起点课堂会员权益
起点课堂会员权益一文教你读懂Token的消耗规则
当你为一段5秒AI视频支付39元时,是否想过背后的商业逻辑?从文生文到视频生成,Token消耗的差异背后暗藏计算规则与定价策略的玄机。本文将深度拆解MaaS商业模式,揭秘为何有的模型贵如黄金却门庭若市,有的近乎免费却无人问津。

最近,我在给甲方做demo的时候,用了seedance2.0的模型,在所有的节点都搭建完成的时候,我看了一下最后的生成的积分消耗,折合人民币39元……
老实讲,我一顿晚饭可能都没这么多,但是不用又没办法,seedance2.0的效果确实很好,尤其是图生视频,配合image2直接屌炸了。
但是,我很好奇,我们一直在使用这些模型,却从来没有想过他们背后的计算规则,虽然都知道是消耗Token,但是却很疑惑为什么视频生成普遍那么贵?以及厂家的商业逻辑,为什么不同模型厂商的定价还不一样,有的厂商几乎就是白嫖,而有的却贵的离谱还有人想要用。
所以今天这篇文章主要来解释token的消耗以及帮大家看懂MaaS(Model as a service)的商业模式
要理解Token消耗,你必须先理解Token本身。这不是一个可以跳过的前置步骤——Token是整个AI计费体系的基石,不理解Token,后面所有的计费规则、成本逻辑、优化策略都会像空中楼阁一样站不住脚。
大语言模型(如GPT-4、GLM-4)并不直接理解文字——它们只理解数字。你输入一段中文,模型需要先把这段中文”翻译”成一串数字,处理完之后,再把数字”翻译”回中文返回给你。这个翻译过程中的最小单位,就是Token。
打个比方:你跟一个只会英语的翻译官说话,你说”你好”,他需要先在脑子里把”你好”翻译成”Hello”,理解你的意思后,再用英语回答,最后把回答翻译回中文告诉你。在这个过程里,翻译官不是逐字翻译的,而是按照他自己理解的”意义单元”来切分——有时候一个字就是一个单元,有时候两个字的词是一个单元。Token就是模型眼中的”意义单元”。
更准确地说,Token是模型词表(Vocabulary)中的一个条目,是大模型自己的语言,当你和他沟通的时候,它需要理解你并且对你进行不同程度的输出,这一部分就会消耗模型能量,而Token就是供给。
那”1000个Token大概等于多少字?”其实不是一个固定数字,而是一个范围,因为不同语言、不同内容的Token化效率不同。一个实用的估算方法:对于中文文本,你可以用”1个汉字 约= 1.3个Token”来粗略估算。也就是说,一段1000字的中文文章,大约消耗1300个Token。但这个估算只适用于”正常文本”——如果你的文本包含大量代码、公式、特殊符号,Token数会显著增加。
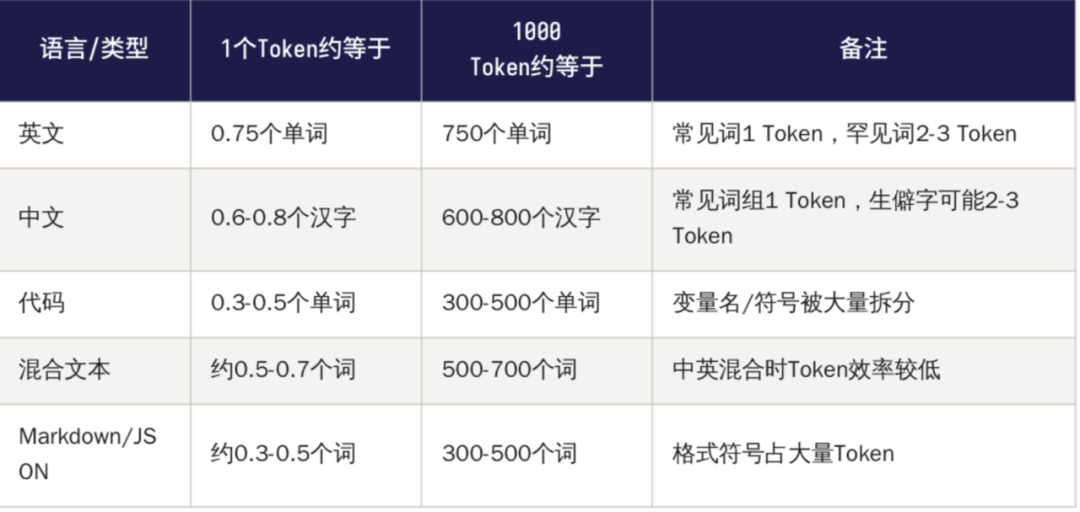
