
 起点课堂会员权益
起点课堂会员权益同一个模型,为什么你的 Agent 没有别人的好用?
同样的基座模型和任务场景,为什么有的团队三个月就能让 Agent 跑真实业务,有的团队却一直在修 Bug?其实差距往往不在模型本身,而在幕后的数据工程。这篇文章聊了聊我们在训练 GUI Agent 时踩过的一些坑,比如数据同质化、忽略异常状态、标注不一致等,并分享了从场景拆解到 Bad Case 复盘的几点实际做法,希望能帮大家在堆数量之外,重新看看数据的设计。
去年年底和同行聊天,发现一个挺扎实的怪现状:大家都在做 GUI Agent,两边团队用的基座模型差不多,任务场景也高度接近。结果一个团队三个月就让 Agent 接了真实业务,另一个做类似场景的团队却还在测试环境里反复调试修 Bug。最开始大家都以为是模型能力或者策略有差距,后来一起复盘才发现,问题压根没出在模型本身,而是出在数据准备阶段——更准确地说,是数据设计的底层逻辑掉坑里了。
过去大半年的行业讨论,大家都把目光死死盯着模型上限,比如参数量、推理链、多模态跑分。但真正扎进项目里去控全流程质量的时候,我越来越觉得,决定 Agent 能不能稳定落地的,往往不是模型的上限,而是数据的下限。
很多时候模型反复在同一个地方翻车,问题未必在训练框架,而是数据本身存在致命的缺口。每当 Agent 表现不符合预期时,我后来养成的习惯是先别急着怀疑模型,回头去翻翻训练集,答案通常就藏在里面。
一、先说个很容易被忽略的问题:数据多,不代表数据有效
刚接触这类项目的时候,我也曾经觉得数据量是最重要的指标。毕竟从直觉上看,训练数据越多,模型见过的内容越丰富,效果似乎就应该越好。但后来参与项目多了,我发现事情并没有这么简单。
有一次在整理训练集的时候,我专门抽样看了几千条数据。原本以为数据量已经足够大,覆盖也应该比较全面,结果翻着翻着就发现了问题。大量样本其实都在重复描述同一种场景。看起来数据很多,但真正有价值的信息并没有增加多少。类似的问题在 GUI Agent 项目里尤其常见。
