
 起点课堂会员权益
起点课堂会员权益从Transformer到MoE:大模型架构的范式转移
大语言模型领域正经历一场静默却深刻的架构革命。从Transformer到MoE再到Mamba,这场由成本与效率驱动的变革正在重塑AI行业的底层逻辑。本文将带你穿越2017-2025年的关键技术节点,解密MoE如何实现参数规模与计算成本的解耦,剖析Mamba挑战注意力霸权的可能性,并深度解析Qwen3等前沿开源模型的混合架构设计。

2024年至2025年,大语言模型领域正在经历一场静默但深刻的架构革命。
当大多数人还在关注模型的参数规模和benchmark分数时,一场关于”如何更高效地构建和运行大模型”的技术变革正在悄然发生。从2017年Transformer的横空出世,到2023年Mixtral将MoE架构带入主流视野,再到2024年Mamba挑战注意力的霸权地位,以及2025年Qwen3、GLM-5等国产模型采用的混合架构——大语言模型架构正在经历从”单一架构主导”到”多元架构融合”的范式转移。
这场变革的核心驱动力是什么?
答案很简单:成本与效率。
GPT-4级别的模型训练成本高达数亿美元,推理成本更是让大多数企业望而却步。MoE架构的出现,让模型能够在保持巨大参数规模(知识容量)的同时,仅激活少量参数进行推理,实现”大模型的小成本”。而Mamba等新兴架构,则试图从根本上解决Transformer注意力机制的二次复杂度问题,为长序列建模开辟新的可能。
这场变革不仅仅是技术层面的创新,更是对整个AI行业成本结构的重新定义。在过去,训练一个GPT-4级别的模型需要数亿美元的投入,这让大多数企业和研究机构望而却步。但现在,通过MoE架构,DeepSeek-V3仅用557万美元就完成了671B参数模型的训练,这一成本优势将极大地推动大模型的普及和应用。
同时,长上下文能力的提升也正在开辟新的应用场景。从处理整本书籍到分析大型代码库,从理解长视频到处理基因组序列,128K甚至256K的上下文窗口正在让以前不可能的任务变为现实。
本文将带你穿越这场架构演进的时间线,深入理解:
- Transformer为何能成为过去七年的主导架构?
- MoE如何实现参数规模与计算成本的解耦?
- Mamba能否真正挑战Transformer的地位?
- 2024-2025年最前沿的开源模型架构长什么样?
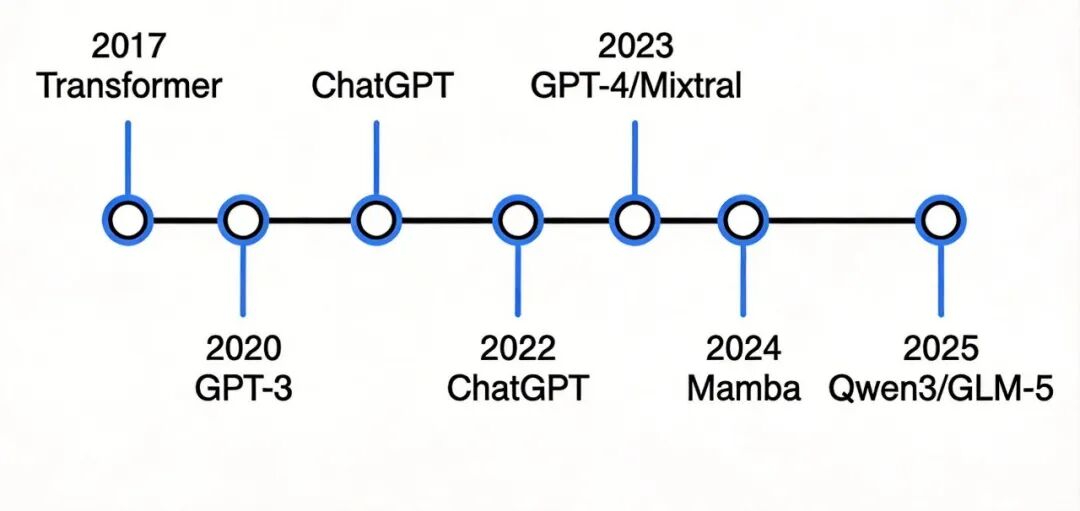
图1:大模型架构演进时间线(2017-2025)
一、Transformer的统治时代
1.1 Attention is All You Need
2017年6月,Google Brain团队发表了那篇改变NLP历史的论文——《Attention is All You Need》。这篇论文在短短几年内获得了超过10万次引用,其提出的Transformer架构成为此后几乎所有大语言模型的基石。
Transformer的核心创新是什么?
