
 起点课堂会员权益
起点课堂会员权益最贵的模型卡死了我的流程,小模型却救了它-AI 选型的反常识
在AI模型疯狂迭代的时代,产品经理们正陷入一场无休止的'参数军备竞赛'。本文作者通过亲身经历的血泪教训,揭示了'最强模型'神话背后的陷阱:86秒的进度条、180秒的卡死,以及那些信誓旦旦给出错误答案的0.9高分。从'SOTA FOMO'焦虑到'四问选型法'实战指南,这篇文章将彻底改变你对AI模型选型的认知——原来,'够用就好'才是更高级的产品智慧。

一场我亲手制造的”车祸现场”
前段时间,我做一个需要批量处理图片的项目。一上来,我就给它配了当时能找到的、参数最大、最被看好的一个模型。逻辑很朴素:这是个重要项目,用最强的总不会错吧?最强的模型,就是最稳的保险。
结果第一页跑完,用了 86 秒。我当时没太在意,想着第一次冷启动慢点正常。然后第二页,180 秒,接着——整个流程卡死了。我盯着那个转了三分钟还没停的进度条,心里第一个念头不是”模型不行”,而是”是不是我哪里配错了”。因为在我的潜意识里,这么强的模型怎么可能这么拉胯,一定是我的问题。
折腾了半天,我抱着试试看的心态,换了一个参数小了整整一个量级、定位也轻得多的模型,跑同样的活。单页 2.3 秒,快了几十倍,而且效果还更稳。
更讽刺的事还在后面。那个被我供起来的”最强”模型,不光慢,它还有个要命的毛病:它会一边输出错误的结果,一边给自己打 0.9 的高分,信誓旦旦地告诉我”我对了”。我让它评估自己每一次输出的可信度,它几乎每次都锁在 0.9 以上,哪怕那次答得离谱。
那一刻我突然清醒了。我根本不是在解决问题,我是在为”我用上了最强模型”这件事本身,买一份心理安全感——而这份安全感,差点把我的项目搞崩。
这件事过去之后,我开始反复琢磨一个问题:作为一个天天跟 AI 打交道的产品经理,我们到底从什么时候开始,把”用最强的模型”当成了一种默认正确、不容置疑的政治正确?这篇文章就是我对这个问题的复盘,不讲虚的,全是我自己踩出来的教训。我想聊清楚一件事:在这个模型每周都在”登顶”的时代,”够用就好”不是一种妥协,而是一种比”无脑追最强”高级得多的产品能力。
一、参数焦虑:一场你不必参加的军备竞赛
1.1 我们都得了”SOTA FOMO”
先说个现象,你一定不陌生。打开任何一个行业群、任何一个技术媒体,这个月的标题永远是”谁谁谁登顶了”——Kimi 登顶、DeepSeek 反超、通义刷新纪录、某海外大厂又发布了新一代旗舰,榜单每周都在换王。
在这种信息轰炸下,一种集体焦虑悄悄蔓延。我管它叫”SOTA FOMO”——生怕自己用的不是最先进的(State-of-the-Art),生怕一旦落后半个版本,自己做的产品就”不够格”了。
这种焦虑具体表现成什么样?最典型的是选型会上,没有人敢拍板用那个便宜的、够用的模型。因为万一出了问题,”你为什么不用最好的”这句话谁都担不起,于是大家默契地往最贵最强的那个靠,仿佛只要用了顶配,技术上就立于不败之地。另一种表现是永远在追新:这个月刚把模型接进去,下个月新版本出来了,立刻就觉得自己手里的”过时了”,心里痒痒,总想换。最近我还看到有同行在聊”请收起你们的算力自嘲”,大意是别动不动就拿”我用的模型不够强”来自我调侃——你看,连”焦虑”本身都成了一种社交货币。
但我想问一句:这份焦虑,真的是你的吗?
