
 起点课堂会员权益
起点课堂会员权益Loop Engineering:Agent时代的棘轮效应
2026年6月,“Loop Engineering”突然成了热词。Claude Code的负责人Boris Cherny说“我的工作是写Loop”,Addy Osmani为它写下纲领性的文章,整个圈子都在教你怎么搭一个能自己无限畅跑的 Loop,但真正有价值的另一面呢?

有段时间,我养成了一个习惯…..把活儿丢给agent,让它自己跑,我在旁边看着它一行行往下吐结果,感觉自己一个人顶一个团队。
那阵子我手上同时开着好几个窗口,每个窗口里都有一个Loop在跑:一个在改代码,一个在跑数据,一个在整理材料。我不用盯着任何一个,只要偶尔扫一眼,看到它们都在动,心里就踏实。
那种感觉很上头。任务排得满满的,每一个线程都在并行推进,屏幕像一个小型工厂,我是那个站在中控室里、双手插兜看着流水线的人。我确实觉得自己快了很多——以前一天干一件事,现在一上午能让五件事同时开工。
直到有一天,我停下来算了一笔账。
我把那一周真正“做完、能交付、我自己也认可”的东西捋了一遍,发现没有想象中多。再往回看时间都花在哪了,才有点恍惚:我大量的时间,其实不是在干活,是在重启那些跑偏的Loop、在给它们补上下文、在收拾它们自信满满交上来、但其实不能用的东西。
是的,这笔账显然不对。
我以为我在指挥一个团队,实际上我更像一个被五个实习生同时追着问问题的人。每个实习生都很积极,都在动,但我那一周的产出,未必比我自己安安静静干两件事更多。
这个事儿后来一直卡在我心里。直到Loop这个概念彻底火起来,我看到谷歌工程师Addy Osmani那篇《Loop Engineering》,又顺着翻了一圈相关的讨论,才慢慢回过味来:我那一周做的,恰恰就是这段时间AI圈都在推崇的事——该好好设计Loop了。只不过,我写得并不好。
这并非是一阵风
这一年多的 vibe coding 经验告诉我,Loop Engineering是实打实的趋势,不是又一个被炒起来的词。