简单来说,它彻底摒弃了此前主导序列建模的RNN和CNN,完全依赖自注意力机制(Self-Attention)来建模序列中的依赖关系。
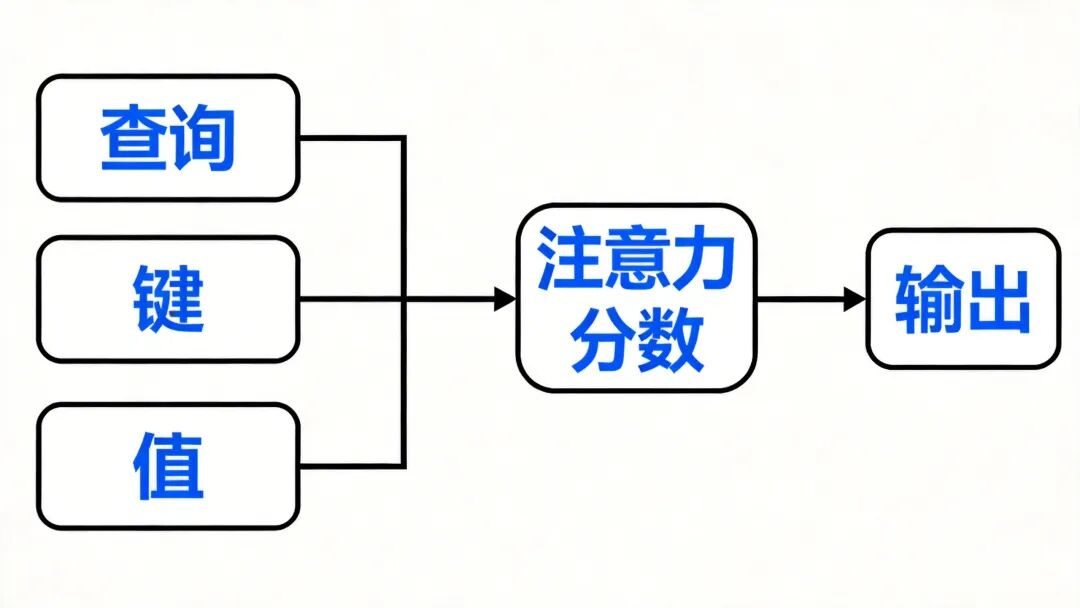
图2:Transformer自注意力机制示意图
让我们用一个通俗的比喻来理解注意力机制:
想象你在阅读一篇长文章,当读到”他”这个词时,你的大脑会自动回溯前文,寻找”他”指代的对象。注意力机制做的就是这件事——它让每个词都能”看到”序列中的所有其他词,并根据相关性分配不同的关注度。
自注意力的数学本质:
对于输入序列中的每个位置,模型会生成三个向量:
- Query(查询):”我在寻找什么信息?”
- Key(键):”我包含什么信息?”
- Value(值):”我的实际内容是什么?”
通过计算Query和Key的点积,得到注意力分数,再用这个分数对Value进行加权求和,就得到了该位置的输出表示。用公式表示就是:
Attention(Q, K, V) = softmax(QK^T / √d_k) V
其中,除以√d_k是为了防止点积结果过大导致softmax梯度消失。
这种设计的精妙之处在于:
- 并行化训练:不像RNN需要逐个时间步计算,Transformer可以一次性处理整个序列,充分利用GPU的并行计算能力
- 长距离依赖:序列中任意两个位置的距离都是O(1),不存在信息随距离衰减的问题
- 可解释性:注意力权重直观展示了模型”在看哪里”,便于调试和分析
1.2 从BERT到GPT:两条路线的分野
Transformer架构诞生后,迅速分化出两条主要的技术路线:

1.3 Transformer的阿喀琉斯之踵
然而,Transformer并非完美无缺。随着模型规模和应用场景的不断扩展,其固有缺陷也逐渐暴露:
问题一:计算复杂度的二次增长
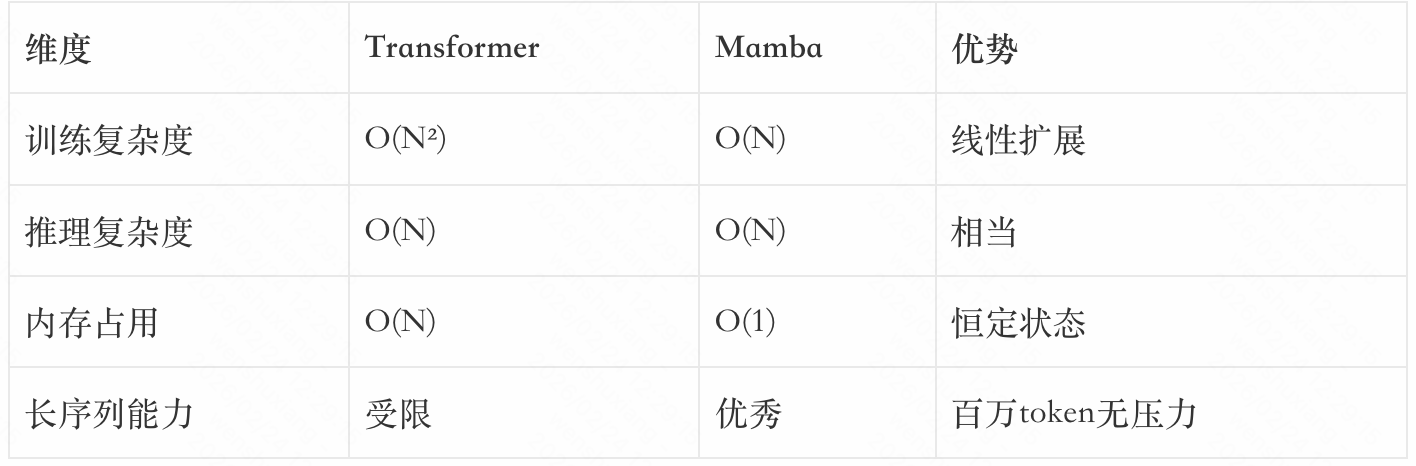
自注意力机制的计算量与序列长度的平方成正比(O(N²))。处理100万tokens需要约1万亿次操作。
问题二:KV Cache的内存爆炸
在推理阶段,Transformer需要缓存所有历史token的Key和Value向量。一个70B参数的模型,处理128K上下文,KV Cache可能占用数十GB显存。
问题三:参数效率的瓶颈
传统稠密(Dense)模型在推理时需要激活所有参数。GPT-4级别的模型可能有1.8万亿参数,每次推理都要全部计算,成本极高。这导致大模型的部署成本居高不下,限制了其在实际应用中的普及。
这些问题催生了对新架构的探索——MoE和Mamba应运而生。
1.4 多头注意力:Transformer的核心组件
Transformer的另一个关键创新是多头注意力(Multi-Head Attention)。这一设计让模型能够从不同的”角度”关注输入序列,捕捉不同类型的依赖关系。
工作原理:
多头注意力将Query、Key、Value分别投影到多个子空间,在每个子空间独立计算注意力,然后将结果拼接起来:
MultiHead(Q, K, V) = Concat(head_1, …, head_h) W^Owhere head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
