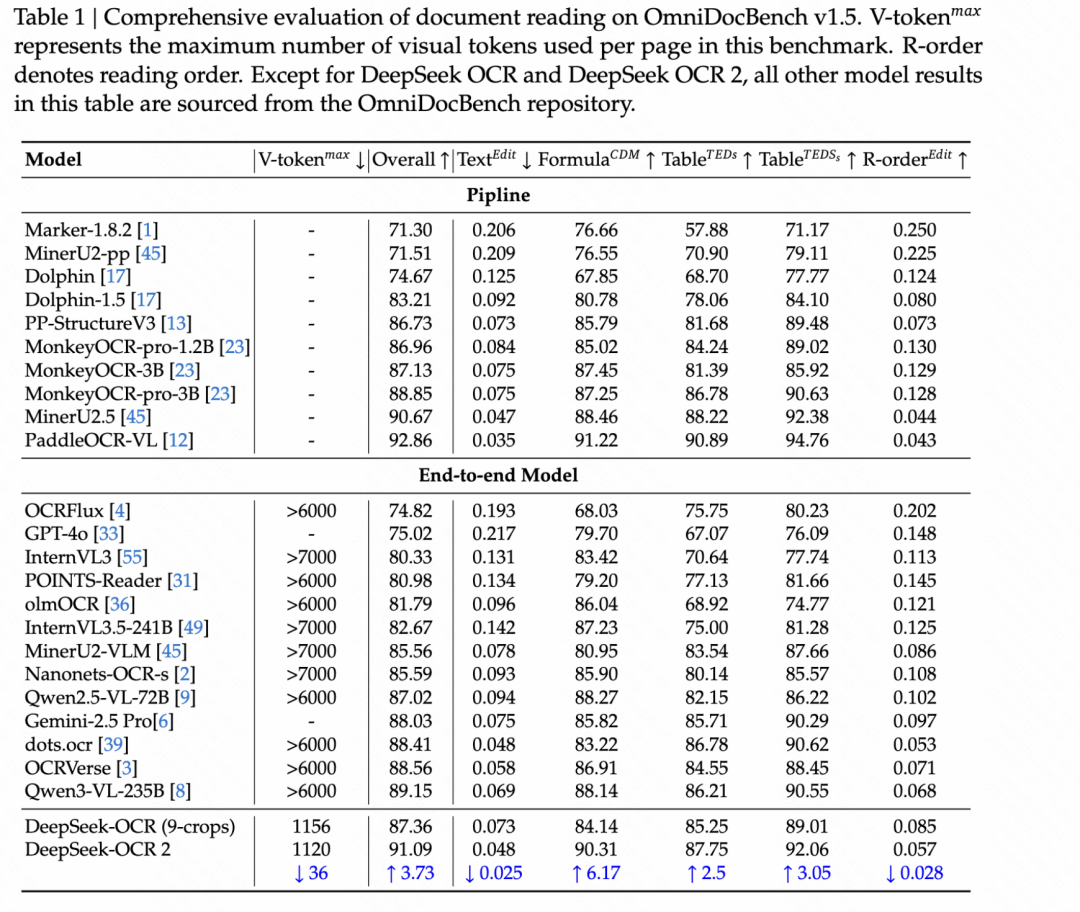
结果:
整体得分:91.09%
相比 DeepSeek-OCR 提升:3.73%
这个提升看着还行,但真正让我意外的是”阅读顺序”(Reading Order)指标——编辑距离从 0.085 降到了 0.057。
编辑距离是什么?就是”把 AI 读出来的顺序调整到正确顺序,需要多少次操作”。从 0.085 降到 0.057,意味着 AI 的阅读顺序更接近人类了,改善了约 33%。
更妙的是,DeepSeek-OCR 2 在保持高精度的同时,视觉 token 数量控制在 256 到 1120 之间,和 Google 的 Gemini-3 Pro 相当,但远低于 MinerU2.0(6000+ token)。这意味着什么?意味着用更少的资源,实现了更好的性能。
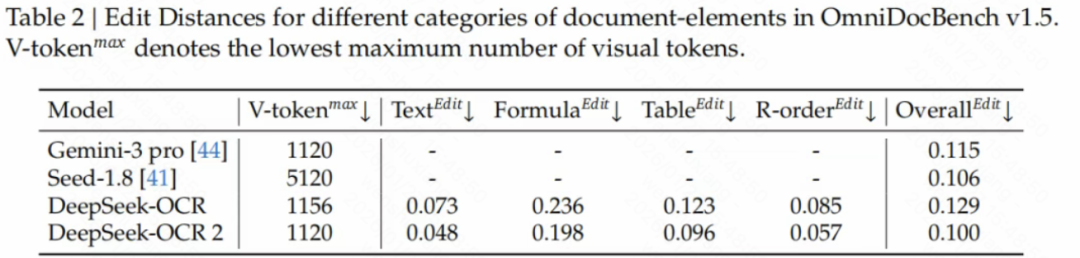
生产环境表现
DeepSeek 还披露了生产环境的表现。这个挺关键的,因为很多模型在基准上表现很好,但一到实战就崩了。
他们主要看两个指标:在线用户日志图像的重复率、PDF 批处理数据的重复率。

结果:
在线用户日志图像:重复率从 6.25% 降到 4.17%
PDF 批处理数据:重复率从 3.69% 降到 2.88%
重复率是什么?就是 AI 输出重复内容的比例。重复率高,说明 AI 在”瞎猜”——它不知道该读哪里,就在那儿瞎编。重复率下降,说明 AI 的阅读逻辑更准确了,瞎猜变少了。
最后
写到这里,我觉得这篇论文的意义不只是改进了 OCR,而是指向了一个更大的方向——统一全模态编码器。
DeepSeek 在论文里说,DeepEncoder V2 的架构可以扩展到其他模态。未来,同一个编码器可能处理图像、音频、文本,都通过”观察全局 → 决定顺序 → 因果推理”的逻辑。
为什么这么说?因为 DeepEncoder V2 的核心不是”视觉特征提取”,而是”因果推理能力”。图像需要按语义顺序读,音频需要按时间顺序理解,文本本身就需要因果注意力。
如果这些模态都通过同一个编码器处理,它们就能共享”因果推理”的能力,而不是每个模态单独设计一套架构。
这可能是通向原生多模态的一条路。
参考资料:
- DeepSeek-OCR 2 论文:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
- DeepSeek-OCR 2 Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
- OmniDocBench 基准:https://github.com/opendatalab/OmniDocBench
- DeepSeek-OCR 原版论文:https://arxiv.org/abs/2510.18234
本文由 @卡萨丁AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


