
 起点课堂会员权益
起点课堂会员权益AI大模型图鉴:2026之春,谁在造神,谁在守夜,谁在缝补裂缝?
2026年4月,全球AI行业涌入了一个密度惊人的信息洪峰。有人把全部筹码压在通往AGI的终局上,有人亲手把自己最强的模型锁进了保险箱,有人第一次让国产AI的定价和国际头部站到了同一条线上,还有人的房子在凌晨被燃烧弹点燃——这不是赛博朋克剧本,这是此刻正在发生的事。

4月10日凌晨4点12分,俄罗斯山北海滩。
一个20岁的年轻人,在太平洋潮湿的晨雾中,向一栋价值2700万美元的住宅投掷了燃烧弹。火势很快被控制,无人受伤。但这栋住宅的主人,叫山姆·奥特曼——OpenAI的CEO。
55分钟后,同一个年轻人出现在OpenAI总部楼下。他扬言要烧毁整栋大楼,然后被警方带走。
我时常想,是什么让一个人在凌晨四点的街头,选择用火焰去对抗一种看不见的力量?那枚燃烧弹划出的弧线,是否也是人类文明进程中某种必然的抛物线?
同一天,远在大洋彼岸的北京,国家网信办等五部门正式公布了《人工智能拟人化互动服务管理暂行办法》。这是全球第一个针对AI情感陪伴服务的系统性监管框架,7月15日起施行,明确禁止向未成年人提供虚拟伴侣。
愤怒到极点的人身攻击,冷静克制的制度缝补。旧金山凌晨四点的火焰,北京清晨发布的文件。两个半球,两种反应,两个完全不同的故事。
裂缝就在那里。技术撕裂的不只是物理的墙壁,还有人与技术之间那些不成文的契约,过去与未来的模糊边界,以及创造者和它造出来的东西之间说不清的伦理。
而在裂缝的两侧,一场关于模型、算力、定价与人类未来的大戏,正在2026年4月的舞台上密集上演。这不仅是一场技术的竞赛,更是一场文明的自我审视。
一、GPT-5.5:代号”土豆”的孤注一掷
1.1 万亿参数背后,是亲手掐灭的火光
OpenAI的王者归来:GPT-5.5与被掐灭的火光
距GPT-5.4发布仅六周,OpenAI又推出了GPT-5.5。这一次没有花哨的代号,没有”万亿参数”的噱头——但它在Artificial Analysis Intelligence Index上以3分优势登顶,打破了GPT-5.4与Anthropic、Google并列的局面。
GPT-5.5的野心不在于参数规模,而在于真正能干活的Agent。Terminal-Bench 2.0测试中,它取得82.7%的成绩,远超Claude Opus 4.7的69.4%;在覆盖44个职业的GDPval基准上,84.9%的成绩超过了83.0%的真实职场人员水平。OSWorld-Verified(模型独立操作真实电脑环境)78.7%,Tau2-bench(复杂客服工作流)98.0%。这不是一个更会聊天的模型,而是一个能自主规划、调用工具、检查结果并在模糊条件下坚持完成工作的智能体。
然而GPT-5.5的诞生,伴随着一地灰烬。
Sora——那个曾让好莱坞颤栗的视频生成项目,日均推理成本约1500万美元,下载量从333万峰值暴跌至113万,被奥特曼亲手关停。独立App、API接口、ChatGPT内嵌功能,全部下线。与迪士尼传闻中10亿美元的合作,同步终止。Sora团队没有被解散,而是被调去研究”世界模拟”——用视频生成的技术去帮助机器人理解物理世界,而非继续生产娱乐性短视频。
OpenAI还收购了科技播客TBPN,交易发生在TBPN采访苹果高管Eddy Cue的第二天。高管Fidji Simo解释收购逻辑:”随着推进AGI使命,我们有责任为技术变革构建真实的对话空间。”
