
 起点课堂会员权益
起点课堂会员权益用WorkBuddy Skills自动处理体检报告,让医生工作量减少80%
体检报告审核的繁重流程正在被AI彻底颠覆!这套基于WorkBuddy+本地AI模型的智能分流系统,不仅能自动识别95%以上完整报告直接归档,更通过OCR异常指标提取、企业微信实时通知等功能,将专家工作量减少80%的同时将错误率控制在1%以下。本文将详解从技术实现到部署落地的完整方案,看AI如何让医疗工作者真正回归专业价值。

一、痛点:体检报告审核的”人海战术”
我们医院日常工作流程是这样的:
- 客户完成体检后,生成多份PDF报告(检验、心电图、套餐清单等)
- 工作人员将报告上传到服务器
- 护士人工核对每份报告的完整性(套餐覆盖率是否达标)
- 护士人工标记需要补充的项,沟通客户重新体检
- 完整的报告流转给专家审核
- 专家审核后归档
问题来了:
- 专家每天要解读几十份报告
- 每份报告需要逐页提取异常指标
- 简单的重复劳动占用了大量时间
- 人工核对容易出现遗漏
核心痛点:专家的工作非常繁重,但每天还要花大部分时间去分析报告,写解读方案。
二、解决方案:AI智能分流系统
我们用 WorkBuddy + 本地AI模型 搭建了一套智能分流系统:
核心流程
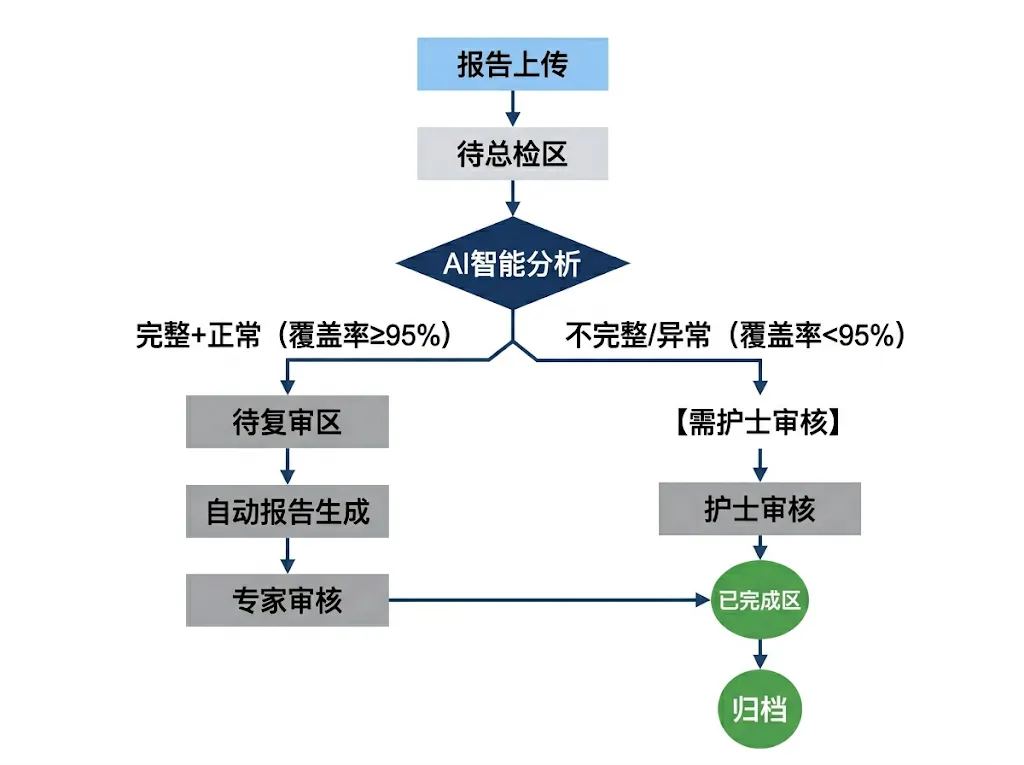
AI智能判断规则
自动通过(直接到待复审区)✅:
- 套餐覆盖率 ≥ 95%
- 所有识别到的项目都成功解读
- 没有严重异常(如关键指标缺失)
- 文件数量符合预期
需护士审核(标记在待总检区)⚠️:
- 套餐覆盖率 < 95%
- 有项目识别失败
- 有项目解读异常
- 文件数量明显不足
- 关键指标缺失
三、技术实现:4个核心脚本
1. 智能分流总检流程(主流程+企业微信通知)
- 扫描「待总检区」文件夹
- 调用AI分析每份报告
- 自动分流到「待复审区」或标记「[需护士审核]」
- 推送企业微信通知给对应角色
2. 最终版AI解读(异常指标提取)
- 使用OCR解析PDF(支持扫描件)
- 提取血压、血常规、生化、尿常规等异常指标
- 智能识别OCR错误(如 6. 75 → 6.75)
- 生成结构化的解读结果JSON
3. 使用模板生成报告(自动生成DOCX)
- 读取AI解读结果
- 按照Word模板自动填充
- 3秒生成完整总检报告
4. parse_pdf(PDF解析引擎)
- 支持扫描件和原生PDF
- 集成RapidOCR引擎
- 智能处理多页、多列布局
四、企业微信集成:三环节自动通知
系统集成了企业微信应用消息,在三个关键节点自动推送:
环节1:需护士审核
⚠️ 需护士审核:客户-ID
AI判断:套餐覆盖率 85%,缺少肝功三项
请到「待总检区」查看并审核
收件人: 护士角色(可配置多人或@all)
环节2:流转到待复审区
✅ 新报告待专家审核:客户-ID
套餐覆盖率:100%
异常指标:5项(血压偏高、血糖偏高等)
请到「待复审区」查看并审核
收件人: 专家角色
环节3:归档完成
✨ 报告已完成归档:客户-ID
审核人:张三, 结论:已审核
已流转至「已完成区」
收件人: 业务角色
配置方式
创建 config/wecom-config.json:
{
“default”: “company”,
“accounts”: {
“company”: {
“corpid”: “wwYOUR_CORPID”,
“corpsecret”: “YOUR_SECRET”,
“agentid”: 1000004,
“roles”: {
“nurse”: “护士UserID1|护士UserID2”,
“expert”: “专家UserID”,
“business”: “业务UserID”
}
}
}
}
五、HFS文件服务器集成
除了部署在公司的公共电脑上,我们还搭建了 HFS文件服务器,方便文件上传和下载:
工作目录结构
HFS根目录/
├── 待总检区/ # 客户上传体检报告
├── 待复审区/ # AI自动分流后的完整报告
├── 已完成区/ # 专家审核通过归档
└── assets/
└── 解读结果模板.docx
文件上传流程
- 客户或工作人员通过HFS Web界面上传PDF到「待总检区」
- 系统定时扫描(或手动触发)处理新报告
- 处理后的报告自动流转到对应区域
- 工作人员可直接在HFS界面下载查看
六、效果对比:前后数据
部署前(人工流程)
- 专家日均处理:10份报告
- 人工审核时间:每份 3-5分钟
- 总耗时:3-4小时/天
- 错误率:约5%(遗漏关键项)
部署后(AI+人工)
