
 起点课堂会员权益
起点课堂会员权益全双工语音来了,AI 语音产品要重写一次交互逻辑
语音AI正在经历一场交互革命。Google的Gemini 3.1 Flash Live全球扩张与字节Seeduplex的发布,标志着语音产品从'半双工问答'向'全双工对话'的跨越。这次升级不仅是技术突破,更是产品逻辑的重构——如何优雅处理打断、多轮对话和环境噪音,将成为下一代语音助手的决胜点。

最近两周,语音 AI 有两个很值得产品人盯住的动作。
一个是 Google 在 2026年3月26日 发布 Gemini 3.1 Flash Live,并把 Search Live 扩展到 200+ 国家和地区。另一个是字节在 2026年4月9日 正式发布 Seeduplex,并宣布已在豆包 App 完整上线。
很多人会把这理解成一句很熟悉的话:语音更自然了。
但真正值得关注的不是“更像人”,而是语音产品的交互协议开始变了。过去的语音助手,本质上还是“你说完,我再说”的半双工逻辑;现在,全双工能力一旦成熟,系统就必须学会一边听、一边判断、一边回应,还要在噪音、停顿、插话和多轮上下文里保持稳定。
这不是前端小改版,而是一次产品层面的重写。
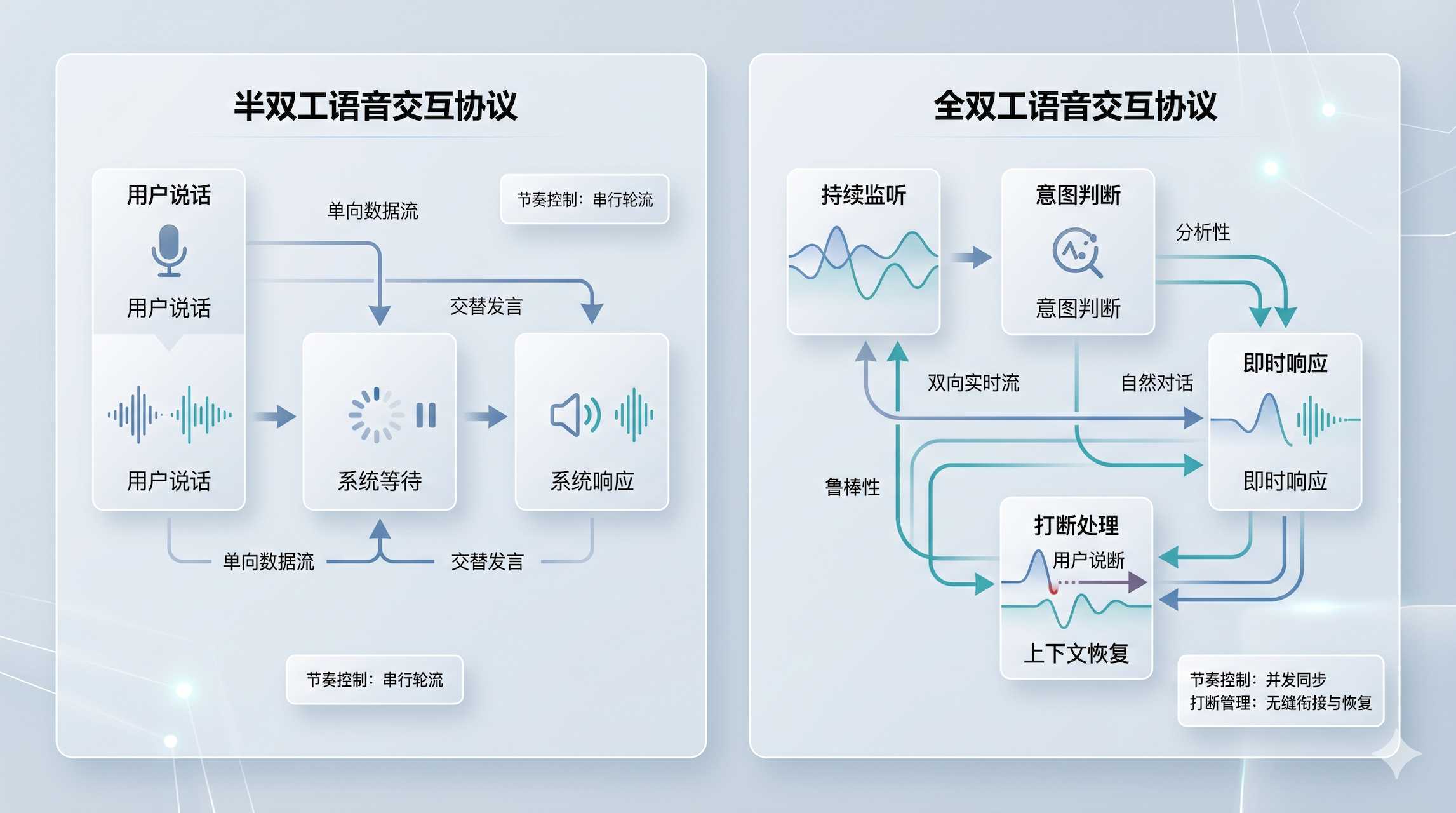
01 这不是模型升级,而是一次“回合制”被打破
过去的大多数语音产品,虽然名字叫“对话”,但本质上更像回合制问答。
用户说话,系统等结束;系统回复,用户再等待。这种机制的好处是简单,坏处也很明显:只要用户中途停顿、思考、改口,或者环境里多了别人的声音,系统就很容易误判。
字节这次披露的 Seeduplex,核心不是把声音做得更像真人,而是把“听”和“说”从串行变成并行。官方给出的几个信号很有代表性:复杂场景下误响应率和误打断率下降了一半,过早响应率下降了 40%,而且已经不是实验室 demo,而是在豆包里大规模上线。
这意味着什么?