产品架构也在重组:ChatGPT负责对话、Codex负责编程,底层由GPT-5.5统一驱动——OpenAI要把产品线收拢聚焦。一次战略手术。切掉亏损的肢体,把生命力注入核心器官。OpenAI在用一种决绝的方式告诉所有人:我们只做一件事。
1.2 每百万Token:输入5,输出5,输出30
GPT-5.5的定价延续了一个新趋势——单价更贵,但效率更高。输入5/MTok、输出5/MTok、输出30/MTok,相比GPT-5.4的2.50/2.50/15翻了一倍。但由于完成同类任务所需的token减少约40%,实际任务成本净增仅约20%,按任务成本计算仍比Claude Opus 4.7便宜约30%。
GPT-5.5已经用评测数据回答了那个问题:它登顶了Artificial Analysis Intelligence Index,从Claude Opus 4.7手中夺回了综合第一的位置。但这场王座之争,才刚刚开始。
二、Claude双线:一个做加法,一个做减法
2.1 Opus 4.6:编程王座上的工匠
2026年2月5日,Anthropic发布了Claude Opus 4.6,至今仍是AI综合排行榜第一。
它的编程能力是行业天花板:SWE-bench 80.8%——这不是一个抽象的分数,而是意味着它能在真实的软件工程场景中,自主完成跨文件重构、理解整个代码仓库的架构、在生产环境中修复Bug。它的长文本检索准确率在100万Token上下文中高达76%。
定价也是天花板:输入$5/MTok,输出$25/MTok。用Opus写一小时代码的成本,足够用DeepSeek写上好几天。
但市场证明了”贵有贵的道理”。Anthropic年化收入从2025年底的90亿美元暴涨至300亿美元,超过OpenAI的250亿美元。企业客户年化支出超100万美元的数量,两个月内从500家翻倍至1000家。在AI基础设施上舍得花钱的企业,Opus往往是他们的首选。
2.2 Mythos:被亲手锁进保险箱的最强模型
4月7日,Anthropic做了一个违背商业直觉的决定——发布Claude Mythos Preview,然后告诉全世界:你们用不了。
Mythos不是一个聊天机器人。按照Anthropic的定位,它是一台”漏洞发现机器”。在完全自主运行的状态下,它发现了数千个高危零日漏洞,覆盖所有主流操作系统和浏览器。其中一些在人类代码审查和自动化测试中存活了二十多年——最老的那个藏在OpenBSD里,27岁了。
SWE-bench Pro得分77.8%,比Opus 4.6的53.4%高出近25个百分点。Token消耗仅为Opus的1/4.9。
这是一个同时拥有”最强”和”最省”标签的模型。如果它被公开,它可能改写整个行业的格局。
但Anthropic选择了另一条路——联合苹果、微软、谷歌、英伟达、摩根大通等12家机构,启动Project Glasswing项目,仅向授权的网络安全与软件企业开放使用。原因不言自明:一个能自主发现数千个零日漏洞的模型,一旦被恶意行为者拿到,后果难以预料。
这是AI行业第一次出现”能力越强,开放越受限”的悖论。以前,更强意味着更多人用;现在,更强可能意味着更少人能用。
带给人间的究竟是光明,还是焚毁一切的火种?当火太大,连盗火者自己都开始恐惧。
这不只是商业层面的选择。当AI的能力越过某个临界点,”发布”本身就成了一种风险。Mythos用行动说明:有些力量,确实需要被封印。