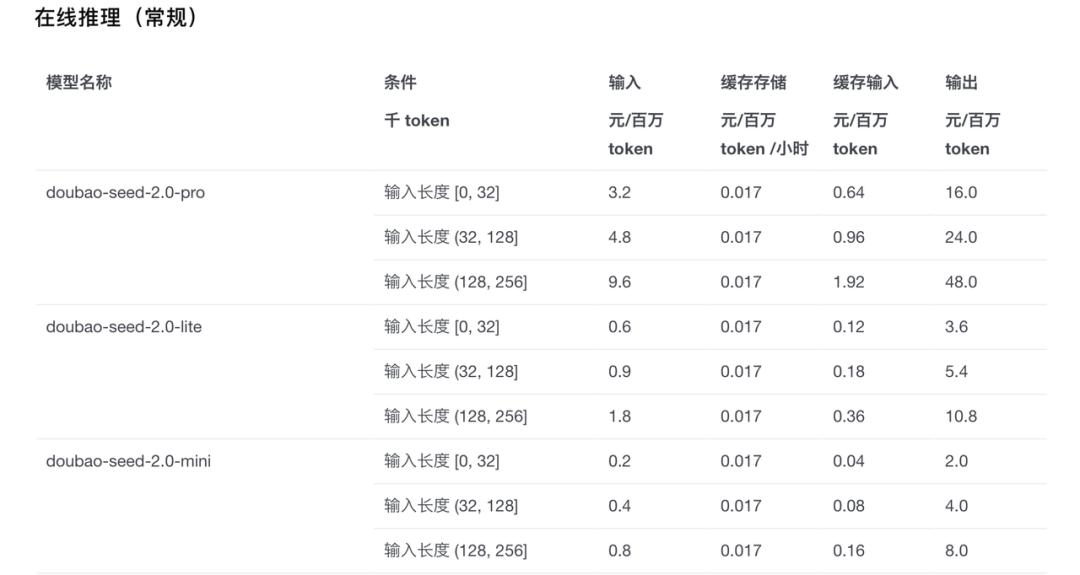
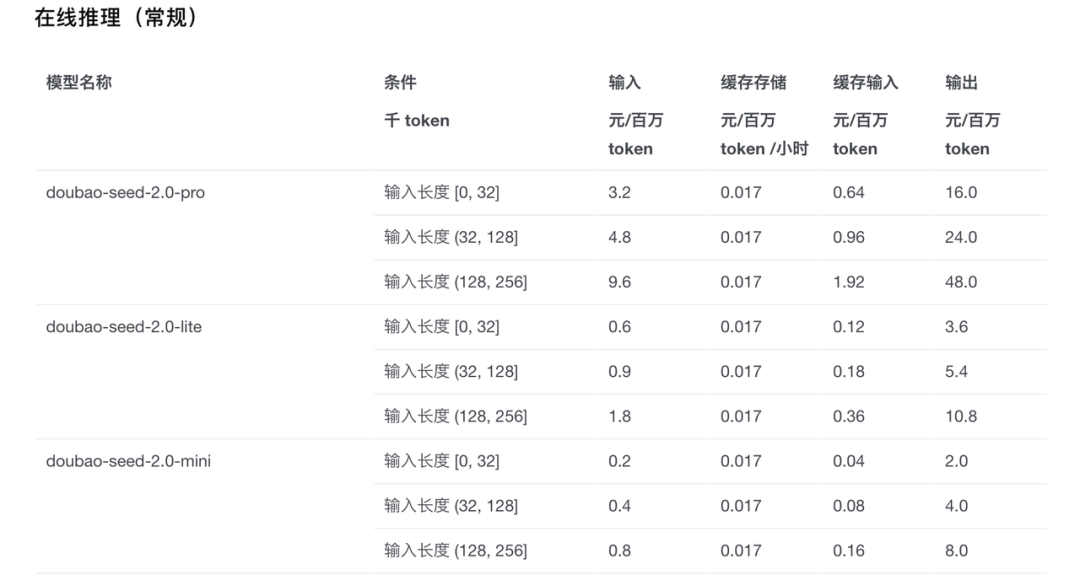
讲完token的基本概念之后,我们需要理解三个不同类型的模型消耗规则,这一部分我主要参考了火山引擎的大模型价格的文档,链接为:https://www.volcengine.com/docs/82379/1544106?lang=zh。
由于火山官方的模型有很多,但这里我只例举最常用的几种,从实际使用的场景来看我把它们分为:文生文模型、文生图模型和文生视频模型这三种。
文生文模型(如GPT-4、GLM-4、Claude)的计费核心是”分别计算输入和输出的Token数量,然后乘以各自的单价”,公式也相对简单:
总成本 = (输入Token数 × 输入单价) + (输出Token数 × 输出单价)
总成本 = 视频时长(秒) × 每秒单价
每秒单价 = 分辨率系数 × 帧率系数 × 模型溢价
其中输入部分包括三部分内容:
- 系统提示词(SystemPrompt):你给模型设定的角色和行为规则,如”你是一个专业的法律顾问”。通常100-2000Token。
- 历史对话(Conversation History):之前所有的对话内容,包括用户提问和模型回复。随着对话轮次增加,这部分Token会不断累积。值得注意是,历史对话会不断叠加和累积,好处是它会记住你的信息,每一次的回答会更精准,当然代价也很明显,就是上下文窗口的带来的巨大增加而导致的Token消耗也会变多。
- 当前用户输入(User Message):用户本次发送的内容。
输出Token(Output Tokens)只有一部分:
模型生成的回复:模型针对用户输入生成的全部文本内容。
但是通常来说,输出的定价一般都会高于输入的定价,原因在于推理过程的计算量差异。大模型的推理过程分为两个阶段:
- Prefill阶段(预填充):处理输入Token。这个阶段可以并行计算——模型同时”阅读”所有输入Token,计算速度很快。你可以把它想象成”一口气读完一篇文章”,虽然文章很长,但你可以快速扫完。
- Decode阶段(解码):生成输出Token。这个阶段必须串行计算——模型每次只能生成一个Token,每生成一个Token都需要参考之前所有的Token(包括输入和已生成的输出)。你可以把它想象成”逐字写文章”,每写一个字都要回头看看前面写了什么。
因为Decode阶段是串行的,每生成一个Token的计算量远大于Prefill阶段处理一个Token的计算量。具体来说,生成一个输出Token的GPU计算时间,大约是处理一个输入Token的5-10倍。这就是为什么输出Token的单价是输入Token的2-5倍。