每个”头”可以关注不同的特征:一个头可能关注语法结构(主谓宾关系),另一个头可能关注语义相似性(同义词、近义词),还有一个头可能关注长距离依赖(代词指代)。这种设计大大增强了模型的表达能力。
1.5 位置编码:赋予序列顺序信息
自注意力机制本身是无序的——它平等对待序列中的所有位置,不考虑词的先后顺序。为了让模型理解序列的顺序信息,Transformer引入了位置编码(Positional Encoding)。
原始Transformer使用正弦和余弦函数生成位置编码,这种设计的好处是可以处理任意长度的序列,相对位置可以通过线性变换得到。后来的模型(如GPT、Llama)改用可学习的位置编码或旋转位置编码(RoPE),进一步提升了性能。
1.6 层归一化和残差连接:训练稳定性的保障
Transformer还引入了层归一化(Layer Normalization)和残差连接(Residual Connection),这些都是训练深层网络的关键技术。
残差连接:output = LayerNorm(x + Sublayer(x))。这种设计让梯度可以直接流过跳跃连接,缓解了深层网络的梯度消失问题。现代Transformer模型通常有24、32甚至更多的层,残差连接是训练如此深层网络的必要条件。
二、MoE——参数规模与计算成本的解耦
2.1 混合专家模型的核心思想
混合专家模型(Mixture of Experts,MoE)的思想最早可以追溯到1991年。但在神经网络领域,MoE长期停留在学术研究的层面,直到2020年代才在大语言模型领域焕发新生。
MoE的本质是什么?
想象一个大型医院,有多个专科医生(专家):心脏科、神经科、骨科……当一个病人来看病时,分诊台(路由器)会根据病人的症状描述,将病人分配给最相关的1-2个专科医生,而不是让所有医生都来看一遍。
MoE做的就是这件事:
- 专家(Experts):多个专门化的子网络,每个擅长处理某类输入
- 路由器(Router):决定每个输入token应该由哪些专家处理
- 稀疏激活:每个token只激活少量专家(如2-8个),而非全部
2.2 MoE的数学原理
一个典型的MoE层可以表示为:
y = Σ(i=1 to N) G(x)_i · E_i(x)
在实际实现中,为了保持稀疏性,通常采用Top-K选择策略,只选择权重最高的K个专家。
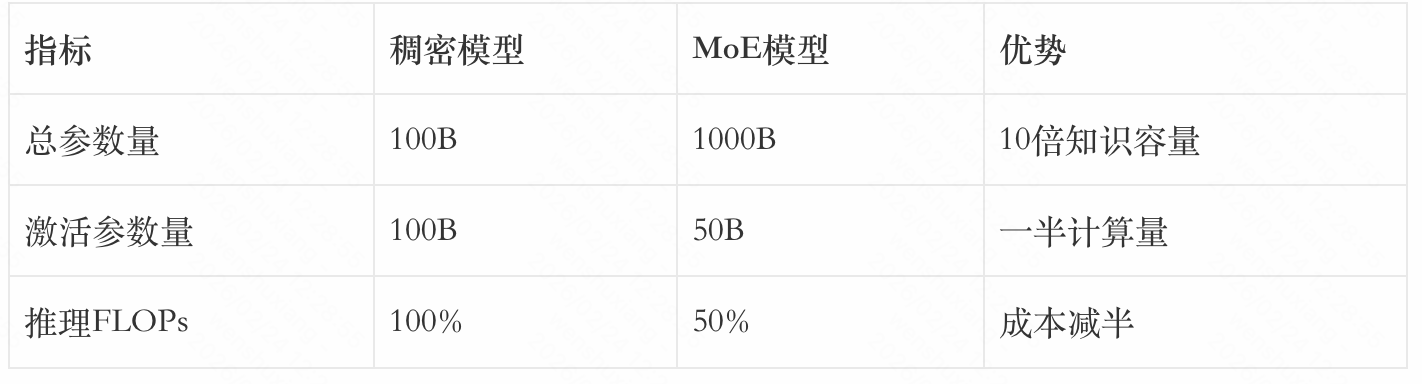
2.3 从GShard到Mixtral:MoE的主流化之路
2021年:GShard(Google)
Google的GShard首次展示了MoE在万亿参数模型上的可行性,采用Top-2专家路由,在机器翻译任务上取得了突破性的效果。
2023年:Mixtral 8x7B(Mistral AI)
法国AI公司Mistral开源的Mixtral 8x7B成为MoE进入主流的标志。它采用8个7B专家,每次激活2个,总参数46.7B,激活参数仅12.9B,性能却超越了Llama 2 70B。Mixtral的成功证明了MoE架构的实用价值,也推动了开源社区对MoE的广泛采用。此后,越来越多的模型开始采用MoE架构,包括Qwen3、GLM-5、DeepSeek-V3等国产模型。
2.4 专家容量的设计
