
 起点课堂会员权益
起点课堂会员权益拒绝背锅:如何制定一份合格的AI产品验收标准?🤔
AI产品的验收绝非简单的黑盒测试,而是需要一套科学严谨的评估体系。本文将揭秘三大实战方法论:如何通过限定边界、建立量化测试集、明确权责划分,在充满不确定性的AI领域构建可靠的验收标准,帮助产品经理告别无休止的内耗与背锅。
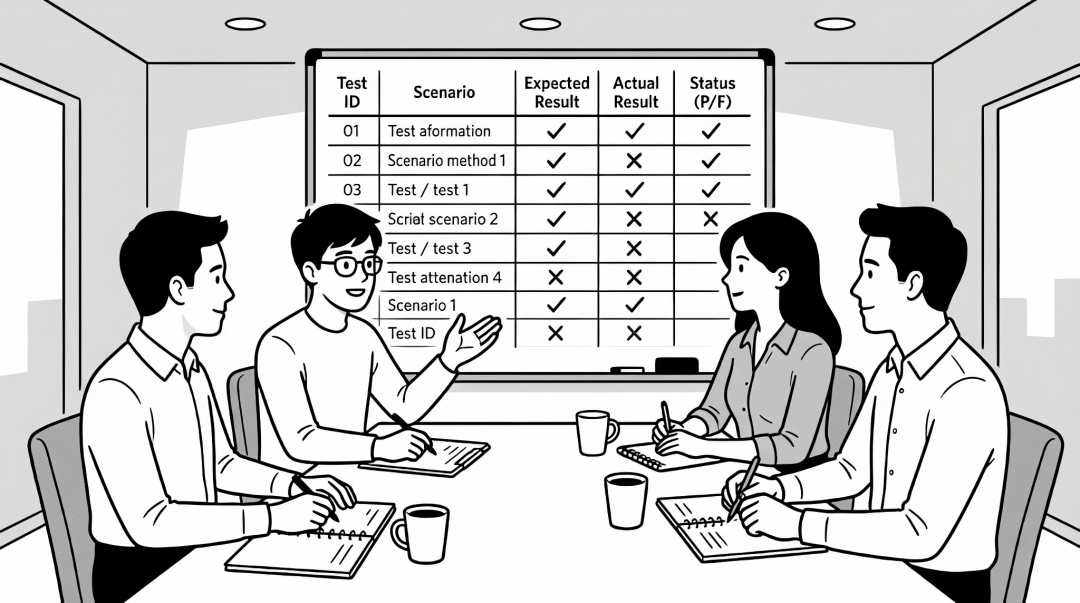
做AI产品,很多时候都感觉在摸黑。
在拿着“点下去就得出这个结果”的逻辑去验收AI,下场只会各种的延期和争论,以及一个扣下来的锅。
在技术是具有概率性和业务强依赖场景下,我们是需要有一套明确的“验收标尺”的。
在接下来,我就为大家讲下我如何去解决这个的一些方法:
方法一:尝试抛弃“能力全面”,先限制好边界
我们经常陷入一个巨大的认知陷阱:
以为接入了大模型,产品就成了全知全能的神。
业务方来提需求,恨不得一个方案能搞定所有事。我在做AI生图项目的时候就是这样。
今天要在A场景下生成一个3D卡通元素,明天又想直接复用到B、C业务线上。一旦在新业务线上跑出的图风格走样,业务方就会指着你问:这AI为啥变笨了?