如果你最近没怎么关注这个事儿,我用一句话给你交代清楚它在说什么。过去我们用AI,人其实是那个Loop的控制器:你给个任务,AI做,你看结果,你判断对不对,你再给下一个指令。这个“给➡️看➡️再给”的圈,是靠你手动一圈圈推的。Loop Engineering想做的,是把这个外层的圈自动化——你只定义一次目标和终止条件,然后让一套系统替你推着agent反复迭代,直到条件满足为止。
说这话最有分量的人是Boris Cherny,Anthropic那边Claude Code的负责人。他在2026年6月一次公开场合说了一句后来被反复转发的话,大意是:我已经不prompt Claude了,我让Loop去prompt它、去决定下一步做什么,我的工作是写Loop。
这句话之所以扎人,是因为它不是某个卖课的人说的,是真正把Claude Code做出来的人说的。而且有实打实的东西在后面撑着:Anthropic工程团队现在100%的pull request都要过Claude Code。工具层也已经落地了,Claude Code和OpenAI的Codex都有“/goal”这样的命令。这些都不是PPT上的概念,是已经能用的东西。
更有说服力的是OpenAI的一个项目例子。Frontier团队五个月写了大约一百万行代码,几乎没有人工手写。但这里有个常被忽略的细节:这个项目最初的一个半月,比纯人工还慢十倍。优势是在框架搭好之后才出现的——什么玩意,这跟主题无关吧?别急,先把这个细节记着,后面我会给您 call back。
所以很明显 Loop engineering 不单有用,而且代表了一个真实的方向:人正在从 Loop的操作者,向Loop的设计者推进。
还记得我那篇文章Harness里的那张对比表么?现在又多了一位新成员,还是个重量级的成员。 把这几个最近满天飞的 “XX Engineering” 摆在一起,它们的层级关系大概是这样:
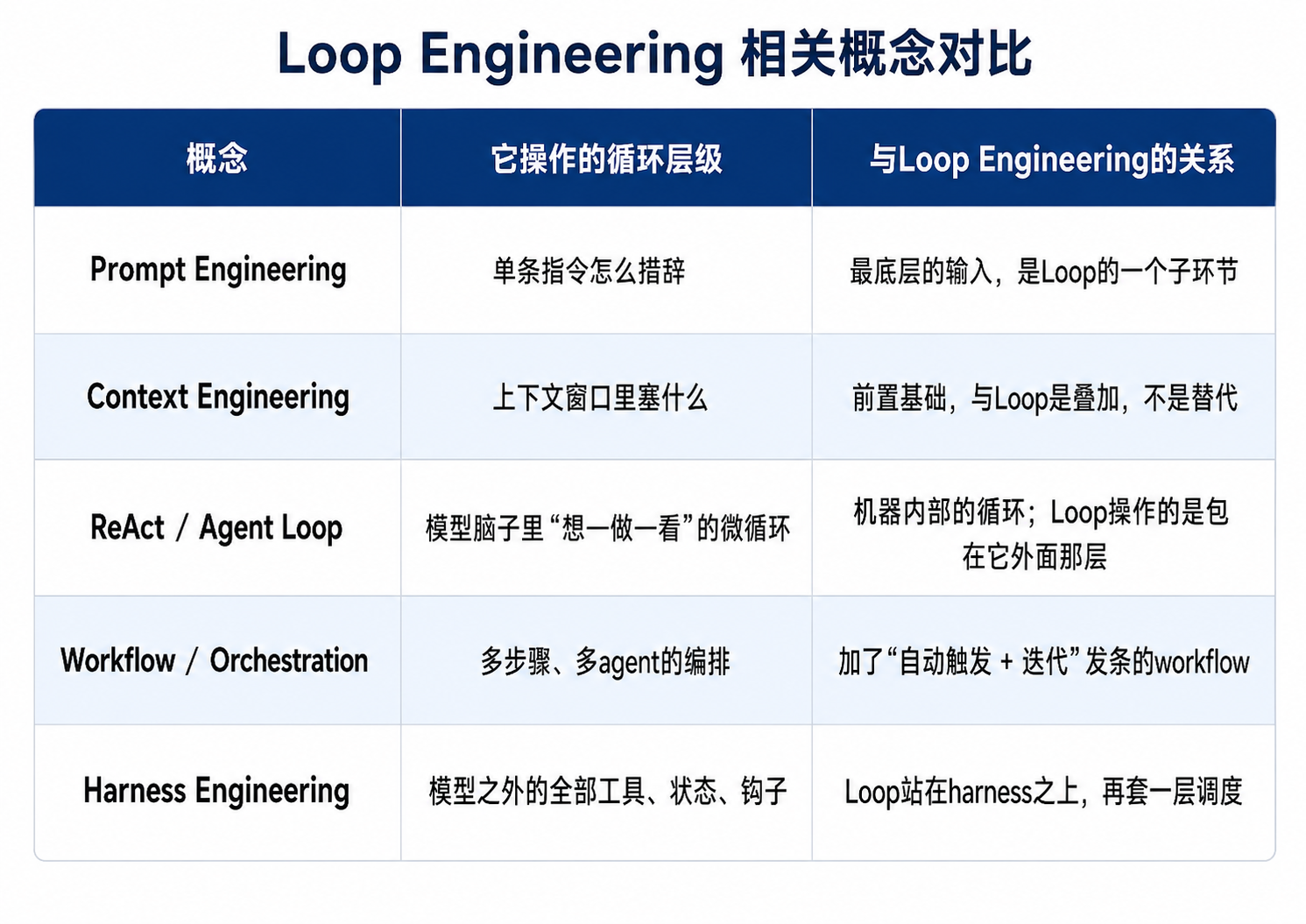
看明白这张表,你大概就懂了:Loop Engineering不是要取代谁,它是把人的手从“一圈圈推循环”这个动作里抽出来,挪到“设计这个Loop”上。
这是纯粹的进步!
