
 起点课堂会员权益
起点课堂会员权益非技术背景,一文读懂大模型后训练(万字长文)
大模型的后训练都在训练些什么?sft、rl、ppo、lora、adapter,这些算法开发们口中的专属名词,都代表着什么意思?本文将尽可能从非技术角度,一文帮你读懂大模型后训练。
同时这也是继去年发布《非技术背景,一文带你读懂大模型》后,时隔一年多,推出的非技术系列第二篇文章啦。也确实看到大家对于此类非技术向讲解的科普文比较感兴趣,希望这篇新文章能一样受大家的喜欢。

首先我们先简单回顾下,《非技术背景,一文带你读懂大模型》中,提到的大模型的预训练方式。当时我们引入了两个比较重要的概念,一个是向量机制,一个是attention机制。向量机制当时我们用特征,用诗歌中的意向来进行比喻和理解。而attention机制,我们则从阅读文章时脑海中不断形成的网状记忆来进行理解。
那么其实大家当时有没有产生一个问题:
我们进行大模型的预训练,到底实际训练的是什么,以及得到的训练产物是什么呢?
一、预训练到底训了什么
我们经常听到说一个模型有多少多少亿的参数,什么7b,600b,甚至上千b。这些参数,其实就是大模型预训练后沉淀下来的产物了。而参数本身其实并不神秘:
简化到极致的话,我们拿y=kx+b,其中的k和b就是参数。x就是输入,y就是经过参数计算后的输出。
所以实际大模型训练中沉淀下来的,其实也就是这些参与到计算中的参数。简单来看的话,我们可以认为大模型其实就是个巨大的,分模块的,矩阵方程组。输入的信息x,在经过这个巨大方程组内诸多参数计算后,得出输出结果y。
在未进行训练之初,这个巨大方程组中海量的参数会有一个初始的随机值。然后再经过一系列的预训练策略和算法,比如掩码生成(盖住部分词让模型来猜)、预测下一个词,等预训练手段后,参数也逐渐在几个环节里同步逐渐收敛沉淀了下来:
第一个是向量化的阶段。这个环节主要负责将输入的信息内容,转化为向量化表达。因为后续的推理计算都是在建立在向量化的基础之上,所以这个环节会在最前置的环节。这个转化的过程可以理解为对应着一套规则,这套规则即为预训练在该环节沉淀下的参数。比如我们输入了“苹果”两个字,那么在经过这套参数计算后,将把“苹果”转为比如[0.1、0.2、0.3…..]这种向量化特征表达。这里实际是会存在一个巨大的升维的方程,而这个方程里的的参数则会在预训练过程中不断收敛固定下来。
然后是在attention层内,attention这个概念我们在前文里介绍过,本质上是要把输入的内容彼此之前建立关联,形成类似“网状记忆”的效果。实际这里会有多个attention层来承接,每一个attention层内均会存在qkv(query查询、key键、value值)三个维度的参数矩阵。这里会把上一步我们转换得到的向量结果在每一层里的qkv三个维度上展开,展开的目的实际是要找到“苹果”这个实体,在向量化后,与其他输入序列实体中的潜在关联关系和权重的个计算。
有点拗口,打个比方。“今天我吃了水果”,那么在这个处理过程里,会让“今天”“我”“吃了”“水果”,彼此之间都带上彼此的向量特征信息和权重,以保证在后续的推理时,不是仅因为“苹果”,而预测下一个token,而是因为关联了“今天我吃了水果”这整句话的语义,以及“今天”“我”“吃了”“水果”这几个实体彼此的向量特征,进行的综合加权后的预测结果。这其实也是transformer架构的核心,也是attention is all you need这个理念的核心。
然后是在ffn前馈神经网络层内,这里会和attention层一一对应,每层attention后都会紧跟着一层ffn,这一阶段主要做的是,把attention阶段计算得到的关联结果,再经过大模型学习沉淀下的“通识知识和关联特征”,做一次“升维再降维”的处理。这里会有两个矩阵方程来完成这件事。这一步的主要目的是尽可能的放大并聚合特征,把过程中没必要的杂音过滤掉,聚焦关键信息,让模型的输出更精准。
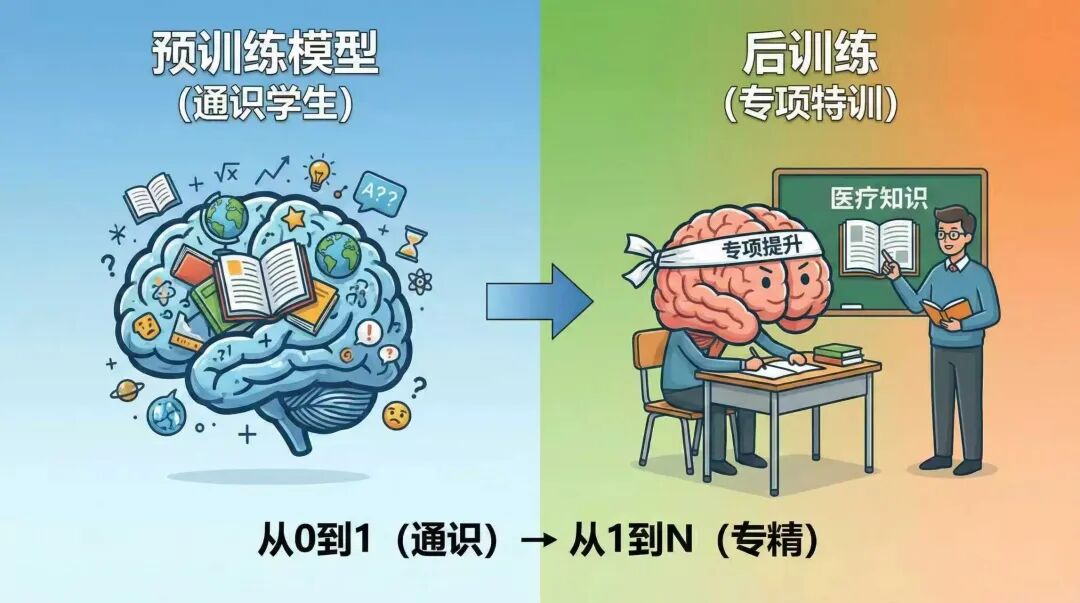
那么搞懂了预训练的产物,我们对于后训练阶段到底训练的是个啥,就好理解了:
本质上,后训练就是通过各种“工具和方法”,对预训练阶段经过以上三个环节不断收敛沉淀的这些“矩阵方程组内的参数”,做针对性调整、优化,使得大模型的输出更加符合业务层面的预期的过程。
二、后训练的微调方向
在后训练方向上,我们可以简单区分为两个大的方向,分别是监督学习微调(sft)、强化学习微调(rl/rlhf)
这两个个方向其实我们可以拿老师教授学生学习来打比方:
首先我们把预训练的模型,看作是一个有一定基础的,有一定通识能力的学生。而教会这个学生提高成绩,是我们后训练微调的目标。
监督学习微调(SFT)

监督学习微调,则相当于老师给了学生一堆的题目和答案(标注数据),来让学生模仿答案的输出来进行学习。这个过程里,来自于人工整理的“标准答案”至关重要。人工整理出“输入问题”和“理想预期回复结果”的成对数据,模型通过学习这些成对数据,来不断调整并收敛参数,让自己输出的内容尽可能贴近“标准答案”。
SFT是大模型后训练中最常用的方式,因为这种方式首先定义很明确,可以很容易有来自业务侧明确的输入(回答结果的好与坏因主观因素过多,可能不好定义,但预期理想结果,这个相对来说还是好给出的)。其次这种方式所需要的数据量一般不需要太多,就可以在测试集上立竿见影的看到效果,所以如果是想快速满足业务诉求,这种方式会比较快捷且相对来说可控些。
但缺点其实也很明显,因为这种方式更像是让模型在死记硬背试题答案,且虽然预训练的模型具备一定的泛化性,但如果是遇到了超出训练集的case,其效果就要大打折扣,模型的推理能力和创造力会因这种“死记硬背”而交一大笔对齐税”Alignment Tax”
另外这里补充一个小知识点。大家有没有好奇过,transformer架构下,大模型实际做的是通过计算概率,来预测下一个token。所以实际预训练后的模型,本质上是一个“续写模型”才对。但如果遇到一个输入,“今天吃了什么”,目前的大模型会对问题进行友好的回答,而不是紧跟着输入来继续续写。
这里答案就是因为,在经过预训练的模型,都会先进行一次“冷启动”,也叫指令微调。冷启动其实就是拿着几千到几万条高质量的问答、指令遵循数据,用SFT的方式监督微调模型,这样才让模型从一个“续写模型”,变为了一个“问答模型”。
ok以上基本就是监督学习微调的内容了。不过可能会有同学好奇,有监督学习微调,那么有没有无监督学习微调呢?
有的兄弟,有的。无监督微调(UFT),当然行业内更多是叫作增量预训练(CPT):
这里也打个比喻,就好像是老师觉得学生的语文有点不太好,所以给了学生大量的古诗作文等语文相关的知识,让学生自己学习自己去悟,以加强语文这块的垂域知识能力。
其实这一过程跟预训练很像,包括使用的训练策略也一样是使用比如掩码生成(盖住部分词让模型来猜)、预测下一个词等方式来完成。只是在阶段上,预训练是从0到1,从一堆随机参数里让模型学会语言规律和构建通识能力。无监督微调是从1到N,在一个已完成预训练,有了一定基础和通识能力上的模型上加强训练,强化的是模型在某一个垂域下的知识丰富度。
所以这里行业内对于这个过程算不算作后训练各有说法,属于介于预训练到后训练中间一环,所以这里我就不多加定义了,也就没有把他单独领出来算作后训练的一个大类
强化学习(RL/RLHF)
这种方式可以理解为,老师给了学生一堆的题目来做,并对学生输出的结果进行打分。然后让学生从评分中,自我学习自己悟出优化的方向。
RL的方式其实在机器学习中很早就在应用了。比如像之前的alphaGo zero,就是通过对模型每一步下棋的结果进行打分,来让alphaGo zero在每一步的下棋过程里,逐渐领悟到诸多的下棋技巧。
但在llm中,我们发现对于结果的好坏,有点没法像下象棋,围棋,贪吃蛇等,对于大模型的决策过程有一个相对精准的打分了。比如游戏里吃到金币+十分,吃掉对面的卒加5分等。因为模型的输出是一段口语化的回复,针对这个回复去打分,会掺杂很多主观的成分。所以这时候我们就引入了人类打分的概念,这就是RLHF里,HF,human-feedback的由来了。