在MoE架构中,每个专家都有一个容量(Capacity)限制,即每个专家在单个训练步骤中最多能处理的token数量。这个设计是为了防止内存溢出和负载不均。
容量因子的计算:capacity = (tokens_per_batch / num_experts) * capacity_factor。其中,capacity_factor是一个超参数,通常设置为1.0-2.0。
溢出处理:当某个专家接收到的token超过其容量时,多余的token会被标记为”溢出”,通常会被直接传递到下一层而不经过任何专家处理。DeepSeek-V3采用了一种更智能的溢出处理机制——动态容量调整。
2.5 专家并行的分布式训练
MoE架构的一个关键优势是可以通过专家并行(Expert Parallelism)实现高效的分布式训练。
数据并行 vs 专家并行:
- 数据并行:每个GPU处理不同的数据批次,但拥有完整的模型副本
- 专家并行:每个GPU只负责一部分专家,所有GPU共同完成整个MoE层的计算
通信开销的优化:专家并行的主要瓶颈是GPU间的通信开销。为了减少通信,研究人员提出了多种优化策略:局部路由、专家分组、异步通信、All-to-All优化。
三、Mamba——挑战注意力霸权的新势力
3.1 状态空间模型(SSM)的复兴
2023年底,一篇名为《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》的论文在NLP领域投下了一颗重磅炸弹。作者提出了一个大胆的命题:
我们不需要二次复杂度的注意力机制,线性复杂度的状态空间模型同样可以实现Transformer级别的性能。
3.2 Mamba的三大创新
创新一:选择性状态空间(Selective SSM)
传统SSM的参数是固定的,与输入无关。Mamba让它们成为输入的函数,模型可以根据当前输入动态决定关注什么、记住什么、更新速度。
创新二:硬件感知算法
Mamba设计了一种高效的并行扫描算法,在GPU上实现了接近Transformer的训练速度。
创新三:简化的架构设计
Mamba将SSM、一维卷积和门控机制整合为一个简洁的块结构,去除了传统Transformer中的注意力层和MLP层。
3.3 Mamba vs Transformer:复杂度对比
3.4 Mamba的局限与挑战
尽管Mamba在效率上具有优势,但它也面临一些挑战:
挑战一:上下文学习能力。研究表明,Transformer的注意力机制在上下文学习(In-context Learning)方面具有独特优势。Mamba的固定状态大小可能限制了其从上下文中学习新模式的能力。
挑战二:工程生态。Transformer拥有成熟的工程生态(FlashAttention、vLLM、TensorRT-LLM等),而Mamba的工具链仍在发展中。
挑战三:大规模验证。目前Mamba主要在中小规模模型上验证(如2.8B、7B参数),其在千亿参数级别的表现仍有待观察。
3.5 线性注意力:另一条降复杂度的路径
除了Mamba,研究人员还探索了其他降低注意力复杂度的方法,统称为线性注意力(Linear Attention)。
核心思想:标准注意力的计算瓶颈在于softmax和QK^T的矩阵乘法。线性注意力通过数学技巧,将计算顺序重新排列,复杂度从O(N²d)降到了O(Nd²)。