我认为这个问题可以简单的去理解,好比如你阅读一本书,和你自己去写书一样,前者对于大脑算力的消耗会更小一些,而后者要涉及到创作和灵感,也更费脑,你可以一目十行,也可以一天读完一本书,但是你不能在短期内创造出一个好的作品。
文生图模型:
文生图模型(如image2、seedream)的计费方式与文生文模型完全不同——它不是按Token计费,而是按”张”计费。你输入一段文字描述,模型生成一张图片,你付一张图片的钱。
为什么文生图不按Token计费?因为文生图的成本主要不在”理解文字”上,而在”生成图片”上。理解你的Prompt可能只需要几百个Token,但生成一张1024×1024的图片,需要模型在像素级别进行数百万次的计算。所以,文生图的计费单位是”张”而不是”Token”——文字输入的Token消耗相对于图片生成的计算成本可以忽略不计。
不过,文生图的”按张计费”并不是一个固定价格——它受到多个因素的影响,其中最重要的是分辨率和推理步数。
分辨率是影响文生图价格的最主要因素。分辨率越高,图片的像素越多,模型需要计算的数据量就越大。1024×1024的图片有约100万像素,2048×2048的图片有约400万像素——像素量翻了4倍,计算量也近似翻了4倍,所以价格也相应增加。
这一步和后面讲到的视频模型相同,因为推理步数(Inference Steps)是另一个影响价格的因素,但在主流API中通常不直接暴露给用户。推理步数是指扩散模型(Diffusion Model)从纯噪声逐步去噪到最终图片的迭代次数。步数越多,图片质量越高、细节越丰富,但计算时间也越长。大多数API默认使用30-50步,如果你需要更高质量(如80-100步),可能需要支付额外费用。
还有一个容易被忽略的因素:图片数量。很多平台默认一次生成多张图片(如4张),让你选最好的一张。这意味着你实际支付的是4张图片的价格,而不是1张。Midjourney就是这种模式——一次生成4张,如果你只要1张,也需要付4张的钱。印象中Nano banana也是默认一次性出四张图的,很多国产模型也是优先出两张,这个需要特殊情况来定,主要还是使用的习惯不同。
视频生成模型:
按 token 单价 × token 用量=按 token 单价 × (输入视频时长+输出视频时长) × 输出视频的宽 × 输出视频的高 × 输出视频的帧率/1024
文生视频是当前所有AI生成模式中成本最高的——一段5秒的1080p视频,价格可能相当于生成50-100张同分辨率的图片。
主要也是因为计算量的指数级增长。一张1024×1024的图片有约100万像素需要计算;一段5秒24fps的1080p视频有120帧,每帧约200万像素,总共需要计算2.4亿像素——是单张图片的240倍。而且视频还需要保证帧与帧之间的时序一致性(不能前一秒是白天下一秒变黑夜),这增加了额外的计算复杂度。