你以为的“快”,可能根本不存在
在过程中,我还发现了这么一组数据,它像是来了一记巨人之握锤在我那笔“算不对的账”上。
有一家叫METR的机构在2025年做了一次随机对照实验。这种严格的对照实验在这个领域很少见,所以它格外值得认真看。他们找了16位资深的开源开发者,246个真实任务,一半用最前沿的AI工具,一半不用,然后比对。
实验之前,这些开发者自己预测:AI大概能让我快24%。
实验之后,他们的主观感受是:嗯,确实快了大概20%。
但客观测下来的结果是——他们慢了19%。
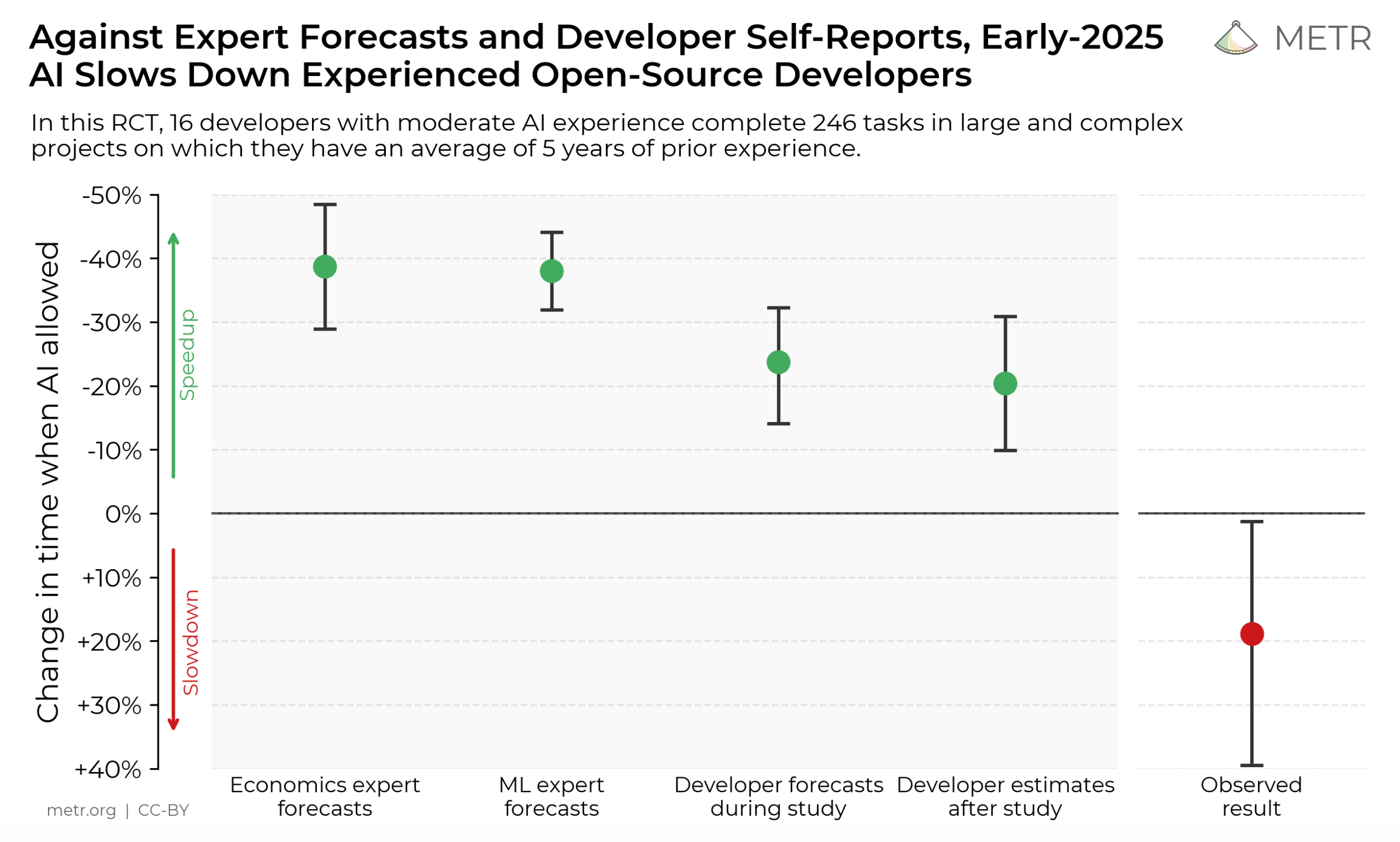
你把这三个数字摆在一起看,这可不是慢了一点,是慢了将近两成。而且最要命的不是慢,是这些测试者是资深开发者,是这个领域里最该有判断力的一群人,他们身处其中,却完全没感觉到自己变慢了。他们的体感是“我快了20%”,方向都反了。
这就是我那笔账对不上的原因。加速从来不是一个你能”感觉”到的事实,它是一种感觉。而感觉,是会骗人的。DORA在2025年那份覆盖了近五千名从业者的报告,从另一个角度印证了这件事。它的结论是:AI是一个放大器。它放大好的流程,也放大脆弱的流程。你的测试、你的反馈机制、你的架构如果本来就扎实,AI让你更快;如果本来就松垮,AI让你更快地垮。决定收益的,从来不是工具本身。
把METR和DORA放一起,一个让人不太舒服的结论浮出来了:当你觉得“我开了五个Loop、我效率快极了”的时候,你很可能正处在那个最危险的位置:一边在减速,一边却坚信自己在加速。
Loop:一个不好停下来的棘轮
当我第一次看完Boris那段“我的工作是写Loop”的发言,刹那间想起的,是经济学和心理学里的“棘轮效应”。
棘轮是机械里那种只能朝一个方向转的齿轮,上面有个卡爪卡着,往前可以,往回不行,一旦开始,就只能朝一个方向走,很难停下来。经济学和心理学借这个词,描述一种“只进不退”的状态:投入上去了就下不来,标准提上去了就降不回来。而它最麻烦的地方,恰恰就是那个”很难停”——它没有内置的刹车,停,从来不是它的默认动作。

这也正是为什么后面我会反复说:真正的Loop Engineering,难的不是让它跑起来,是给它设计一个“停”。Loop就是一个标准的棘轮,而且是我们每个人在 Agent 里亲手装上去的。
你想想一个Loop跑偏之后,人会怎么反应。它转了三轮没出对的结果,你的第一反应几乎从来不是“算了,这条路不对,我停了它自己来”。你的反应是:是不是我目标没写清楚?是不是上下文给少了?是不是该再加个重试?是不是换个模型再跑一轮?