最初的RLHF,其中human-feedback部分是由人类来完成。但这种方式太过于耗人了,且不同人类之间的评价机制过于主观,反而效果不好。直到openAI于2017年,提出了PPO的强化学习算法,并在2022年首次将其应用在instructGPT的强化学习流程中并验证了其可行性,至此才正式拉开了,大模型人类反馈强化学习(RLHF)的序章。
2.1 PPO算法
这里我尝试拆解下PPO算法在大模型RLHF中的过程和思想,拆解过后,大家估计就对RLHF这个逻辑清楚很多了。
我们可以这么理解下:首先我们前面讲过,RLHF本质上是让老师给了学生一堆的题目来做,并对学生输出的结果进行打分。然后让学生从评分中,自我学习自己悟出优化的方向。
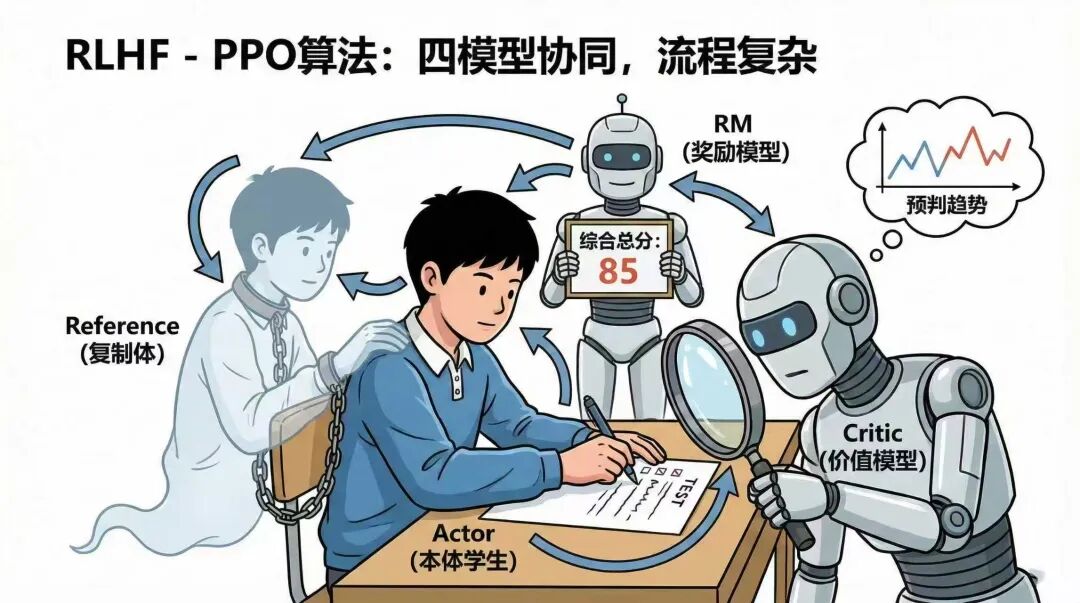
那么首先我们需要有一个被训练的学生,这就是PPO在RLHF中的(Actor)策略模型。
然后我们还得有个老师,来对学生做出的题,进行打分。这一打分当然可以由人类老师进行,但出于上面说的效率低,主观性强的点,所以这里我们引入一个机器人老师来给学生打分,这就是PPO在RLHF中的(RM)奖励模型。通常这个模型是由标注数据后训练的个模型。
然后我们还可以发现,单纯我们通过对于学生的做题结果打分,似乎没法细化到衡量学生在做题过程中是好还是坏的。
打个比方,学生答题时写了一句完整的话“我今天吃了一个又红又大的菠萝”。首先整句来看肯定是有问题的,因为菠萝怎么也不会跟又红又大来挂钩。但如果我们因此对,学生写下整句过程里的推理过程打负分的话,似乎对于学生写下前半句的推理过程不太公平。。。这就好像老师给学生判了个60分,但没有告诉学生扣分点,学生只能盲猜自己需要优化的点。盲猜那就存在一定的随机性啦,就会造成学生的学习成绩起伏不定,始终稳定不下来。提现到模型上就是,训练过程参数震荡剧烈,收敛的也及其的慢。
所以这时候我们还需要再引入一个更强的机器人老师,这个老师会在学生写题时,紧盯着学生的每一步操作,每一步都会针对当前已输出情况,给出一个预判的得分出来。这样学生就可以在收到第一位机器人老师打出的总分的同时,也收到第二位机器人老师针对每道题甚至每个解题步骤给出的预判总分波动图,这样学生就能更快的明白自己是在哪个环节那个步骤出了问题,也就知道该如何加强学习了。而这个,就是PPO在RLHF中的(Critic)价值模型。通常这个模型也是一个由标注数据后训练的个模型。与RM不同的是,打分的阶段和目标不同。一个是整体评判,一个是加速收敛。
然后学生在大量做题提高分数时,虽然我们引入两个机器人老师来帮助学生加速收敛提升学习成绩,但在学习过程里,因为模型参数变动很容易引起全局的输出结果变差。学生的学习也容易出现为了学习一个小知识点,结果混淆了更重要知识点。这个有个名词叫灾难性遗忘。
为了避免这种情况,我们又复制出来一个学生,跟被训练的学生一起做题。并把这个复制体学生的做题结果,与被训练的学生做题结果做对照,并设定一个奖惩机制,如果差距过大,就惩罚被训练的学生,以此避免学生在学习过程里,为了捡了芝麻丢了西瓜的情况。而这个复制体学生,实际就是PPO在RLHF中的(Reference)参考模型。把初始的(Actor)策略模型冻结参数,作为训练时的输出参照,并根据输出参照来计算出一个KL惩罚约束,来保证针对(Actor)策略模型的每步训练调参都不会与初始的输出差距过大。
2.2 DPO算法
ok,讲完了PPO,其实对于RLHF是个啥也就基本清楚了。不过这里我还想再展开讲讲后面出现的些迭代算法,也挺有意思的。不感兴趣的同学可以直接跳过这part。
首先PPO还是很强大的,不然也不会有chatgpt的诞生。但其缺点其实也很明显,我们可以看到,为了优化一个模型,需要搞四个模型去跑,流程相当复杂,及其消耗显存。
那有没有什么更好的方案呢?
这时候在2023年,斯坦福团队提出了另一种思路:PPO是为了判定模型输出的结果好坏,搞出来两位机器人老师分别针对整体和过程来打分,以此让学生清楚自己的优化点。那如果我们极端些,把具体的评分抽象为好答案的概率和坏答案的概率,是不是就不需要再引入这么多模型了呢?
