
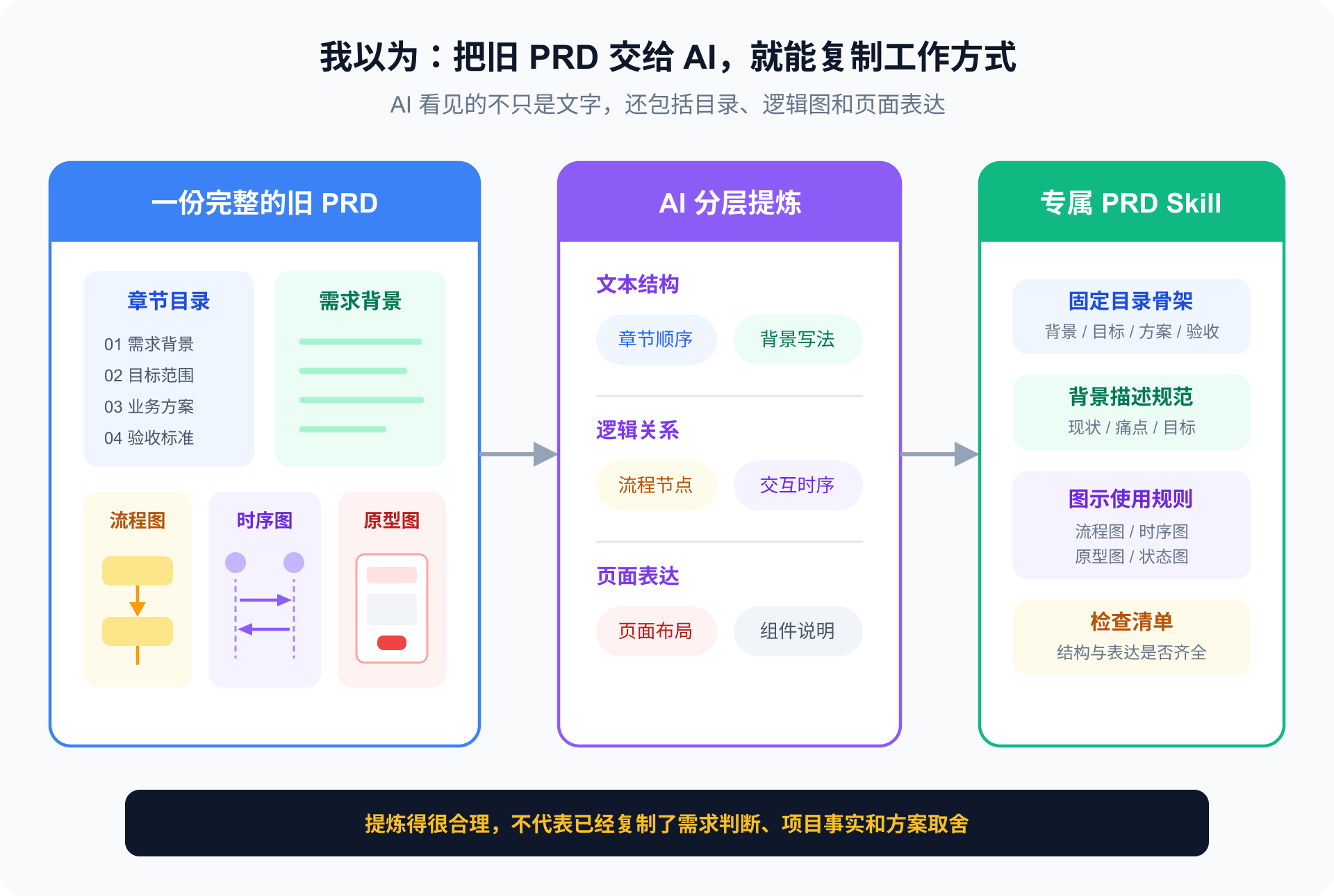
 起点课堂会员权益
起点课堂会员权益我做了一份“像我”的 Skill,为什么换个需求就失效
这是「AI 协作」系列二第 4 篇。上一篇看见了市场通用版的适配缺口;这一篇进入第一次跃迁:把旧 PRD 中的结构、颗粒度和表达方式,改成 AI 可以执行的输出标准。

读完这篇,你不需要马上做出一份完整 Skill。先从一份真正通过评审的旧产物中,提取 3 条可以检查的输出标准。
下载版不好用,我决定让 AI 复制一个“我”
上一篇用市场下载版 Skill 跑完真实需求后,我没有继续寻找另一份更强的模板。
它知道标准 PRD 应该包含什么,却不知道我的项目现状、团队评审习惯和不能改动的历史规则。
既然通用版不懂我,那能不能让 AI 直接学我?
