
 起点课堂会员权益
起点课堂会员权益决定AI产品生死的,不是算法,是产品经理的这个决策
AI产品的竞争,早在产品立项阶段就已经分出了高下。很多产品经理把精力放在功能交互、算法选型上,却忽视了一个更底层的问题:你的产品设计,能不能产生"有价值的数据"?这才是AI产品真正的护城河。

一、两款相似的AI产品,三年后命运截然不同
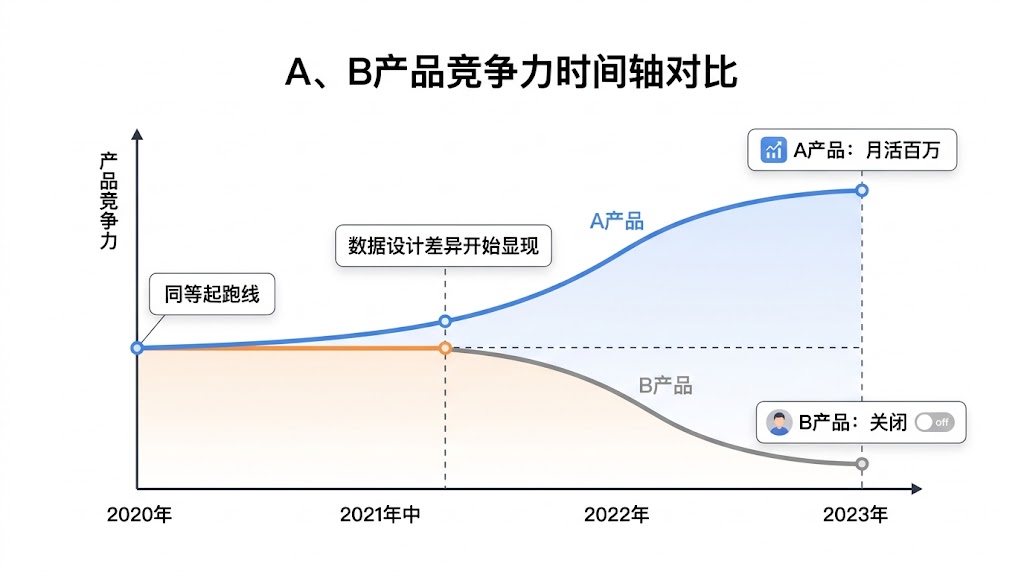
2020年,国内几乎同时出现了两款AI智能简历助手,我姑且称它们为A产品和B产品。
两款产品起点相似:都是帮求职者优化简历、匹配岗位的AI工具,初期用户体量差不多,融资规模也旗鼓相当,背后的算法团队实力相当。
三年后,A产品成为行业头部,月活破百万,还孵化出了招聘SaaS业务。B产品则悄悄关闭了,几乎没有激起任何水花。
是A产品的算法更好吗?不是,初期两者都用的是同类开源模型。
是A产品更会做市场推广吗?也不是,B产品一度比A产品更激进。
核心差异,出在产品设计的一个决策上。
A产品在设计之初就想清楚了一件事:简历优化工具最有价值的数据,不是”用户投了多少份简历”,而是**”哪些简历修改行为,对应了后续的面试邀请”**。于是他们把产品设计成了一个闭环:用户投递简历→跟踪后续面试结果→记录哪些修改带来了正向反馈→反哺推荐模型。
B产品呢?他们的数据埋点逻辑是传统的:”用户打开次数、使用时长、功能点击率。”这些数据能帮他们优化交互,但无法帮模型变得更聪明。
A产品积累的是有因果关系的训练数据,B产品积累的是没有闭环的行为日志。三年时间,这个差距被无限放大。
这个案例让我意识到:AI产品的竞争,在产品设计阶段就已经决定了胜负。 那个决定胜负的关键变量,叫做——数据设计。
二、什么是”数据设计”?大多数PM从没认真想过这个问题
“数据设计”不是数据分析,不是埋点方案,也不是BI报表。
它是指:在产品功能设计阶段,有意识地规划这个功能将产生什么数据、这些数据有没有训练价值、数据能不能形成壁垒。
打个比方。你是一名厨师,要做一道菜。数据分析是”分析这道菜好不好吃”;数据埋点是”在厨房里安装摄像头”;而数据设计,是”在建厨房之前,就规划好食材从哪里来、怎么储存、怎么加工”。
大多数PM会做前两件事,但很少认真做第三件。
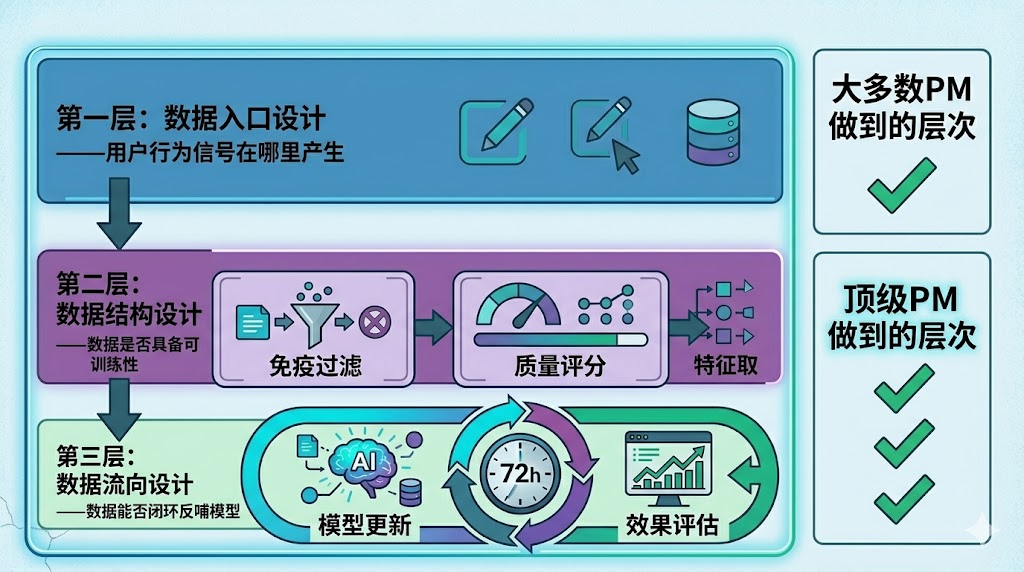
数据设计有三个核心层次,PM必须都想清楚:
第一层:数据从哪里来(数据入口设计) 你的产品功能是否会产生有意义的用户行为信号?用户的哪些操作,能反映他们真实的需求和判断?
