
 起点课堂会员权益
起点课堂会员权益做 AI 竞品分析失败了:一次被 Bug 和需求膨胀拖垮的尝试
AI竞品分析工具的探索之旅充满技术与成本的双重挑战。从多模态识别到RAG增强生成,开发者投入200多元却最终折戟于复杂的产品化陷阱。本文将深度复盘这场失败的实验,揭示从简洁技术栈到臃肿业务系统的致命转折,为AI产品落地提供血泪教训。

狂砸了 200 多块钱的 Claude API 调用费,结果最终还是失败了。非常心痛,于是写下这篇文章。总要有点收获,不能钱砸进去之后,什么都没剩下。
1. 最初的设想与技术链路
刚开始我对 AI 竞品分析的设想非常简单:输入一个目标链接,系统自动分析页面内容,并按照固定的 Prompt 输出一篇结构化的竞品分析报告。
为了实现这个闭环,我设计了一条包含多节点的处理链路:
- 信息抓取(爬虫脚本): 拆分为两个独立的脚本执行。一个专门负责对网页进行全局截图;另一个负责把网页里的 HTML 源码和全量文本提取出来。
- 多模态识别(VLM Agent): 引入视觉模型,对第一步抓取到的网页截图进行识别,将图片中的视觉信息转化为文本描述。
- 数据清洗(Clean Agent): 负责处理乱序文本,将 HTML 源码里无用的标签和乱七八糟的冗余代码全部清洗掉,只保留干净的纯文本数据。
- 报告生成(Generator Agent): 将压缩后的截图与清洗后的纯文本,一并交给负责撰写分析报告的 Agent 进行归纳输出。
- 审查与兜底(Review Agent): 这是解决“AI 幻觉”和信任问题的核心机制。报告写完后,由审查 Agent 将生成的文字与原始图片及内容进行交叉验证,核实内容是否基于事实。如果不合格直接打回重写,设置重试上限为 3 次。如果 3 次后仍不达标,则在最终报告上明确标记“置信度较低”。
为了控制成本(省 Token)和提升效果,我在链路中应用了明确的工程策略:
- 图片压缩: 截图直接丢给模型非常消耗 Token,必须在前端先进行压缩处理。