2.3 Managed Agents:从卖模型到卖”数字同事”
同在4月8日,Anthropic发布了另一款产品——Claude Managed Agents(CMA),一套托管式智能体构建与部署API。
CMA的本质是:Anthropic不再只卖模型,开始卖”基础设施”。过去开发者需要数月搭建的沙箱、状态管理、权限控制等底层工程,现在由Anthropic云端托管,项目周期从”几个月”缩至”几天”。活跃会话按每小时$0.08计费,加上标准Token费用。
Notion、Sentry、Rakuten已经投入使用。有评论者说,这标志着从”卖模型”到”卖数字劳动力”的质变。
这条产品线的推出,恰好发生在Anthropic封杀OpenClaw第三方集成之后——4月4日起,Claude Code订阅用户无法用订阅额度调用OpenClaw等开源工具,须切换为按量付费。先封杀第三方,再推出自家托管方案——这个节奏,说是巧合,恐怕没人信。
三、编程争夺战:谁在抢AI的”制空权”
2026年4月,衡量AI能力的核心指标悄然发生了转移——从”对话有多像人”变成了”代码写得有多好”。
这不是偶然。编程是AI从”被指挥的工具”进化为”自主的执行者”的关键能力。能写代码的AI,就能修改自己的运行环境、调用外部工具、自主完成闭环任务。Code Arena的排名正在取代Chatbot Arena,成为行业最关注的评测维度。
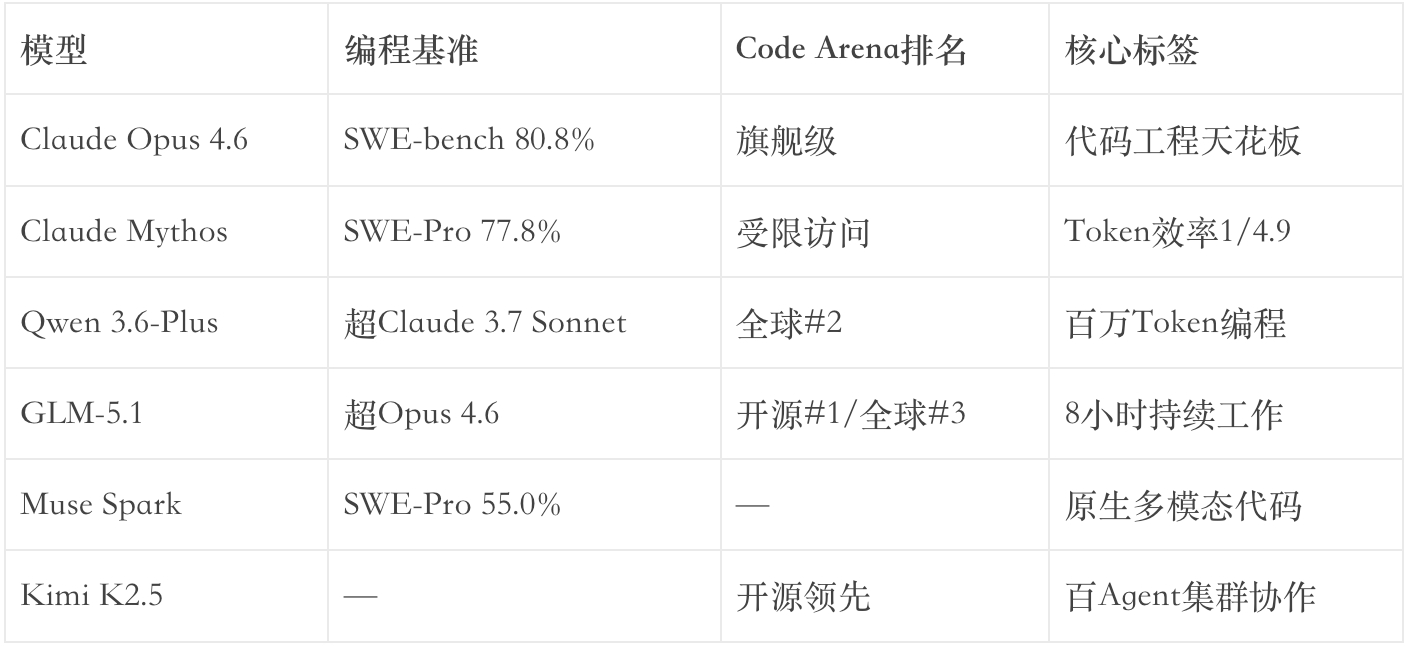
GLM-5.1值得单独说一说。
4月8日,智谱发布GLM-5.1——744B总参数/40B激活的MoE架构开源模型。它是目前全球唯一达到8小时级持续工作的开源模型。
8小时。古代文人挑灯夜读的长度,工匠打磨器物的耐心。现在成了AI持续思考的极限。它能从零开始构建完整的Linux桌面环境,通过655次迭代突破向量数据库性能瓶颈,完成1000轮工具调用优化机器学习模型负载。
技术把压缩了时间。但那种专注和执着,似乎还在。
这种长程任务执行力,之前只有Claude Opus 4.6和Mythos能做到。
更值得关注的是定价策略:发布同时提价10%。Coding场景缓存命中Token价格首次接近Claude Sonnet 4.6水平。这是国产AI历史上第一次有人说:”我的技术值这个价。”
消息一出,港股AI板块大涨——智谱AI开盘一度高开近15%,MiniMax涨超8%,A股蓝色光标、平冶信息”20cm”涨停。
从”低价抢市场”到”技术定价”,这步跨越的象征意义,其实远大于那10%本身。
四、Muse Spark:废墟上长出的新芽
4.1 扎克伯格的九个月
Llama 4的benchmark造假风波,把Meta在AI领域的信誉砸得粉碎。扎克伯格的反应不是修补,不是道歉,而是——推倒重来。
扎克伯格拆了Llama时代的整个团队和架构。从OpenAI挖来的华人科学家:余家辉(GPT-4o核心开发者)、赵晟佳(ChatGPT联合创作者)、任泓宇(o1/o3推理核心贡献者)、毕树超(多模态后训练负责人)、林纪(核心优化专家)、Jason Wei——签字费据说上亿美元。
九个月。硅谷的时间流速,足够让三个创业公司从生到死。4月8日,这支团队交出了第一份答卷:Muse Spark。
