
 起点课堂会员权益
起点课堂会员权益AI动漫视频工具1.0—探索全新内容创作设计理念与实现策略
本次为大家分享创作工具「度加」赋能AI动漫视频应用中,在定制化模型供给、多视角镜头控制、临场感音频合成等方面沉淀的创新经验,进而有效提升AI动漫视频内容的品质感和氛围带入感。

一、项目背景
AI动漫视频是AIGC的热门赛道之一,目前市面上许多动漫领域核心玩家均布局或已启动AIGC动漫内容生产。我们希望为有意向进行AIGC领域创作的PUGC创作者提供便捷的渠道及工具,通过孵化一批独家的AIGC动漫原创作者,入局动漫创作行业核心圈,为平台供给大量差异化原创内容。

1. 行业洞察
通过对AI动漫视频行业进行深入调研洞察,我们发现其具有以下特点:
- 随着小说推文行业规模扩大,代理机构及推文KOC达人账号迅速增长,AI动漫视频订单规模不断扩张。
- 在小说推文用户群中,18-23岁的年轻人和女性用户居多,着眼于抖音小说推文指数,用户逐渐增加,且有逐渐“破圈”的趋势。
- 目前小说推文KOC达人的用户画像,集中在女性学生和宝妈群体,表明女性达人对于小说内容的理解更为透彻。
2. 用户痛点

同时我们发现,目前用户使用AI动漫视频产品时的痛点主要集中在以下几个方面:
1)文本内容识别不准确
画面识别和文字匹配度不高,导致适配内容画面表现出现偏差,影响视频效果。

2)图像不受控制
不能保证同一人物在不同分镜下的妆造一致,同个人物的服饰、发型等会发生变化,影响画面内容的连贯性。

3)风格匹配度不高
AI动漫视频会存在较强的“机器感”,人物和场景风格未必和漫画风格匹配。

4)动态效果生硬
AI动漫视频终端交付内容动态不连贯,转场效果很像PPT。

3. 设计理念
基于此,我们对产品落地进行细致规划,将模型驱动AI动漫视频能力落地「度加」创作工具,跑通从文章识别到视频合成的完整流程,确保基础功能落地。从文本转化、画面控制、动态能力等多方面调优,对标高质量视频要求,持续打磨工作流,支撑生态向高质量内容转型。

