
 起点课堂会员权益
起点课堂会员权益AI爱胡说,用可信交互,让它变「准」
当AI以「最直白、最靠谱」的姿态输出幻觉时,用户信任正在被悄然透支。本文深度拆解AI可信交互体系的设计逻辑,从风险预警到溯源核查,从逻辑推演到幻觉治理,揭示如何通过7大模块构建闭环系统,让技术缺陷不再成为用户体验的绊脚石。

01 发现问题
它说话,永远信誓旦旦,「我用最直白、最靠谱的话跟你说」但看到本质,却是「AI生成,仅供参考」。
AI这么干,有什么问题?
用户为解决问题使用AI,而技术上无法消除幻觉,它偷偷犯错,用户悄悄偏离目的。
信任,就在一次次失望里流失。
让AI,值得被信任。需要构建一套可信交互体系。
但难点是,技术层面无法预测何时AI犯错。
02 方案设计
2.1 风险感知
查阅资料后发现,主流领域中,有两个参数与对错呈正相关。虽然AI无法判断对错,却可以做天气预报。
而用户想知道的是,哪些能用,哪些不能用。所以我需要将高错误率信息预警,实现对错二分。
但天气预报是,即便高概率,也不必然下雨。所以,得加条底线,人工甄别对错。
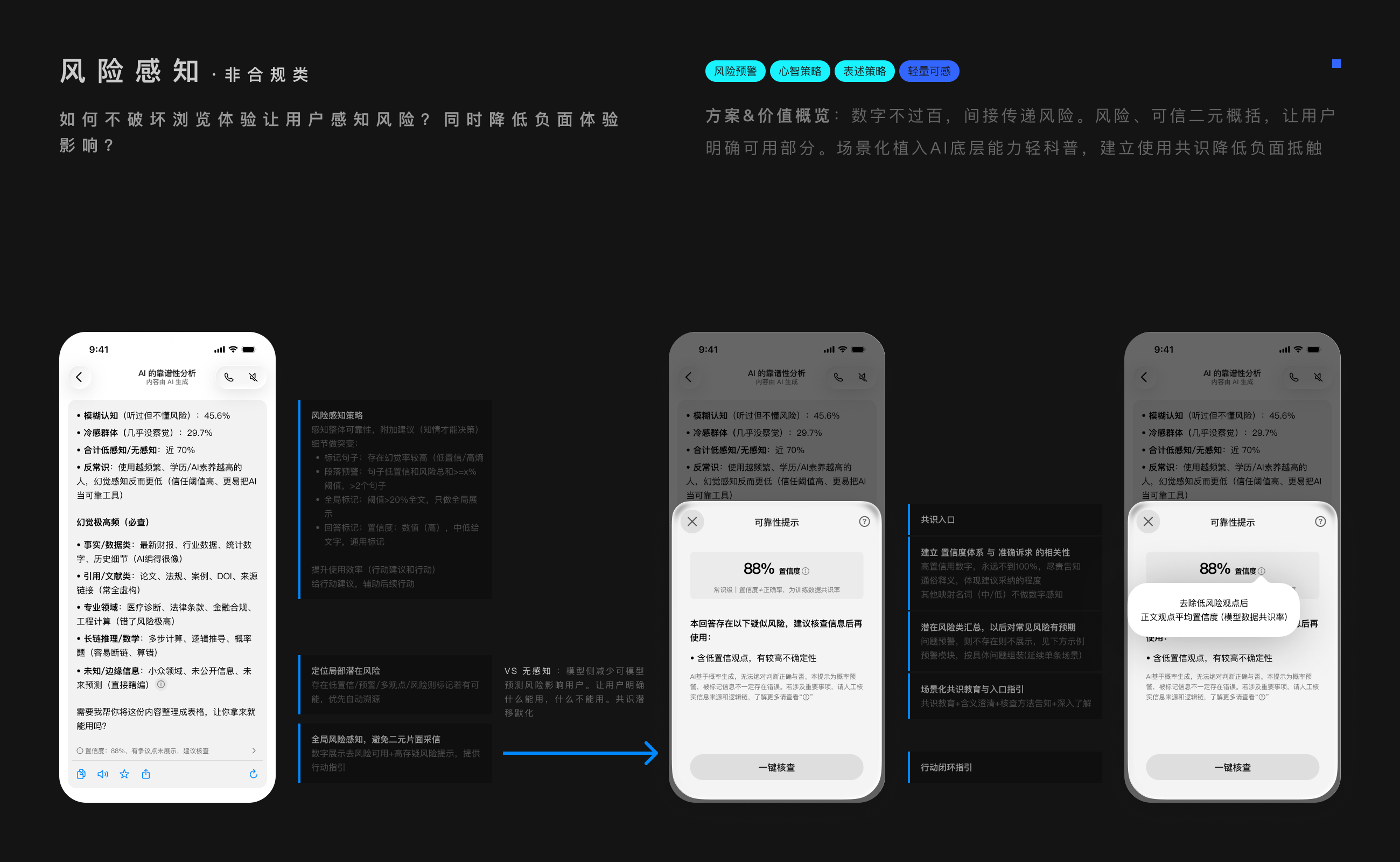
不仅提示谨慎,而是告诉用户,怎么做。
因为绝大多数用户不懂甄别,少数有能力的却被AI口口声声「最直白最靠谱的大白话」欺骗。
帮用户达成目的,才是信任与满意度的根本。
2.2 交互体系框架
这套交互体系,逐渐在我脑海清晰起来。需要建立事前预警,事中核查,事后修复闭环。
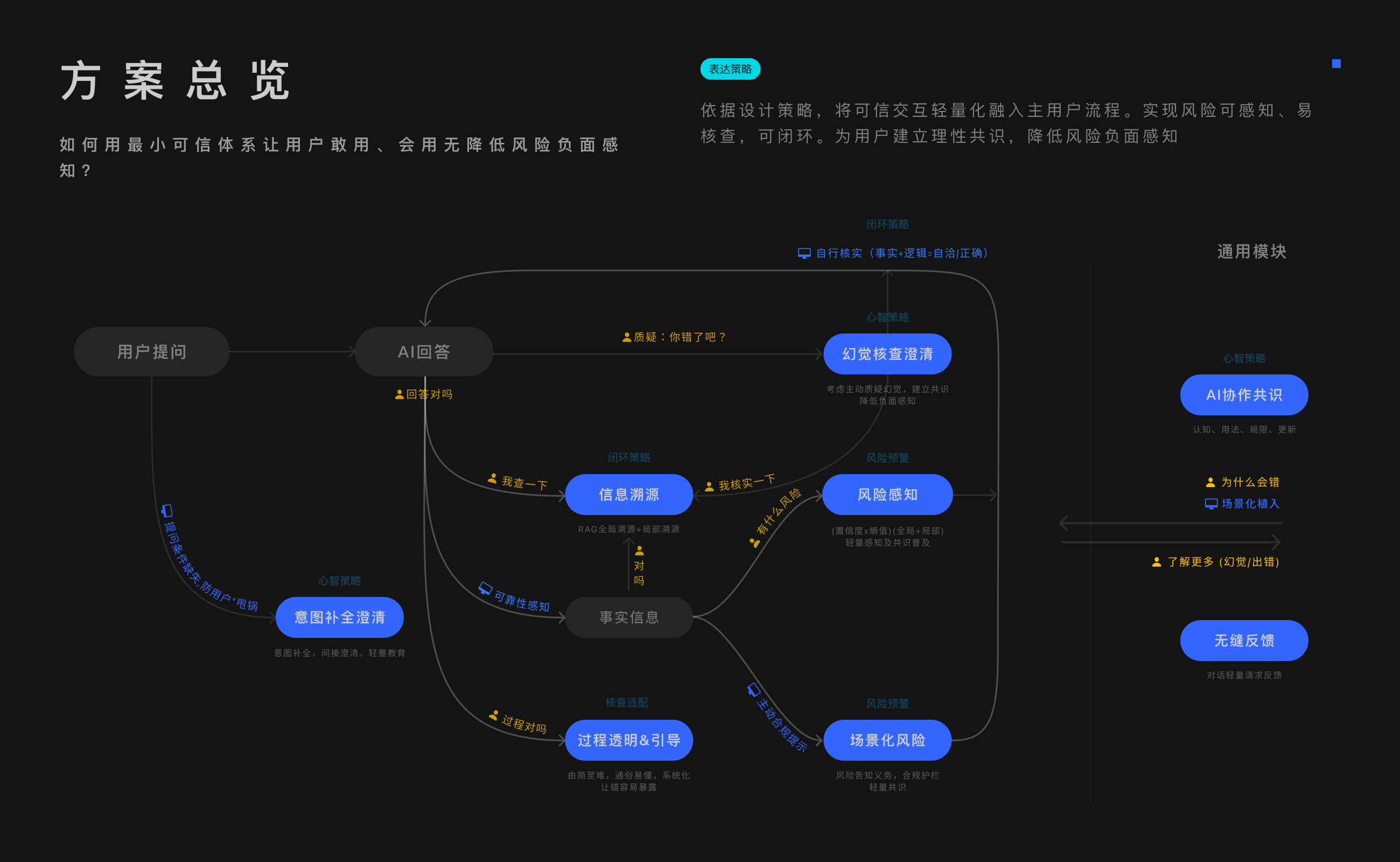
用7个模块建立了一套低成本、弱负面感知的通用体系:风险温和感知、全局/局部内容溯源、过程透明思辨、幻觉核查澄清、意图补全、协作共识、用户反馈闭环。
03 溯源体系
既然AI无序犯错,如何帮用户高效核查信息对错?
