
 起点课堂会员权益
起点课堂会员权益Agent Scope全链路自动化:文档解析→数据建模→报表生成的实战拆解
在企业信息化领域,文档到报表的链路往往充满痛苦:格式混乱、数据清洗耗时、报表反复调整。Agent Scope作为一套全流程解决方案,不仅覆盖开发、部署、监控全生命周期,更关注生产级需求——可观测性、容错性、安全隔离。本文将深度拆解其三层架构设计、文档解析闭环、数据建模革命与报表生成自动化,为企业提供从Demo到落地的实战指南。

做企业信息化,相信大家太清楚企业里从文档到报表这条链路有多痛苦了。文件格式不统一、数据清洗耗时、报表反复调,一套流程走下来半个月没了是常态。这篇文章,把Agent Scope这套全流程方案掰开了揉碎了讲,给技术人员和信息化管理者提供可参考的思路。
一、从Demo到生产的鸿沟
先泼盆冷水:跑通一个智能体Demo和让这套东西在真实业务场景里稳定运行,中间差了十万八千里。
我见过太多团队,Demo演示的时候光鲜亮丽——”看,AI自动识别发票、自动填表、自动生成报表”。结果一上线,问题全来了:PDF扫描件识别率暴跌、表格结构识别错位、报表格式对不上甲方要求、跑着跑着内存溢出没人知道。业务方骂骂咧咧,技术方疲于奔命。
核心痛点:大多数所谓的”智能体方案”只是把几个API串起来,根本没有考虑到生产级的要求——可观测性、容错性、安全隔离、长时运行稳定性。
Agent Scope这套框架的出现,踩到了点上。它的核心定位很明确——“以开发者为中心,覆盖开发、部署、监控全生命周期的生产级解决方案”。注意”生产级”这三个字,不是实验室里的玩具。
二、理解Agent Scope:为什么它不是又一个框架
说到智能体开发框架,很多人的第一反应是:LangGraph、AutoGen、LlamaIndex……怎么又来一个?
我的判断:大多数框架解决的是”怎么写”的问题,Agent Scope解决的是”怎么跑”的问题。
三层架构设计
核心框架层负责智能体的构建和编排——用什么模型、怎么组织工具、消息怎么流转,这层决定了你写的代码长什么样。
Runtime层负责安全运行环境——智能体要在隔离的沙箱里跑,不能随便读你的文件系统、不能随便发网络请求。这层解决的是”能不能放心跑”的问题。
Studio层负责可视化监控——任务执行到哪一步了、消耗了多少资源、哪里出了错,统统可视化。这层解决的是”跑的时候能不能看见”的问题。
很多框架只有第一层,画个图、写几行Prompt就完事了。但企业生产环境里,后面两层才是命门。
核心能力一览
- 消息机制:Python字典作为消息载体,天然支持多模态数据传输
- 模型接口:ModelWrapper统一抽象,通义千问/GPT/Claude/DeepSeek一次编程多模运行
- 记忆系统:ReMe记忆压缩算法降低短期记忆占用60%以上
- 开发效率:模块化解耦,开发效率提升40%以上,运维成本降低约70%