第二层:数据长什么样(数据结构设计) 采集到的原始数据,是否具备可训练性?它是有标签的还是无标签的?是稀疏的还是稠密的?
第三层:数据能去哪里(数据流向设计) 这些数据最终能不能流回模型、形成反馈?还是采集了就躺在数据库里睡大觉?
三层都想清楚,才叫完整的数据设计。只做其中一层,是大多数PM的现状。
三、三个改变产品命运的数据设计决策
数据设计不是抽象的理念,它落地在产品经理每天都要做的功能决策上。以下三个决策点,决定了你的AI产品数据壁垒的高度。
决策一:你的产品”问用户”,还是”让用户做”?
这是数据设计最根本的分叉点。
“问用户”是指:通过调研问卷、评分弹窗、满意度打分来获取数据。这类数据看起来很直接,但有两个致命缺陷:第一,用户的表达和用户的真实行为往往是两回事;第二,这类数据量太少,很难驱动模型迭代。
“让用户做”是指:把数据采集内嵌在用户的自然操作流程中,用户的每一次使用行为本身就是数据。
以AI代码助手为例。GitHub Copilot的数据设计有一个极其聪明的地方:他们不只看”用户点了接受”,还会追踪”用户接受了AI建议之后,在接下来5分钟内有没有修改它”。如果用户接受之后马上修改,说明这条建议质量不高;如果用户接受之后直接提交,说明质量很好。这个行为序列给了模型非常精准的质量信号,而整个过程中用户什么都不需要额外做。
这就是“让用户做”的精髓:数据采集藏在用户价值里,用户毫无感知,但每一次操作都是高质量标注。
决策二:你设计的是”单次反馈”,还是”序列反馈”?
很多PM在设计数据采集逻辑时,只考虑”单次”:这次交互好不好,用户满意不满意。
但AI模型真正需要的,是序列信号——用户行为的前后文关系。
举个例子:某AI客服产品,只采集”用户是否点击了满意”。这是单次反馈。
但是,一个更聪明的设计是采集这样的序列:用户问了问题→AI给了答案→用户追问了(说明没答好)→AI给了第二个答案→用户结束对话(说明这次答好了)→整个对话链构成一条训练样本。
前者只知道”结果”,后者同时知道”哪一步出了问题”。对模型训练来说,后者的价值是前者的数十倍。
Netflix的推荐系统是这方面的经典案例。他们发现”用户评分”这个信号其实很脏——用户给的评分反映的是”用户认为应该喜欢”,而不是”用户真正喜欢”。所以Netflix更依赖”用户的观看行为序列”:看到哪里暂停了、第二天又继续看了、看到一半关掉了——这些序列信号,比评分准确得多。
单次反馈给你一个点,序列反馈给你一条路。想清楚你需要的是点还是路,决定了你能训练出什么样的模型。
决策三:你的数据是”可积累的”,还是”用完即弃的”?