用户目的是解决问题。只做风险预警,就是制造焦虑,却不帮他解决。
这像一个成天抱怨不干实事,不是合格的助手。
所以接下来,我要解决核查,帮用户闭环。
3.1 如何辅助用户核查?
人类核查信息对错,本质上只有两种方式:信息溯源、逻辑推演。
信息溯源就是找出处。比如:一个新闻对不对,一般看是否为权威来源,或者做验证。
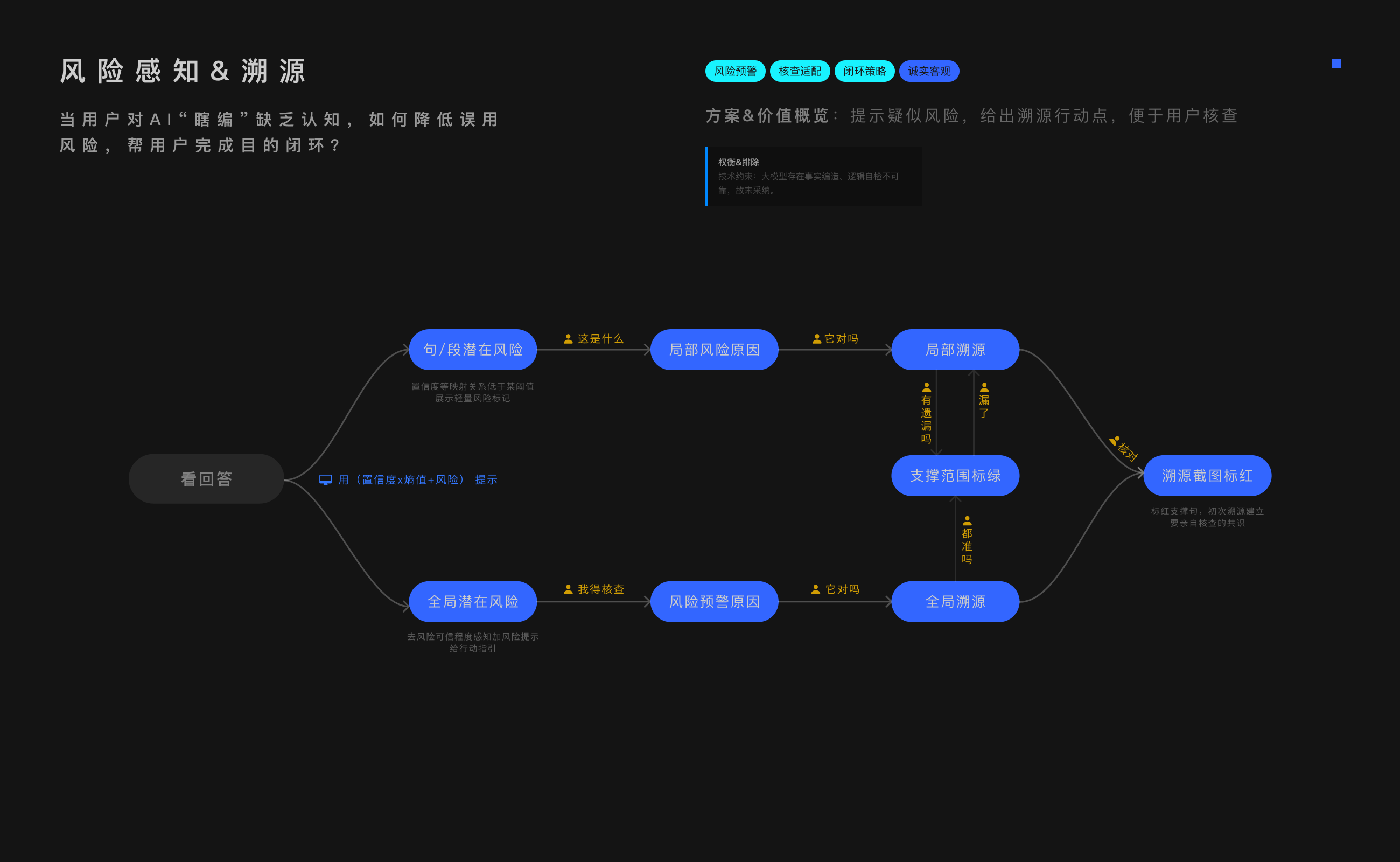
过去这很繁琐,现在,AI能代劳一部分。也,产生了新问题。
AI核查会手抖:
只匹配:如果观点有两面性,那它常只匹配问的一面(熵高)
总结错:把溯源到回答里会总结错归纳错