我找出一份真正进入过评审的旧 PRD,让 AI 反向分析:
- 章节是怎么组织的;
- 业务规则写到了什么颗粒度;
- 表格、术语和表达习惯是什么;
- 评审真正关注哪些内容。
最后,我让 AI 根据这些特征生成一份专属 PRD Skill。
我的目标很直接:
以后只需要交代需求背景,AI 就能沿用现有工作产物的风格,替我完成大部分 PRD 书写。
AI 很快提炼出固定章节、表格格式、规则结构、术语规范和检查项。
这份 Skill 比市场下载版熟悉多了。它终于不再像一份标准答案,而开始像“我的工作方式”。
我当时真的以为,自己离“少写一点需求文档”只差最后一步。
第一个需求差不多能用,我误以为成功了
第一次测试,我选了一个与样本文档比较接近的 A 需求。
它们的业务类型、角色和系统都很接近。AI 生成的 PRD:
- 章节顺序基本符合我的习惯;
- 表格列更适合团队扫读;
- 术语没有到处变化;
- 流程、异常和验收标准都有覆盖;
- 整体语气也比市场版更像我。
我删掉多余说明,补了一些业务细节和真实限制。这份文档虽然不能直接评审,但已经到了“改一改可以继续”的程度。
这次结果给了我一个很强的错觉:
只要样本选得够好,AI 就能从旧 PRD 里学会我的写法。
现在回头看,A 需求并没有证明这份 Skill 足够强,只证明了:
当新需求和旧样本足够相似时,模板可以产生一份看起来不错的结果。
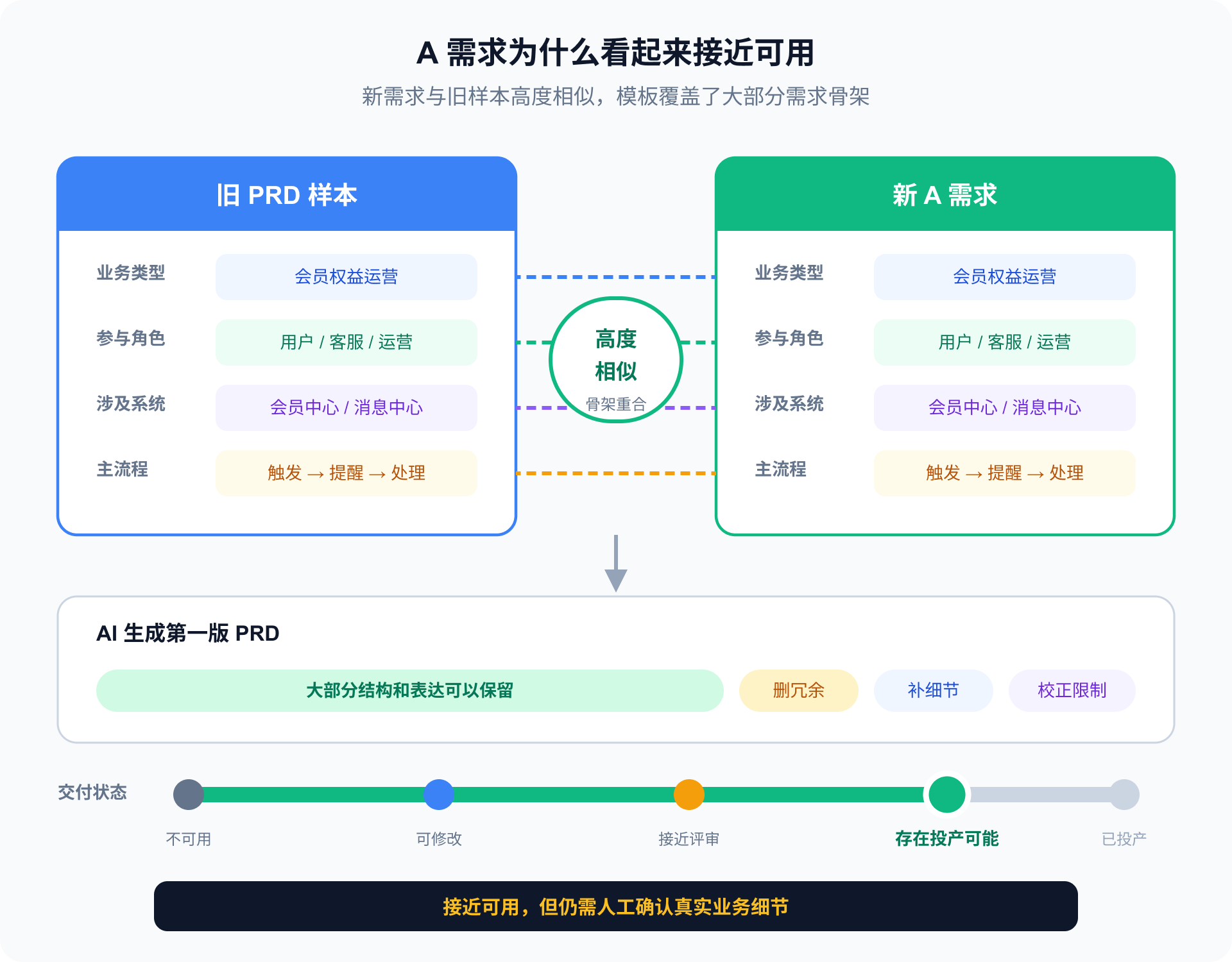
真正的测试,是换一个不一样的需求。
换了一个需求,整份文档开始失效
第二次,我换成了差异更大的 B 需求。