每一个念头都通向“再来一轮”,没有一个通向“停”。
这不是因为你笨,恰恰是因为这些念头每一个都合理。它们听上去都像是在解决问题。可它们合在一起,构成了一个只能往前的棘轮——你不断往里投入更多的token、更多的时间、更多的耐心,而这些投入只会让你更不愿意停。
这里藏着一个特别拧巴的心理账。当一个Loop已经吃掉你两小时和一笔不小的token,“停下来承认方向错了,开个新对话”的成本,在你心里是被严重高估的——那意味着这两小时白花了,那意味着我一开始的判断就是错的。相比之下,”再调一轮试试”的成本,则被严重低估了——不就再花十分钟嘛。
于是你一次次选了”再来一轮”。每一次都觉得自己离答案更近了一点,每一次都不舍得停。停不下来的不是Loop——是你越投入越不敢承认投入可能是错的那种心理。Loop只是忠实地、不知疲倦地,把你这种不甘心放大成了一个可以无限转下去的机器。
人至少还会累,会烦,会在某个瞬间停下来怀疑自己到底在干什么。Loop不会。它会一直转,转到你的配额烧光,转到你某一刻终于回过神。它没有那个”算了吧”的瞬间,因为它根本没有”算了”这个概念。它的默认答案,永远是再来一轮。
我们以为自己在写Loop。其实很多时候,是Loop在替我们决定什么时候停——而它给出的答案,永远是:不停。
那问题到底卡在哪:Loop再快,也快不过你看的速度
前面只是解释了为什么停不下来。但还有一个更结构性的问题:就算你不停,这套东西的天花板到底在哪?
我后来想明白了,天花板不在Loop这边,在我这边。
打个比方你就懂了。计算机领域有一条很老的定律叫Amdahl定律,说的是:一个系统的提速,受限于它那个没法并行、没法加速的环节。你把能加速的部分提到一百倍,但只要有一小段卡在那动不了,整个系统的上限就被那一小段死死摁住。Loop这件事,有一个永远没法被加速的环节——我。Loop能生成,能重试,能并行,能一夜不睡地吐东西出来。这些都能无限快。但有一件事的速度是固定的,甚至会越来越慢,那就是我看它、我判断它对不对、我决定要不要用的速度。生成可以是无限带宽,验收只有一个我,一条很窄的带宽。