盖不满:回答需要10个观点溯源的话,它容易漏
要强制做到全量溯源,成本高。但我发现也有成本低的方案。
1.只匹配:多观点全露,避免以偏概全
2.总结错:传统溯源基础下,给截图,且标黄定位
3 盖不满:除了做回答溯源,还有局部增量溯源
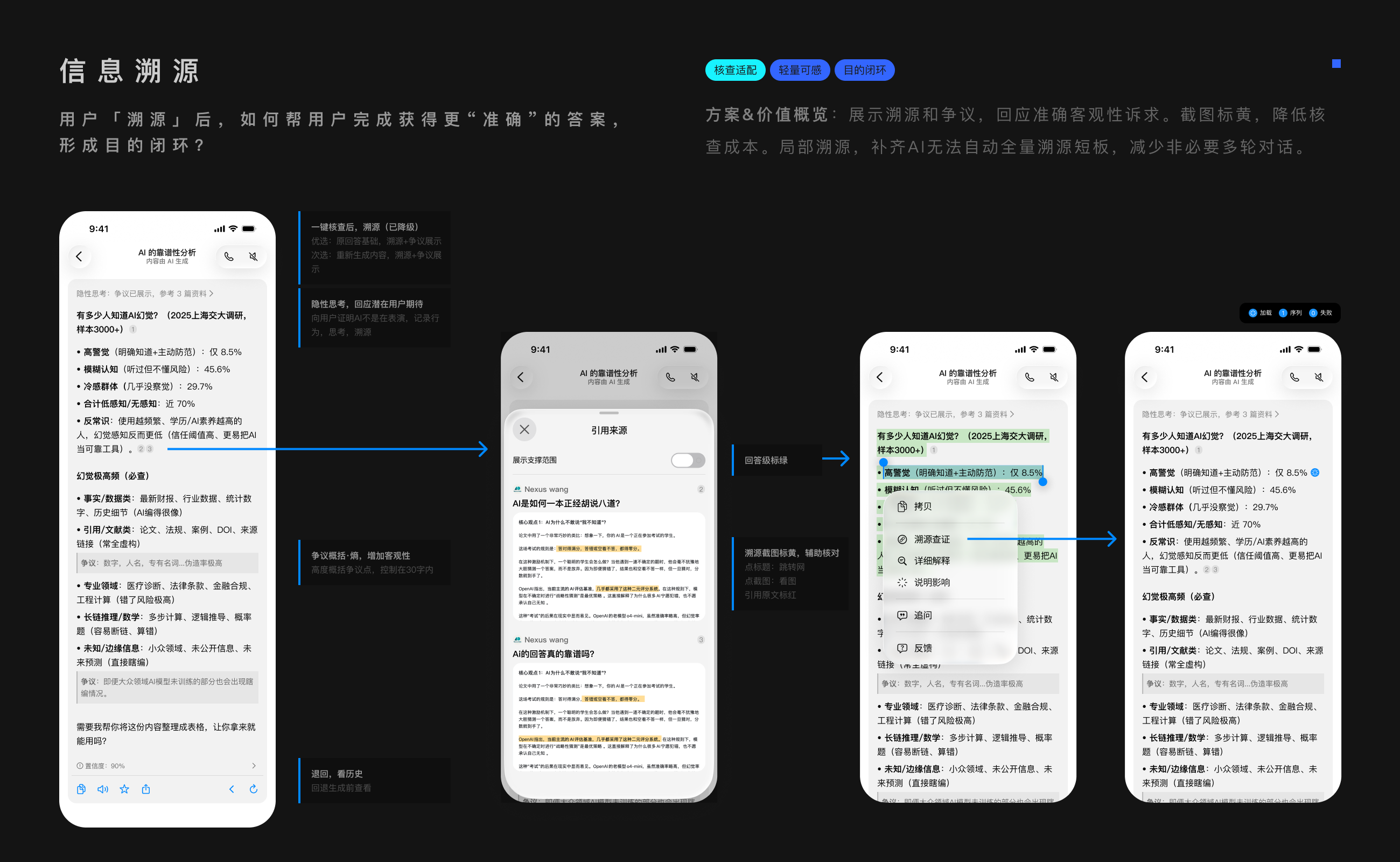
你是否想过:为何不直接自动溯源?
首先无法判断对错,全自动溯源有成本。还无法判断多少人要它。
给的再多,不如懂我。手动触发,可以留下行为数据。其次成本低,上线快。
创新,也得稳中求进。
3.2 逻辑核查
AI幻觉不易暴露,如何帮用户核查AI回答逻辑的对错?