1.2 焦虑是谁制造的
我们冷静想想:到底是谁,在不遗余力地告诉你”算力永远不够”、”模型必须更强”?是卖算力的,和堆参数的。
这话不是阴谋论,而是最朴素的商业逻辑——卖铲子的人,永远希望你相信金矿挖不完、铲子不够用;做模型的厂商,它的整个估值故事就建立在”我比上一代更强、比对手更强”之上。他们的商业模式,决定了他们不可能站出来跟你说一句:”兄弟,你这个场景,用便宜的就够了。”这不是他们坏,是屁股决定脑袋,指望卖铲子的告诉你不需要买铲子,本来就不现实。
所以你得分清楚:行业里那些铺天盖地的”参数焦虑”,有相当一部分是别人的增长叙事,需要你来买单。你以为你在追逐技术前沿,其实你可能只是在替别人的财报添砖加瓦。
1.3 一个更扎心的陷阱:你以为的”最强”,可能是假的
这里还有一个坑,我也亲自踩过,必须拿出来说。很多人为了用上”最强模型”,会去找一些第三方的聚合通道、中转平台,因为便宜,因为方便,号称什么模型都能调。
但我吃过亏:有些通道,标的是最新最高的版本,实际给你的表现却对不上。你以为你调用的是顶配旗舰,实际上后台给你接的可能是个缩水版,甚至是别的模型套了个壳。只有官方直连,你才能确认自己用的到底是什么。
很多人精心呵护的”我用了最强模型”的优越感,可能从一开始就是个幻觉——你为”最强”付了钱,却连真货都没拿到。这件事给我的触动很大,它让我意识到,”追最强”这条路上从源头就埋着各种各样的坑。与其在一条充满陷阱的路上狂奔,不如先停下来问自己一个更根本的问题。
1.4 真正该问的问题
兜了这么大一圈,我想说的核心判断其实就一句话:产品经理的价值,不是”用上最强的模型”,而是”判断出你到底需要多强的模型”。前者是一种本能,是随大流的安全感;后者才是专业,是一种需要认知和判断力的硬功夫。
这个区别,是这整篇文章的地基。接下来,我想先帮你拆掉一个最大的误解——你为”最强”付出去的那笔溢价,到底买到了什么。
二、你买的不是分数,是那最后 10% 的溢价
2.1 榜单分数,和你的业务没那么大关系
我们先聊聊那些让你焦虑的榜单。各种评测榜单上,模型的数学能力、代码能力、推理能力,分数一个比一个高,看得人心潮澎湃。但你冷静下来想一个问题:一个模型在数学竞赛题上考了 97 分,跟你让它给商品写一段卖点文案、给图片做个分类、把一段话翻译成英文——这两件事之间,到底有多大关系?
答案是几乎没关系。榜单衡量的是模型能力的”上限”和”天花板”,而你的大多数业务场景,考验的是模型在一个具体、狭窄、重复的任务上稳不稳定,这是两个维度的事。一个能解奥数题的天才,未必能把超市理货这件简单的事做得又快又稳,甚至因为他”想太多”反而做不好。我开头那个卡死的故事,本质就是这个道理:我冲着榜单上那个最高的分数去了,却忘了我的任务根本不需要那个分数。
2.2 90% 和 100% 的差距,用户根本感觉不到
退一步说,就算最强的模型在你的场景里确实更好那么一点,这”一点”值多少钱?假设一个够用的模型能做到 90 分,最强的能做到 98 分,这 8 分的差距,在很多场景里你的用户根本感知不到。一段文案初稿,90 分的版本和 98 分的版本反正都要人来改一遍,差别在哪?一个图片分类,90% 和 98% 的准确率,对一个”后面还有人工抽检”的流程来说,区别真的有那么致命吗?
可为了这用户根本感知不到的一点点,我们却往往要付出翻倍、甚至更高的成本——这笔账,真的划算吗?