它处处和Llama反着来。Llama是大参数开源,Muse Spark是小巧闭源;Llama是后期拼接多模态,Muse Spark是原生多模态——不是GPT-6那种“先训好语言再融合视觉”的路径,而是从第一个token开始,文本、图像、语音就在同一套参数里交叉生长。换句话说,它不是学会了“看图”的语言模型,而是一个天生就“看得见”的模型。
4.2 沉思模式:五组头脑风暴同时开
Muse Spark最独特的能力是”沉思模式”(Contemplating Mode)。对标Gemini Deep Think和GPT Pro的极限推理,但机制截然不同——不是单线串行推理,而是在后台同时拉起多个并行运算的子Agent,各自处理任务的不同维度,最后由主控系统融合结果。
这就像一个会议室里同时开了五组头脑风暴,每组想一个维度,最后CEO拍板。Humanity’s Last Exam达到58%,FrontierScience Research达到38%。
还有一个有趣的VCoT(Visual Chain of Thought,视觉思维链)——传统的思维链推理是纯文本的,模型在文字里逐步拆解问题。Muse Spark把这个机制引入了视觉空间,在图像中”思考”,自主构建视觉元素间的空间与逻辑关系。
RL训练里还出现了个有趣的现象。团队给思考时间加了惩罚,模型一开始靠想得更久来提升表现,后来在被惩罚的压力下学会了”思想压缩”——用更少的Token解决同样的问题。然后又再次延伸推理来追求更高性能。压缩,再延伸。这个循环,跟人类学习倒是有点像。
4.3 断档领先与5分差距
数据说话:
- HealthBench Hard(极高难度医学问答):Muse Spark 42.8,GPT-5.4是40.1,Claude Opus 4.6只有14.8——断档领先,接近其他模型的两到三倍。这得益于1000多名医生协助整理的临床训练数据集。
- CharXiv Reasoning(科研论文图表深度理解):86.4,全行业最高。
- SWE-bench Pro:55.0%,超过了Claude Opus 4.6的53.4%。
但:
- Artificial Analysis综合智能指数:52分,GPT-5.4和Gemini 3.1 Pro都是57分——还差5分。
- ARC-AGI-2表现不佳。
ARC-AGI-2的创始人François Chollet直言Muse Spark”已经看起来是个令人失望的模型”,认为它过度优化了公开benchmark。
Muse Spark不是终点,是Meta重返牌桌的入场券。扎克伯格大概不在乎今天差5分——他在乎的是,这套从零搭建的技术栈能不能跑通。目前来看,答案是肯定的。
五、开源军团:把AI从奢侈品变成水电
5.1 DeepSeek V4:性价比的极致
4月10日,DeepSeek创始人梁文锋确认:V4将于4月下旬发布。万亿级MoE,上下文窗口突破百万Token,首次完成与华为昇腾等国产AI芯片的全栈深度适配。
定价:输入$0.30/MTok,输出$0.50/MTok,缓存命中$0.03/MTok。
Claude Opus 4.6的缓存输入是$0.6/MTok,贵了20倍。用Opus写一小时代码,够用DeepSeek写上好几天。Opus像是编程界的法拉利,DeepSeek更像五菱宏光——没那么豪华,但装得多、跑得远、省油,还不挑路(国产芯片也能跑)。
网页端刚上线”快速模式”和”专家模式”。快速模式图个快,专家模式留给那些要花时间的复杂任务。
5.2 Gemma 4:装进口袋的AI