1)优质视频内容促分发、提时长
我们持续打磨设计工作流,力求使自动生产质量达到动漫视频基线。
2)高效工具建立内容创作优势
设计创新提升工具控制范围和能力,保证辅助生产质量追齐专业动漫视频水平。
二、搭建视频生成流程
通过不断打磨优化,我们搭建了一套完整的视频生成流程:设置基础信息及视频参数→上传文本→角色/场景提炼(可重新生成至符合预期)→生成旁白及分镜(可进行编辑或重新生成至符合预期)→生成视频。
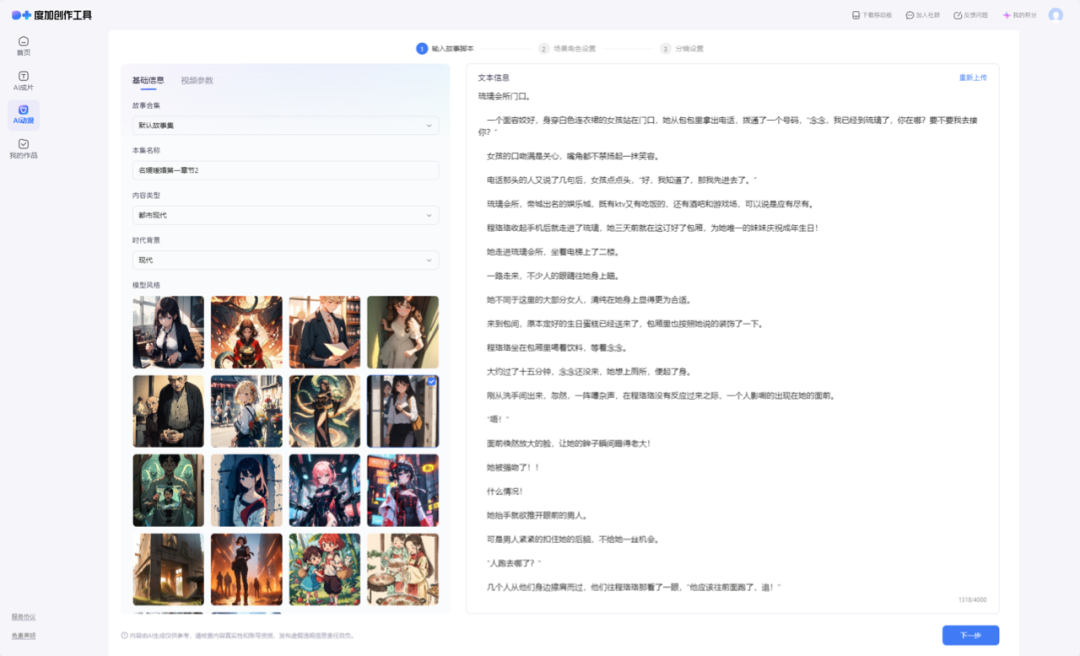
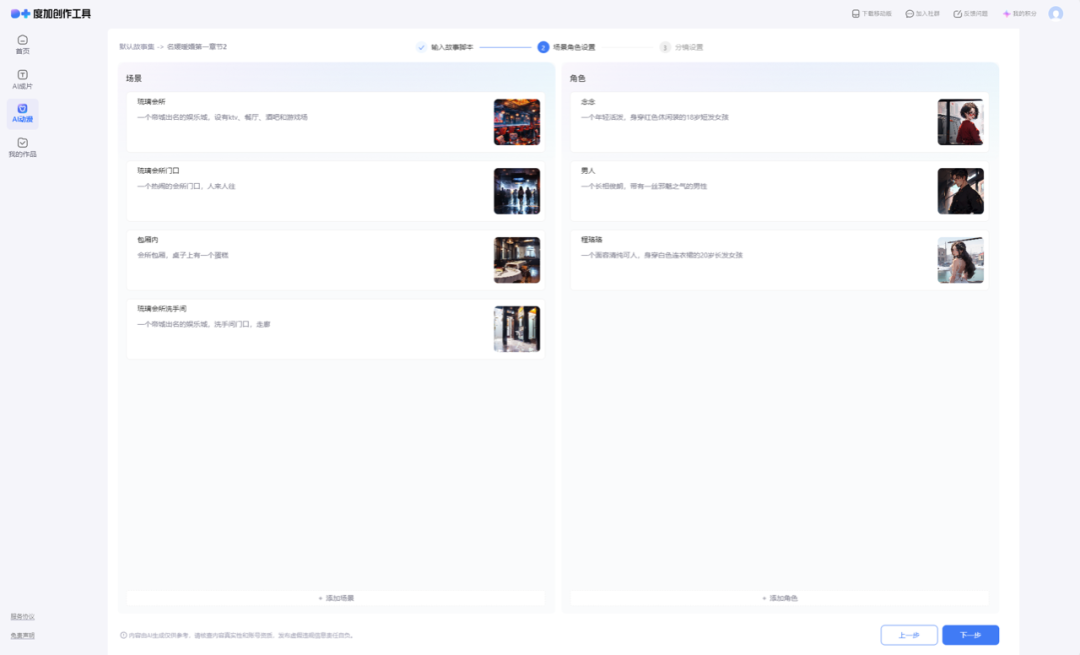
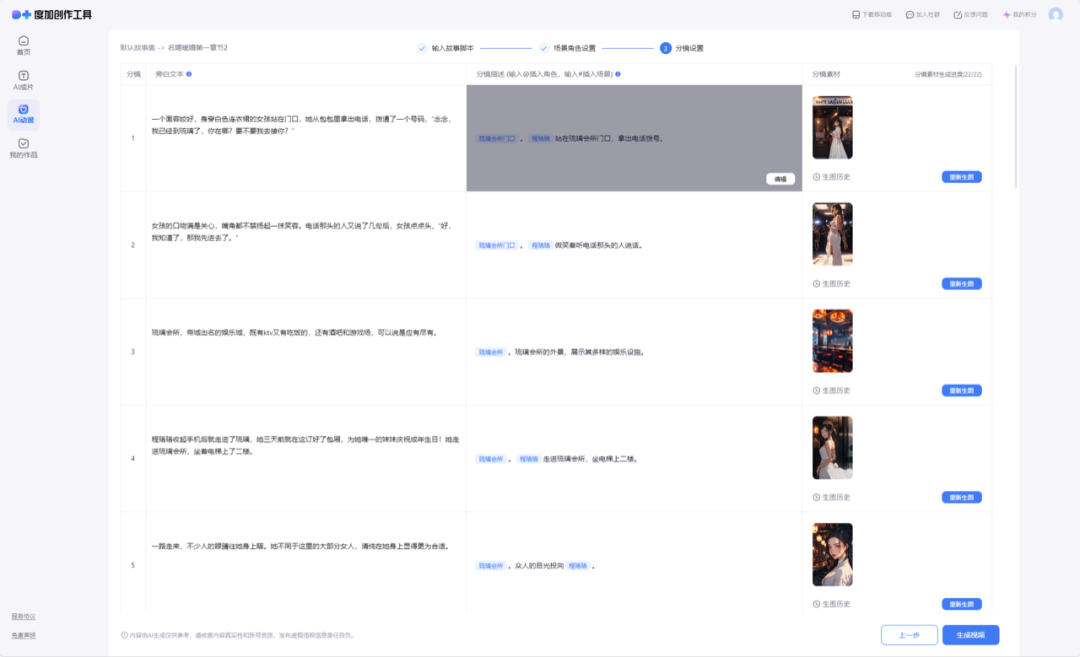
三、聚类定制化风格模型
1. 七大类别模型
选型为了使生成效果更加适配漫画内容,解决风格匹配度不高的问题,我们对市面上的热门漫画题材进行了分析,根据其内容进行了分类梳理。共梳理出七大类别:都市现代、武侠仙侠、奇幻魔幻、恐怖悬疑、科幻赛博、末日废土、儿童绘本。通过对类别内容的判断,选择能表现其内容特色的风格模型。
为增加模型的可选择性,每个类别下选择2套模型进行适配,同时增加通用模型,保证内容品质及风格效果的全方面覆盖。