有些团队会投入大量精力采集页面截图、整理界面数据、组织标注工作,最终得到一个规模相当可观的数据集。但当你真正去分析这些数据时,会发现很多样本之间高度相似。我参与过一个电商后台相关的项目,训练集里积累了大量页面截图。乍一看数量不少,但进一步统计后发现,绝大部分都是商品详情页或者首页展示页。而 Agent 真正需要频繁操作的商品配置页面、库存管理页面、权限设置页面,占比却非常有限。结果也很直接。模型对商品图片、商品信息的识别能力不断提升,但一旦进入真实后台环境,需要完成具体操作任务时,表现却没有达到预期。
后来复盘时大家才意识到,问题并不在于数据不够,而在于数据覆盖不足。这也是我后来越来越重视的一件事。数据量和数据覆盖率,其实是两个完全不同的概念。前者解决的是“见过多少”,后者解决的是“见过什么”。如果新增的数据始终围绕同一类场景展开,那么即使规模扩大十倍,也未必能给模型带来对应的能力提升。
相反,一些数量不算特别大、但场景覆盖足够丰富的数据,往往更容易帮助模型建立稳定的判断能力。在实际项目里,我越来越倾向于优先考虑覆盖率,而不是单纯追求规模。因为 Agent 在真实业务环境中遇到的问题,从来不是重复出现的一张页面,而是各种各样没有预料到的情况。而这些情况,恰恰决定了模型最终能走多远。
二、真正拉开差距的,是数据工程的颗粒度
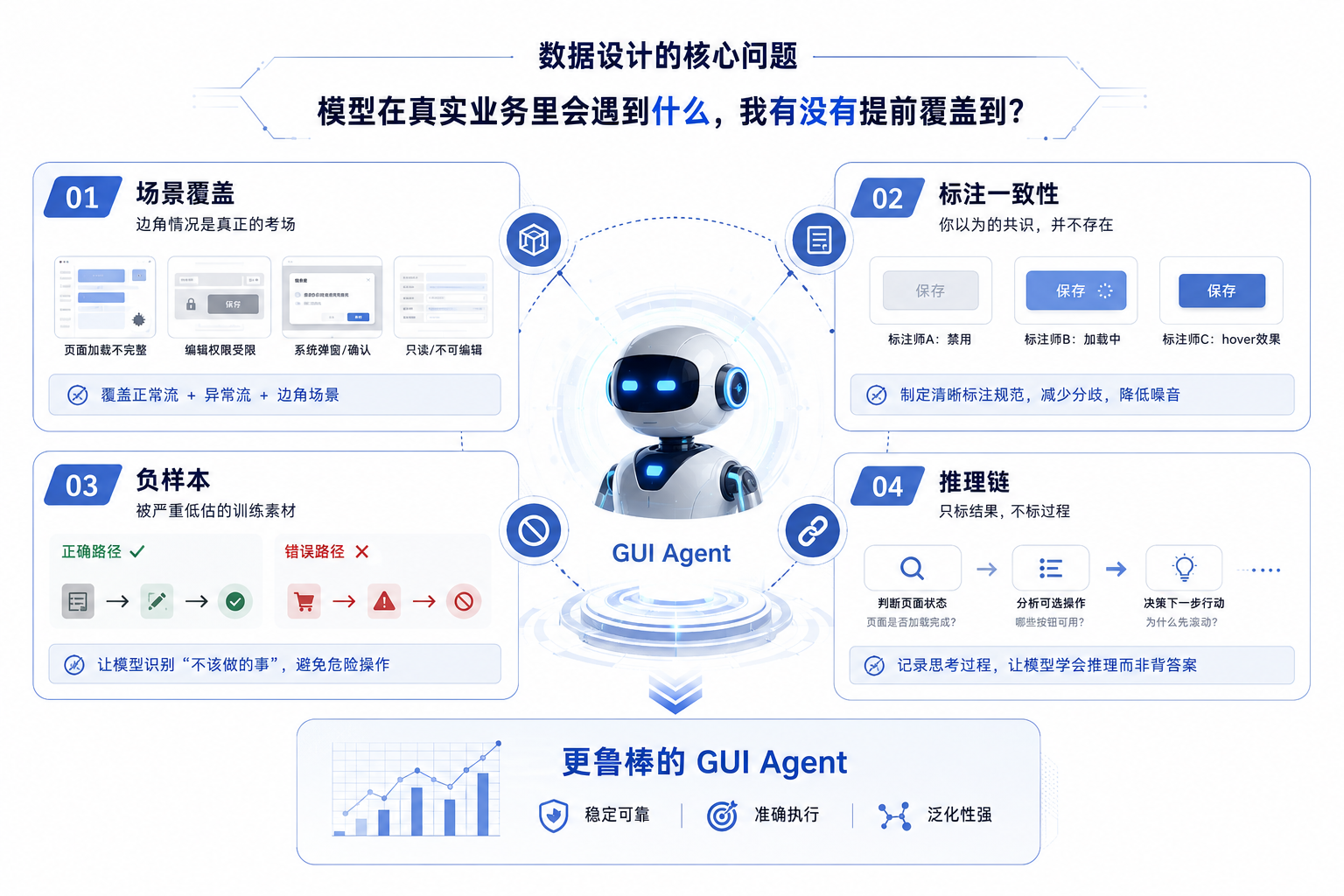
GUI 界面的标注和传统的自然场景标注不一样,它是个复杂的移动靶。页面 UI 会迭代,不同分辨率、浏览器、深浅色模式下的渲染结果差异极大。很多团队的数据采集逻辑是“有什么就喂什么”,而不是“需要什么就设计什么”,这直接导致了三个致命的硬伤:
边角情况完全断档
正常情况下,页面加载完整,输入框清晰,点击保存即可。但在真实业务里,网络慢导致页面只加载了一半怎么办?商品被锁定编辑、保存按钮变灰怎么办?系统突然弹出一个未预期的二次确认弹窗怎么办?采集数据时,大家默认走的都是最顺的那条路,这些异常状态在训练集里几乎为零。Agent 一碰到复杂页面立刻懵掉,而偏偏这些边角情况,才是真实业务里的家常便饭。