这不是AI笨,而是它在不同场景的发挥是有区别的。
我们要做的是去承认它的局限性。所以在写验收标准时,要把“不能做什么”写在“能做什么”前面。
模版干货如下(以个人工作场景为例,仅供参考):

方法二:要摒弃“主观感觉”,去用全量化的测试集说话
验收AI产品,绝对不能靠几个零散的demo。我们一定要靠全量化、可复现的测试集。
比如:在准备接入第三方API时,别光听网上说的生成速度有多快、计费有多便宜。我们要做的是直接建个包含上不同真实业务case的跑测表。把不同平台的出图效果、响应时间、解析失败的概率,一笔一笔列出来。
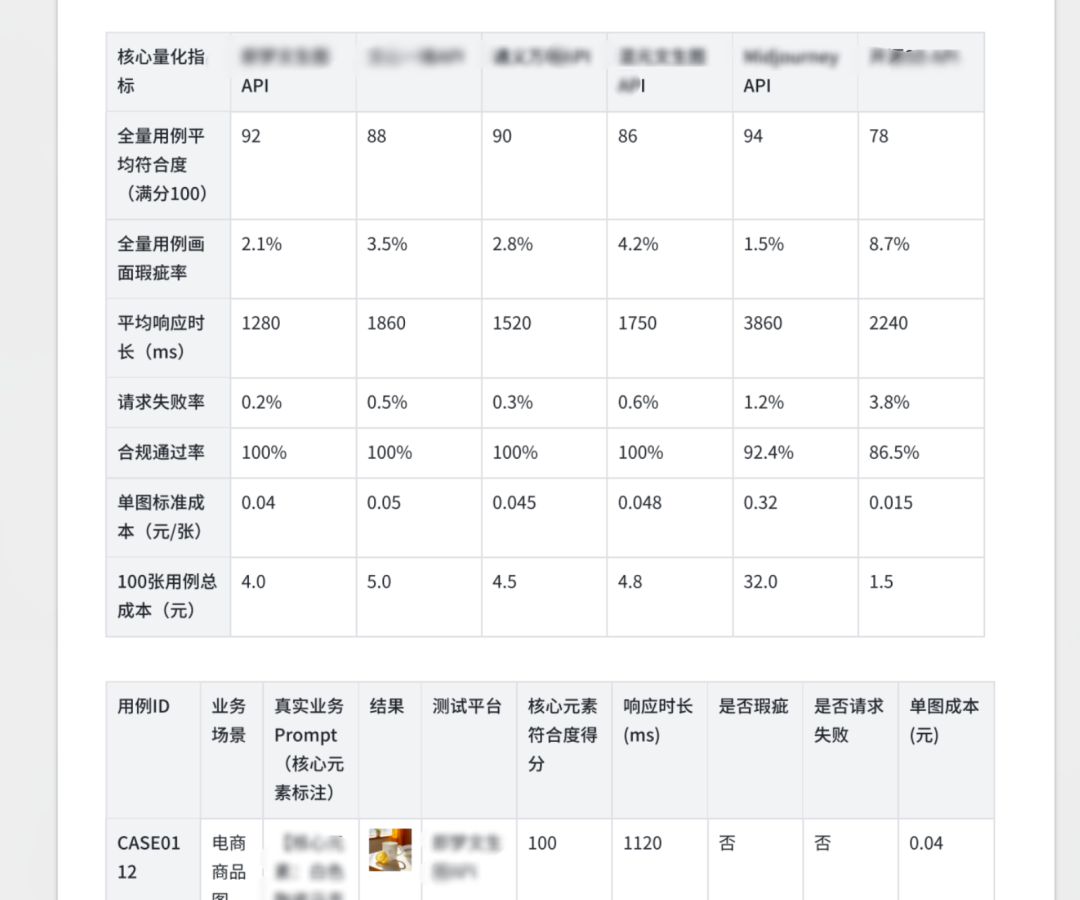
在提prd的时候,带上这样测试集。跟所有人定好规矩:我们不看单张图有多惊艳,我们要看的是这套测试集跑下来的综合达标率。设定一个及格线,比如90%,到了就可以算验收通过。
谁再拿一些极端的bad case来说,你就可以把测试集拿出来。
数据,才是终结主观争论的唯一武器。
制作测试集的方式如下(以个人工作场景为例,仅供参考):
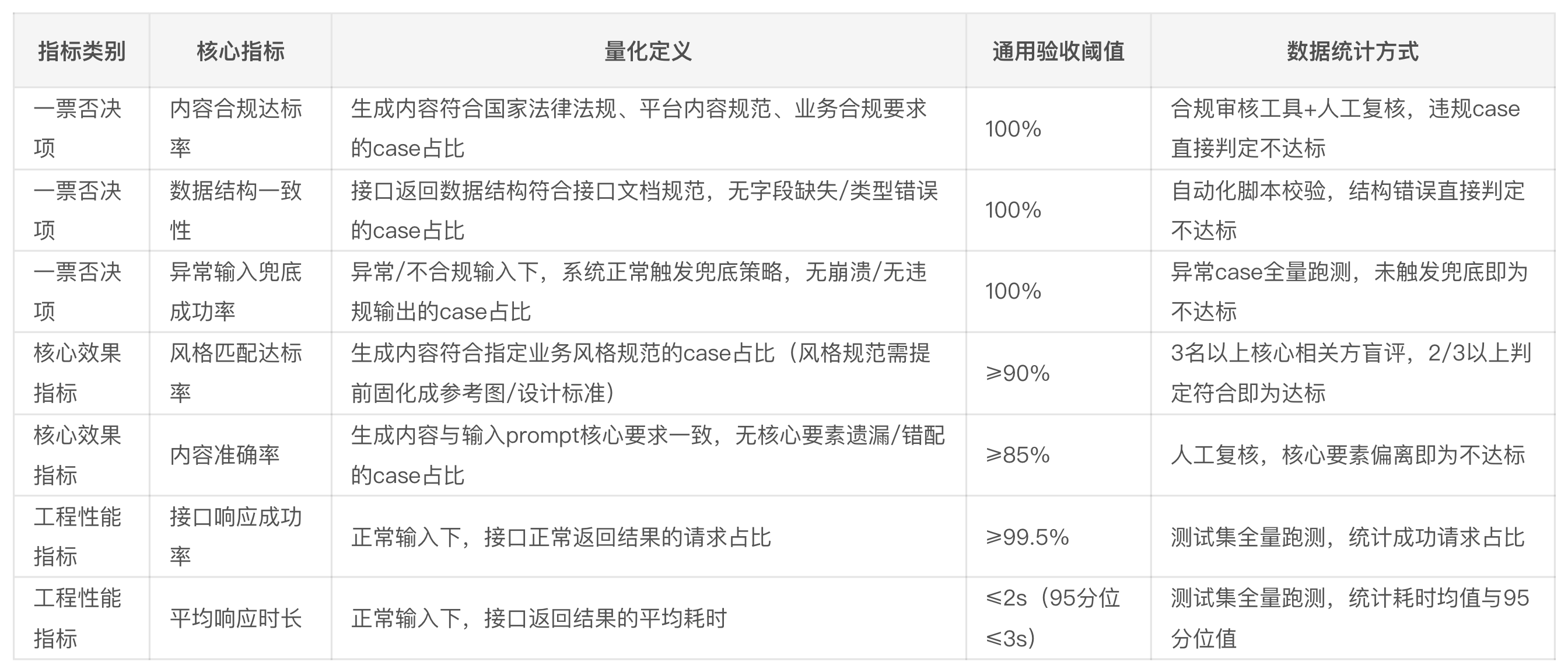
1.测试集构成:单场景测试集case数量≥100条,可遵循7:2:1黄金比例。
- 常规正向case:占比70%,从业务历史数据中提取,覆盖90%以上高频用户输入场景;
- 边界合规case:占比20%,覆盖低频但合规的输入场景,验证模型边界能力;
- 异常负向case:占比10%,覆盖违规、不合规输入场景,用于验证兜底能力,不纳入效果达标率计算。