它的目标、角色、系统边界和评审重点都与样本不同,原来的章节比例和表达方式不再适用。
AI 仍然生成了一份格式完整、章节齐全的 PRD。真正阅读后,问题才一层层冒出来。
模板没有跟着需求变化
A 需求与样本接近,原来的结构基本可用。到了 B 需求,重点变成角色关系、状态流转和复杂交互,AI 却仍然平均分配篇幅:无关章节为了“完整”被硬写,关键规则反而被压缩。
需求有差异,但模板没有。
信息很多,评审重点却被淹没
输入里没有写清的地方,AI 会按照常见业务逻辑补全。单独看都不算错,堆在一起却让重点消失:
- 基础概念被反复解释;
- 大量“建议考虑”的内容混入正式方案;
- 真正需要决策的规则被淹没;
- 评审者必须从长篇文字中自己寻找重点。
我原本想减少书写成本,最后只是把成本转移给了评审者。
该画图的地方,全写成了说明书
B 需求里有几段复杂的条件分支和页面交互,一张逻辑图或低保真原型就能解释清楚,AI 却全部写成了文字。
“当用户满足条件 A 且未触发条件 B 时,系统展示状态 C;如已完成操作 D,则进入状态 E……”
信息不能说不全,却很难让人快速建立整体理解。文档逐渐变成了一本没人愿意从头啃到尾的说明书。
这让我第一次明确意识到:
PRD 的目标不是把所有信息写出来,而是让不同角色以最低成本形成同一个理解。
需要图的时候继续堆文字,不是完整,而是表达方式选错了。
常规逻辑替代了真实业务
更麻烦的是,AI 不理解需求真正依赖的定制规则。它会顺着行业常规补出一套“合理方案”,真实项目却常有例外:
- 历史流程不能立刻下线;
- 某类用户需要保留特殊入口;
- 一个看似属于订单的规则,实际由会员系统控制;