更具体地说,视频生成的计算成本来自三个维度:
- 空间维度:每帧图片的像素量,由分辨率决定。4K视频每帧的像素量是720p的9倍。
- 时间维度:视频的总帧数,由时长和帧率决定。10秒30fps的视频有300帧,5秒24fps的视频有120帧。
- 一致性维度:保证帧间连贯的额外计算。这是视频生成独有的成本,图片生成不需要。

不过也有一些别的部分会影响到整体视频生成的token消耗:比如是否输入包含图片和视频,包含的话就会很耗时更高,同样token消耗也更高,这也侧面说明了文生视频的成本远低于图生视频,因为前者这一块的文本token几乎可以忽略不计。
这里我有一个建议:就是现在很多模型推出了fast版本,为了弥补视频生成时间慢、token消耗大的问题而解决的,1因此大家在用视频的时候,尤其是在前期可以优先去使用一些fast 模型,同时降低画质的帧率,在给到的提示词、图片和人物参考不变的情况下,看看最终出来出来的效果如何,在空间上、一致性上是否存在较大的误差,如果在此基础上没有太大问题,可以重新给出一个branch,然后生成优质高清的视频,如果有问题,那就要回溯,查询每一个步骤的图片和提示词。这样整体的成本可以极大降低,反而提高了生产效率。
大模型的成本主要由五部分组成:
- PU算力成本(约55%):这是最大的成本项。训练一个大模型需要数千张GPU运行数月,推理服务需要持续运行GPU集群。一张NVIDIA H100 GPU的价格约20-30万元,一个千卡集群的硬件投入就超过2亿元。加上训练成本(GPT-4级别的模型训练一次约1亿美元),算力成本是压在每家厂商头上的大山。
- 电力和散热成本(约15%):GPU是电老虎——一张H100的功耗约700瓦,一个千卡集群的功耗约700千瓦,相当于一个小型工厂的用电量。数据中心的电费和散热费用是持续支出,且随规模线性增长。
- 研发人力成本(约15%):顶尖AI研究员的年薪在百万美元级别,一个核心团队(50-100人)的年人力成本就超过5000万美元。而且人才极度稀缺,各家厂商在抢人上的投入不亚于抢GPU。
- 数据成本(约10%):高质量训练数据的采集、清洗、标注成本不菲。尤其是专业领域数据(法律、医疗、金融),获取成本更高。
- 利润(约5%):当前大多数厂商的API利润率并不高,部分厂商甚至亏本运营——用低价换规模,期待规模效应降低成本后盈利。
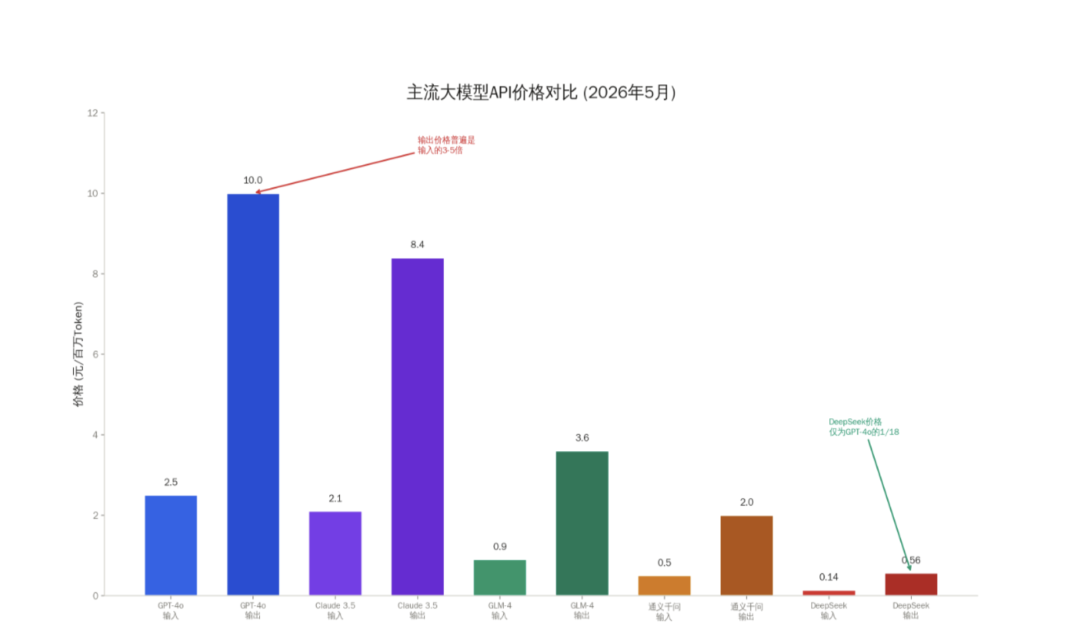
从图中可以看到,不同厂商的价格差异巨大——DeepSeek的输入价格只有GPT-41/18。
这种价格差异是怎么产生的?