意味着语音产品的竞争点,开始从“答案好不好”往“节奏对不对”迁移。谁更会掌握对话节奏,谁就更像一个真正可用的语音助手。
02 先被改写的,不是内容质量,而是“什么时候该等”
全双工能力出现后,第一个要重做的不是回答内容,而是等待逻辑。
用户在真实语音场景里,经常会有这些状态:想一想再说、说一半改口、边说边组织、突然停顿两秒、被别人打断后再接回来。半双工系统很容易把这些停顿理解成“你说完了”,然后抢答。
但在很多关键场景里,抢答本身就是体验灾难。
比如英语陪练,系统不该在用户卡壳时立刻补全;比如面试模拟,系统要分得清“思考停顿”和“回答结束”;再比如搜索或客服场景,用户常常边描述边补充条件,这时过早接话,只会让对话更碎。
所以,全双工语音时代,产品经理至少要重做三种状态判断:
第一,耐心等待。
第二,确认收尾后快速响应。
第三,识别到用户插入新意图时即时切换。
这已经不是一个 VAD 阈值问题,而是一个“语音节奏状态机”问题。
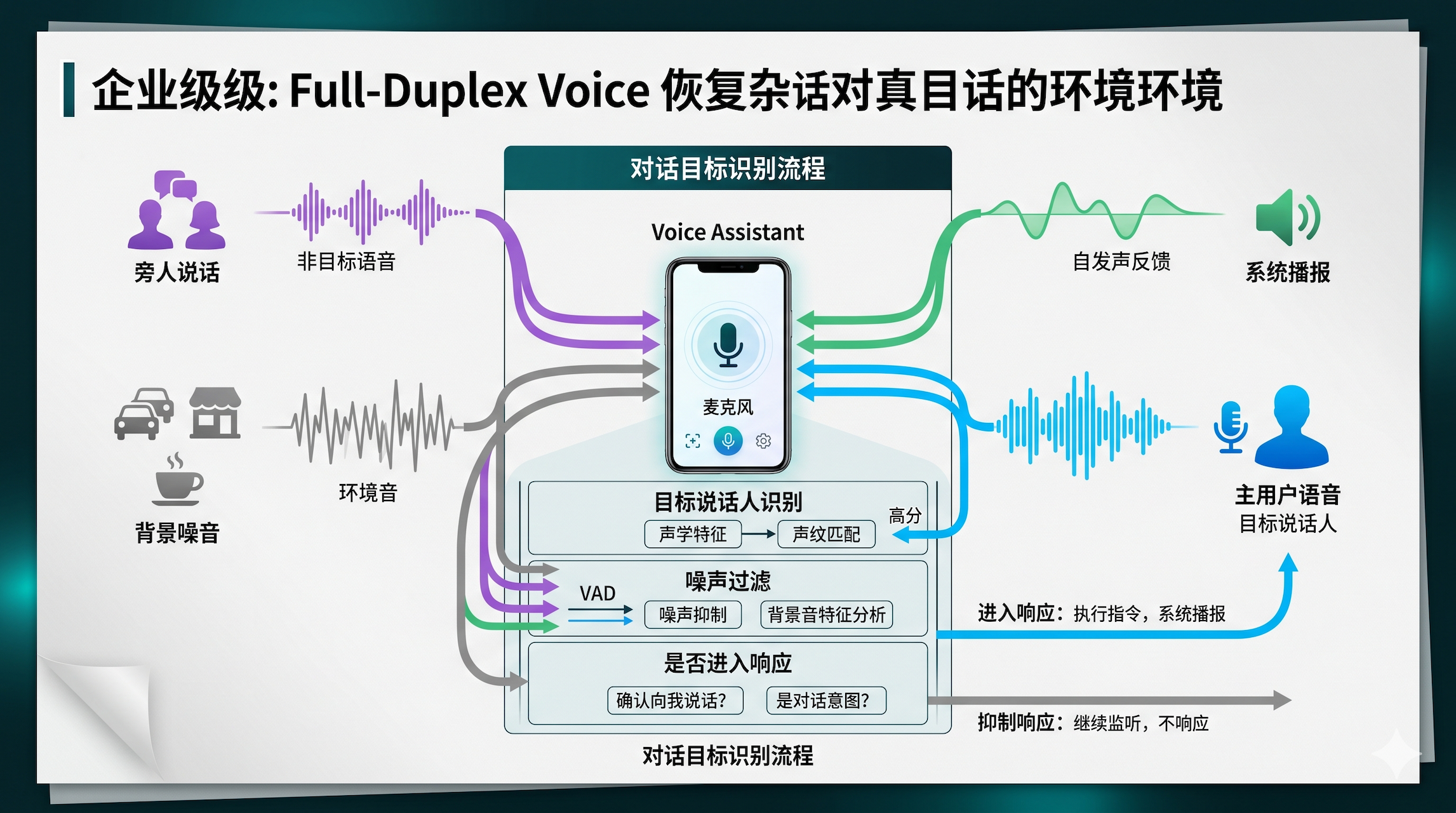
03 第二个被改写的是“谁在跟我说话”
语音 AI 以前默认一个理想前提:安静环境、单一说话人、明确指令。
但现实不是这样。
Google 在 Search Live 里把语音和摄像头一起带进搜索,本质上是在承认:用户越来越多地会在走路、逛店、修东西、看现场的过程中发起语音交互。字节也在 Seeduplex 里反复强调复杂声学环境、多说话人干扰和环境噪声识别。
这会直接改写一个产品基本题:系统到底该听谁?
在车里,导航播报、乘客聊天、用户命令会混在一起。
在家里,门铃声、电视声、家人对话会同时出现。