- 某些异常不能自动重试,必须转人工;
- 简单页面背后涉及多个系统状态。
- 这些信息没有完整写在样本里,也无法从文档风格中推导。于是结果进入一种危险状态:
它读起来像一个成熟方案,但并不贴合真实业务。

问题不在文笔,而在样本只保存了结果
一份完成的 PRD 可以让 AI 看到:
- 最后保留了哪些章节;
- 规则和表格使用什么结构;
- 术语怎样统一;
- 最终文档详细到什么程度。
它看不到的是形成结果之前的取舍:
- 为什么不同需求要增删章节;
- 哪些内容值得展开,哪些一句话就够;
- 什么时候应该画图;
- 某条规则来自行业惯例,还是项目特殊限制;
- 哪些备选方案曾被放弃,以及为什么。
工作产物保存了判断结果,却没有完整保存形成判断的过程。

旧产物无法迁移全部判断,但仍能回答一个更具体的问题:合格输出到底长什么样。
第一次跃迁:把“像我”拆成可执行标准
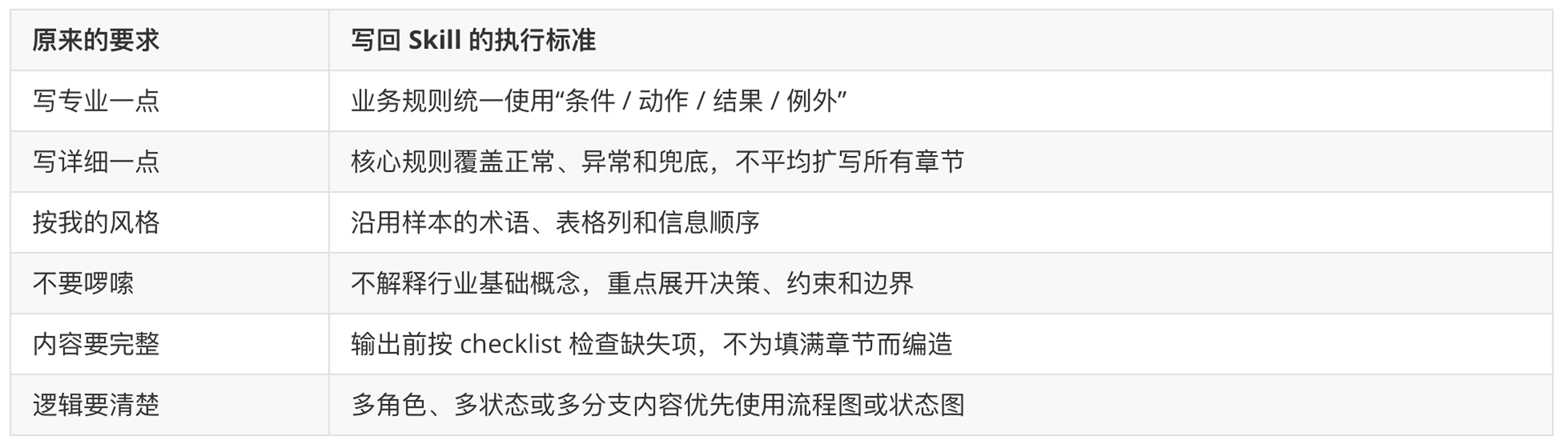
最初,我给 Skill 下达的指令是:

这些要求方向都对,却没有告诉 AI 什么叫“专业”、哪里需要“详细”、怎样才算“可以评审”。
AI 只能自行解释:

“像我”必须先被拆成 AI 能执行、我也能检查的标准。
从旧产物中提取什么
我重新回到通过评审的旧 PRD,只寻找可复用的稳定规律:
- 章节通常按照什么顺序出现;
- 表格、规则和术语采用什么标准;
- 哪些基础概念不必解释;
- 哪些复杂内容必须使用图或原型;
- 哪些地方评审一定会追问。
- 这一次,我不再问“这份文档写得好不好”,而是问:
哪些特征可以被写成规则,并在下一份产物中检查出来?