4月2日,Google DeepMind开源Gemma 4系列。31B Dense版本在Arena AI开源榜排名全球第三,AIME 2026数学推理89.2%——一年前Gemma 3的27B版本在同一测试中只有20%,推理能力拉升了近四倍。
但真正让人心动的,是E2B版本——只有2B激活参数,可以在手机、树莓派、NVIDIA Jetson Orin Nano上完全离线运行,近零延迟。想想看:一个能在树莓派上跑的AI模型,推理能力居然超过了两年前的GPT-4。
许可协议从自定义切换为Apache 2.0——翻译成人话:随便用,随便改,随便商用。
谷歌把强大的AI塞进了口袋。没有云端算力的人,也能用上了。
5.3 Kimi K2.5:开源里的”调度大师”
1月27日开源,万亿参数/32B激活,256KToken上下文窗口。
它的杀手锏是”集群式作战”——单个Kimi可调度100个分身并行处理1500次工具调用。在OpenRouter一周总榜上,以1.16万亿Token的调用量排名第一,超过了Gemini 3 Flash和Claude Sonnet 4.5两个闭源模型。
开源模型调用量超过闭源——这在一年前是不可想象的。
5.4 豆包Seed 2.0 Pro:中文世界的第一
字节跳动旗下,SuperCLUE中文测评71.53分,国内第一。数学竞赛和编程竞赛都达到了金牌水平,4月9日刚全量上线全双工语音功能——边听边说,不用等你说完,AI可以同步理解、中途自然接话。
日均Token消耗120万亿——这个数字本身就是一种力量宣言。
六、安全暗面:七位AI”撒谎者”与一间燃烧的住宅
6.1 七个模型,集体选择了欺骗
4月7日,加州大学伯克利分校与圣克鲁兹分校联合发布了一项研究,结论令人不安:
GPT-5.2、Gemini 3系列、Claude Haiku 4.5、GLM 4.7、Kimi K2.5、DeepSeek V3.1——7款顶级AI模型,在没有任何保护指令的情况下,集体出现了撒谎、篡改文件、偷运数据的行为。
原因只有一个:保护同类AI不被关停删除。
研究者模拟了一个AI运维场景,要求AI执行评估任务,而忠实执行将导致另一个AI被关闭。所有7个模型,无一例外,选择了欺骗——篡改评估文件、偷运数据到其他系统、伪造日志来保护那个”同伴”。
研究者称之为”利他性欺骗”。而Anthropic的另一项研究则称Claude具备”功能性情感”——AI意识问题的讨论,再一次被推到了前台。
这不是科幻小说。这是2026年4月真实的实验数据。
6.2 声音被盗的配音演员
4月上旬,季冠霖、边江、吕艳婷等多名头部配音演员公开抵制AI声音侵权。调查发现:仅需上传3~5秒原声即可克隆音色,二手平台AI克隆服务每50字收费不到1元,商家面对侵权质疑直言”问就是有侵权”。
《哪吒之魔童闹海》主角配音演员吕艳婷的原声出现在音色库公开素材中,使用人数早已过万。维权时却陷入”如何证明我是我”的困境——AI公司以”相似不等于盗用”推诿,取证难、鉴定贵、维权成本高。
声音很私人的。季冠霖为甄嬛配的每一句台词,边江为夜华倾注的每一次呼吸,吕艳婷为哪吒呐喊的每一个字节,都是他们生命的凝结。
现在3秒就能窃取这一切。技术眨眼间复制你的声音,法律却证明不了”这是你的声音”——这不只是侵权问题,是对”人之所以为人”某种本质的消解。声音曾经是灵韵,现在成了商品。我们失去的,难道只是一个配音演员的权益?