个人判断:三层解耦设计让企业可以渐进式采纳,不用一步到位。先用核心框架跑通业务流程,Runtime和Studio可以后面再上。
三、文档解析:把非结构化黑盒变成结构化金矿
企业里80%的数据其实是非结构化的——PDF报告、图片截图、扫描件、手写表格。这些东西对人来说好理解,对机器来说就是黑盒。
传统OCR有两个硬伤:识别率不稳定(表格结构经常错位)、识别完了不知道怎么用(只是把图片变成文字,语义理解还得靠人)。
识别-理解-行动闭环
Agent Scope的解法是OCR+智能体的闭环:DeepSeek-OCR做识别,智能体做理解和行动。
DeepSeek-OCR七种模式:
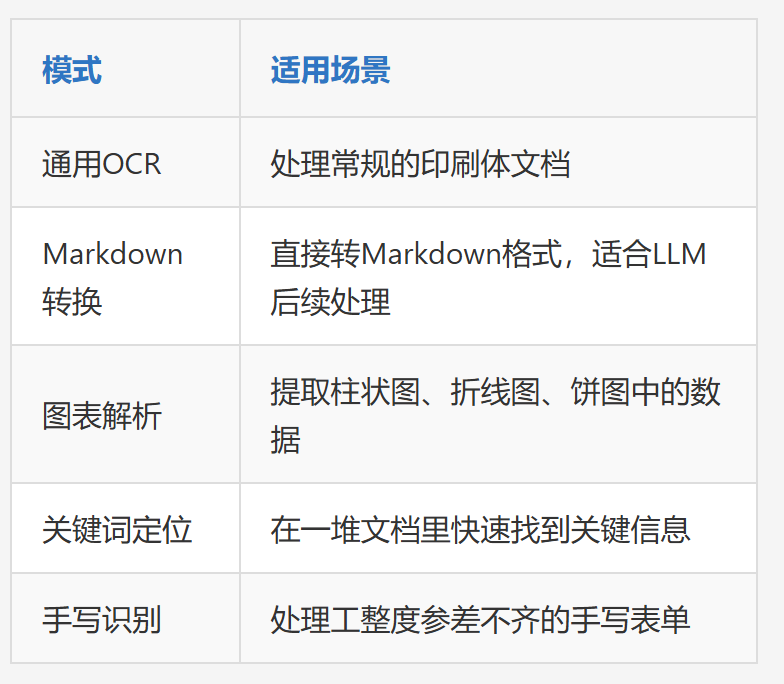
私有化部署:金融、政务的刚需
Docker一键部署,表格结构还原度能做到99%以上。数据不能出内网、模型不能上公有云的强监管行业,这是底线要求。
MCP协议(Model Context Protocol)即插即用的设计,对Java技术栈企业非常友好。能把文档解析封装成标准Tool注册到Agent Scope,不用改现有架构。
四、数据建模:自然语言驱动的分析革命
传统做法是写SQL、写Python脚本,让数据工程师跑一遍。问题在于:每次分析都要从头来,上次清洗的逻辑下次换个人可能就丢了。
Data-Juicer Agent的核心价值:用自然语言描述分析逻辑,智能体自动拆解执行。你说”把这三个月的销售数据按区域汇总,算出同比增长”,智能体自动拆解成:数据加载→字段清洗→分组聚合→计算增长率→格式化输出。不用写一行代码。
三层智能体协作
- 数据清洗Agent:去重、填充缺失值、统一格式
- 特征提取Agent:从原始数据里提炼有业务意义的指标
- 建模分析Agent:统计分析、趋势预测等高级操作
MsgHub消息总线负责三者通信,执行过程透明可视。
两个至关重要的能力
1. 实时介入控制:异步架构实现任务执行中动态中断与恢复。智能体正在跑耗时很长的分析,突然发现数据源有问题,直接暂停、修正、继续,不用从头重跑。
2. 安全沙箱:容器隔离执行环境,智能体只能操作授权的数据范围,不会误删核心库。
我的观点:建模的本质不是技术问题,是业务知识怎么被AI承载的问题。工具再先进,如果业务逻辑没有结构化地沉淀下来,AI也只能是空中楼阁。
五、报表生成:从”写代码”到”下指令”
报表生成是整条链路的最下游,也是业务方感知最强的环节。
传统做法:业务提需求→技术写代码→调格式→导出→反复修改。一来一回,一周没了。
Alias智能助手
核心能力:
- 配置后即时可用
- 快速迁移下游场景
- 前后端一体部署
直接说”给我生成一张本月各区域销售额对比的柱状图,带同比数据标注”,智能体自动选图表类型、自动格式化、自动输出。普通业务人员也能独立完成。
技术亮点
图表类型智能匹配:根据数据特征自动判断——对比用柱状图、趋势用折线图、占比用饼图
多格式输出:HTML/Markdown/PDF/Excel
