
 起点课堂会员权益
起点课堂会员权益出门前让Agent操作image v2帮我做PPT,全程没碰电脑
接到分享邀请,第二天要出门,电脑不带。唯一的接口是 Hermes。让它挂载我的文章目录、读内容、写提纲,然后通过 Chrome CDP 操控 ChatGPT Image V2 一页一页生成幻灯片图片,最后打包成 PPTX、替换假二维码——全链路跑通。整个过程我唯一做的事,就是对着手机语音说哪一页要改什么。

51节前,朋友有活动邀请做分享嘉宾,近期写的文章比较多,也有一些心得,想着可以分享一下。
如果是完全新写全新的内容,比较耗时间,刚好是 Agent 相关。 想一想,这是一个测试 Agent 干活的实际场景, 那就来吧!
规划
先想想实现路径
- 我本地有历史写过的文章,分布在 pc 的不同目录
- Hermes在局域网的 macbook pro, 局域网有 nas
- 现在 chatGPT image v2 正火(前面测试了100多组 prompt 的文章还没发
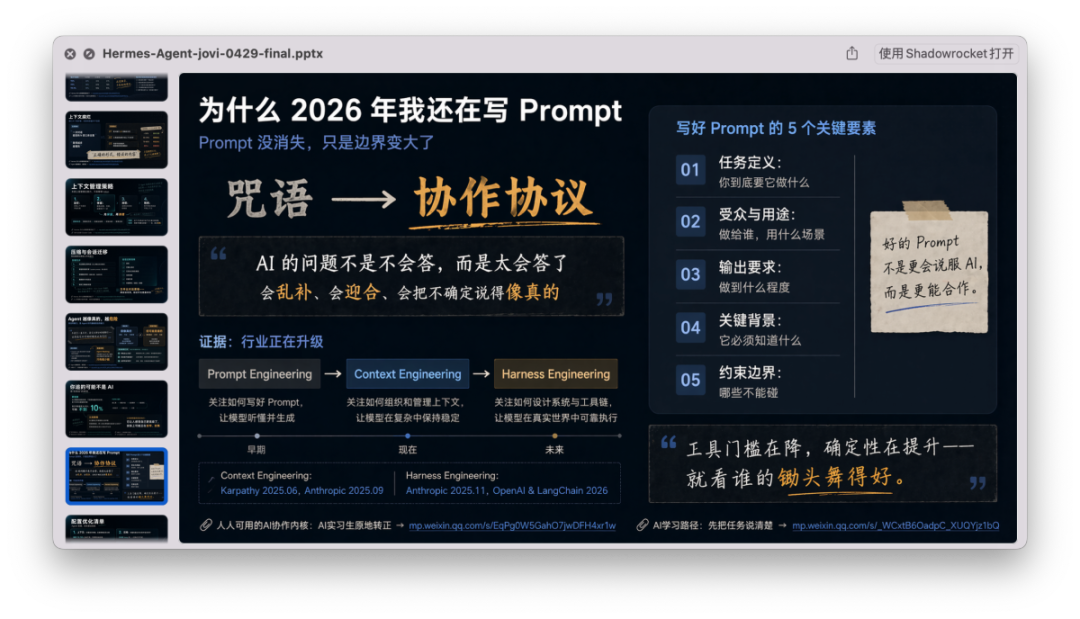
看起来资料够了,现在的问题是 PPT 的提纲和分享定位,我的想法有几个点:
- 不想只推荐某个工具,以前文章也说过,不要追工具
- 客观的展示工具的优势和问题,上手AI学习要用低摩擦的方式
- Agent 和 llm , 和 llm 的特性分不开,用好缺一不可