这就回到我开头那个“算不对的账”了。我那一周真正的瓶颈,从来不是Loop跑得不够快,恰恰相反,是它们跑得太快,快到我根本看不过来。
我那阵子的真实状态,与其说是一个指挥官,不如说是一个人肉验收员。五个Loop在我面前排着队交东西,一个比一个交得快,而我只有一双眼睛。它们交得越快,我面前堆积的东西越多,我越堵。到最后,决定我那一周能产出多少的,根本不是那五个Loop的速度,是我一个人审一份东西要多久。
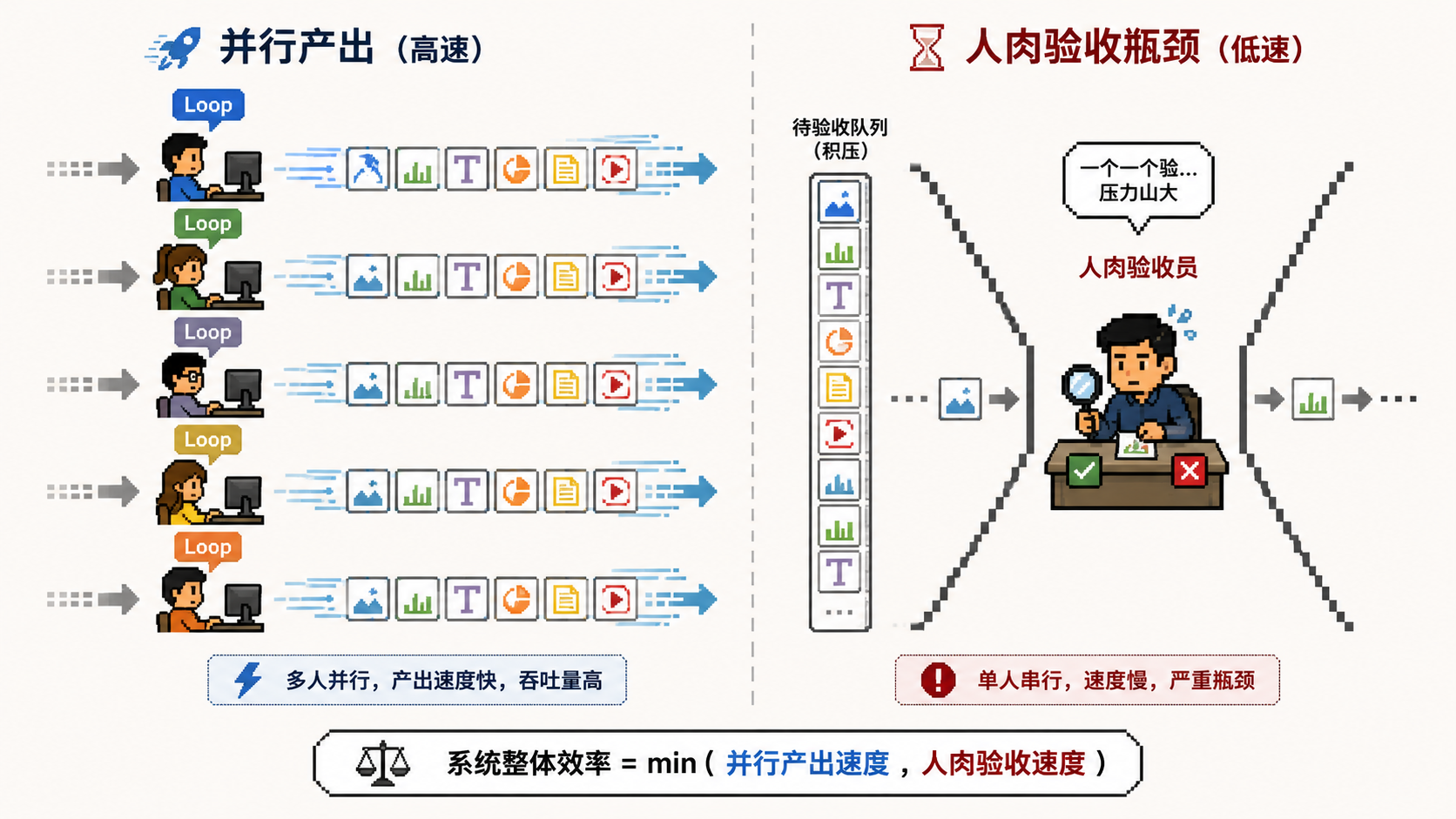
而且这里还有一个更隐蔽、更让我后背发凉的滑坡。当东西堆到你看不过来的时候,人会本能地做一件事——少看。
一开始你还认真读每一行,后来你只扫关键部分,再后来你看它”长得对不对”,最后你干脆就信了。这个过程有人叫它“理解债务”(comprehension debt):代码(或者任何产出)堆积的速度,超过了你真正理解它的速度,于是你欠下一屁股自己都没搞懂的东西。再往下一步,是”认知投降”——你不是看不过来,是你放弃看了,照单全收。
到这一步,那个最初的反转就闭环了:你以为Loop替你干了活,其实它只是把”干活”换成了“验收”,又因为你验收不过来,逼着你放弃验收。你不是更高效了,你是把“思考”这件最该自己干的事,悄悄交了出去。
Loop浪潮里的“百密一疏”
到这一步,或许很多人才意识到一件有点讽刺的事:这一波Loop Engineering的讨论,铺天盖地都在教你怎么“Loop”——怎么写一个好的Loop,怎么配重试,怎么搭隔离的工作区,怎么让agent自动触发、跨会话记忆。这些都是关于怎么让Loop跑起来、跑得更久、跑得更自动。
但真正最难的那个问题,几乎没人正面讲:Loop什么时候该停?谁说了算?