流式展示:AgentScope 2.0 Content Block支持实时看到报表生成进度
Java 2.0:无状态水平扩展、多租户隔离、可嵌入Spring Boot
六、全链路集成:单点能力再强,闭环才是王道
前面把三个环节拆开讲了。但实操中,关键不是每个环节有多强,而是环节之间的衔接有多稳。
三层结构
输入层:接收PDF、图片、Excel、Word,统一转成标准化内部格式
处理层:文档解析→数据清洗→特征提取→建模分析,通过MsgHub串联
输出层:报表生成和多样化输出
三级容错机制

我的感悟:全链路自动化的关键不在于每个环节的AI有多智能,而在于环节之间的衔接有多可靠。一条链路跑100次,99次成功1次失败,业务方对你的信任就会归零。

七、选型建议:三大框架对比
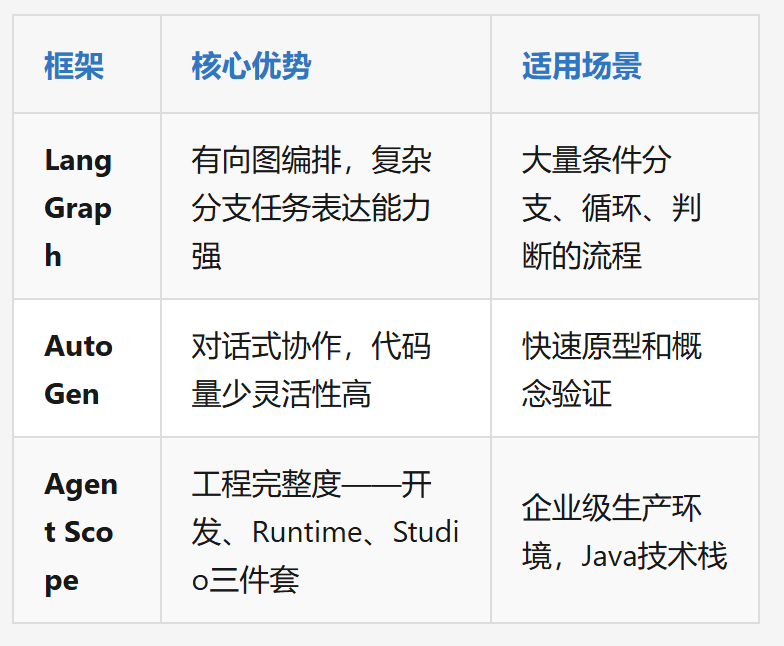
Agent Scope的独特价值:Runtime和Studio层能兼容LangGraph和AutoGen,可以在Agent Scope里跑其他框架的方案,不用非此即彼。
选型建议:先用轻量级单机部署验证,确认可行再切K8s分布式。中小规模场景下一键启动,跑通全流程,验证效果再考虑弹性扩展。
八、结语:全链路自动化不是终点,是起点
从文档到报表这条链路,传统做法是人在中间当桥梁——文档要人读、数据要人洗、报表要人调。Agent Scope的本质,是让AI替代人做这些连接工作,人从“操作者”变成“决策者”。
未来的企业信息化,不是人围着系统转,而是系统围着数据转。谁能先把数据从文档里解放出来、把分析逻辑固化下来、把报表生成自动化,谁就占据了效率高地。
对不同角色的意义
对技术人员:掌握Agent Scope意味着你有能力设计智能化解决方案,不只是调用API。框架思维、架构能力、系统集成经验——这些在AI时代只会越来越值钱。
对信息化管理者:这套方案提供了从效率瓶颈迈向全流程数智化的可行路径。不是all-in的概念验证,是可以渐进落地的生产级方案。
全链路自动化不是终点,是起点。
谁先跑通全链路闭环,谁就占据先机。
本文由 @数智产研笔记 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议









生产级这个点抓得准,很多Demo在实验室跑得欢,一上线就崩。可观测性和容错性才是企业敢用的前提,Agent Scope能把这俩单独拎出来做成层,比单纯堆框架靠谱。
三层架构的定位确实切中痛点,但Runtime和Studio层对LangGraph等框架的兼容性在实际迁移中可能没那么顺滑,企业里往往有多种技术栈并存,适配成本容易被低估。
从文档到报表的链路一直很痛苦,格式乱、清洗耗时、报表反复调。文章把Agent Scope的三层架构讲清楚了:核心框架管怎么写,Runtime管安全运行,Studio管监控。关键判断是生产级方案不能只拼接口,还得看可观测性和容错性。最后落脚到人从操作者变成决策者,这个视角挺好。