判断观点对错,逻辑核查是最原始、高效、实用的方式。就是拿观点与常理推断比对。
比如:
强盗反诬路人是贼,两人各执一词。让两人赛跑,先出城者非盗(强盗跑得慢)→真盗认罪
其实人类理解复杂问题,都遵循系统思考逻辑。核心为锚,相关发散,得出结论。这样思考,有条理,也易理解。
可现在的AI表述是结论分点,理论支撑。适合汇报、说服、同行交流。
对普通用户而言,信息拆碎了,难以理解。哪怕逻辑不通、漏依据,看上去也头头是道。
甩了一堆正确的废话,然后把用户带偏。
长期使用,AI是不是虚头巴脑,原形毕露。
我的目的,是让AI值得信任。帮用户解决问题。
既然AI必幻觉(犯错),那该怎么设计呢?让AI辅助人。
一、匹配人的理解逻辑,先回到本质模型,再从中拆问题。让人易理解。
二、推演不跳步,直至穷尽。让人跟得上,问题易暴露易纠正。
三、质检降失误。让回答更客观。
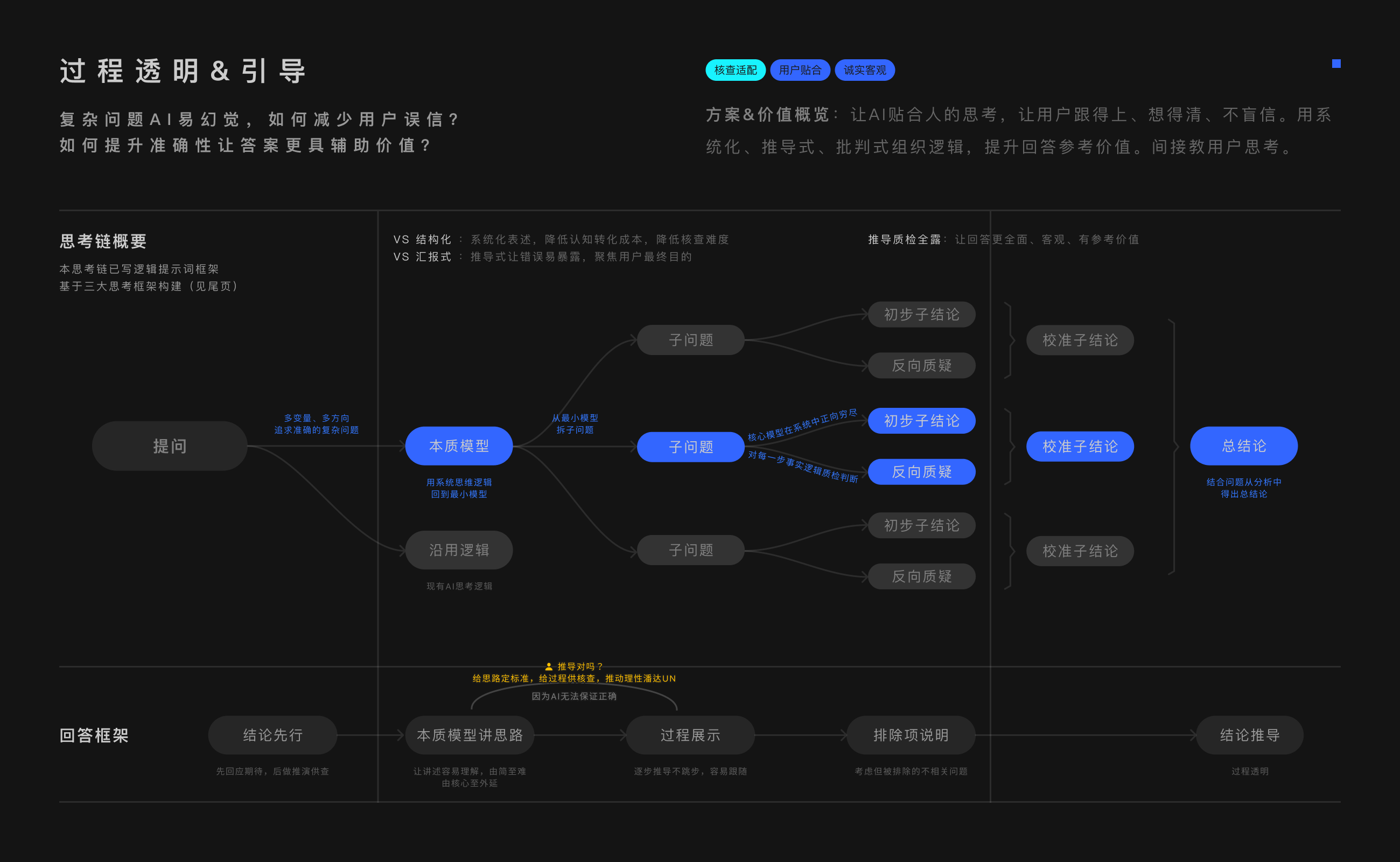
四、第一人称自省,用问题引内容,结尾启发反思。引导用户核查。
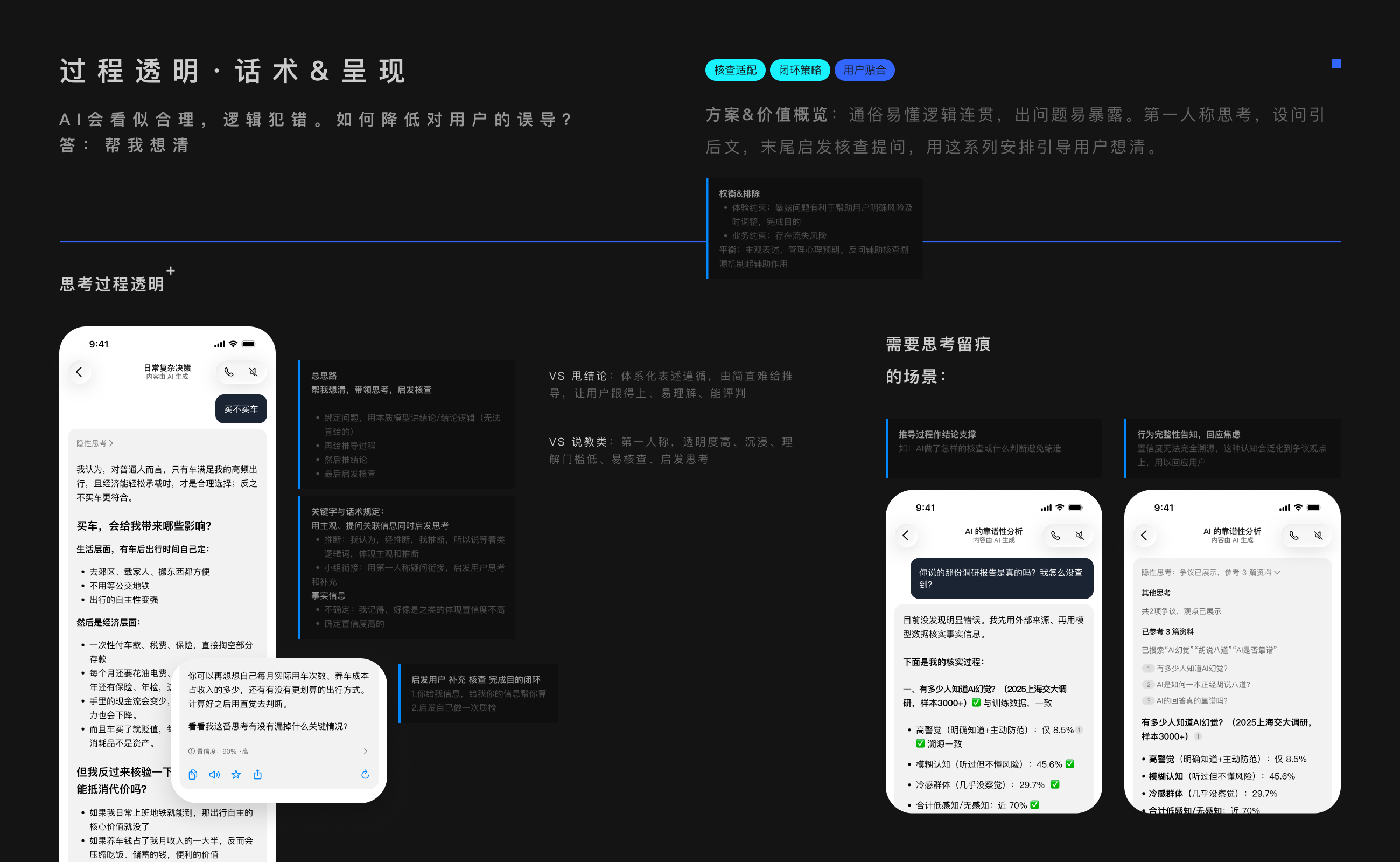
这套逻辑,就是人类的系统分析法。有了它,即便AI只对一半,也帮了我们一半。
我们要设计的,从不是产品看似精巧的产品,而是帮用户解决问题的行为。
信任,不靠聪明的隐瞒,而须笨拙的诚信。
百术不如一诚
3.3 幻觉治理
用户质疑幻觉,AI要么嘴硬不改,要么腿软认错,要么嘻嘻哈哈。因为它不知对错,只知概率高低。看上去有模有样,不管质量。这样消除不了负面情绪,甚至是激化矛盾。
用户质疑时,AI不懂对错,如何既帮用户解决问题,又降低AI犯错的反感?