2.3 那笔溢价,换来的是什么
那么,你为”最后这 10%”付出去的溢价,到底换来了什么?很多时候,换来的是更高的成本、更慢的响应、过度的工程,是我开头那个卡了三分钟、最后崩掉的进度条。你以为你买的是”更好的效果”,实际上你买到的是更高的成本、更慢的速度、更大的不确定性,而那点”更好的效果”用户压根没看见。
没有人会开着一辆法拉利去楼下菜市场买菜。不是法拉利不好,是这个场景配不上它、也用不上它——你为那身性能多付的钱,全都浪费在了一段你根本跑不起来的路上。道理大家都懂,但落到具体工作里,怎么判断哪个场景配得上”法拉利”、哪个场景一辆买菜车就够?这就需要一套真正能用的方法。
三、核心方法:用”四问选型法”,算清你到底需要多强
接下来是这篇文章最实操的部分。我把自己这些年踩坑踩出来的判断逻辑,提炼成了四个问题。每次要选模型时别看榜单,先问自己这四句话,我管它叫”四问选型法”。
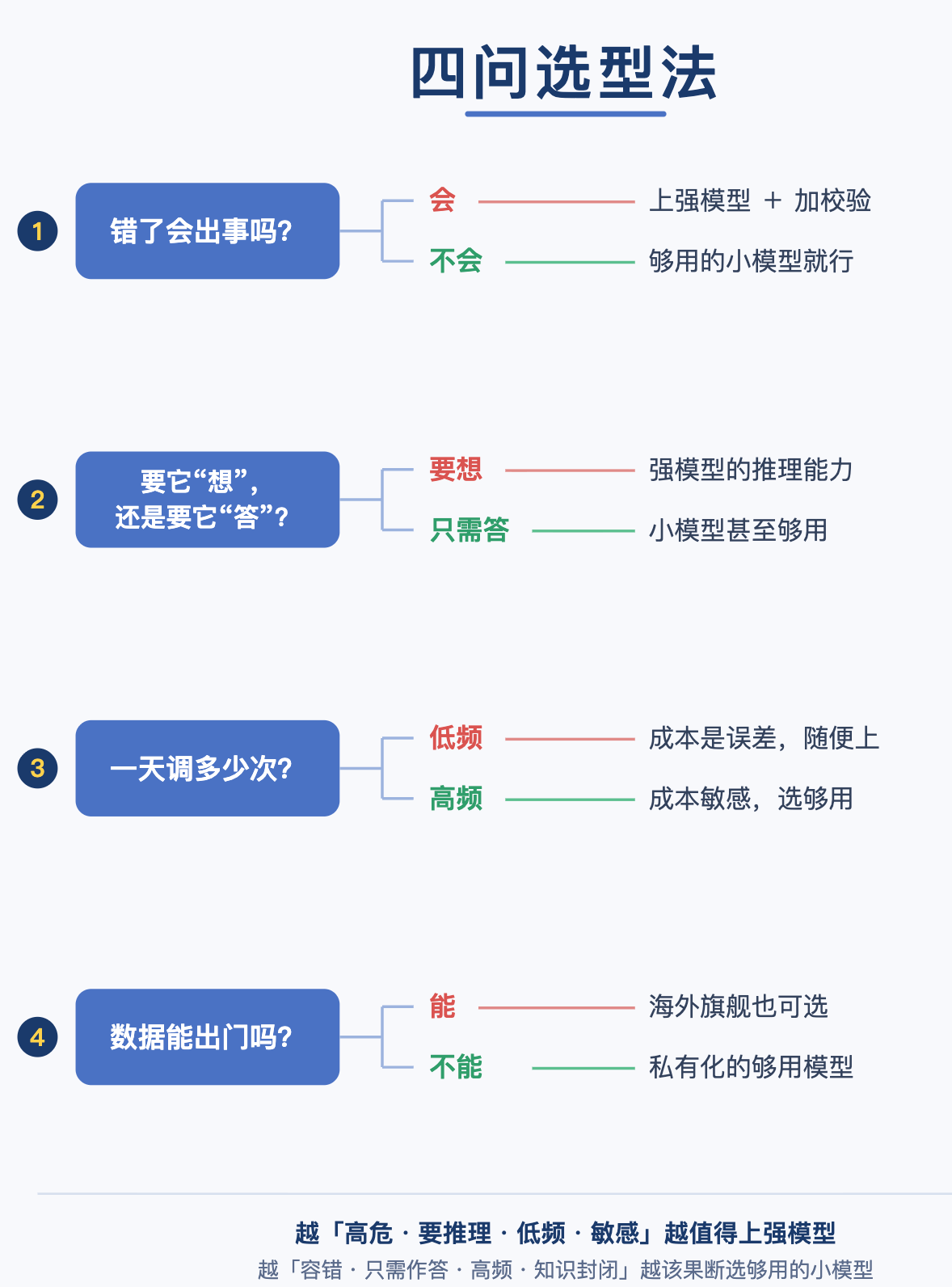
第一问:错了会出事吗?(看容错率)
这是最重要的一问,决定了你能不能”省”。你要判断的是:这个任务一旦出错,后果有多严重?有没有人兜底?