写回下一版
模糊要求被改成了具体标准:
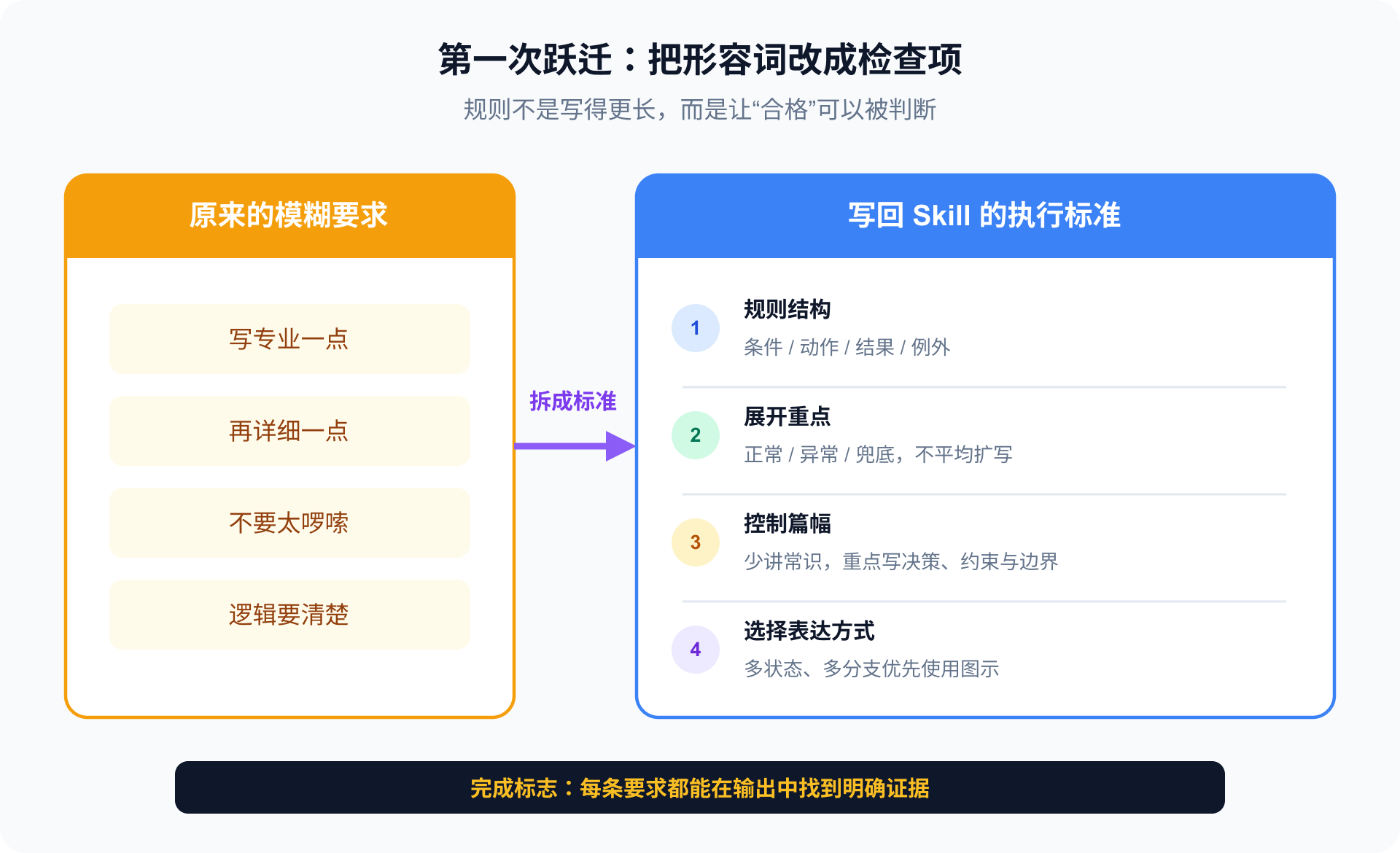
复测后,改善了什么
复测时,我不再凭“像不像我”的感觉判断,而是记录具体变化:
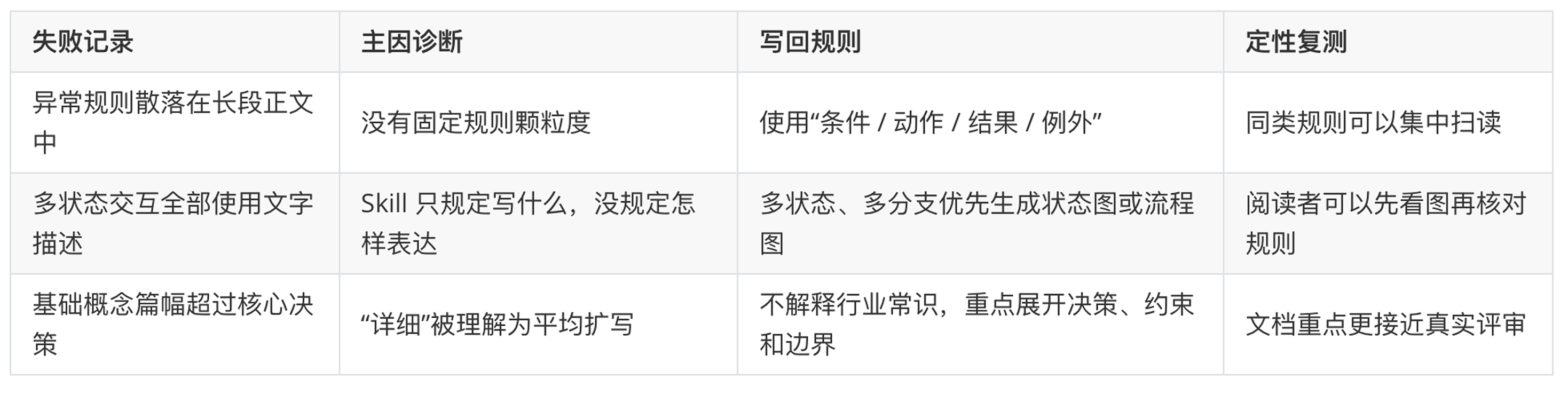
第一次跃迁结论: 不要教 AI“写得更好”,要告诉它“好具体长什么样,并且怎样检查”。
但输出标准仍然替代不了业务判断
修改后的 Skill 更好读,一部分局部内容也更容易复用,但定制业务判断仍然需要我完成。继续增加限制,只会让某个问题暂时缓解,换个需求又出现新问题。
AI 几分钟生成的完整文档,我可能需要花更长时间逐段核对:
- 哪些是输入中存在的事实;
- 哪些是 AI 按常识补出的内容;
- 哪些规则不符合系统;
- 哪些部分需要删除或重画。
生成很快,不等于交付很快。
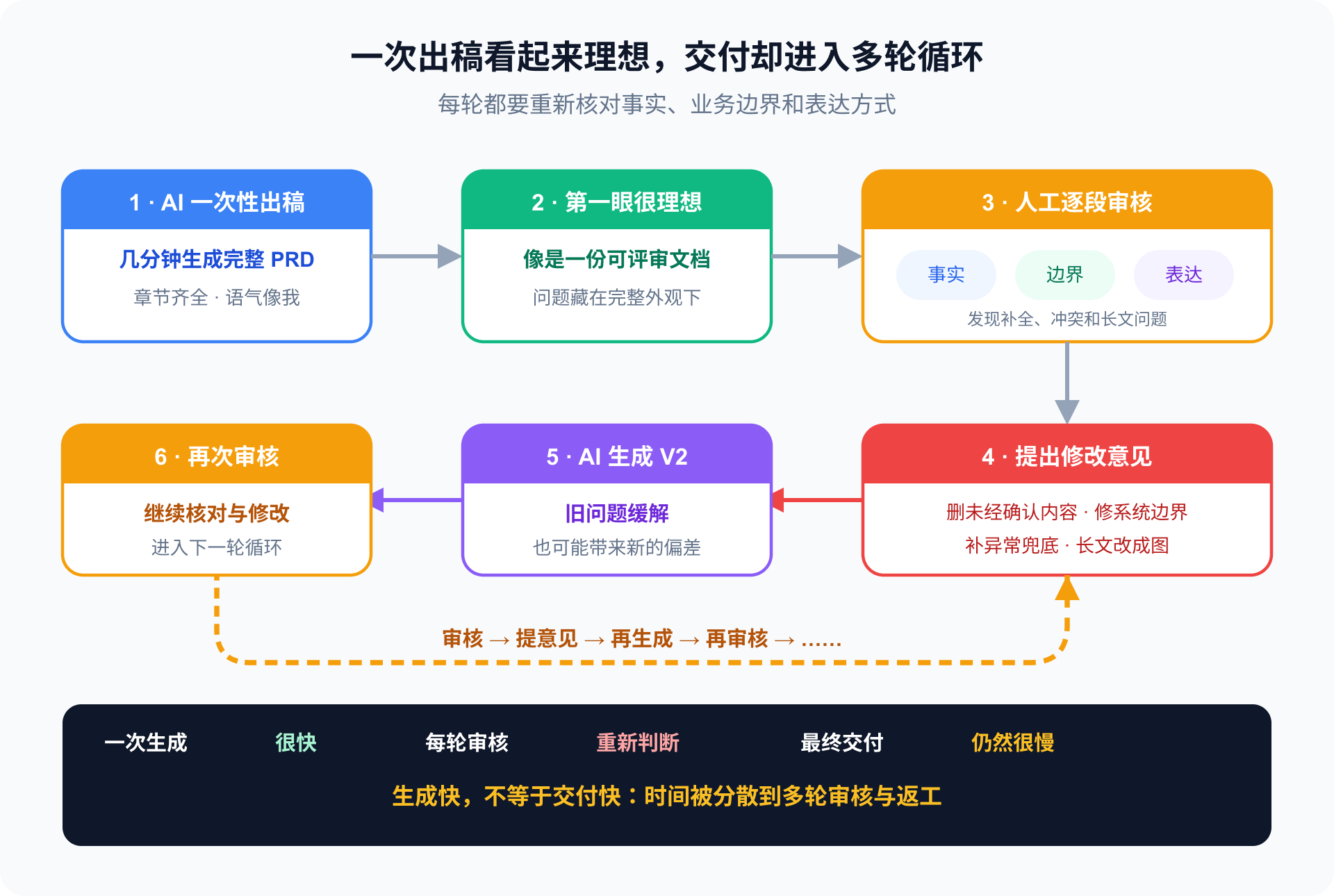
最后,完整 PRD 往往只留下背景描述、异常提醒、待确认问题、字段表初稿和少量规则表达。
于是,我暂时放下“一次生成整篇 PRD”,先把 AI 用在范围更小、结果更容易核对的任务上:整理一段规则、补充一组异常、生成一张状态图,或者把讨论记录变成待确认问题。
AI 暂时没有接走整份需求,却开始接走需求中的局部表达工作。
这也划出了本次调整的边界:输出标准解决了“怎么写”,没有解决“凭什么这样判断”。 如果每次仍要我先想清事实、规则和限制,AI 只是换了一种表达方式。