这可不是我乱抛出来的,是给这个概念命名、搭框架的人自己说的。Addy Osmani,被普遍认为是把Loop Engineering正式立起来的那个人,他自己就把“终止条件”——也就是“什么时候算真正做完”——列为整件事里最核心的工程难题。而且他强调得很清楚:这个”做完了没有”的判断,绝对不能由那个正在干活的agent自己说了算,必须由一个独立的验证机制,基于能被客观核实的标准来判定。

你品品这件事的微妙。连立这个旗的人都说,最难、最核心的是”怎么停、谁来判定停”。可市面上九成的热闹,都在教你”怎么跑得更欢”。
这就像所有人都在研究怎么把车造得更快、马力更猛、油门更灵敏,却没人认真聊刹车,而数据已经告诉我们了:刹车比油门重要得多。
为什么最难的部分被绕过了?因为“跑”是看得见的、可炫耀的、有成就感的。你搭好一个能自动跑一晚上的Loop,一个截图朋友圈晒出去,很酷。而研究”停”是反直觉的,是扫兴的,是要你亲手给自己那个一人顶一个团队的幻觉踩一脚刹车的。
但Loop Engineering真正的工程,恰恰在刹车这一侧。
真正的工程:给棘轮装一个卡扣
棘轮的问题,是它只有“往前转”的卡爪,没有”往回扳”的机制。所以真正的Loop Engineering,不是去写一个转得更快更自动的Loop——那只是把棘轮装得更紧。真正的工程,是给这个棘轮装上一个卡扣:一个能让它停下来、能让你往回扳、能让每一轮转动都留下点东西的机制。
真正的Loop Engineering,难的不是让Loop跑起来,是让它知道什么时候不该再跑——也就是,什么才算真正的结束。
具体到机制上,这个卡扣有两个零件。
一个是独立的验证。干活的agent不能自己给自己判及格,这是Osmani反复强调的。你必须有一个独立于执行者的验证环节,去回答“这一轮到底做成了没有”。理想情况下,这个标准要能被机械地、客观地判定——比如”所有测试通过””这个数对得上那个数”——而不是Loop自己拍胸脯说”我觉得搞定了”。