标注规范变成了糊涂账
同样一张截图,一个按钮处于半透明状态,标注师 A 认为是“禁用”,B 认为是“加载中”,C 认为是“hover 效果”。如果没有极度清晰的边界定义,这种标注噪音会大量混进训练集,模型学到的就是一锅粥,判断自然开始飘。不少团队在标注规范上偷懒,觉得“大家经验差不多,口头对齐一下就行”,但往往越是觉得不需要规范的地方,分歧就越大。比如按钮的五种状态、弹窗与浮层的视觉层级关系,如果不提前白纸黑字写清楚反例,每个人都会按自己的主观直觉来标。
极度缺乏负样本与推理链
绝大多数团队只喂正确示范,告诉 Agent 点哪里是对的,但从来不喂“做错了什么”或“点了会触发不可逆翻车的危险路径”。负样本的价值,恰恰是帮 Agent 建立安全边界,学会识别“不该做的事”。同时,很多标注任务只记结果(点击某个坐标),不记过程。优秀的训练数据应该要求记录标注师的判断依据——我为什么认为这个按钮当前可用?我凭什么判断页面加载完成了?把这种“思考过程”写进数据,模型才有机会学会真正的推理,而不是死记硬背建立输入到输出的死板映射。
三、别让标注人员的认知偏差,成了模型的隐形天花板
在数据生产里,人的主观偏差往往被严重低估了。比如在标注“当前页面的主要操作区域”时,大多数人受日常使用习惯影响,会本能地倾向于往页面的右上角或右下角找按钮。如果某个特定业务系统的操作按钮偏偏设计在左侧,这种人类惯性带来的标注偏差就会直接变成模型的偏见,导致它在陌生界面里一味地去右上角盲目搜寻。这时候,数据设计就必须主动介入,通过强行覆盖常规布局的反例,来对冲掉这种隐形噪音。
更普遍的问题是,很多团队的数据生产流程是单向的——采集、标注、送训,然后就切断了。模型跑得不好,大家就去调推理策略、改模型参数,很少有人回头查数据。如果我们不建立一个紧密的 Bad Case 复盘闭环,数据生产就成了往一个漏水的桶里不停倒水。每次 Agent 出错,必须把出错截图和操作链路存下来,反向推演:是标注错了,规范没写清,还是这类场景的数据压根就是空白?
四、我们在业务一线总结的几点实际做法