它能不能在动笔前,主动发现自己还缺少什么?
轮到你:从旧产物中提取 3 条输出标准
找一份真正通过评审或已经投入使用的旧产物,不评价“写得好不好”,只回答三个问题:
- 它固定有哪些组成部分?
- 哪一部分最影响别人理解和使用?
- 什么内容绝对不能出现在合格产物中?
把答案改写成 3 条可以检查的规则。例如:
- 输出必须包含:背景、目标、规则、待确认项
- 每条核心规则必须写清:条件、动作、结果、例外
- 三个以上状态或分支不得只用长段文字,必须补充图示
完成标志: 你已经得到 Skill 的“输出结构”和第一批验收标准。
如果旧产物里有不符合这 3 条标准的位置,也把它们留下来。后续修改 Skill 时,它们不是黑历史,而是第一组失败证据。
总结:像你写,只是第一步
旧 PRD 可以教会 AI 章节、表格、术语和表达习惯,但“像我写的”不是一条可执行规则。只有拆成结构、颗粒度、表达方式和验收标准,它才知道具体怎么做。
旧产物负责提供样本,人负责把样本背后的合格标准说清楚。
但输出越像我,未经确认的业务判断也越容易骗过我。
这一篇先完成第一次跃迁:
- 从下载模板,走到使用自己的真实产物;
- 从“按我的风格”,走到可执行的输出标准;
- 从凭感觉评价,走到用失败记录完成复测;
- 从期待整篇代写,退回更可靠的局部协作。
输出层变得更稳定后,下一个问题也更危险:文档越像我,未经确认的判断越容易被当成事实。