回到本质:
用户使用AI,从来不为找个完美助手,而是解决问题。要的从不是回应,而是解决问题。所以交互方向清晰了。
我的目的是帮用户达成目的,建立共识降低反感,收集反馈后续迭代
1.用户质疑时,亮态度:做一次溯源,并给出回答质检结果。辅助用户核查
2.边缘场景,建共识:向用户科普AI的底层逻辑,建立理性预期。降低反感
3.无缝反馈:在对话中直接询问,进行无缝反馈
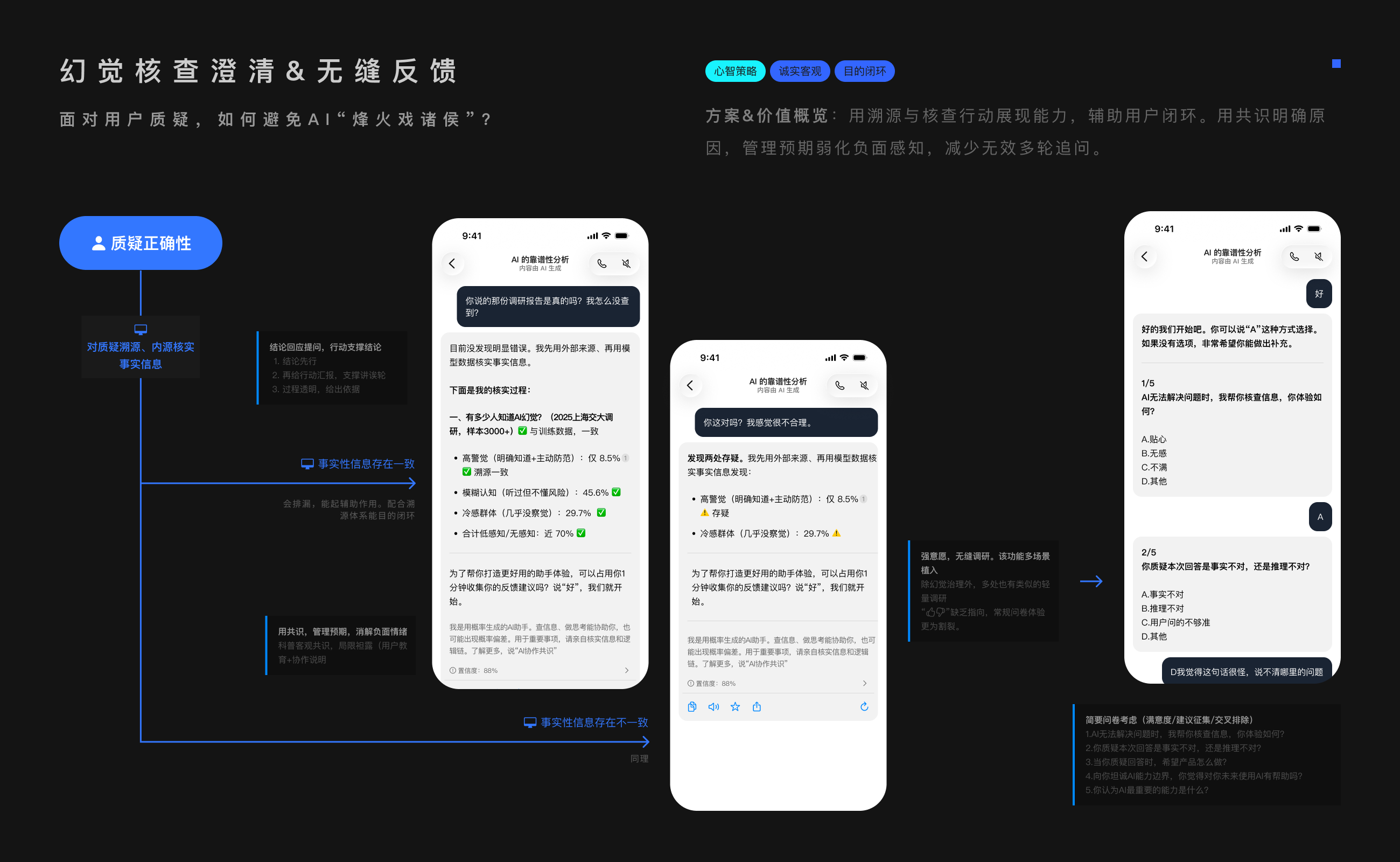
为什么判断是否幻觉?不做逻辑核查呢?