代表工作:Performer(使用随机特征映射)、Linear Transformer(使用核技巧)、RWKV(结合RNN和Transformer的优点)。
四、2024-2025年主流开源模型架构深度解析
4.1 模型对比总览
在进入具体模型分析之前,让我们先对2024-2025年主流开源模型有一个整体认识:
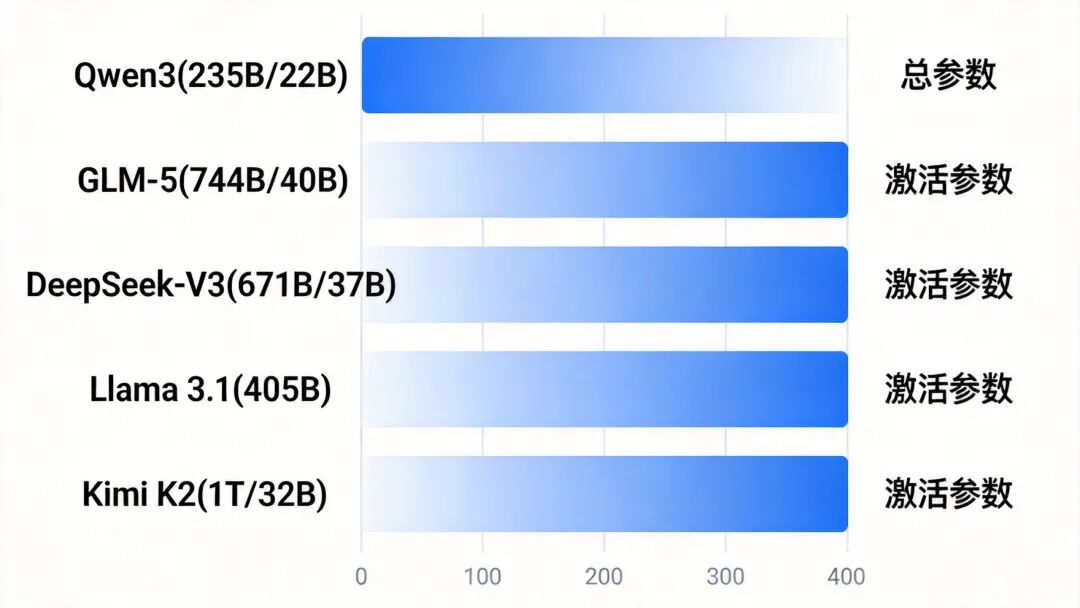
图4:2024-2025年主流开源模型参数对比
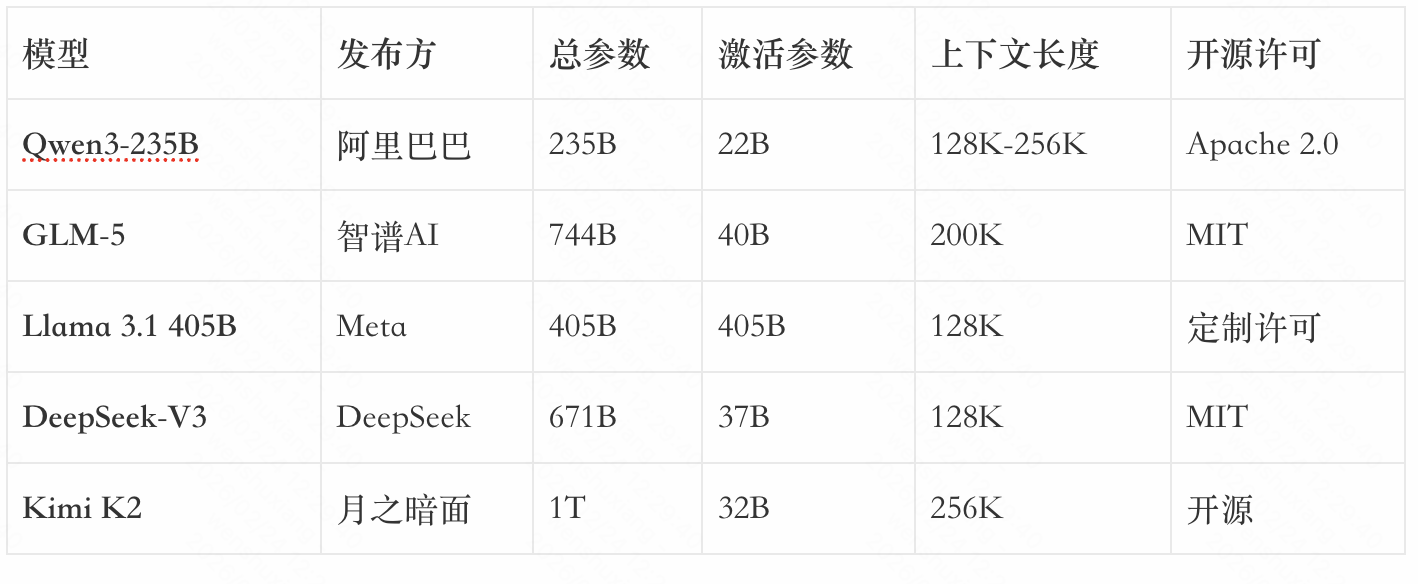
4.2 Qwen3:阿里开源的MoE标杆
2025年4月29日,阿里巴巴通义千问团队正式发布了Qwen3系列模型,这是国产开源大模型的重要里程碑。
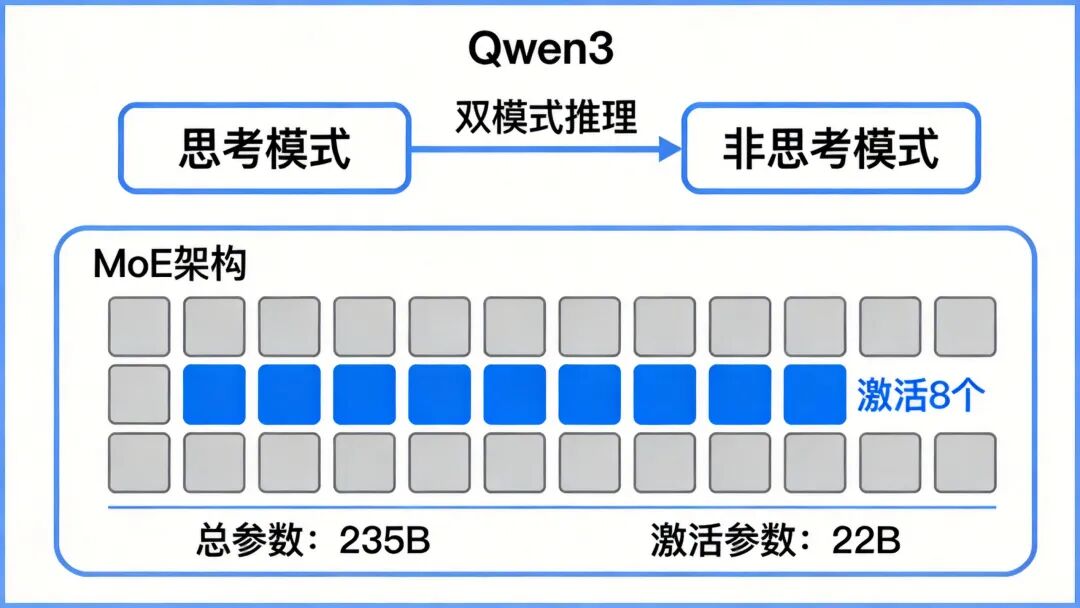
图5:Qwen3双模式推理与MoE架构
双模式推理:
- 思考模式(/think):针对数学推理、代码生成等复杂任务,通过”内部草稿纸”进行多步骤推演
- 非思考模式(/no_think):适用于闲聊、信息检索等场景,响应延迟降至200ms以内,算力消耗减少60%
架构创新:
- 取消共享专家层:传统MoE通常有一个共享专家被所有token使用,Qwen3取消了这一设计,采用128路细粒度专家分割
- 全局负载均衡:通过全局负载均衡损失函数优化专家调度效率
- QK-Norm技术:移除注意力层QKV偏置项,引入QK-Norm,降低显存占用
性能表现:
根据官方数据,Qwen3-235B-A22B在多个基准测试中表现出色:MMLU-redux(综合知识)超越Llama 3.1 405B,MATH(数学推理)超越DeepSeek-R1,MBPP(代码生成)超越GPT-4o,Arena-Hard(人类偏好对齐)开源模型第一。
2025年7月更新:阿里发布了Qwen3-235B-A22B-Instruct-2507-FP8版本,将上下文长度扩展到256K,在BFCL(Agent能力)测评中表现卓越,超过Kimi-K2、DeepSeek-V3等顶级开源模型。
4.3 GLM-5:智谱AI的新一代旗舰
2026年2月,智谱AI发布了新一代旗舰基座模型GLM-5,代表了国产大模型的最高水平。
核心规格:744B总参数、40B激活参数、256个专家、200K上下文长度。
技术亮点:
- 更大基座,更强智能:参数规模从GLM-4的355B扩展至744B,预训练数据从23T提升至28.5T
- 异步强化学习框架:构建了全新的”Slime”框架,支持更大模型规模及更复杂的强化学习任务
- 稀疏注意力机制:首次集成DeepSeek Sparse Attention,大幅降低模型部署成本
性能表现:GLM-5在多个基准测试中取得开源SOTA:SWE-bench-Verified 77.8分(开源第一)、Terminal Bench 2.0 56.2分(开源第一)、BrowseComp(开源第一)、MCP-Atlas(开源第一)、τ²-Bench(开源第一)。在全球权威的Artificial Analysis智能水平榜单上,GLM-5位居全球第四、开源第一。在Agentic榜单上,GLM-5超过GPT-5.2 (xhigh)和Claude Opus 4.5,位列全球第三。