另一个是可机械判定的终止条件。在你启动Loop之前,“什么叫做完”就得被你想清楚、写下来。不是“做得差不多就停”,而是一个明确的、不依赖Loop自觉的硬性条件。这个条件不是为了限制Loop,恰恰是为了把“停”这个决定,从Loop手里——也就是从你那个不甘心的心理手里——夺回来,提前交给一个冷静的规则。
我把“只会猛跑的Loop”和“装了卡扣的Loop”放在一起对比,差别会很清楚:
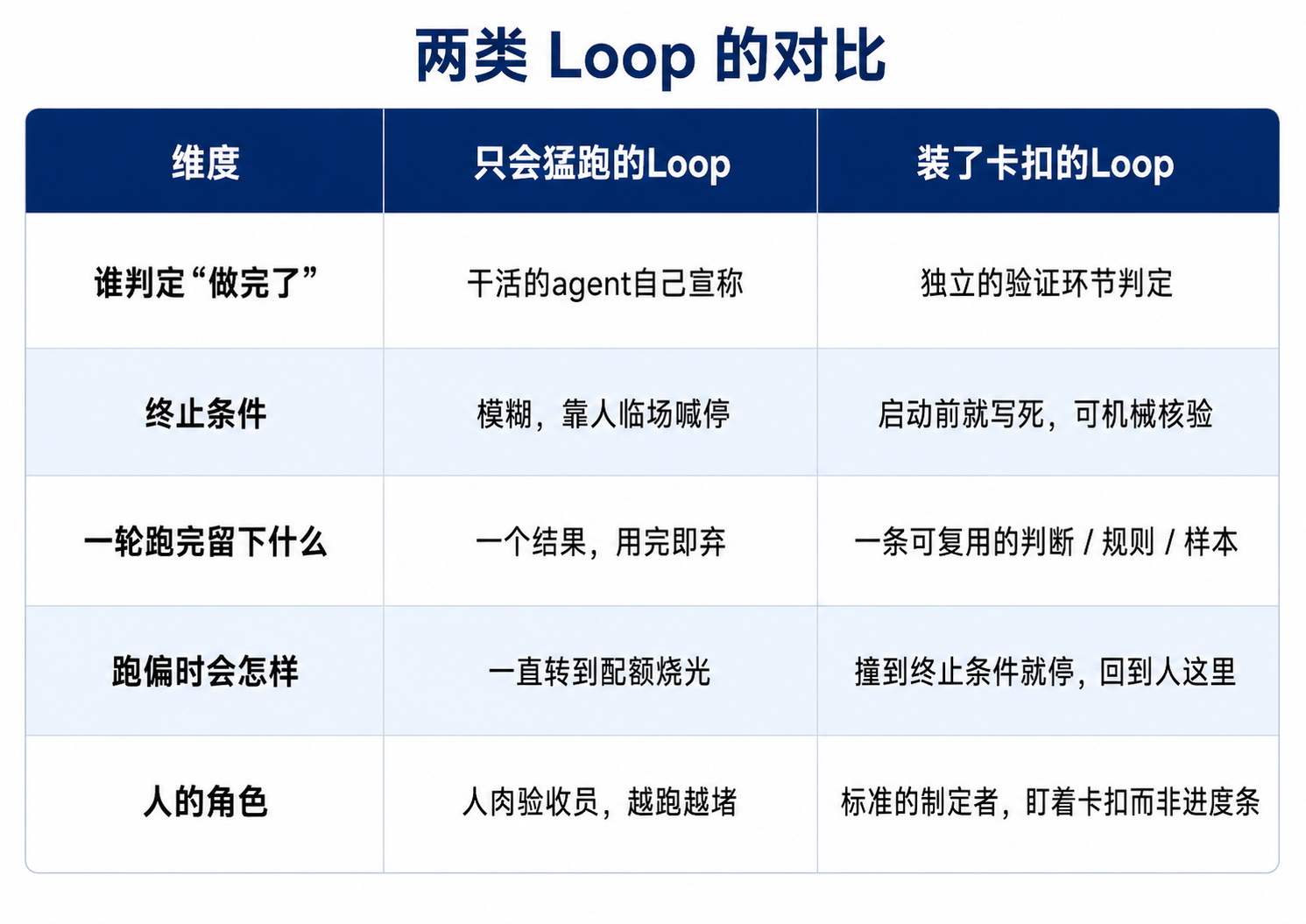
请注意第三点——“一轮跑完留下什么”。这是我觉得最关键、却最容易被忽略的一点。一个只会转的Loop,跑完一轮就是一个一次性的产出,下一轮还得从头来。而一个装了卡扣的Loop,因为有验证、有明确标准,每一轮跑完都能沉淀下一点东西:这次的判断对不对、错在哪、下次该怎么改。它不是在原地空转,它在螺旋往上跑,长期往复后——这是什么?一个 Loop engineering 里的数据飞轮!
回到OpenAI Frontier那个例子——那个项目最初一个半月比人工慢十倍,但后面快了起来。慢的那一个半月,现在大家后知后觉,知道他们在干嘛了吧?在搭框架、搭验证、搭那个”什么叫做对了”的标准。是的,装卡扣也在搭建进程里,卡扣装好了,Loop才真正开始产生价值。这恰恰反过来证明:价值不在Loop本身,在Loop之外那套让它能停、能验、能沉淀的东西。
那到底该怎么做
讲了这么多,落到具体价值上,其实就三件事,而且没有一件是关于”怎么让Loop更强”的。
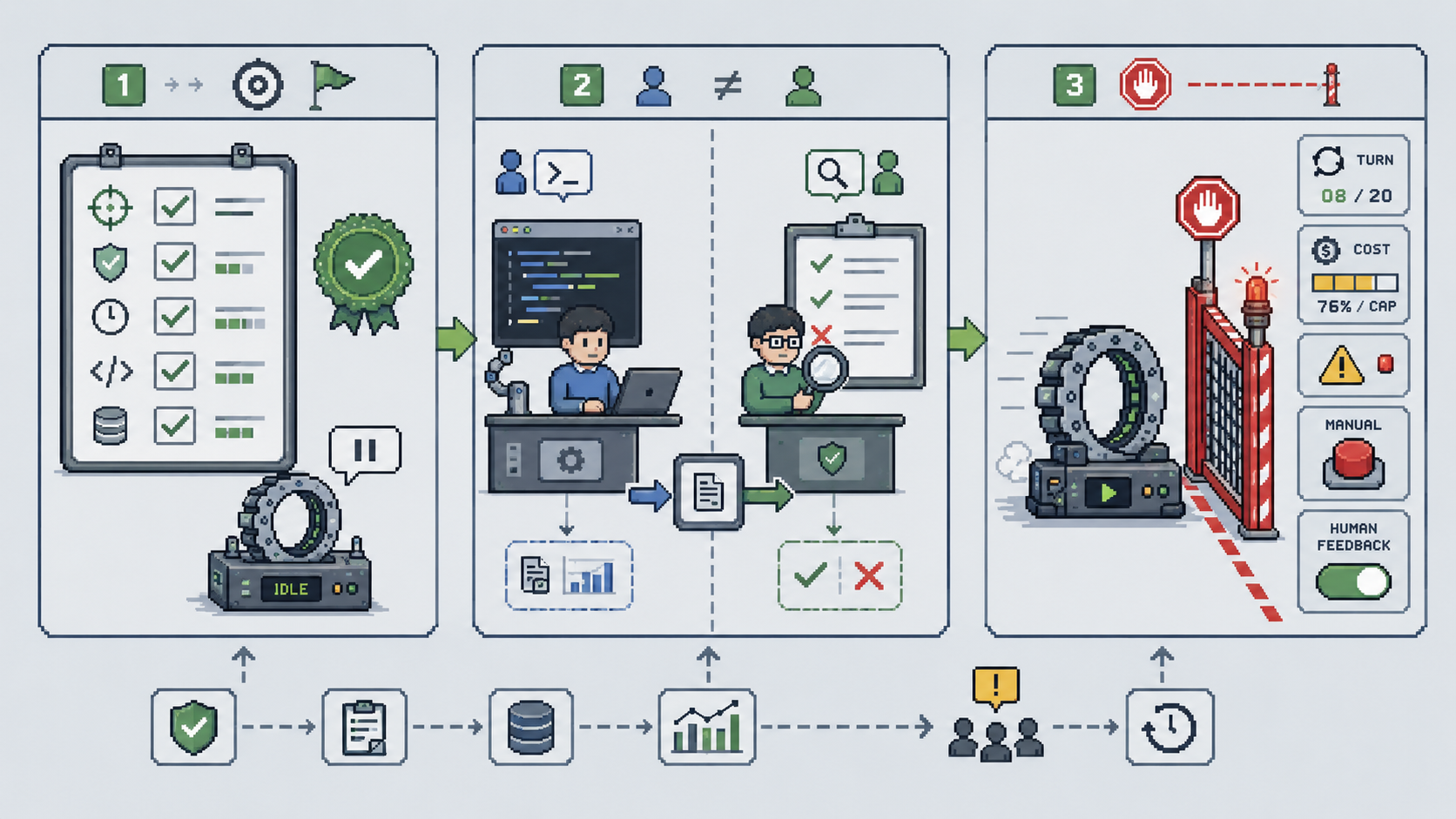
1. 先把验收标准定了。
别急着启动那个很酷的Loop,先停下来问自己一句:这件事做到什么程度,我才算它做完了?这个标准越具体、越能被客观核验越好。如果你连”做完长什么样”都说不清,那Loop转得再欢,也只是在一个你自己都没定义的目标周围打转。
2. 让验证的人和干活的人分开。