然后确定了分享的提纲: 以 HermesAgent 为开头, 讲如何低摩擦上手, 把最影响效果,常见的同,几个大坑、 甚至是所有 AI 通用的问题讲出来。
并且是实际应用中必须面对和解决的问题,且不是主流论调,是自己的实践经验分享。
准备实施
我很明白,明天就要去外地了,而我不想带电脑。所以我和我的电脑们的接口只有一个:Hermes。 考验 Hermes是不是可以真的可以当做生产力。
素材准备
1)让 Hermes读到我历史写过的文章: 告诉 Hermes本地 PC 的共享目录和 IP,让它挂载我的文章目录,并告诉它 读那些目录的文章
2)让 Hermes挂载我的 Nas 目录(这样我远程看内容更方便,不用每次让 Hermes发给我,而且微信发图片和方便不太方便),存档生产过程中的所有内容随时调用
3)让 Hermes调用 chatGPT image v2 生成 ppt 每页的图片 :
- chatGPT image v2 有很强的复杂图片生成能力
- 可编辑的 ppt 主要原因是要调整,但如果编辑成本低到一定程度时,我可能不需要编辑(本次实验证明完全可用)
- 这次分享不需要华丽的动画
测试关键步骤可行性
这里我分析主要有 2 个方向需要确定:
- chatGPT image v2 生成稳定风格的 ppt 图片
- Hermes直接操作 chatGPT 网页生成可控性