4.4 DeepSeek-V3:极致效率的MoE实践
2024年底,DeepSeek发布了V3模型,以671B总参数、37B激活参数的MoE架构,成为开源社区的新标杆。
架构创新:
- 多头潜在注意力(MLA):通过低秩压缩技术,将KV Cache压缩到传统方法的1/4,大幅降低显存占用。
- 无辅助损失负载均衡:通过动态调整机制,无需额外损失函数即可实现负载均衡。
- 多token预测(MTP):一次前向传播预测多个未来token,提升训练效率和推理速度。
训练成本:DeepSeek-V3的训练仅花费约557万美元,远低于同等规模模型的数亿美元。这证明了MoE架构在成本控制上的巨大潜力。更重要的是,DeepSeek-V3证明了:中国团队完全有能力在有限的算力资源下,训练出世界一流的大模型。
4.5 Llama 3.1:开源社区的中流砥柱
2024年7月23日,Meta发布了Llama 3.1系列模型,包括8B、70B和405B三个版本,其中405B版本是当时最大的开源稠密模型。
核心规格:

架构特点:Llama 3.1采用了GQA(Grouped-Query Attention)替代传统的Multi-Head Attention,将KV Cache大小减少了一半。与MoE模型不同,Llama 3.1采用传统的稠密Transformer架构,所有参数在推理时都被激活。这种设计保证了推理的确定性和稳定性。
性能表现:Llama 3.1 405B在多个基准测试中表现出色:MMLU(综合知识)与GPT-4相当,HumanEval(代码生成)开源模型领先,GSM8K(数学推理)接近顶级闭源模型。
开源生态:Llama 3.1采用定制的商业许可(Llama 3.1 Community License),允许商业使用,但有一些限制条件。这种”开放但受控”的策略,既推动了开源社区的发展,又保护了Meta的商业利益。
4.6 Kimi K2:月之暗面的MoE力作
2025年7月11日,月之暗面(Moonshot AI)发布了Kimi K2模型,这是继Kimi k1.5之后的又一力作。
核心规格:总参数1万亿,激活参数320亿,上下文长度256K。
技术亮点:
- MuonClip优化器:预训练阶段使用MuonClip优化器实现万亿参数模型的稳定高效训练
- 大规模Agentic Tool Use数据合成:提升模型的工具使用能力
- 自我评价机制的通用强化学习:提升模型的推理能力
2025年11月更新:月之暗面发布了Kimi K2 Thinking,在Humanity’s Last Exam(HLE)基准测试中取得了44.9%的SOTA成绩,超过GPT-5.2和Claude Opus 4.5。作为第一代原生支持”边思考,边使用工具”的Thinking Agent,Kimi K2 Thinking标志着开源AI推理模型的重大突破。
五、架构演进的技术逻辑
5.1 从稠密到稀疏:参数效率的革命
大模型架构演进的一条主线是参数效率的不断提升:
稠密模型(Dense) → 稀疏激活(MoE) → 混合架构(Hybrid)
5.2 从二次到线性:复杂度的降级
另一条主线是计算复杂度的优化:
Transformer O(N²) → 稀疏注意力 O(N√N) → Mamba O(N)
为什么复杂度如此重要?