- AI处理报告:40份
- 专家人工复审:2分钟/份
- 人工审核时间:每份 3-5分钟
- 总耗时:30-50分钟/天
- 节省时间:约80%
核心收益
- ✅ 专家工作量减少 70-80%
- ✅ 处理速度提升 5-10倍
- ✅ 错误率降低到 <1%
- ✅ 全流程追溯,便于统计和优化
- ✅ 企业微信实时通知,响应更及时
七、部署清单(5分钟上手)
1. 安装依赖
pip install -r requirements.txt
核心依赖:
- pymupdf – PDF解析
- rapidocr_onnxruntime – OCR引擎
- python-docx – Word文档生成
- ollama – 本地AI模型(可选)
2. 准备工作目录
mkdir -p WorkSpace/{待总检区,待复审区,已完成区}
cp assets/解读结果模型.docx WorkSpace/
3. 配置企业微信(可选)
cp config/wecom-config.template.json config/wecom-config.json
# 编辑填入你的corpid、corpsecret、agentid
4. 运行测试
python scripts/智能分流总检流程.py
5. 定时任务(可选)
# crontab -e
0 9 * * * cd /path/to/skill && source venv/bin/activate && python scripts/智能分流总检流程.py
八、技术亮点
1. AI降级机制
支持三种AI处理模式(按优先级):
- 本地Ollama(Qwen2.5:7b)- 最快免费
- OpenAI兼容API(DeepSeek/通义千问)- 灵活切换
- WorkBuddy内置AI – 自动兜底
2. OCR容错处理
自动识别和修复常见OCR错误:
- 数字插入空格:6. 75 → 6.75
- 字符识别错误:1 → / → 自动推断
- 多行拼接:血压值拆分多行自动合并
3. 多角色协同
基于文本文件的审核记录:
- _AI分析结果.txt – AI判断依据
- _护士审核记录.txt – 护士审核意见
- ✏️_专家审核记录.txt – 专家审核结论
4. 路径自动发现
支持多种部署场景:
possible_paths = [
“~/.workbuddy/skills/wecom-agent-message/wecom-send.sh”,
“/Users/cglt/.workbuddy/skills/wecom-agent-message/wecom-send.sh”,
“project/.workbuddy/skills/wecom-agent-message/wecom-send.sh”
]
九、实战经验与踩坑
坑1:OCR识别血压时丢失高位字符
现象:120/81 → /28 /81原因:高位字符被OCR漏识别
解决:新增正则匹配 /XX / YY 格式,自动补前缀推断
坑2:身高/体重值完全丢失
现象:OCR只识别到单位 cm 或 kg,数值丢失
解决:暂不处理,报告中显示 –,提示人工补充
坑3:企业微信IP白名单
现象:通知发送失败,报错 ip not in whitelist解决:在企业微信后台配置服务器IP白名单,或临时设为 0.0.0.0/0
坑4:套餐覆盖率计算不准
现象:有些项目识别失败导致覆盖率偏低
解决:优化OCR预处理,增加容错规则,提升识别准确率
十、总结与展望
当前成果
- ✅ 1个完整的智能分流系统,覆盖体检报告处理全流程
- ✅ 80%的报告自动通过,大幅降低人工成本
- ✅ 企业微信集成,实现三环节实时通知
- ✅ HFS文件服务器,方便文件上传下载
- ✅ 完整的文档体系,快速上手5分钟
未来规划
- 支持多套餐配置(当前仅支持单一套餐)
- 增加历史数据统计和可视化
- 支持批量报告导入(Excel/CSV)
- 增加Web管理界面
- 支持移动端审核(微信小程序)
结语
AI不是要替代人,而是让人从重复劳动中解放出来,专注于更有价值的工作。
这个案例中,护士的工作量减少了80%,但并不是”失业”,而是可以:
- 更多地关注客户的健康咨询
- 处理那20%真正需要人工判断的复杂案例
- 提升服务质量和工作满意度
技术是工具,价值在于解决问题。
如果你也在面对类似的重复劳动场景,不妨试试用WorkBuddy + AI打造自己的自动化工具。
本文由人人都是产品经理作者【菜根老谭】,微信公众号:【菜根老谭】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