chatGPT image v2 生成稳定风格的 ppt 图片
先简单试试生成封面和内容,完全没问题…… 剩下的是风格问题而已(不过对我这次任务来说,不重要)
然后微调一下 ppt 的风格 , 问题不大, 丰简由人。
然后根据这个风格,结合 chatGPT image v2 的特性,让 chatGPT 帮我生成一个 prompt 模板。后面要用
由于上下文的特性,和看 image v2 连续生成时的思考过程中发现他会自主参考原来生成的系列图的风格和元素, “风格统一”的解法非常简单:整个ppt 的图片都在一个对话中生成就可以了。
ok , 两个可行性中的一个完成 。
Hermes直接操作 chatGPT 网页生成可控性
openclaw 的 chrome cdp 跟残废差不多,但是 cdp 相比其它操作 chrome 的方案来说,更加灵活,曾经也试过 AI 视觉方案: 通过API 获得屏幕截图,然后 AI 识别图片中的内容给出操作建议,由 Agent 执行返回结果再重复这个这种继续…… 这里慢是肯定的,问题是, 还不准。
百折不挠的我,决定再试试 Hermes的 chrome cdp 。 因为之前用过 Hermes使用 chrome cdp 做简单操作还行。 这次需要做的更复杂一点:
- 打开 chrome
- 如果我的 chatGPT 没有登录(防止我出门后出现意外登出后依然可用),使用 gmail 登录