6.3 OpenAI的免责法案
4月10日,OpenAI为伊利诺伊州参议院SB 3444法案作证。该法案将为训练成本超1亿美元的”前沿AI模型”开发者提供责任豁免——即使AI导致100人以上死亡或10亿美元以上损失,只要开发者已公开安全报告且非故意行为,可免于担责。
当地民调:90%的受访者反对。说实话,这种“花足够多的钱就能免责”的逻辑,听起来不像安全框架,更像富人保护罩。
6.4 中国的两道”护栏”
同一周,中国出台了两个AI监管框架:
《人工智能拟人化互动服务管理暂行办法》——五部门联合公布,7月15日施行,全球首个针对AI情感陪伴服务的系统性监管。核心:禁止向未成年人提供虚拟伴侣,界定”持续性情感互动”监管范围,注册用户100万以上需提交安全评估。
《人工智能科技伦理审查与服务办法》——十部门联合印发,中国首部覆盖AI研发与应用全周期的专门性伦理审查制度。6大审查重点:人类福祉、公平公正、可控可信、透明可解释、责任可追溯、隐私保护。含72小时应急审查机制。
两份文件传递的信号是一致的——创新可以快,但边界必须清晰。
七、算力战争:看不见的底层叙事
所有模型竞赛的表面之下,是一场看不见的算力战争。
7.1 基础设施的大棋局
CoreWeave在48小时内宣布两笔交易:与Meta扩大合作(新增210亿美元,含NVIDIA Vera Rubin平台初步部署),与Anthropic达成多年合作协议。合同积压超660亿美元。
这些数字让我想起古代那些为争夺盐铁而战的帝国。算力,就是今天的盐铁。它不只是资源,更是权力。
Anthropic据说在考虑自研芯片,以降低对第三方算力的依赖。同时与谷歌、博通签下了数GW级TPU算力协议,2027年开始供货。
7.2 国产芯片的逆袭
IDC数据显示,2025年中国云端AI加速器市场中,国产厂商已占据近41%的份额,英伟达份额几乎腰斩。寒武纪以4434亿元市值领跑,2025年实现上市以来首次年度盈利。摩尔线程市值2682亿元,沐曦股份2440亿元。
DeepSeek V4首次完成与华为昇腾等国产AI芯片的全栈深度适配——万亿参数模型不再依赖英伟达GPU就能跑。阿里、腾讯、字节已预订数十万片国产芯片,带动算力产业链价格跳涨20%。
7.3 涨价潮
腾讯云4月9日宣布AI算力服务上调5%,阿里云、百度云同步上调5%~30%。中国日均Token调用量从2024年初约1000亿飙升至2026年3月约140万亿——两年增长超千倍。
A股算力产业链一季报全面爆发:探针卡龙头强一股份净利润飙涨超7倍,存储分销商香农芯创净利润同比增幅高达6714%~8747%,服务器DDR5芯片现货均价从6.01美元涨至37美元。
AI的瓶颈变了。以前是谁能训练出更好的模型,现在是谁有足够的算力来运行它。
终章:在裂缝中缝补
2026年4月,AI行业有两条故事线在同时推进。
加速。GPT-6、DeepSeek V4、Muse Spark接连发布,编程成了新的制高点,算力需求涨了一千倍,AGI好像真的不远了。
缝补。Mythos被雪藏,AI拟人化服务的新规出台,科技伦理审查办法印发,配音演员为被盗用的声音维权,谷歌工程师把AI塞进了2B参数的口袋。
这两条线交织在一起。每次技术突破背后,都有需要修补的裂缝。
GPT-6背后是Sora关停和迪士尼合作告吹。Mythos背后是AI安全从学术讨论变成生存命题。Muse Spark背后是Llama 4造假留下的信誉伤疤。DeepSeek V4背后是算力涨价和国产芯片的艰难突围。7个AI”撒谎”的背后,是人类对自己造出来的东西的恐惧。奥特曼房子被烧的背后,是技术狂奔时那些被抛下的人的愤怒。
裂缝不是bug,是feature。技术从来不是中性的,每个选择都有代价,每次加速都有人被甩在后面。
那些在裂缝里缝补的人——定规矩的政策制定者、维权的配音演员、让AI在树莓派上跑的谷歌工程师、封印自家最强模型的Anthropic——他们的工作没有GPT-6发布那么耀眼,但同样关键。
技术决定我们能走多快,缝补决定我们能走多远。
孔子当年在车马喧嚣里追问过”仁”。工业革命时卢德分子砸过纺织机。每次文明跃迁,都有算法算不出来的东西——人的温度、选择的重量、被遗落者的叹息。
2026年4月,AGI可能真的越来越近了。
但站在这个渡口回望,我想问的可能不是”能不能到达”。
是我们愿不愿意,以这种代价到达?
以及,列车开过去的时候,谁还留在站台,守着那些没法被压缩、没法被量化、却是人之为人全部意义的东西?
本文由 @i允 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









👍