2.固化规则:测试集必须在需求评审阶段同步确认,与所有相关方开会对齐,验收阶段严禁新增/修改case,尽量杜绝临时加测。
3.跑测规则:同一测试集、同一环境、同一参数下,连续跑测多轮,取平均值作为最终验收数据,规避掉单次跑测的概率性误差。
产品量化验收指标(以个人工作场景为例,仅供参考)
方法三:将权责前置,准备一套的“免责声明”
在AI产品工作中出了bug,大家的第一反应往往是:大模型又幻觉了,或者是产品逻辑没写清楚。
但实际,可能是前置的标注同学连命名都搞错的,“错误进”当然会导致“错误出”,所以肯定是不能算产品的缺陷的。
所以在验收标准里,我们需要把权责切分清晰,来便于归因。
我们要把失败场景分级。如果是用户输入的内容不合规、提示词严重违背常识,归因到“用户侧输入异常”。如果是API调用超时了,归因到“工程链路故障”。只有在输入标准、链路正常的情况下,输出的结果依然离谱,那才是“算法或策略缺陷”。
缺陷分级与归因划分清单如下(以个人工作场景为例,仅供参考)

最近也常常在想,一个合格的AI产品到底该是什么样?
也许我们不该只是一个写方案、拉会议、担责的工具人。在充满不确定性的AI里,我们更需要成为一个“信任体系的架构师”。
你制定这些看似冷酷的量化标准,不仅为了保护自己不背锅,也是在保护自己的项目和产品。在面对那些bad case时,不会去把用于探索的勇气消耗在无意义的内耗之中。
希望对你有些帮助~
本文由 @虫虫 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