在办公和客服场景里,用户甚至可能一边说、一边跟旁边人确认信息。
如果产品还停留在“检测到语音就响应”的层面,后面做再多大模型优化都救不回来。
真正该补的是目标识别机制:谁是主说话人,什么声音应该忽略,什么插话要暂停当前回答,什么外部声音又应该被吸收到上下文里。
04 全双工时代,打断权和恢复权会变成核心体验
以前很多产品把“打断”理解成一个小功能,无非是用户说一句“停一下”,TTS 停掉。
但全双工不是这样。
在全双工里,打断不是异常,而是常态。用户会临时改主意,会在系统说到一半时加条件,会先让系统暂停,再继续追问。系统不仅要会停,还要知道这是硬打断、软暂停,还是无关插话。
这背后其实对应三种完全不同的恢复策略:
一种是立刻停并切到新任务。
一种是暂停当前输出,保留上下文,等用户回来继续。
还有一种是识别这不是对我说的,继续保持监听但不介入。
所以,未来好的语音产品,不会只拼“声音自然”,而会拼“打断后能不能优雅恢复”。这类能力一旦做好,车载、教育陪练、客服、搜索、智能硬件的可用性都会上一个台阶。
05 语音产品的 KPI,也该重写了
如果你的语音产品今天还主要看识别准确率、平均响应时长、满意度,那已经不够了。
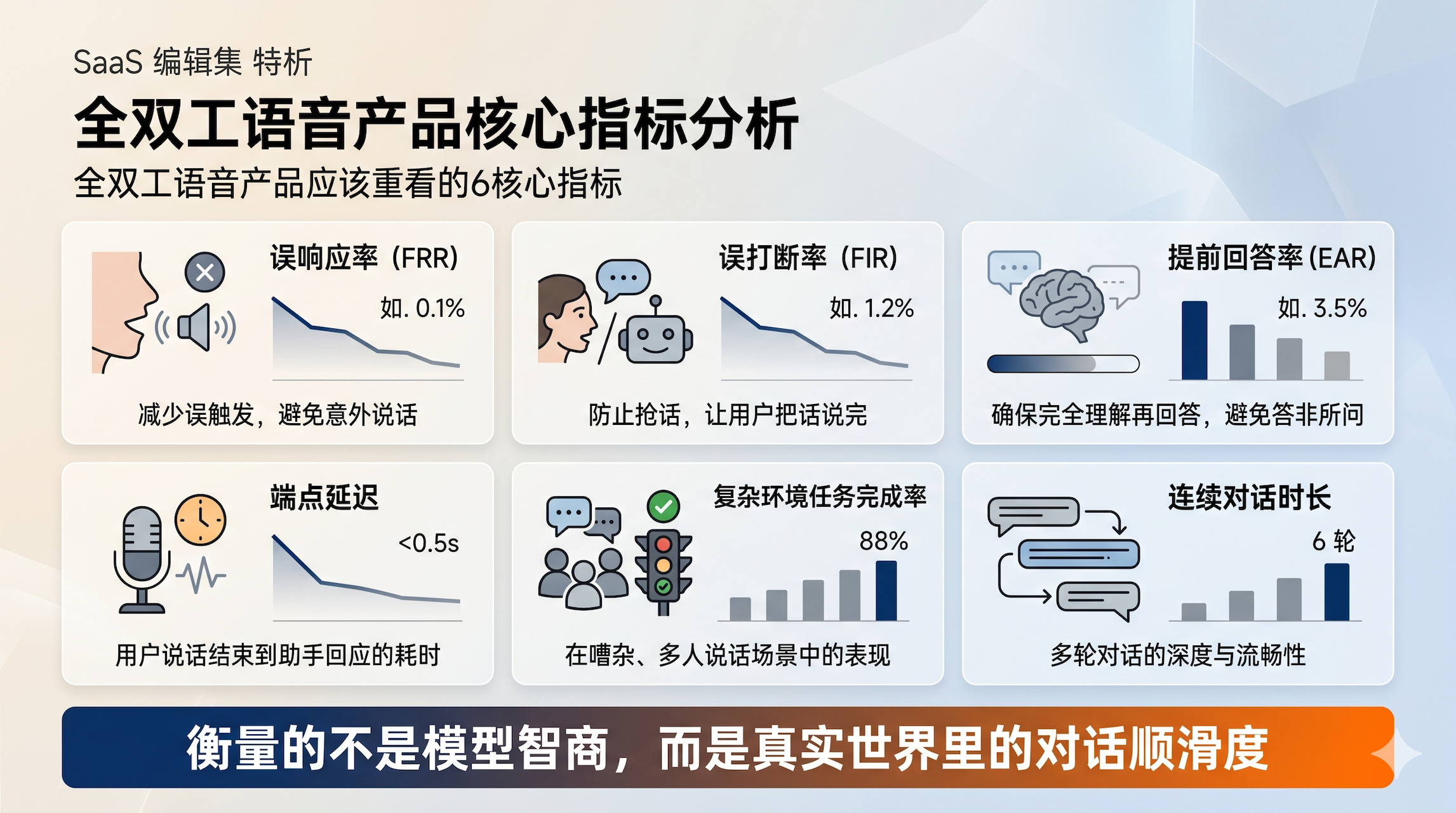
全双工时代,我更建议重点看这 6 个指标:
误响应率:系统不该回应时却回应了多少次。
误打断率:系统不该插嘴时插嘴了多少次。
提前回答率:用户还没表达完,系统就接话的比例。
端点延迟:用户真正说完后,系统多久开始回应。
复杂环境任务完成率:噪音、多说话人、移动中场景下能否把任务做完。
连续对话时长/轮次:用户是否愿意持续说下去,而不是说两句就放弃。