于是,DPO(直接偏好优化)算法应运而生。还是用“老师”和学生的比喻:
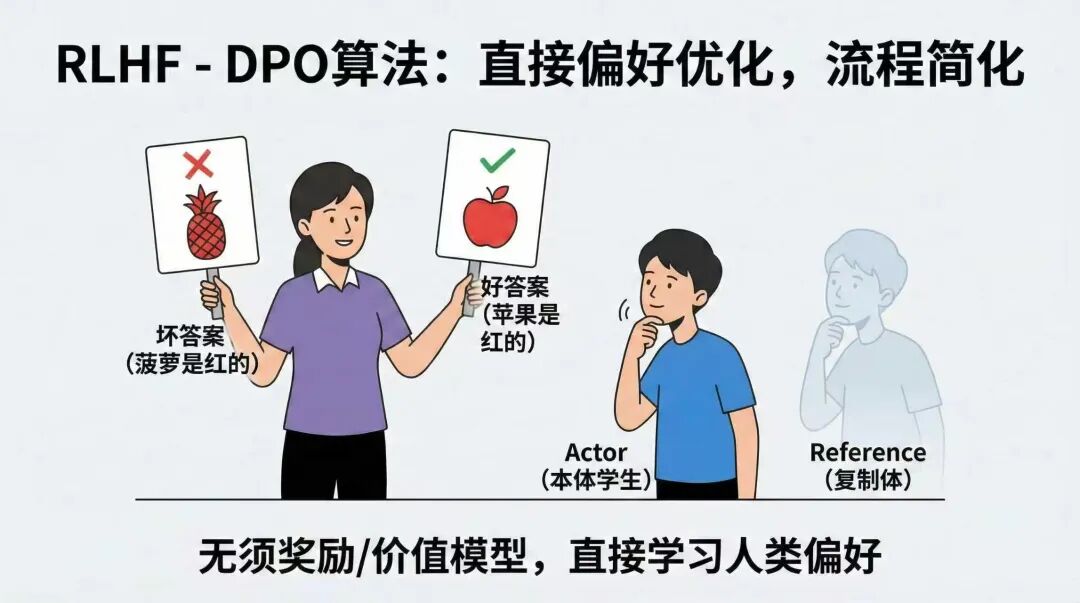
PPO的两位机器人老师,需要给学生的输出打两个分数,一个是整体分数,一个是当前过程中输出的个分数,并需要对学生输出的“我今天吃了一个又红又大的菠萝”,对整体打六十分,并对前半句打高分,对后半句打低分。
而在DPO中,直接由人类老师入场,有点像SFT,直接告诉学生“我今天吃了一个又红又大的菠萝”是一个坏答案,“我今天吃了一个又红又大的苹果”是一个好答案。并让模型自己努力提升输出后者的概率,降低输出前者的概率。
这里要说明下,其实这个形式有点像“加了badcase的SFT”,但其本质和SFT是不同的。SFT是让模型按标准答案一个字一个字去临摹,抄标准答案。而dpo目标是让学生分清好坏,自主偏向好结果的概率。
所以这样一来,DPO中就只需要有两个模型在了。一个是学生,也就是DPO中的(Actor)策略模型。一个是学生的复制体,防止学生跑偏的,也就是DPO中的(Reference)参考模型。省去了两个吃显存的大户,两位机器人老师:(RM)奖励模型和(Critic)价值模型。
所以DPO对于PPO,不仅模型少了,流程也简化轻便了很多。训练起来更高效、稳定,甚至在一些场景下可能效果会比PPO更加的好。这也是为啥DPO目前被广泛应用,因为不需要太多算力,不需要单独训练奖励模型和价值模型,也不需要很复杂的数据集标注即可,即便是中小团队也能快速落地。但其缺点也是显然的,不像PPO那样具备这么强的主动探索的能力,更适合些偏好明确的领域目标。
2.3 GRPO算法
消化完了PPO和DPO之后,我们不妨再思考下。有没有可能有种方式,既保留直接偏好优化的特性,又在主动探索的方向上进行一些创新呢?
这里不得不提一下deepseek啦,deepseek团队在2024年交出了另一份答案:借鉴DPO的相对比较思路,但仍保留PPO中的打分机制,让模型保持探索能力。那么他们是怎么做到的呢?
首先回顾下上面提到的PPO和DPO的方式:
PPO的训练方式相当于通过打分让学生自己优化自己探索,但需要RM和Critic两位机器人老师来全程评估,并需要复制学生本体来作为参照,四个模型一起跑,又重又复杂。
而DPO的训练方式缺少了探索,指定goodcase和badcase,但砍掉了RM和Critic两位机器人老师,只靠初始的学生复制体来约束,虽然轻量且省算力,但创造力不足。
而GRPO做了一个聪明的取舍:继续保留RM这位针对结果打分的机器人老师,但砍掉了Critic这位针对过程打分的老师。
前面我们也知道Critic这位老师,其实是要帮助学生在训练过程里,明白中间步骤的得失,以此来加速模型的参数收敛的,那没有了Critic后,怎么解决这部分问题呢?