- 模型路由(大模型分发): 不同任务调用不同能力的大模型。多模态识别、报告生成和最终审查,调用能力强、价格高的模型以保证质量;而数据清洗这种机械工作,则分配给便宜的“小模型”处理。
- 结构化输出控制(Prompt Engineering): 为了保证不同 Agent 之间数据传递的稳定性,我放弃了让模型输出自然语言长文,而是通过 Few-Shot(少样本提示)和明确的 Prompt 约束,强制“报告生成 Agent”以严格的 JSON 格式(如包含核心功能、定价、目标客群等字段)输出。这使得下游的“审查 Agent”能够进行字段级的精准核对,而不是在长篇大论中迷失。
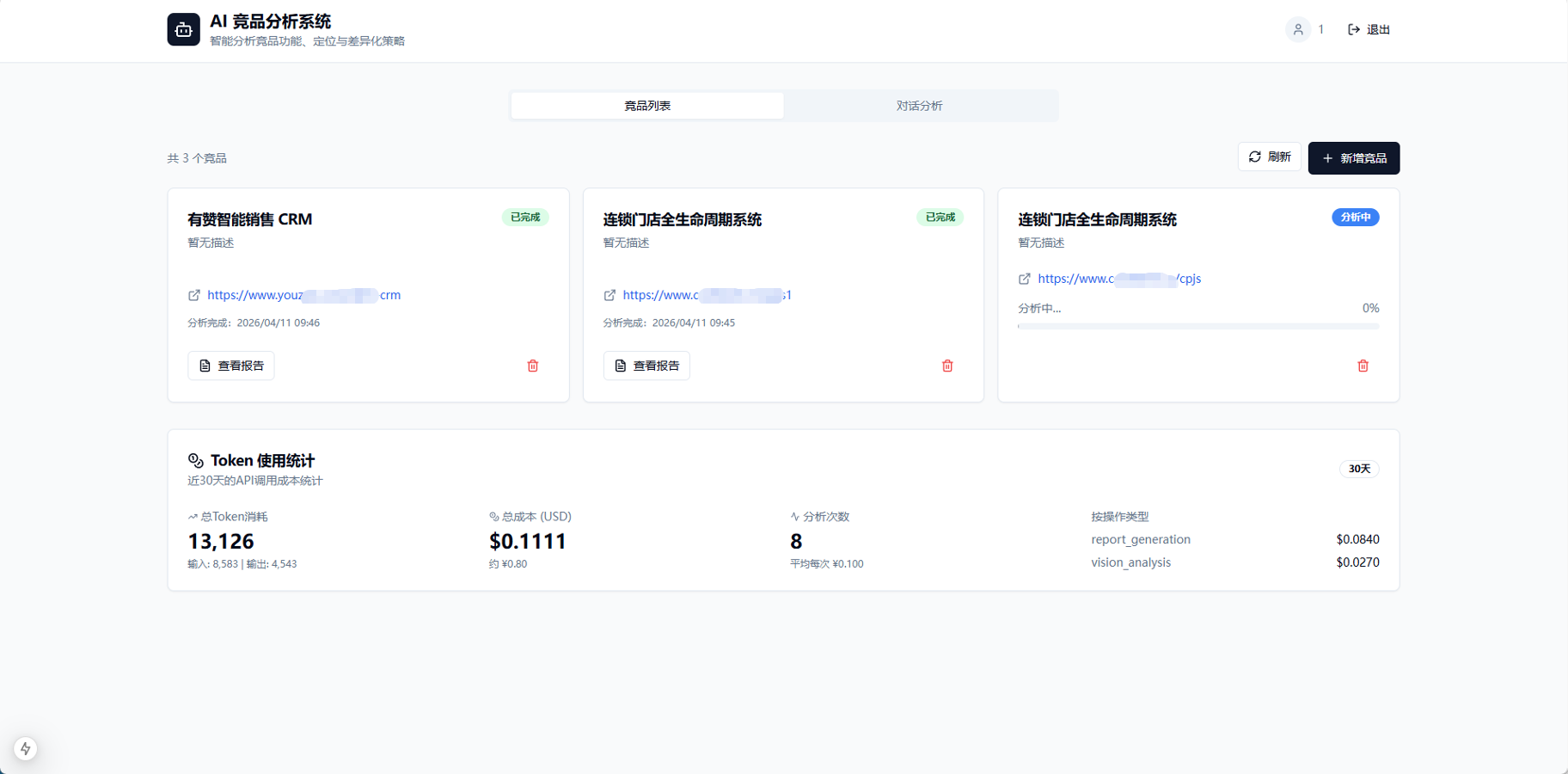
2. 增加复杂度的转向:引入 RAG
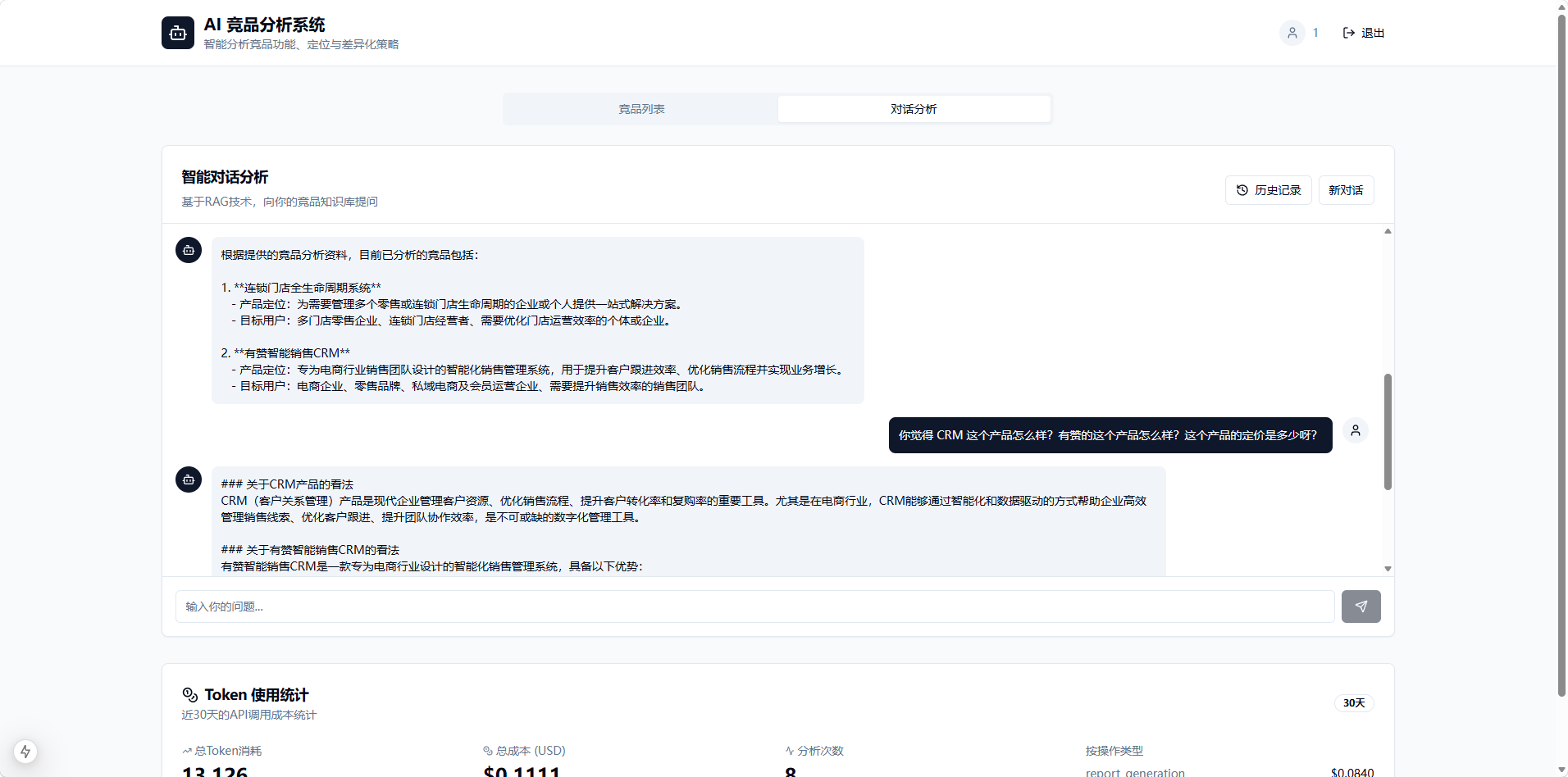
后来我觉得,如果作为日常使用的工具,每次都要盯着长篇幅的分析文档看,效率太低。最符合直觉的交互应该是“问答”——等系统分析完,我直接就我关心的细节提问。
于是,我决定在产品里引入 RAG(检索增强生成):
- 向量化存储: 竞品分析报告生成后,直接转化为向量(Embedding),存入向量数据库中。这里的切片策略定为 800 字一切块,保留 10% 的重合度,以保证上下文的语义关联性。
- 检索与问答: 前端提问时,系统将当前问题与历史对话作为上下文一并发给向量数据库,按相关性优先级排序召回片段,最后由大模型总结并回答。单纯这一步的开发成本其实并不高。
3. 噩梦的开始:陷入伪需求与 Bug 丛林
但正是由于加入了问答机制和想要“产品化”的冲动,各种不顺利接踵而至,场景复杂度直线上升。
- 逻辑漏洞与边界情况: 问答功能极度依赖意图识别。如果我问了与竞品无关的问题,系统需要专门的逻辑去拦截处理;如果我问的是数据库里还没有抓取过的竞品,Agent 也得准确识别并返回“库中暂无该数据”。想把这些边界情况处理得足够智能化,工程量非常大。