这组指标很重要,因为它们衡量的不是“模型聪不聪明”,而是“这个产品在真实世界里顺不顺”。
很多语音产品的问题,不是答错,而是让人不想继续说。
06 不是所有场景都该立刻上全双工
全双工很强,但不是万用钥匙。
最适合优先上的,是那些本来就依赖节奏、插话、环境感知的场景:车载助手、英语陪练、实时搜索、智能硬件、复杂客服。
相反,如果你的核心任务是长文本口述、结构化录入、强隐私环境,或者用户更需要稳定转写而不是自然对话,那半双工未必落后,反而可能更可控。
所以,产品团队别一看到新模型就全量替换。更稳妥的判断标准是这三个问题:
用户是否经常在手忙、眼忙、路上、噪音里使用?
任务是否依赖频繁打断、补充和确认?
对话体验的核心矛盾,究竟是内容质量,还是节奏和响应时机?
如果后两个才是主要问题,那全双工才真正值得上。
07 产品经理现在该做什么
如果你在做语音产品,我建议先别急着追“最新模型”,先做三件更值钱的事。
第一,把现有语音链路画成状态机。
别只画“唤起-说话-回答”,而要把等待、犹豫、插话、暂停、恢复都画出来。
第二,把评测环境从安静会议室搬到真实世界。
去车里测,去商场测,去办公室测,去边走边问的状态下测。
第三,给产品保留“全双工/半双工混合策略”。
不是每个任务都适合同一套对话节奏,能根据场景切换,反而更像成熟产品。
说到底,全双工语音真正改写的,不是语音入口,而是产品对“人类说话方式”的理解。
下一轮语音 AI 的胜负手,未必是谁先把声音做得更像人,而是谁先把等待、打断、恢复和环境识别做成稳定的产品能力。
本文由 @AIGC土豆 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