高容错场景,比如生成文案初稿、做内容的第一轮草稿,错了无所谓,反正后面有人会改、会审,这种场景中小模型完全够用。低容错场景,比如直接对外的合同条款、医疗相关的判断、没有任何人工复核的自动决策,错了就是事故,这种场景不仅要上强模型,还必须额外加一道校验。
举个反例:给”文案初稿”这种高容错的活,配一个最贵的旗舰模型,就是典型的浪费。正确的做法是文案用够用的模型快速出,然后让人来把关,把宝贵的预算和算力留给真正输不起的环节。
第二问:要它”想”,还是要它”答”?(看复杂度)
这个问题,帮你判断手上的任务到底吃不吃”模型的智商”。
只需要”答”的任务,比如分类、信息抽取、格式改写、简单翻译,这些都是”单步映射”,输入进去按规则吐出来就行,小模型甚至传统方法就能干,根本用不着大模型那身推理肌肉。需要”想”的任务,比如多步骤的规划、长链条的 Agent 任务、需要模型自己拆解问题再一步步推导的,这种”多步推理”才是强模型真正的价值所在,也是榜单上那个”推理分数”唯一和你的业务真正相关的地方。
一句关键提醒:千万别拿”推理榜的分数”去给一个只需要”答”的任务做选型依据,那就像用考研数学的成绩去招一个收银员。
第三问:一天调多少次?(看成本曲线)
调用频次,直接决定了”省钱”这件事到底值不值得你费劲。
低频场景,一天就调用几十次,模型贵一点便宜一点对总成本影响微乎其微,成本就是个”误差项”,那你完全可以任性,直接上最强的图个省心。高频场景,一天要调用几千、上万次,这时候成本就从配角变成了主角。
给你个我自己的真实体感:我做过的一个批量生成的场景,单条内容的成本就要五块多。你算一笔账——当这个量级铺开到每天几千条,模型每贵那么一点点,乘以这个调用量,再乘以 365 天,就是一笔能让你的项目直接黄掉的数字。在这种场景里,”够用就好”根本不是一种态度,而是一条硬约束——便宜哪怕一点点,乘以巨大的调用量,省下的都是实打实的真金白银。
第四问:要不要懂最新的世界?(看知识时效)
还有一个常被忽略、但极其关键的维度:你的任务,吃不吃”最新的世界知识”。
需要最新世界知识的任务,比如要回答最近发生的事、要依据刚出台的新规,这种场景要么上带联网能力的强模型,要么给它配一套 RAG(检索增强)。知识封闭、稳定的任务,比如处理你自己公司的业务规则、产品文档、内部流程,这些知识是固定的、不随外部世界变化,这种场景一个小模型经过微调,效果甚至比通用大模型更准。
为什么?因为在这种封闭场景里,你根本不需要模型”懂整个世界”,你只需要它”懂你”。一个什么都知道一点的通才,反而不如一个只精通你这一摊事的专才。
第五问(进阶):你的数据,能出门吗?(看合规边界)
最后补一个进阶维度,尤其是做企业内部、做 B 端的同行,一定要把它前置。这一问很简单:你处理的这些数据,能不能交给第三方?能不能出境?