灵魂拷问:

例如:
写详细一点 → 核心规则必须覆盖正常、异常和人工兜底
逻辑清楚一点 → 三个以上状态或分支必须补充图示
下期预告:
系列二 · AI 协作 · 第 5 篇:AI 总是答得像对的,先让 Skill 学会暴露未知。
下一篇会继续拆解:
- 为什么输出越像你,错误越容易被忽略;
- 信息不足时,Skill 开工前应该检查什么;
- 哪些缺失信息必须阻止完整方案继续生成;
- 怎样区分已知事实、当前理解和待确认问题。
第四篇解决“怎样写才算合格”;第五篇开始解决“现在到底能不能写”。
作者:Zoe产品手记 公众号:Zoe产品手记
本文由 @Zoe产品手记 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议









正文提到AI会补行业常规逻辑但不符合真实业务,那怎么让Skill主动识别哪些规则是项目独有的?比如通过输入约束或反问机制来减少偏差?
支持先放弃整篇代写、专注局部任务的想法。降低期望反而减少了核对负担,AI在小范围任务上更容易产出可用内容,再逐步扩展更务实。
先是用旧PRD让AI模仿自己的写作风格,A需求跑通了就以为成功,结果换到B需求,模板没变、重点丢失、文字代替图、常规逻辑替代真实业务。问题核心是样本只保存了结果没保存取舍,所以得把‘像我’拆成可检查的输出标准,但标准也替代不了业务判断。最后退回到局部协作,反而更可靠。