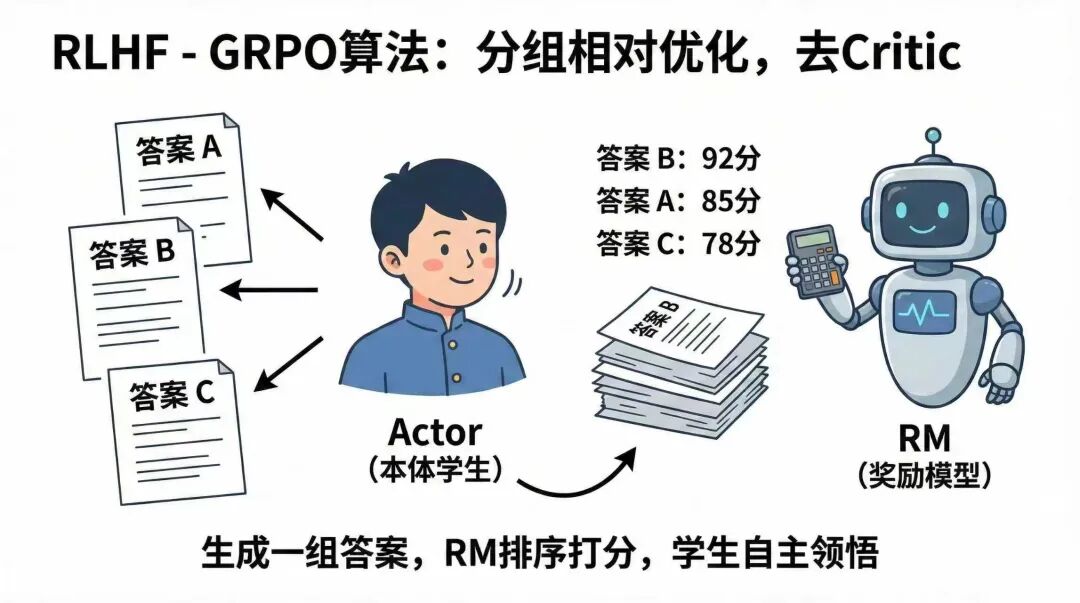
这里GRPO聪明的提出了个“分组相对策略优化”的概念。还是用老师学生来比喻。让学生,也就是(actor)策略模型,一次输出多个结果,并让机器人老师(RM)奖励模型,给这组答案进行逐个打分并排序。然后学生在进行优化调整时,先看下这组答案的个平均得分,再根据每个答案与这个平均得分的相对差距,来作为优化方向的参考。
这样一来,即比PPO省,因为砍掉了Critic这个模型;又比DPO灵活,因为保留了RM模型,可以支持模型自主生成探索。同时还捎带着解决了个RM打分不准带来的震荡问题。这个怎么理解呢?PPO中的RM打分,就好像老师给学生打了个总分,总分的准确率很关键,万一打错,就会对学生的自主探索产生不小的误导。而在GRPO中的RM打分,就好像老师给学生的一组回答打了个分。虽然可能老师个别题打分打错了,但对这组排序整体的影响其实并不大,也就能最小限度的减少因RM打错分,给学生带来的自主探索的误导影响。
ok,讲到这里,那对于大模型后训练这块的方向上,已经基本讲完了。总体来说就是大致两个方向:SFT这种让学生临摹答案的方式来优化训练;和RL/RLHF这种,通过打分或偏好,让学生自己探索的方式来优化训练。前者起效快,周期短,省算力,但探索性不强。后者周期长一些,但能让模型有自主探索性,保证一定的泛化性。
三、后训练的参数微调方法
讲完了大模型后训练的两个方向SFT和RL/RLHF,那我们可以接下来思考下,有了训练优化方向后,那模型里几十亿甚至上千亿的参数,如何去变动更新,来让训练优化朝着我们预期的优化方向进行呢?
首先既然确定了优化目标,那我们就得知道当前模型的表现与预期目标到底相差有多远,这样才能更好的指导接下来的优化。这里我们仍然用老师和学生的方式来比喻:
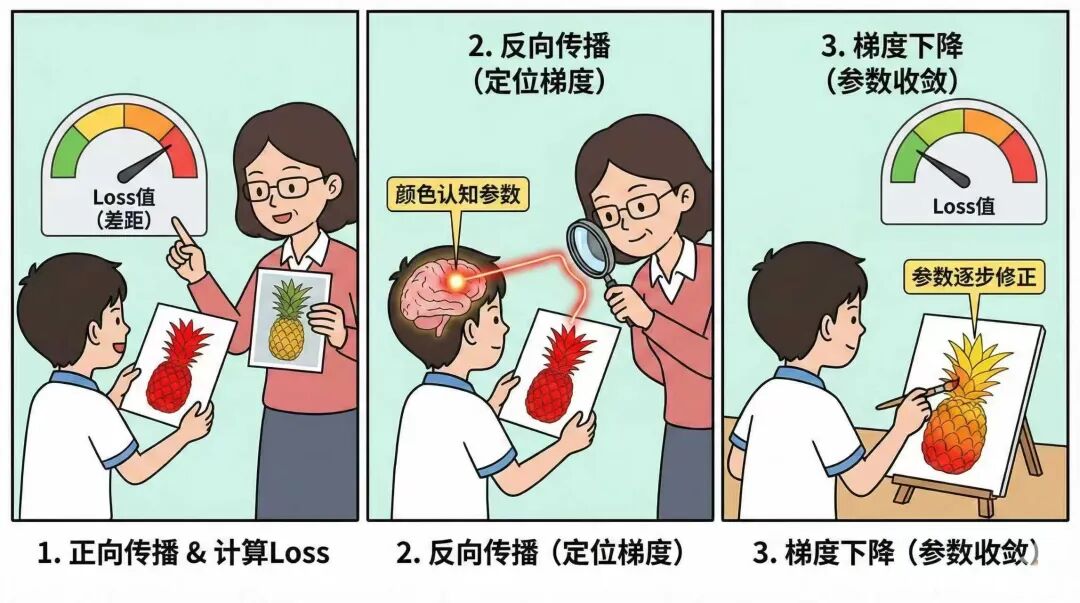
学生拿到试卷,逐个进行答题,最终提交试卷。这个过程对于模型相当于一次完整的输入和输出,在模型训练中,称为一次“正向传播”的过程。
然后老师拿到学生的试卷,根据预期结果,计算总分。计算的时候,根据我们需要让学生加强的方向不同(SFT/RLHF),设定不同的预期,并计算学生的得分以及与预期分数之间的差距。这个差距,在模型训练中称为“loss值”。
然后拿到分数差距后,老师会对照学生的错题点,逐一排查,推断学生在做题时的可能的知识误区和具体哪些知识没有掌握等。比如之前对于菠萝错误判断为了红色,那就判断学生其实对于菠萝的颜色理解的有问题。这个环节在模型训练中称为“反向传播”。对比“正向传播”,是根据输出时与预期的“loss值”,来反向推导模型在推理过程中,每个参数对于loss值的贡献度,也称之为梯度,来找到这些真正导致问题的参数。
然后拿到具体的错误点和知识误区后,下一步就是学生针对性进行改进。比如对于菠萝的颜色理解有误,那就修正。每次改进都能逐渐的缩小loss值,比如从认为菠萝是红色的,到亮黄色,再到焦黄色。这里实际模型训练是采用了“梯度下降算法”,根据反向传播时计算出的每个参数的梯度,让模型一点点修正参数,每次修正都会让loss值变小,直到模型按我们的预期输出。
整体逻辑就是,先通过正向传播以及训练预期,计算出对应的loss值,然后通过反向传播计算参数梯度,然后通过梯度下降算法,逐渐让参数收敛沉淀,并输出符合我们预期的结果。
四、后训练的参数微调范围
掌握了如何调整参数后,新的问题出现里。前文其实也提到了,后训练其实就是调整预训练阶段收敛沉淀下的参数,但预训练的模型参数,动辄几十亿,甚至上千亿的参数。如果我们只是想对模型微调增补些垂域业务知识,难道要把全部的参数更新一遍吗?