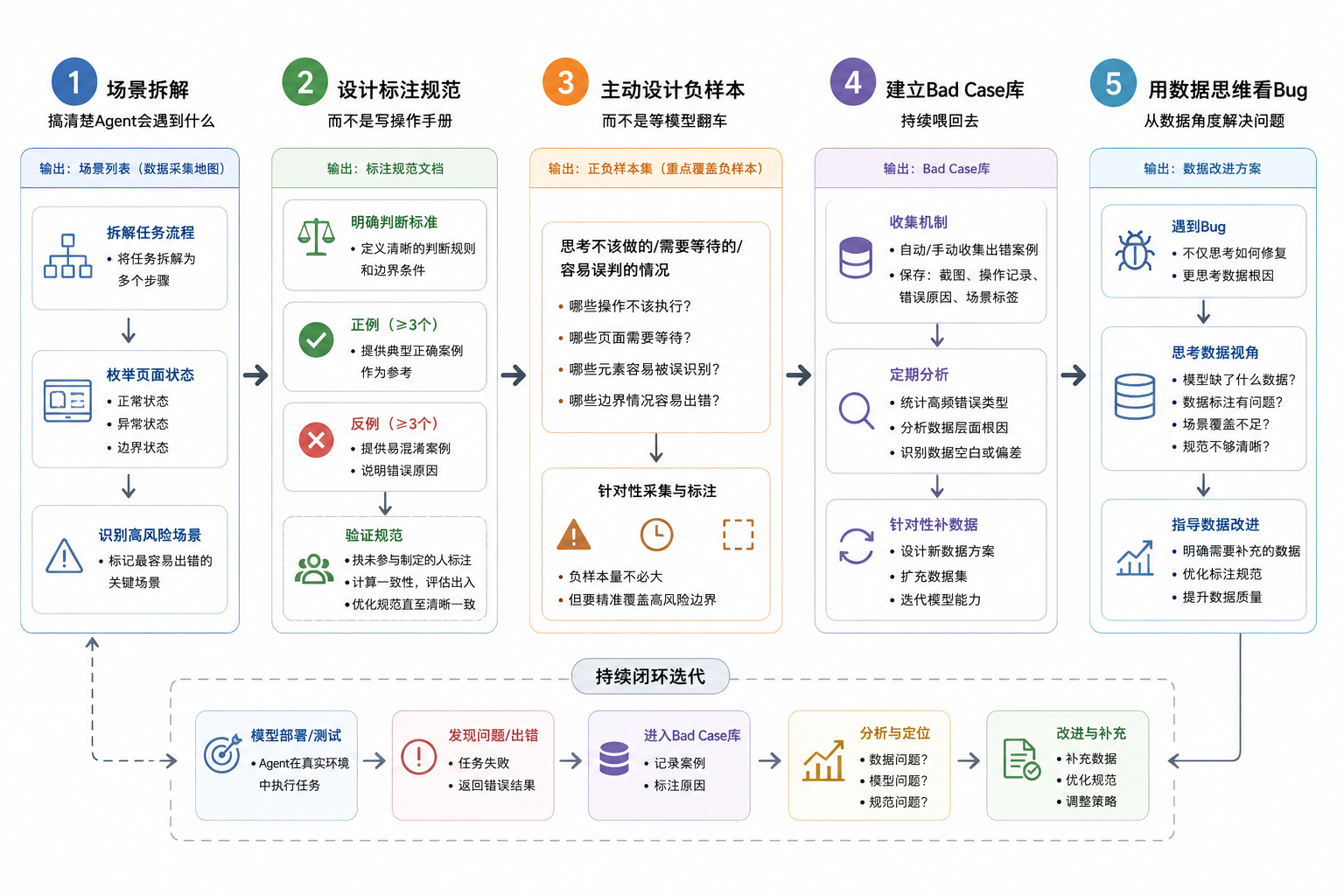
现在基座模型迭代太快了,开源和闭源的差距在快速收窄,任何团队都很难在模型架构上保持长期绝对的领先。能持续筑起护城河的,一定是看谁能把垂直行业的数据工程做得更深、更准。如果你的 Agent 效果也遇到了瓶颈,建议别急着折腾模型,从现在开始可以咬牙切齿地把这几件事落地:
首先,彻底丢掉“完成商品上架”这种粗颗粒度的任务描述,把它拆解成一张场景全景地图,列出每一步可能遇到的所有正常和异常页面状态,拿它去对齐数据缺口。其次,重写你的标注规范,把空泛的操作手册改成“判断标准说明书”,里面举反例的篇幅应该比正例还要多,重点规范那些有歧义的边界情况。
同时,在设计之初就主动把负样本和思考链(Thought Chain)规划进去,强迫模型去见一见那些最容易出错的坑。最后,也是最见效的一点,建一个动态的 Bad Case 库,把线上翻车的 Case 变成结构化数据定期喂回去。我们团队之前带过一个项目,模型一行代码没改,只是花了两周时间把场景列表重新对齐,补齐了异常状态数据,并用几十个争议边界案例把标注规范重写了一遍,两个月后 Agent 的业务准确率直接从不到 60% 稳步拉升到了 82%。
做 Agent 落地,很多时候拼的不是高大上的算法故事,就是看谁更愿意沉下心,在这些脏活累活的数据细节里多抠出几厘米。
本文由 @下一个Token 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









非常认同数据覆盖优先于规模的判断。尤其GUI Agent面对的是动态界面,覆盖率不够模型就像只学过标准答案的考生,一遇变体就懵。
确实,动态界面变数太多,光堆模型规模,没场景覆盖,稍微变一下Agent立马就抓瞎。泛化能力得靠“见多识广”
数据覆盖和标注规范的痛点说得很准,但负样本的收集难度其实被低估了,真实业务里危险路径的标注成本很高,不是所有团队都能轻松做到。
太懂了,很多团队不是不想做,是预算和精力根本撑不住这种消耗