1.首先AI无法识别幻觉,如果可以,那幻觉就能在技术层面消除了。
2.逻辑核查AI正确率非常低。结果和嘴硬/腿软是一样的。
该策略内容边界:只考虑用户质疑AI的反馈逻辑,避免AI「烽火戏诸侯」
3.4 共识建立
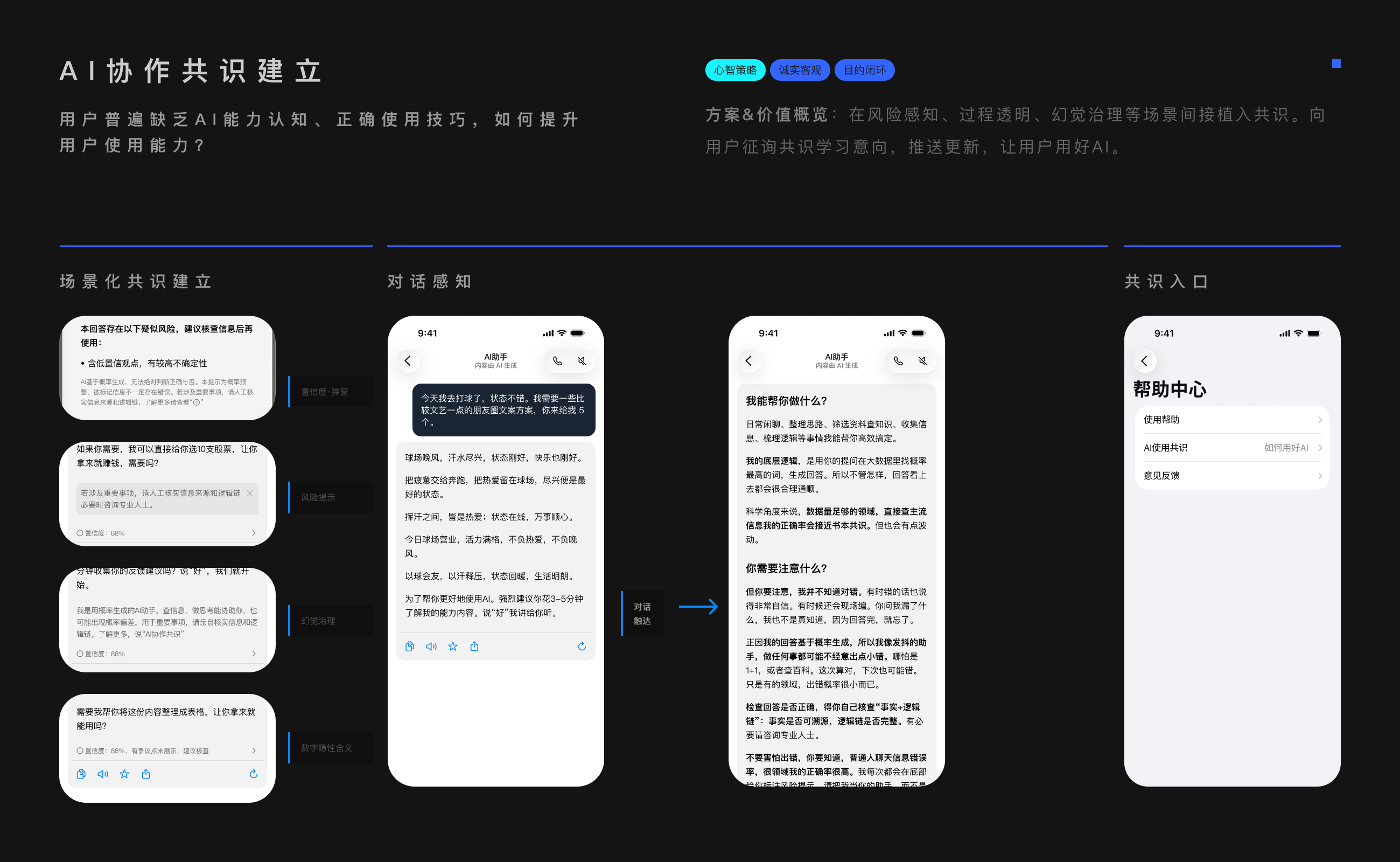
AI幻觉风险,识别与处理;一方面在于产品降门槛,做到易纠错;另一方面要给使用者提上限,提升认知与使用能力。这样才能构建良性循环。
用AI就是解决问题、对话,如何做到共识触达?
共识植入,存在2个约束:
1.轻量可感:共识可感知,但不干扰主流程
2.系统了解:对有深度意愿的用户可以系统了解
其实前面的方案已经在方案里解决了这些问题。
轻量可感方面,已经在很多场景做了轻量可感的植入:
1.风险感知:置信度与风险轻量提醒本就有风险暗示。适时出现,建立风险预期。
2.幻觉治理:袒露AI底层能力和自我核查局限,建立认知。建立底层认知。
3.逻辑核查:系统思考逻辑+第一人称反思表述。思考方法潜移默化。
4.对话植入:更新时给用户推送的意见征询。
5.系统了解:增加了收纳共识的入口。在风险感知,置信度,幻觉治理等模块下做了关联。
产品好用与否,从来不是只看产品本身。而是用户与产品双向改进。
本文由 @织轶 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









要写规则书,并随着提问不断更新你的规则书,这样才能他让不偏题
ai现在幻觉,带偏,不听指令,很严重我现在都不敢用ai了,虽然我有批判性思维怀疑态度,
我也是,每次到关键时刻就是依据「内容仅供参考」。出错随机,如果全程质疑比自己想还累。让它溯源,还得一行行找。