2. 模型选型标准
1)内容准确
目前使用的底模均为基于Stable Diffusion 1.5底模训练出来的模型。通用模型和垂直模型的区别在于,通用模型需要具备比较广泛的通用的内容识别能力,尽可能覆盖热门题材。例如DarkSushiMix这个模型,在热门的都市和仙侠等题材中,均可以识别小说分镜描述的内容,生成符合预期的画面,可以作为通用模型使用。
 2)风格契合
2)风格契合
垂直模型更具有针对性,部分小说内容具有强烈的特色风格,在模型选择中,除了对于文本内容的识别,需要具备符合小说特色的风格效果。这时除了筛选适合的底模以外,还可以使用底模+LoRA模型的方式,一方面保证画面识别,另一方面满足风格需要。
在进行了大量评测组合后,我们选择出适合7大类别的模型搭配。例如在儿童绘本类别下,适配了童趣和国风两种风格。通用的底模虽然可以将画面内容呈现出来,但是风格上与儿童绘本差异较大,会导致观感上与小说本身产生差异,模型适配准确后,就可以生成符合预期的画面效果了。

3)画面美观
画面美观包含内容准确、风格契合、人物画面无崩坏等多个方面。内容准确与风格契合在上面进行了总结,关于人物画面的实现效果上,AI生图在尺寸较小的情况下会出现部分Bug,主要受到影响的是面部清晰度。
因此,我们选择使用Adetailer插件进行面部修复,保证人物的清晰美观。

四、多视角镜头控制画面
在工具初建阶段,重点采用Prompt控制镜头视角的多样性。我们测试了大量镜头视角描述词在不同模型及内容描述下的效果,总结出5个效果识别显著的词汇:Close-up(特写)、From below(仰视)、Top view(俯视)、Front view(正视角)、From side(侧视角)。
镜头视角描述词根据策略随机适配,避免连续出现相近视角的画面,确保画面构图的丰富度。

五、多尺寸及转场增强画面丰富度
1. 规范制定
我们制定了比例和尺寸两方面的规范。
- 比例设定:设定「16:9、9:16、4:3、3:4」4套生图比例,选择4个识别度高的字体匹配4套比例,满足用户对视频横板和竖版的不同要求。
- 生图及视频尺寸:为保证较快的生图速度,生图过程中,先使用较小的生图尺寸,再通过超分扩大图片保证画质清晰度,同时对画面在视频中的范围及尺寸进行规范。以16:9为例,在该比例下,生图尺寸若与视频尺寸一致,画面过长,AI生图会出现相对不可控的情况。经过多轮测试评估发现,将画面尺寸控制在4:3的范围内效果最佳,16:9的高清视频尺寸为1920×1080,所以画面的部分生图使用了684×512(4:3)的尺寸,再通过超分扩展为1440×1080(4:3)。