- 需求膨胀与业务系统: 我想把它做成一个完整的 SaaS 产品部署上线给朋友们用,就必须做账号登录注册、多租户的数据隔离。不同的账户登录,看到的报告和问答记录必须完全独立。此外,还得做一套 Token 消费的账单计费系统。
- 被边缘功能拖垮: 结果是,系统淹没在了 Bug 里。最开始,我用 Gradio(一个专门做 Python Demo 的框架)搭 MVP 的核心逻辑,一天不到就跑通了。但后来为了优化 UI 界面、做成真正的产品,我把前端重构成了 Next.js + React,接着开始加账号、账单、数据隔离这些外围系统。为了修这些边缘业务的 Bug,我花了整整三天,且依然报错不断。
这已经彻底背离了我最初“用 AI 节省时间成本”的初衷。
4. 反思与总结
最终我选择果断放弃。开发 AI 核心业务逻辑连 50 块钱都没花到,但修周边系统的 Bug 却消耗了三倍以上的金钱和精力,关键是还没修好。
虽然心痛,但也算交了学费。如果让我重新操盘这个项目,我会摒弃掉所有花哨的技术堆砌,完全从实用主义和成本角度出发。
如果是个人或小团队的提效工具,其实只需要做透两件事:
- 初次基建: 抓取网站原始信息,生成一篇高质量的基线竞品分析报告。
- 定期追踪: 定期(如每周/每月)执行抓取,结合原始资料和上一次的报告,专注输出“对比分析”(明确指出了增加了什么新功能、修改了什么核心文案)。
这就足够解决业务痛点了。至于 RAG 问答、复杂的多账户系统,在项目早期根本不是核心需求,纯粹是锦上添花的负担。
本文由 @巅魂 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









vibe coding做项目本质上和对话一样,只要轮数够多一旦开始出现幻觉就没办法往回拉了,只能推倒重来。
对,第一回就死在这上。不过今天重做上线了,有个小技巧分享一下:和AI对话功能点逐个测试,通过了再测下一个功能点,确保在后端逻辑跑通,然后再测前端,甚至这时候再让Claude基于后端重写前端也行