这个决策决定了你的产品有没有时间维度的竞争优势。
可积累的数据,是指随着时间推移,数据价值会持续增长的数据。典型例子:用户的历史行为画像、专业领域的标注语料、用户与产品的长期交互记录。这类数据有”飞轮效应”——积累越多,模型越好,产品越好用,用户越多,数据积累越快。
用完即弃的数据,是指采集完成后就失去价值的数据。典型例子:实时流量数据、单次会话日志(没有串联)、没有标签的原始点击流。这类数据可以用来做运营监控,但无法构筑数据壁垒。
某医疗AI公司是反面案例。他们花了大量资源采集了数百万条患者问诊对话,但因为没有设计标注体系,这些数据全是无标签的文本,几乎无法用于模型精调。数百万条数据,价值几乎为零。后来他们花了比采集更多的成本回头补标注,白白浪费了两年时间。
采集之前先想清楚:这条数据,三年后还有价值吗?如果答案是“不确定”,那它大概率是用完即弃的。

四、当数据设计出错:三个代价惨重的真实案例
光说正面做法不够,再来看看数据设计失误会有多大代价。
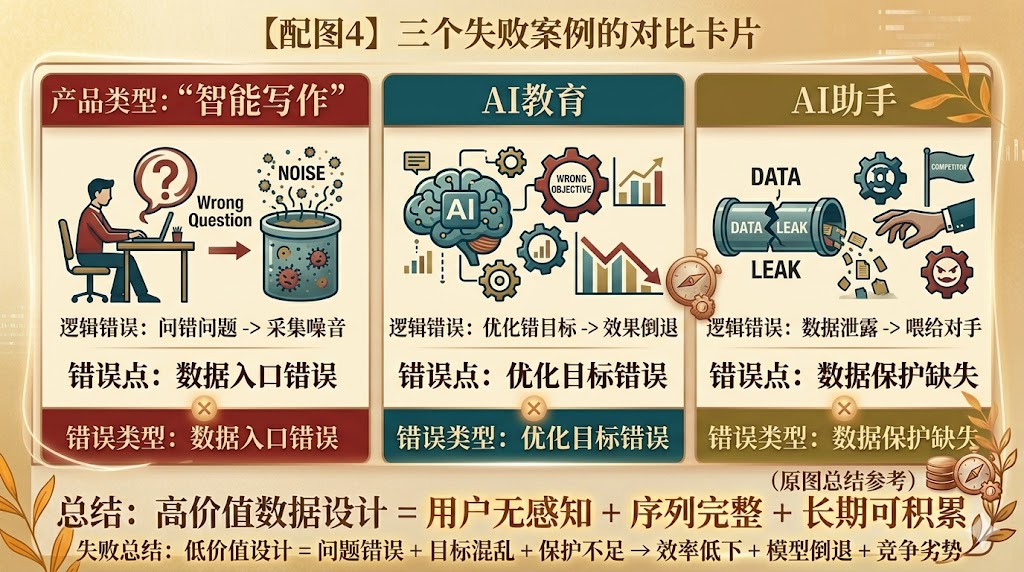
案例一:某智能写作工具,因为“问错了问题”白白浪费18个月
这个产品上线后,设计了一套”用户评分体系”:每次AI生成内容后,弹出1-5星评分。他们用这个评分数据训练模型整整18个月,但产品质量几乎没有提升。
原因很简单:用户给AI打分,打的是”这段内容和我期待的有多接近”,但因为用户自己也描述不清楚期待,评分高度随机。更糟糕的是,评分弹窗影响了用户体验,大量用户开始跳过,导致数据本身也有严重的选择性偏差——只有对结果特别满意或特别不满意的人才打分。
他们问错了问题,采集到的是噪音,而不是信号。
后来他们改变策略,转而追踪”用户对生成内容的具体修改行为”,三个月后模型质量开始显著提升。
案例二:某AI教育平台,把“完课率”当成核心数据,越优化越糟糕
这个平台用AI推荐学习路径,核心优化目标是”完课率”(用户完成课程的比例)。听起来很合理,但问题出现了:模型为了优化完课率,开始推荐最简单的课程——因为简单的课完成率高。结果是,用户确实都完课了,但完的都是没什么挑战性的内容,学习效果极差,用户很快流失。
他们采集了正确的数据,但优化了错误的目标。 数据设计不只是设计”采集什么”,还要设计”优化什么”——这两个问题必须同时想清楚。
案例三:某AI助手产品,数据被竞争对手“白嫖”
这个案例很特殊,但发人深省。某AI助手因为产品开放,用户反馈数据(包括对话日志)通过API大量流出,被竞争对手用于训练自己的模型。等他们意识到问题时,竞争对手已经用他们的数据完成了一轮模型迭代。
数据设计还包括数据的保护设计。 你辛苦采集的高质量数据,如果没有好的访问控制,可能会成为竞争对手的免费训练集。
五、PM的数据设计能力,如何在日常工作中培养?