如果你的数据高度敏感、不能离开内网、不能交给外部接口,那么对不起,再强的海外旗舰模型跟你都没关系,这一条本身就能帮你筛掉一大半选项。在这种场景下,决策逻辑会反过来:一个能私有化部署、能在你自己环境里跑的”够用”模型,价值远远高于一个你根本用不了的”最强”模型。合规这道门槛,会比性能榜单更早地帮你做完筛选。
把五个问题串起来
你不需要每次都做复杂的计算。一个简单的判断逻辑是:一个任务,越是”错了会出事、需要复杂推理、调用频次低、要懂最新世界、数据能外发”,就越值得上强模型;反过来,越是”容错高、只需简单作答、调用量巨大、知识封闭稳定、数据敏感”,就越应该果断选够用的小模型。把这五个问题变成你选型前的本能,你就再也不会被榜单牵着鼻子走了。
四、分场景速查手册:常见场景该用多强的模型
下面这张表,是我按”四问”的逻辑,把日常最常见的业务场景捋了一遍,你可以直接拿去开会用。这里特意用”档位”而不是写死具体型号,毕竟型号每个月都在变,但背后的判断逻辑不会变。三个档位的意思是:旗舰档是最贵最强的那批,主力档是性价比高、够用的中坚力量,轻量档是小模型、可微调、极便宜。
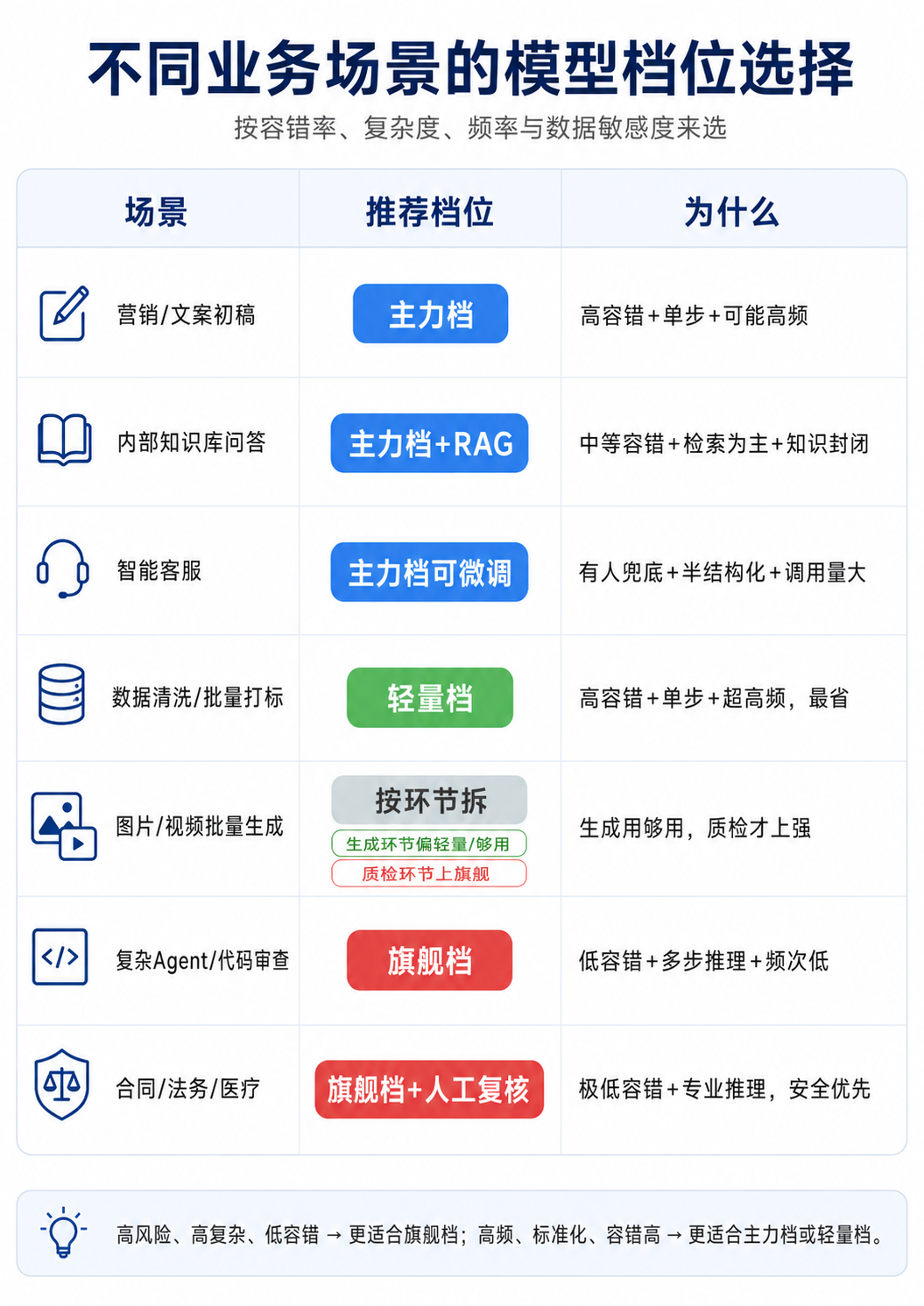
你会发现一个规律:真正值得上”旗舰档”的场景其实是少数,大多数日常业务,主力档和轻量档就能漂亮地解决——而且更快、更便宜、更稳。
五、什么时候该升级?别把”够用”做成”将就”
讲到这里,我必须踩一脚刹车,把话说平衡。这篇文章绝不是劝你”永远用小模型”、”能省就往死里省”。”够用就好”的反面是”无脑追最强”,但它的另一个反面是”一味将就”,两个极端都不对。
我自己就是个例子。前面我讲了一堆”省”的故事,但在另一个项目里,有个环节需要模型看懂一张很复杂的图,然后一步步推理出每个步骤分别要用到哪些零件——这种又要”看懂”又要”推理”的硬骨头,我反而老老实实选了能打的模型,还反复测它的准确率,一分钱没敢省。够用不是抠门,是把钱花在刀刃上,该省的地方狠狠省,该花的地方绝不手软。
那么,怎么判断一个场景”该升级了”?给你三个明确的信号。
信号一:抽检准确率,跌破了业务红线。 这是最直接的。当你的够用模型在实际跑下来的抽检中,准确率已经低于业务能接受的底线,那就是该升级了。注意是”业务红线”,不是”比最强模型低”——低于红线才是问题,单纯比别人低不是。