全量微调
当然,这肯定是可行的。所以这里就有第一种方式,也就是全量微调(Full Fine-tuning)。全量微调其实是模型后训练时最直接最传统的一种方式,首先通过前文的两种后训练方向,SFT和RL/RLHF,来让学生找准自己优化的目标,然后通过正向传播,与与优化目标进行对比,计算出loss值,然后反向传播计算梯度,然后使用梯度下降等算法,动态更新全量参数,让学生的答题结果,持续逼近预期方向。在这个过程里,持续收敛沉淀参数变化。
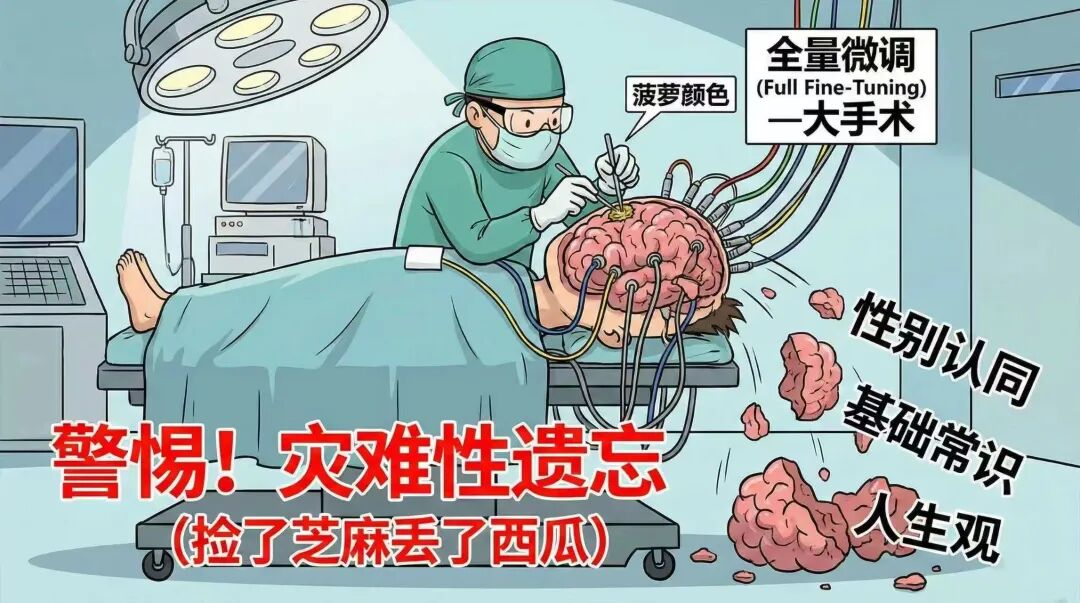
但这个过程由于是全量微调,学生在自主探索过程中,可能不仅是在学科知识这块进行知识的重建,对于自身的一些东西,比如人生观价值观等都会跟着进行重组。这就比较可怕了。。。比如学生可能只是为了要记住“菠萝是黄色的”,但竟然因此调参数把自己的性别搞反了。。。这个前面讲PPO的时候也提过,全量微调的方式更容易出现这种捡了芝麻丢了西瓜的问题。
所以全量微调确实有,且更新彻底,上限很高,但缺点就是耗时耗力,另外就是极容易出现这种灾难性遗忘的问题了,只有大厂在追求极致效果的时候,才可能会出现。
局部微调
那么除了全量微调的方式,有类似局部微调的方式吗?有的兄弟,有的。局部微调(PEFT/高效参数微调)的出现,就是解决这类问题。
首先我们之间讲过,大模型的内部是分模块分层的,但局部微调并不是像我们一般理解的,把大模型的某一部分或某些层冻结后去调剩下层的参数,而是采用更聪明的一种办法来解决这个问题:
既然直接动大模型的原本参数极容易出现灾难性遗忘等问题,那我们给大模型接入一个增量外挂插件,只去调外挂插件里的内容,不就行了?