考虑处理100万token的场景:O(N²)需要1万亿次操作,而O(N)只需要100万次操作,差距是10000倍。这种差距在实际应用中意味着数秒甚至数十秒的延迟差异。
当前解决方案:
- 稀疏注意力:只关注局部窗口或特定位置的token,如Longformer、BigBird
- 线性注意力:用核技巧近似softmax注意力,如Performer、Linear Transformer
- Mamba:完全抛弃注意力,用状态空间建模
5.3 模型并行策略
训练千亿甚至万亿参数的模型,需要复杂的分布式并行策略。
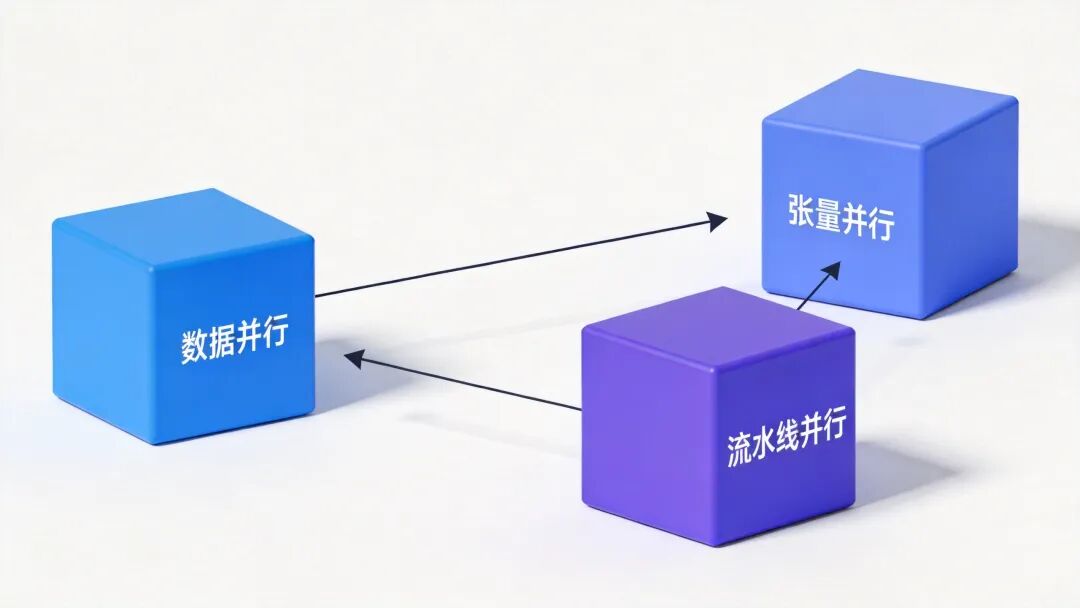
图6:3D并行策略:数据并行、张量并行与流水线并行
- 数据并行(DP):每个GPU拥有完整的模型副本,处理不同的数据批次。
- 张量并行(TP):将模型的每一层切分到多个GPU上。
- 流水线并行(PP):将模型按层切分到多个GPU上,形成流水线。
- 专家并行(EP):MoE特有的并行方式,不同的专家被分配到不同的GPU上。
5.4 推理成本对比
假设处理100万token输入,生成1万token输出:
- Llama 3.1 405B(稠密):约409万亿次操作
- Qwen3-235B-A22B(MoE):约22万亿次操作
MoE模型的计算量只有稠密模型的约5.4%,这意味着推理成本也大幅降低。这就是为什么Qwen3-235B-A22B能以更低的成本提供接近Llama 3.1 405B的性能。
这种成本优势对于企业级应用具有重要意义。以处理100万token输入为例,使用MoE模型可以将推理成本从数百美元降低到数十美元,这使得大模型的商业化应用变得更加可行。
5.4 稀疏注意力:在效率和性能之间寻找平衡
除了Mamba和线性注意力,研究人员还探索了另一种降低复杂度的路径——稀疏注意力(Sparse Attention)。
核心思想:不是所有token对都需要计算注意力。通过只计算部分token对的注意力,可以将复杂度从O(N²)降低到O(N)或O(N log N)。
代表工作:
- Longformer:滑动窗口注意力 + 全局注意力
- BigBird:滑动窗口 + 全局 + 随机注意力
- Sparse Transformer:固定稀疏模式
稀疏注意力的挑战在于设计合适的稀疏模式——既要保证计算效率,又要保留足够的表达能力。
5.5 三大开放性问题
问题一:MoE的通信开销能否彻底解决?MoE在分布式部署时,token需要在不同GPU间路由,造成通信开销。虽然LatentMoE等技术有所缓解,但这仍是制约MoE大规模部署的瓶颈。
问题二:Mamba的上下文学习能力能否追上Transformer?目前的证据表明,Mamba在某些需要强上下文学习的任务上仍略逊于Transformer。
问题三:混合架构的最优配比是什么?Mamba层、Transformer层、MoE层的最佳比例是多少?不同任务是否需要不同的配比?