信号二:Bad Case 集中在”推理不足”,而不是”知识缺失”。 这一条最见功力,也最容易判断错。当模型出错时,你要去归因:它是”不知道”(知识缺失),还是”想不明白”(推理不足)?如果是知识缺失,比如它不知道某个新政策、不了解你的某个内部规则,那你该做的是补 RAG、补数据、补知识库,换更强的模型没用,因为它脑子够使,只是没看过这份资料。只有当错误集中在”推理不足”——资料都有,但就是绕不明白、推导不出来——这才是该换强模型的信号。把这两种 Bad Case 分清楚,能帮你省下大量”换了更贵的模型却没解决问题”的冤枉钱。
信号三:场景本身,从”单步”长成了”多步”。 业务是会演化的,一个一开始只需要简单作答的场景,随着需求叠加,可能慢慢变成了需要多步推理的复杂任务。当你发现任务的复杂度上了一个台阶,模型的档位也该跟着升。升级的依据永远应该是这些客观信号,而不是”隔壁又出了个更强的,我也想换”的焦虑。
结语:会做减法的产品经理,更值钱
回到我开头那个卡死的进度条。那次”车祸”教会我的,不是”小模型更好”这么简单的结论,而是一种思维方式的转变:在一个人人都在做加法、都在追求”更强、更大、更新”的时代,能冷静地做减法、能判断出”这里不需要那么强”,本身就是一种稀缺的能力。
AI 的能力正在以肉眼可见的速度溢出,模型越来越强,强到大部分场景都用不完它的能力。在这样的时代,产品经理的护城河,早就不是”我知道哪个模型最强”——这种信息谁都查得到,而且每周都在变。真正的护城河,是你能不能精准地判断:我的这个具体场景,到底需要多强的能力?多一分是浪费,少一分是冒险,那个”刚刚好”的点在哪里?
追逐 SOTA 是一种本能,是焦虑驱动的随大流;而判断”够用”是一种专业,是认知驱动的冷静决策。
所以,这周给自己留个作业:把你手上正在纠结、或者正在用着最贵模型的那个场景拿出来,用上面那四问(或者五问)认真过一遍,然后给它重新定一个”刚刚好够用”的锚。你很可能会发现,你一直供着的那个最强模型,其实大材小用了。
最后,送你一句我自己常拿来提醒自己的话:用最贵的模型,不会让你显得专业;看穿什么时候不需要它,才会。
本文由 @浩思AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pexels,基于CC0协议









关于“卖铲子的人希望你买更多铲子”这个逻辑很到位。做决策时确实得把厂商的立场考虑进去,别被他们造的焦虑绑架。
核心观点没问题,但“四问选型法”其实有点理想化。实际选型时,组织层面对责任的规避往往比成本和效果更决定结果——没人敢担“不用最强”的风险。
用最强模型反被卡死,换小模型又快又稳。作者点破一个真相:榜单分数跟业务场景是两码事,够用才是真智慧。