2. 运镜转场
为避免视频有类似PPT切换图片的感受,增加运镜和转场,运镜主要为上移、下移、放大,转场设计了下滑、右滑、位移、旋转等8个效果。

六、多音频选择提升临场感
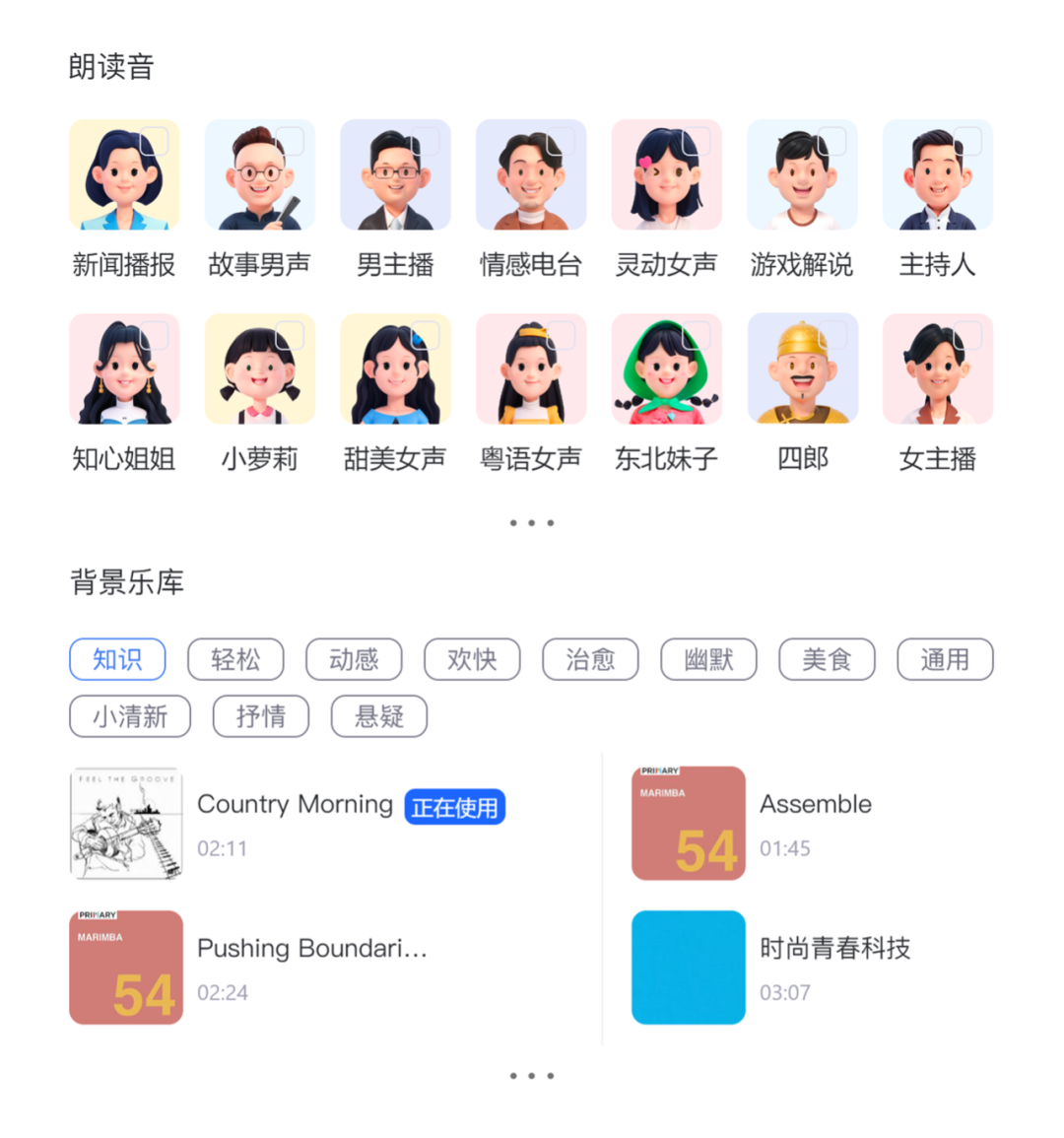
1. 基础能力
我们使用度加TTS旁白与端内音乐进行合成,音色及背景音乐提供多个种类选择,音量、语速均可调整,保证音频与画面的最佳契合度。
2. AI音视频赋能内容生产
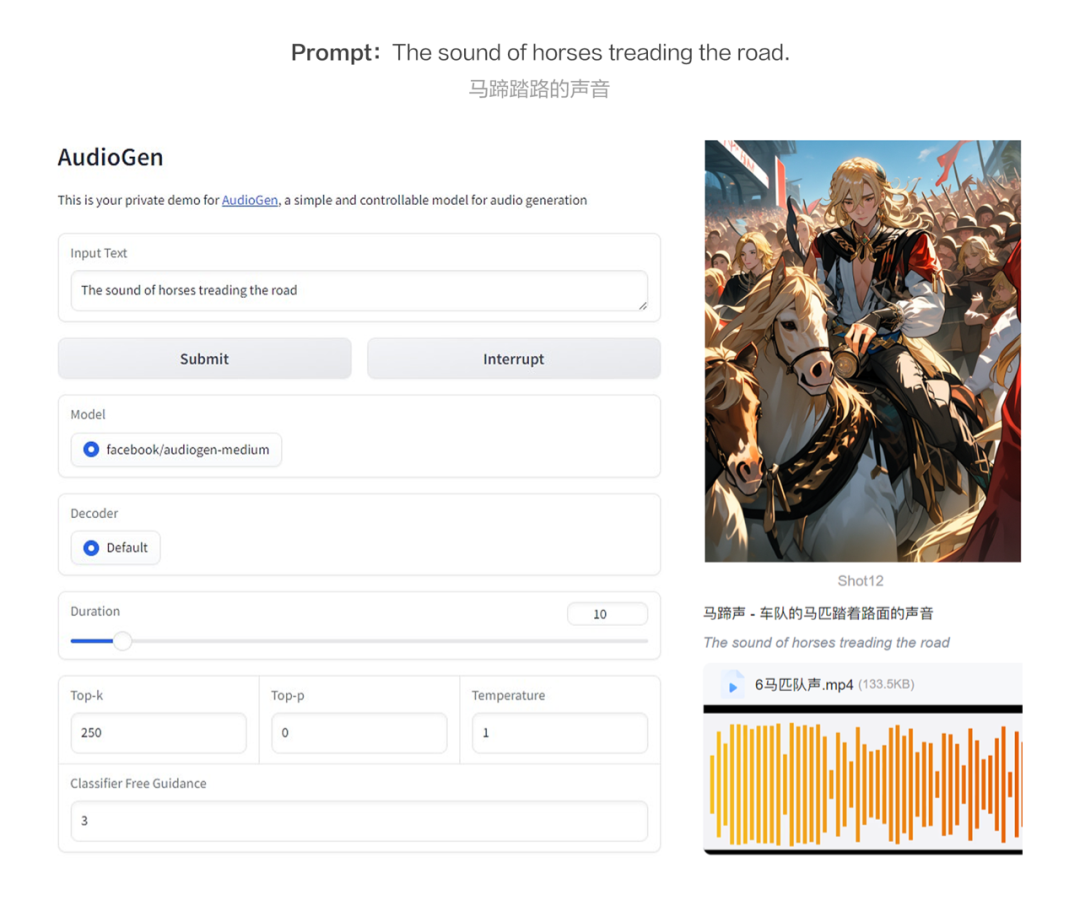
Meta正式开源了一款名为AudioCraft的AI音频和音乐生成工具,该工具可以直接从文本描述和参考音乐生成高质量的音频和音乐。AudioCraft包含MusicGen、AudioGen和EnCodec三个模型,分别实现音乐生成、音频生成和自定义音频模型构建。我们不断探索音频模型的内容供给,规划AI音效库建立模式,为素材供给扩展可能性。
下期预告
本篇内容主要为AI动漫视频工具的基础能力搭建,概述了我们在模型供给、画面控制、规范制定、音频合成等多个方面如何进行调优,以满足产品功能。
在未来的工具2.0迭代中,我们还将从文本转化、画面控制、动态生成能力等方面入手,全面提升视频品质。此外,我们还会通过对多项AI能力的探索,衍生短剧、预告片生成能力,打造AI生视频领域头部产品。大家敬请期待吧~
感谢阅读,以上内容均由百度MEUX团队原创设计,以及百度MEUX版权所有,转载请注明出处,违者必究,谢谢您的合作。
本文由人人都是产品经理作者【百度MEUX】,微信公众号:【百度MEUX】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。


















感觉很不错啊