Adapter Tuning
于是在2019年,由Houlsby提出了Adapter Tuning的方法,核心就是在transformer的每一层的attention和ffn之间,串联的形式新加一层可训练的向量级的适配器,在进行微调时,仅微调适配器中的参数,不动原有预训练阶段大模型的参数,以此来满足微调的诉求。
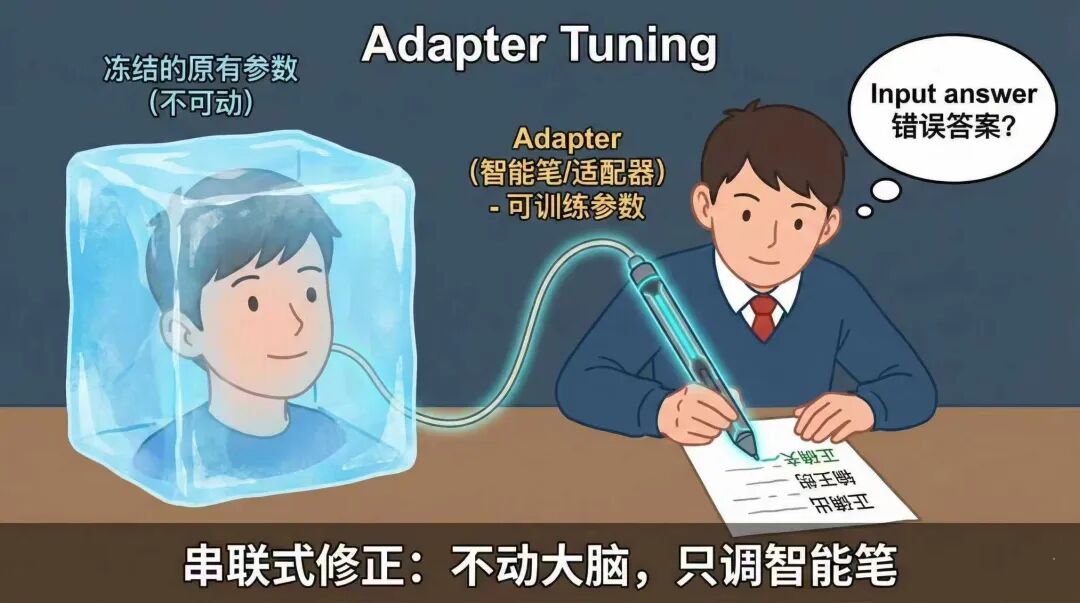
与刚才的全量微调,让学生重新学习相比,就好像给学生新发了一个智能笔,学生不需要去重新学习,这根笔会在学生下笔回答问题时,每一步都会经过智能笔的矫正思路。这样一方面即完成了对于业务微调的诉求,又能不动模型的原有参数。
Low-Rank Adaptation
然后在2021年,微软研究院也新提出一种技术。Low-Rank Adaptation,也就是我们熟知的lora了。这项技术有点像adapter,也是给大模型新加了个增量外部插件。不过跟adapter不同,会在attention层或ffn层,并联的方式插入两个小矩阵,参数量一般不到原模型的1%。在模型推理时与attention或ffn层同步输出,加权后合并结果输出。
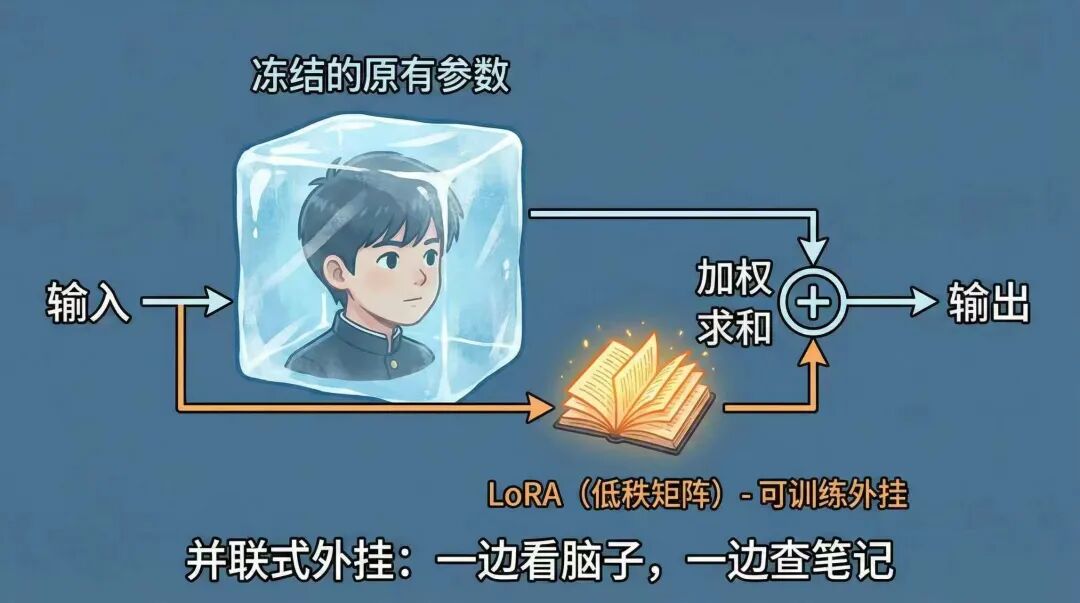
这种形式有点像给学生发了一本专业笔记,在学生进行答题时,让学生按需去查阅这份笔记,并结合自身的基础知识,这样就可以回答的更精准。
这两种方式都是可以实现热插拔式的效果,比如可以灵活给模型切换适用于不同垂域业务场景的lora和adpter插件,以此快速适配不同业务场景。
在stable difussion盛兴的那段时间里,不知道你有没有尝试过下载不同画风的lora。其实他们本质上也是一个个用某种画风的大量图片,持续反向传播梯度下降的方式喂出的个lora插件。相信有过这段炼丹经历的小伙伴能更容易理解这里的概念~
prompt tuning
除了lora和adapter,这里也再提一个更加轻量级的后训练工具,prompt tuning。他也是在2021年,由Liu等人提出。
首先需要先说明下,prompt tuning提示词微调,不等同于prompt engineering提示词工程。提示词工程这个大家应该比较熟知了,就是在给到大模型的输入中,在word层面增加些描述限制之类的东西。而prompt tuning提示词微调,则是在输入内容转为向量化这一阶段,起效的个产物。不修改输入的内容,而是在输入内容的前缀,或中间,插入一段特殊的向量特征,以此来提升模型的输出准确率。

这里用学生答题来比喻的话,,则prompt tuning更像是一个简短的小抄,贴在卷子的最前方。学生在答题时,会先看一遍这个小抄再答题,以此帮助学生在答题时更加准确。
但这种方式虽然足够轻量,不需要像lora和adapter引入新的矩阵,只需要在每次输入时插入一段训练好的固定的向量即可,但其适用性并不高,稍微处理些更泛化更复杂的任务就会抓瞎。
以上,我们基本就对大模型后训练的方向选择、调参方法、调参工具,了解清楚了。
五、后训练的降本增效场景
不过前面所讲的大模型后训练,我们都是预设了模型后训练的目的,是让模型回答更精确或回答更符合业务场景预期来的。但实际后训练还有另外一种目的,降本增效。这里我不打算展开讲,因为大多数同学更多接触的是前者。但既然咱们文章讲的是一文读懂大模型的后训练,似乎不提一下也不够全面。
所以这里再简单展开介绍下大模型后训练,出于降本增效的三种方法:蒸馏、量化、和剪枝。首先大模型降本增效的目的,其实就是减少模型推理时的算力消耗。那么这三种方法,也都是围绕着这一目标进行的,只是各自侧重点不同。
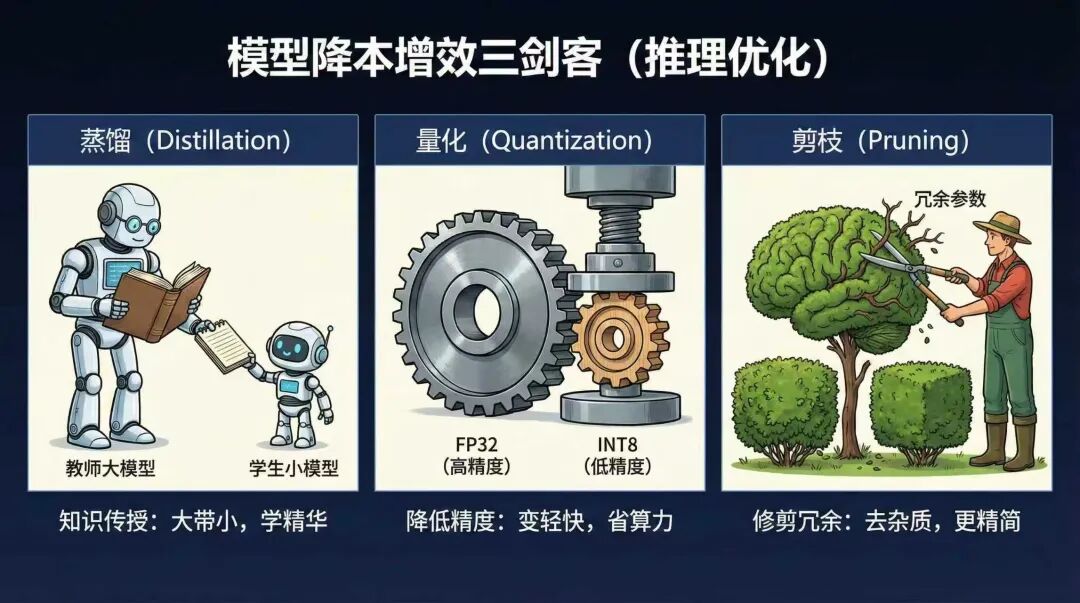