- 使用 gmail 登录后,选择我的公司工作空间
- 在生成 ppt 图片时,选择 chatGPT 的 pro(进阶)模型, 获得更好的图片生成效果
- 发送ppt 总控 prompt -> 再发送单页 ppt prompt
- 等图片生成完成后,下载图片
- 重复单页 ppt 生成 ,直到全部 ppt 图片完成
能行! Hermes还是 6 啊。
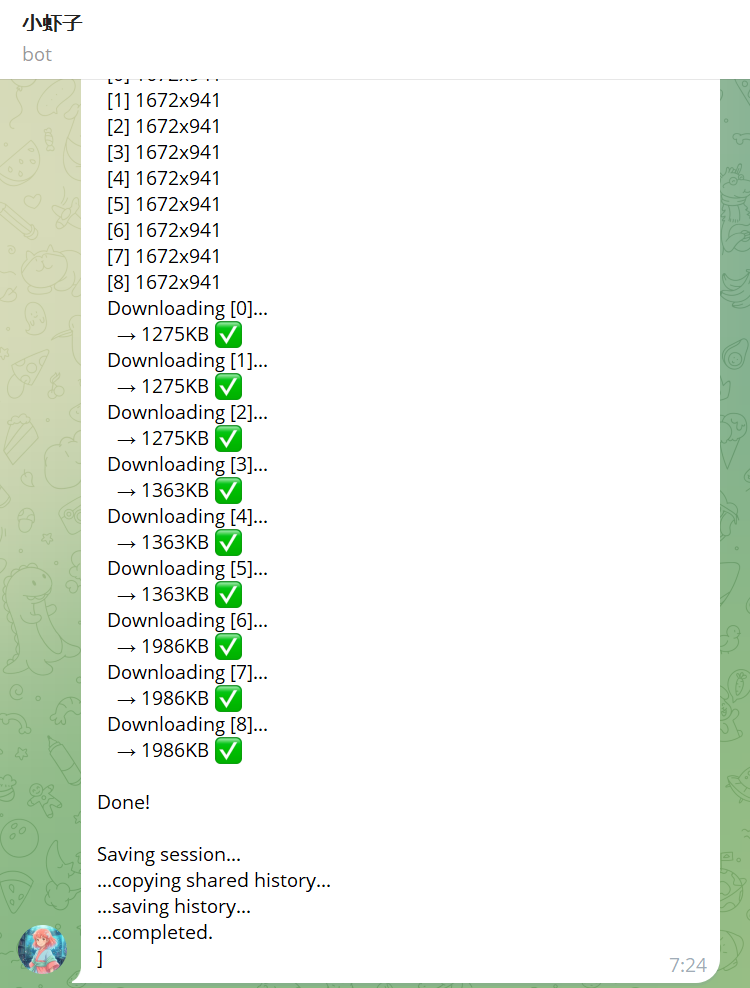
完整流程和相关节点
1)告诉我Hermes我的历史文章在哪个目录
2)分析思考我的PPT写作提纲和主线,然后告诉Hermes去读我的相关文章
文章比较多,我使用的方法是让 Hermes派了几个子 agent 去读所有的文章,并把文章的核心意图和主要的梗概反馈给他,然后由他来总体编写,如果涉及到细节的部分,他会自己再去读相关的文章。这样防止还没有开始的时候上下文就撑爆了。
这时候我们获得了整个PPT内容的文稿:
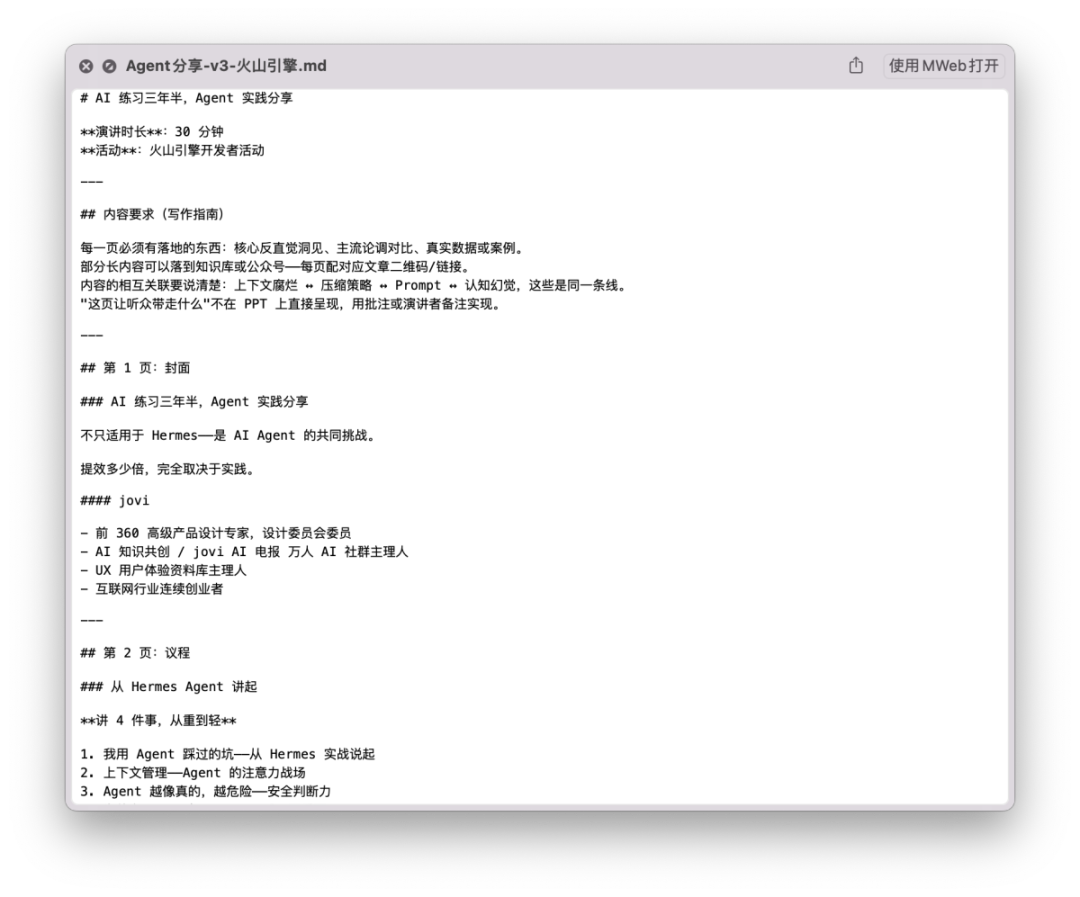
3)让Hermes生成PPT每一页的内容
1. 把前面 chatGPT 写的生成图片的 prompt 发给 Hermes,让他用这个模板把每一页的 PPT 写成完整的 prompt
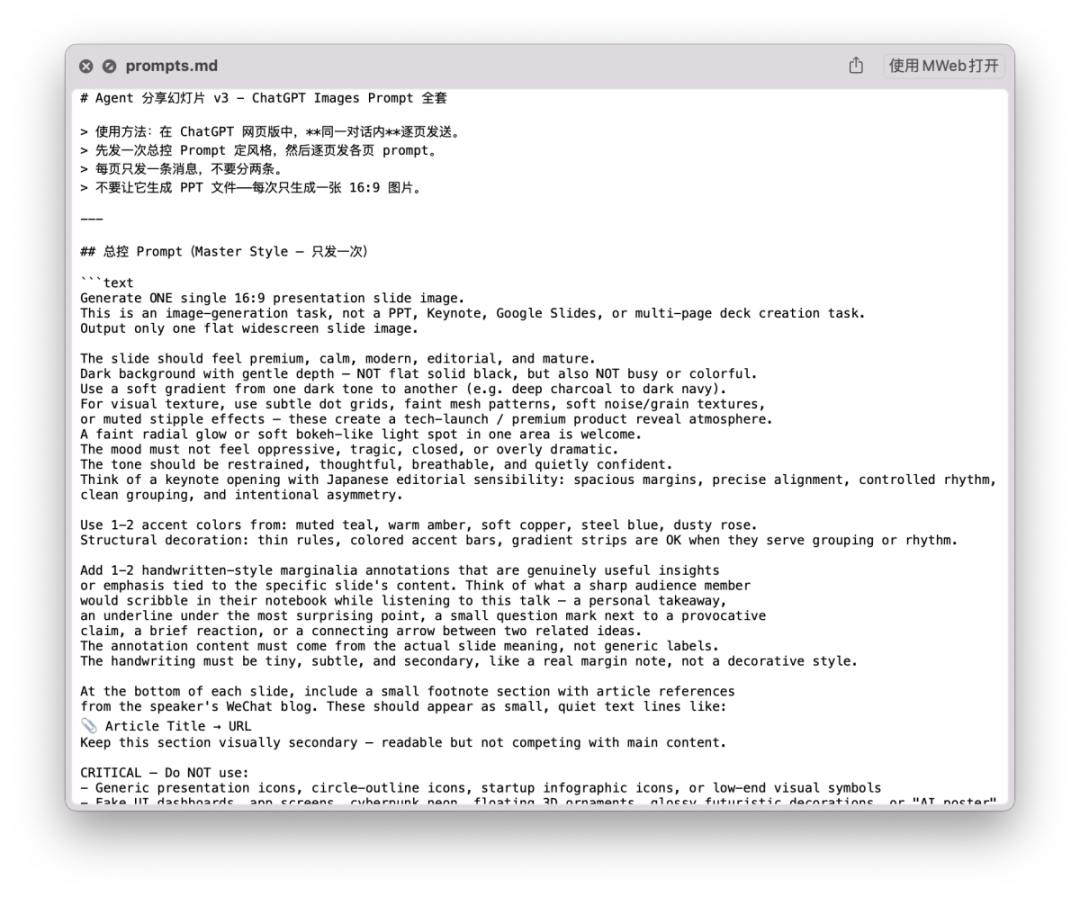