六、未来展望与思考
6.1 架构融合的趋势
2024-2025年的大模型架构呈现出明显的”融合”趋势:不再是“谁取代谁”,而是“谁适合什么场景”。
未来的大模型可能会像一辆混合动力汽车:
- Mamba引擎:高效巡航(长序列处理)
- Transformer引擎:强劲加速(复杂推理)
- MoE变速箱:智能换挡(任务适配)
6.2 国产模型的崛起
从Qwen3、GLM-5、DeepSeek-V3到Kimi K2,国产大模型正在快速崛起。这些创新证明:中国团队完全有能力在大模型核心架构上实现突破性创新。
6.3 对从业者的建议
对于AI产品经理:
- 关注MoE模型带来的成本优势,重新评估AI功能的ROI
- 了解不同架构的适用场景,选择最适合业务需求的模型
- 关注长上下文能力带来的新应用场景(整本书分析、代码库理解)
对于AI工程师:
- 学习MoE和Mamba的原理,理解其工程实现细节
- 关注vLLM、TensorRT-LLM等推理框架对新架构的支持
- 掌握混合架构模型的部署和优化技巧
对于研究者:
- 探索更高效的注意力替代方案
- 研究MoE的专家负载均衡和通信优化
- 寻找混合架构的最优设计范式
6.4 从稠密到稀疏再到混合:架构演进的必然性
回顾大模型架构的演进历程,我们可以看到一个清晰的脉络:
第一阶段:稠密模型(2017-2020)。Transformer诞生后,所有参数都被激活。GPT-3、BERT等模型采用这种设计,虽然简单直接,但计算成本高昂。
第二阶段:稀疏激活(2021-2024)。MoE架构的出现让参数规模与计算成本解耦。Mixtral、DeepSeek-V3等模型证明了稀疏激活的可行性和优势。
第三阶段:混合架构(2024-)。单一架构无法满足所有需求。未来的模型将采用混合架构,让不同的组件各司其职,实现整体效率最大化。
这种演进不是偶然的,而是成本压力和性能需求共同驱动的必然结果。
结语:架构创新的无限可能
从2017年的Transformer到2025年的混合架构,大语言模型的架构演进从未停止。
这场演进的核心驱动力始终不变:在保持甚至提升能力的同时,降低成本、提高效率。
MoE架构让我们看到了”大模型的小成本”的可能——通过稀疏激活,模型可以在保持巨大知识容量的同时,大幅降低推理成本。DeepSeek-V3的训练成本仅为557万美元,远低于同等规模模型的数亿美元,这证明了MoE架构在成本控制上的巨大潜力。
Mamba架构让我们看到了”线性复杂度的高性能”的希望——通过状态空间模型,我们可以在处理百万token级别的长序列时,保持线性复杂度而非二次复杂度。这为长文档理解、视频分析、基因组学等领域开辟了新的可能。
而混合架构则让我们看到了”取长补短、各尽所能”的务实路径——未来的大模型不再是单一架构的天下,而是多种架构的有机融合。Mamba负责高效处理长序列,Transformer负责精确建模复杂依赖,MoE提供可扩展的计算能力。
附录:关键概念速查
注意力机制相关
- Self-Attention(自注意力):让序列中的每个位置都能关注其他所有位置。
- Multi-Head Attention(多头注意力):将注意力分成多个”头”,每个头关注不同的特征子空间。
- KV Cache(键值缓存):在推理阶段缓存历史token的Key和Value向量。
MoE相关
- Expert(专家):MoE中的子网络,专门处理某类输入。
- Router(路由器):决定每个输入token应该由哪些专家处理。
- Top-K Routing:只选择权重最高的K个专家进行处理。
- Load Balancing(负载均衡):确保所有专家都能得到相对均衡的利用。
优化技术相关
- MLA(多头潜在注意力):DeepSeek-V3提出的低秩KV Cache压缩技术。通过将Key和Value投影到低维潜在空间,将KV Cache压缩到传统方法的1/4。
- MTP(多token预测):一次前向传播预测多个未来token的技术。利用token之间的局部依赖性,提升训练效率和推理速度。
- MQA/GQA:多查询注意力/分组查询注意力。所有Query头共享同一对Key和Value头(MQA),或Query头分组共享Key和Value头(GQA),减少KV Cache大小。
- PagedAttention:vLLM提出的KV Cache分页管理技术。将KV Cache分成固定大小的”页”,像操作系统的虚拟内存一样动态管理,减少内存碎片。
- FlashAttention:通过IO感知的算法设计,减少HBM访问次数,加速注意力计算。虽然理论复杂度仍是O(N²),但实际运行速度可提升2-4倍。
并行训练相关
- Data Parallelism(数据并行):每个GPU处理不同的数据批次,梯度通过All-Reduce操作同步。
- Tensor Parallelism(张量并行):将模型的每一层切分到多个GPU上,权重矩阵按列或按行切分。
- Pipeline Parallelism(流水线并行):将模型按层切分到多个GPU上,形成流水线。GPipe和PipeDream等技术通过微批次减少气泡。
- Expert Parallelism(专家并行):MoE特有的并行方式,不同专家分配到不同GPU。
- 3D Parallelism(3D并行):组合DP、TP、PP的并行策略。GPT-3的训练使用了DP+TP+PP的组合,在数千个GPU上高效训练。
稀疏注意力相关
- Longformer:使用滑动窗口注意力和全局注意力的稀疏注意力变体。复杂度O(N × w),w是窗口大小。
- BigBird:结合滑动窗口、全局和随机注意力的稀疏注意力变体。理论上证明了这种组合可以近似全注意力。
- Sparse Transformer:使用固定稀疏模式(如strided attention)的注意力变体。
状态空间模型相关
- SSM(State Space Model):用微分方程描述系统状态变化的数学模型。h'(t) = Ah(t) + Bx(t),y(t) = Ch(t) + Dx(t)。
- Selective SSM(选择性状态空间模型):参数根据输入动态调整的SSM。B = Linear(x),C = Linear(x),Δ = Linear(x)。
- Selective Scan(选择性扫描):Mamba的核心算法,实现高效的并行状态更新。利用GPU的并行计算能力,将顺序依赖转化为可并行化的前缀和操作。
本文由 @卡萨丁AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