对于蒸馏,我们可以理解为原先的学生是一名大学生,学习的知识比较多,参数很大,思考问题时虽然思考的长远,但比较花费脑力和时间。这时候我们就再找一名初中生,初中生把大学生当成老师,去学习这名老师在回答问题时,每一步解答问题的思路和步骤,以此把自己提升到一个大学生的水平。
就比如我们看到个模型,DeepSeek-R1-Distill-Qwen-7B,实际意思就是,这本身是一个7b的qwen模型,通过大量学习600B的deepseekR1的模型输出结果,展现出了类似deepseekR1的输出效果。但模仿的就是模仿的,肯定实际准确率之类的都会打折扣。
然后对于量化,这个理解上会更加简单些。实际就是降低模型的参数精度,比如从float32,调低变为了int8/int4,比如从1.140023,简化为了1.14。参数量没有变,比如原先是600b,量化之后还是600b,但模型文件会缩小不少,且由于精度下降,其推理时的算力大大减少。但缺点就是这种强制抹零行为,有时候抹的可能正好不是地方,某些场景可能会出现错误的情况。
然后是剪枝,这个简单理解,就相当于学生脑子里除了学习之外,还塞了很多游戏啦,娱乐啦,等等其他杂七杂八的知识,那剪枝就相当于把这些答题场景下用不到的知识都去除掉,这样在模型推理时,自然就会更加简单直接。
六、总结
ok到这里,大模型后训练的全部内容基本讲解完毕。我们再回顾总结梳理一遍知识点:
- 预训练:从0到1,输入大量训练数据,让模型以自监督学习的方式,学会通用知识,沉淀下庞大的参数。相当于一位已经有一定知识储备的学生。
- 后训练:从1到N,通过调整预训练沉淀下的庞大参数,来让学生持续在某一方面专项突破加强。
后训练的方向:
- SFT,监督学习,让模型临摹标准答案,快速见效,但泛化性弱,容易有对齐税
- RL/RLHF,让模型根据人类偏好打分,来自主探索优化学习,泛化性更高,但训练难度稍高。RLHF的经典算法,PPO,以及后续的DPO、GRPO,各自在奖励模型、策略模型、参考模型上做出的取舍和创新设计。
后训练的调参方式:先正向传播计算loss值,再反向传播计算梯度,通过梯度下降算法持续调参来收敛loss值。类比学生就是做卷子打分,通过打分反推扣分点,并持续优化扣分点来提升分数。
后训练的调参范围:
- 全量微调,Full Fine-tuning,所有参数参与到正向传播和反向传播的loss值计算中
- 局部微调,PETF,大模型参数不动,通过给大模型外接控制插件,仅控制插件内的参数参与到正向传播和反向传播的loss值计算中。
局部微调的几种形式:并联形式的lora、串联形式的adapter、在向量阶段插入的prompt tuning。
另一种后训练方向下的应用:蒸馏,拿个小参数模型模仿并替代大模型;量化,参数量不变,但降低参数精度;剪枝,删除冗余参数。
七、结尾
本文的讲解尽可能避开了过于技术层面的讲解,目的还是帮非技术北京的大家真正能读懂后训练,而不是去学会后训练。如果大家确实有实际场景要落地,还是最好再结合对应方向的专门技术文章再深度去了解,本文更多是为你打下后训练这块一个整体认知框架和基础。
说实话这点还是挺重要的。因为我也看过不少后训练的科普文,能发现有些要么是过于技术视角,动不动一堆公式和算法。要么是在概念理解分类上就有问题,比如把sft和lora放在一起讲解,很容易让人误以为这两个名词是一类工具。。。
最后,希望这篇文章能彻底帮大家理清大模型后训练的所有核心知识点,并整理出一个清晰的后续持续继续学习的脉络。希望大家喜欢~
作者:Ranger 公众号:薛定谔的猫爪印
本文由 @Ranger 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