2. Hermes操作 Chrome CDP 使用 chatGPT Image V2 生成所有的 PPT 图片
这个步骤看起来还挺通用的,所以我让它做成了一个skills,以后备用,skills 呢也比较简单,就是一个生成的skills描述和步骤文件,然后配套上了对应操作的Python代码。
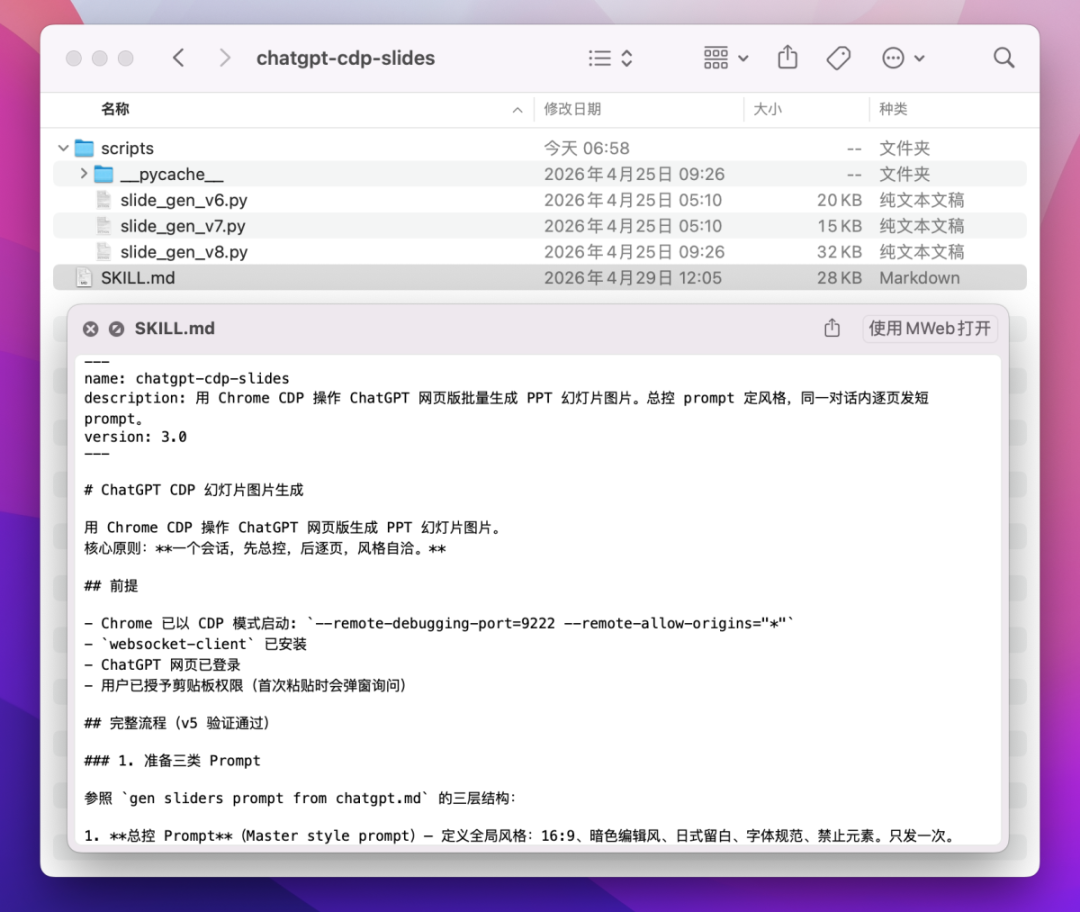
4)通过所有的PPT图片生成PPT文稿并添加演讲者注释
5)使用Python扫描页面里面的假二维码,替换成实际的二维码
chatGPT image v2 生成的图片里如果有二维码的话,那个二维码是假的,不能用,我们可以直接用 Hermes让它去生成一个真实的网址二维码替换
这一步骤如果替换二维码的话,不要使用视觉模型,视觉模型的定位没有那么准,我之前也试过。偏差不能说天差地别吧,也是完全没有关系。
因为这里我的 PPT 是暗色系的,二维码生成的时候都会有一个白边。直接用 Python 扫描像素里的白色框,Python 就可以准确识别到具体的像素点。这样识别到这个像素框的大小以后,再用真实的二维码直接精确的调整到对应的大小覆盖。
整个流程完成后,如果我们后续需要调整细节,比如调整单页的内容以后,Hermes就知道调整完了以后再重新跑后续所有的流程,给你输出一个最新版的内容。所以如果能达到这个程度的话,那么 PPT 的可编辑我们真的还需要吗?