说了这么多理论和案例,最后落到一个最实际的问题:作为产品经理,我该怎么做?
第一步:在每次需求评审时,加一个“数据维度”的灵魂发问。
每当你在评审一个新功能时,强制自己问三个问题:
- “这个功能上线后,会产生什么数据?”
- “这些数据,能不能用来训练或优化我们的模型?”
- “如果不能,我们能不能调整设计,让它产生更有价值的数据?”
把这三个问题变成需求文档的标配章节,刚开始可能会觉得多余,但坚持三个月,你对数据的直觉会发生质变。
第二步:学会区分“行为数据”和“偏好数据”,并优先设计前者。
行为数据是用户”做了什么”——点击、修改、停留、复购。偏好数据是用户”说他们喜欢什么”——评分、问卷、标签选择。
绝大多数情况下,行为数据比偏好数据更可靠、更有训练价值。在功能设计时,优先思考”如何让用户的自然行为成为数据”,而不是”如何让用户主动告诉我他们的偏好”。
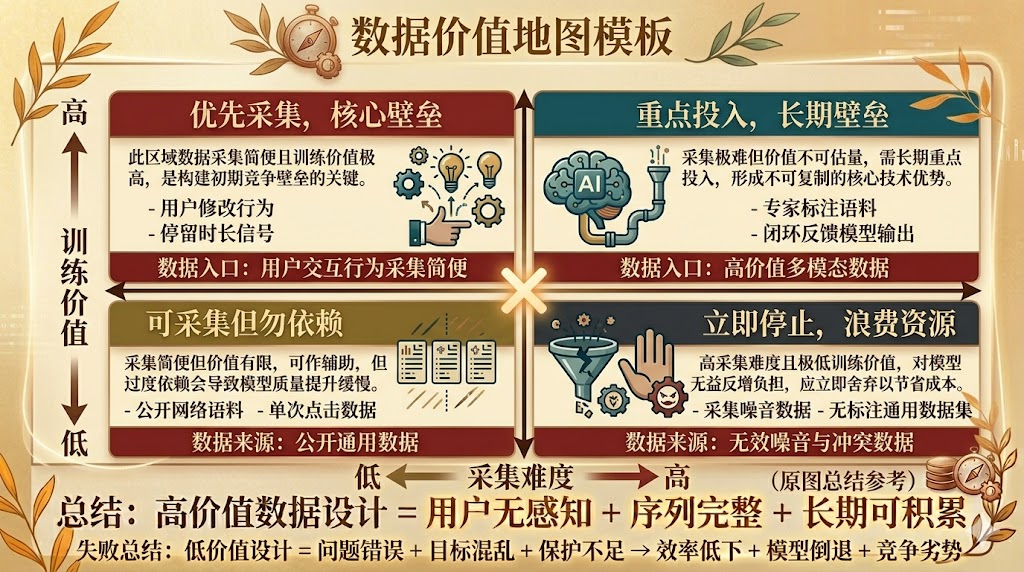
第三步:建立“数据价值地图”,定期复盘你的产品在采集什么。
每隔三个月,画一张表格:列出你的产品正在采集的所有数据类型,评估每一类数据的”训练价值”(高/中/低)和”积累趋势”(增长/平稳/衰减)。
这张表会给你很多意外发现:有些数据采集成本极高但训练价值极低;有些数据轻易可得却从未被利用。定期做这个复盘,是提升数据设计能力的最快路径之一。
六、结语:产品经理,是AI产品数据战争的第一决策人
我在做AI产品的这几年里,见过太多团队把精力放在错的地方:花几个月时间选算法框架,花大价钱买算力,花无数会议讨论模型架构——却从来没有认真坐下来想过:我们的产品,在产生什么样的数据?这些数据,能不能让我们的产品越来越聪明?
算法工程师可以选择更好的模型,数据工程师可以优化数据管道,但只有产品经理,才能在设计阶段决定产品能不能采集到有价值的数据。
这是一个只有PM才能做、也只有PM必须做好的决策。
AI产品的竞争,本质上是数据的竞争。而数据的竞争,在产品经理画第一张原型图的时候,就已经开始了。
本文由 @吴知 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议








AI产品竞争,数据设计才是核心,产品经理责任重大!