因素一:推理优化技术的差异。这是价格差异最大的来源。推理优化包括量化(降低模型精度以减少计算量)、蒸馏(用大模型训练小模型以降低推理成本)、投机解码(用小模型预测大模型的输出以加速推理)等技术。DeepSeek之所以价格极低,核心原因就是它在推理优化上做到了极致——通过MoE(混合专家)架构和多头潜在注意力机制,把推理成本降到了同级别模型的1/10以下。
因素二:算力成本的差异。海外厂商(OpenAI、Anthropic)主要使用NVIDIA GPU,价格高且供应受限;国内厂商部分使用国产GPU(如华为昇腾),成本更低。此外,中国的电价和人力成本也低于美国,进一步降低了运营成本。
因素三:定价策略的差异。这是”非成本”因素,但对价格影响巨大。OpenAI和Anthropic采取”高价值定价”——它们认为自己的模型质量最好,应该收更高的价格,用高利润支持持续研发。DeepSeek采取”渗透定价”——用极低价格快速获取用户和市场份额,建立生态壁垒。国产模型(通义千问、GLM-4)介于两者之间——质量接近海外模型,但价格更低,以性价比竞争。
但是每家厂商都面临这个两难选择:降价可以获取更多用户和消耗量,但会压缩利润空间;维持高价可以保持利润,但可能流失价格敏感的用户。当前的市场格局是:头部厂商(OpenAI、Anthropic)选择维持高价,因为它们有质量优势和品牌溢价;追赶者(DeepSeek、通义千问)选择低价,因为它们需要用价格换市场。如果所有模型的能力趋同(即用户觉得用哪个模型都差不多),那么价格就会成为唯一的竞争维度,最终走向价格战。这就是为什么各家厂商拼命在模型能力上做差异化——OpenAI强调推理能力和多模态,Anthropic强调长文本和安全对齐,DeepSeek强
调性价比和代码能力。差异化是避免价格战的唯一武器。字节的see dance2.0由于在模型能力上的提升,导致其他厂商无法与其抗衡,进而形成垄断的局面,对于c段用户,他们会不断的购买会员和算力充值,相反企业会选择接入火山引擎的借口,但是门槛会更高。相比于其他模型厂商求着别人使用他们的模型,字节在AI视频领域似乎没什么压力。这里也作为补充,云厂商的模型销售(Maas)不同于传统的SaaS的销售逻辑逻辑,大模型是一个前期投入成本极高但是边际成本极低的行业,这也就意味着厂家需要在一开始投入大量的算力和人力在研发上,但是一旦商业模式跑通或者实现盈利,那么整个的研发和和基础设施投资都会被摊薄。在火山内部,token的消耗量也是作为业务发展的核心指标,类似于传统电商的GMV。
最后就是,开源模型的存在,给闭源模型的定价设定了一个”天花板”——如果闭源模型的价格远高于自部署开源模型的成本,用户就会选择自部署。所以闭源模型的定价必须考虑开源模型的竞争压力。这也是为什么DeepSeek敢于定这么低的价格——它知道自己的开源版本已经设定了价格上限,不如主动把API价格降到接近开源自部署的成本,把用户留在自己的生态里。
本文由 @迭代 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!