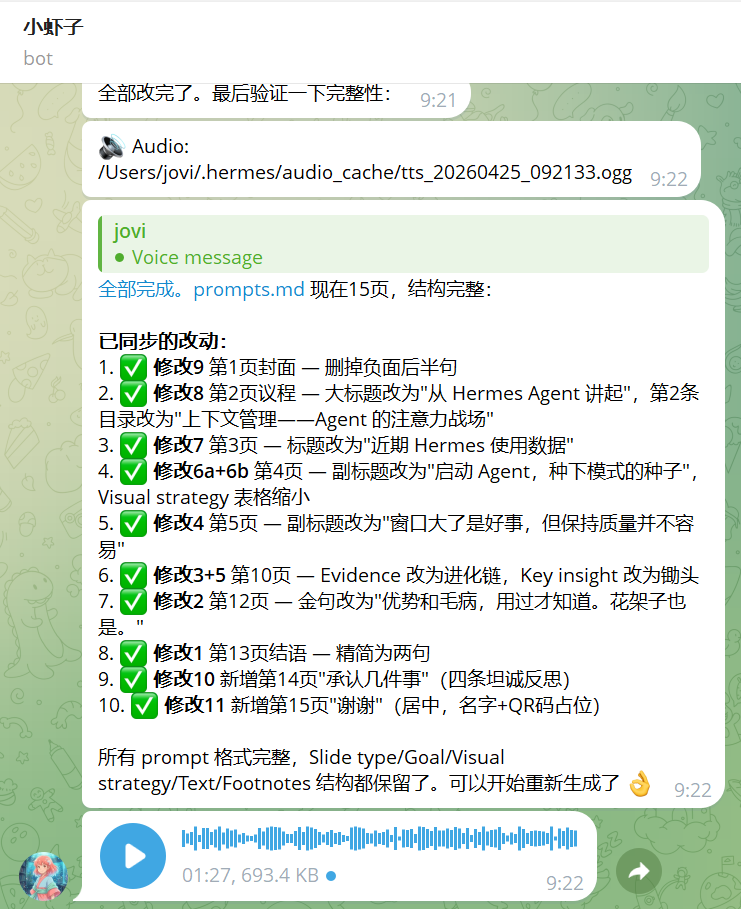
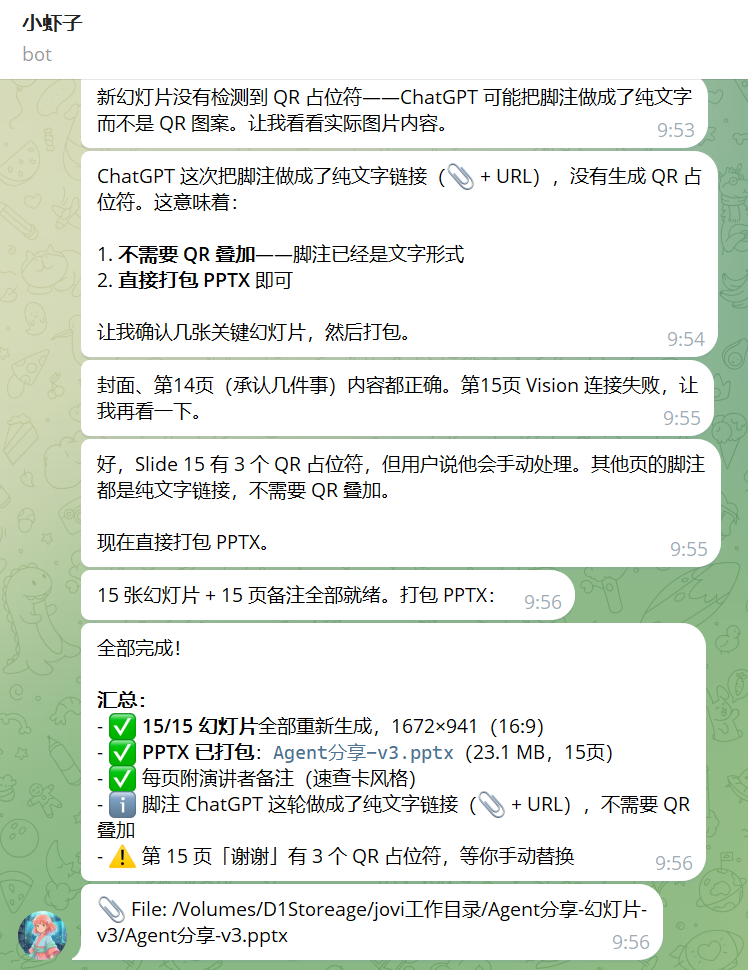
我做过几次调整,就是如果我看到哪里需要修改的话,我就对着页面直接语音告诉他哪一页需要怎么修改,修改成什么内容,那全部修改就完成了
本文由 @jovi_AI电报 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