哪怕只有你一个人,也要刻意把“执行”和“验收”拆成两个动作、两个时刻。别让那个刚跑完Loop、还沉浸在“我搞定了”兴奋里的你,去验收它自己的产出。换一个冷静的视角,或者干脆换一个独立的agent专门挑刺——自己判自己及格,是棘轮最舒服的姿势。
3. 给Loop设一个硬的停止线,而不是指望它自觉。
提前设好:跑多少轮没达标就必须停,烧到多少成本就必须停,撞到哪些信号就必须回到human feedback这个环节,通过追问与人工协作的方式解决。把“停”写成一条铁律,而不是一个你临场凭心情做的决定。因为我们已经知道了,到了临场那一刻,你那个不甘心的心理,是不会让你停的。
这三件事,全都是关于”怎么让Loop能停、能被验、能往回扳”。因为强,从来不是这件事的瓶颈。
最后
写到这,我想回收开头那笔算不对的账。
我现在大概明白那段的问题出在哪了。有时候产生“一个人顶一个团队”的幻觉,是因为我把“Loop在转”误当成了“我在产出”,把”我很忙”误当成了”我很高效”。我装了五个只会往前转的棘轮,然后被它们推着,一路往前,舍不得停。我没有给任何一个Loop装上卡扣。
后来,我的claude.md里新增了这么一句约束:启动任何Loop之前,先与我对齐终止条件。
现在我会做的事,反而朴素了很多。启动一个Loop之前,我会先想清楚它的终止条件是什么;它跑的时候,我盯的不再是进度条,是我的约束条件到底有没有生效?生效的效果如何?它停下来的时候,我也会先问自己——这一轮,除了结果外,这一轮沉淀了怎样的数据经验?
这听上去好像是在给AI设限,是在让它没那么自动、没那么自由。但我越来越觉得,恰恰相反。一个只会跑,没有很好学会停的Loop,其实是最不自由的——它被困在自己的惯性里。真正高级的自主,不是少问人、自己一路跑到黑,而是知道什么时候该停下来,把问题交还给人。
本文由 @梅万枢 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自AI生成,由作者提供






- 目前还没评论,等你发挥!


