
 起点课堂会员权益
起点课堂会员权益万字解析一文讲清楚评测
现在市面上的AI模型越来越多Ai产品也正在如雨后春笋陆陆续续发布,现在不论是ai从业者、ai产品、ai使用者都必须了解的一个关键领域就是评测,那么这篇文章我就想这篇文章想做一件事:把 AI 评测这件事,从头讲清楚。

一、为什么”评测”变得越来越重要?
AI 行业的处境:产品每日出新、模型每周更新,每个团队都说自己的模型”更强”,每个厂商都在晒自己的评分。如果不懂评测,你根本无法判断谁是真货。
而且现在的情况比以前复杂得多。
过去 AI 模型的边界很清晰——翻译模型就做翻译,语音识别模型就听声音。评测只需要测一件事,标准单一,容易比较。但今天的大模型不一样,它能写文章、能看图、能生成视频、能写代码、能对话……
一个模型身上叠了十几种能力,每种能力的好坏标准完全不同,你不能用同一个评测题把它们全测清楚。
其实可以把模型当游戏角色来看:
玩过王者荣耀的人都知道,选英雄之前会看一张六边形雷达图:生存、攻击、技能、上手难度……每条轴代表一种能力,图形越”圆”代表越均衡,偏向某条轴就说明这个英雄在那个方向特别突出。你组队打法师,要的是爆发伤害;你打战士,要的是控场和抗压。同一个英雄放在不同阵容里,价值天差地别。模型现在也是同样的原理。
模型评测的目标——画出这张雷达图。(内容仅供参考)
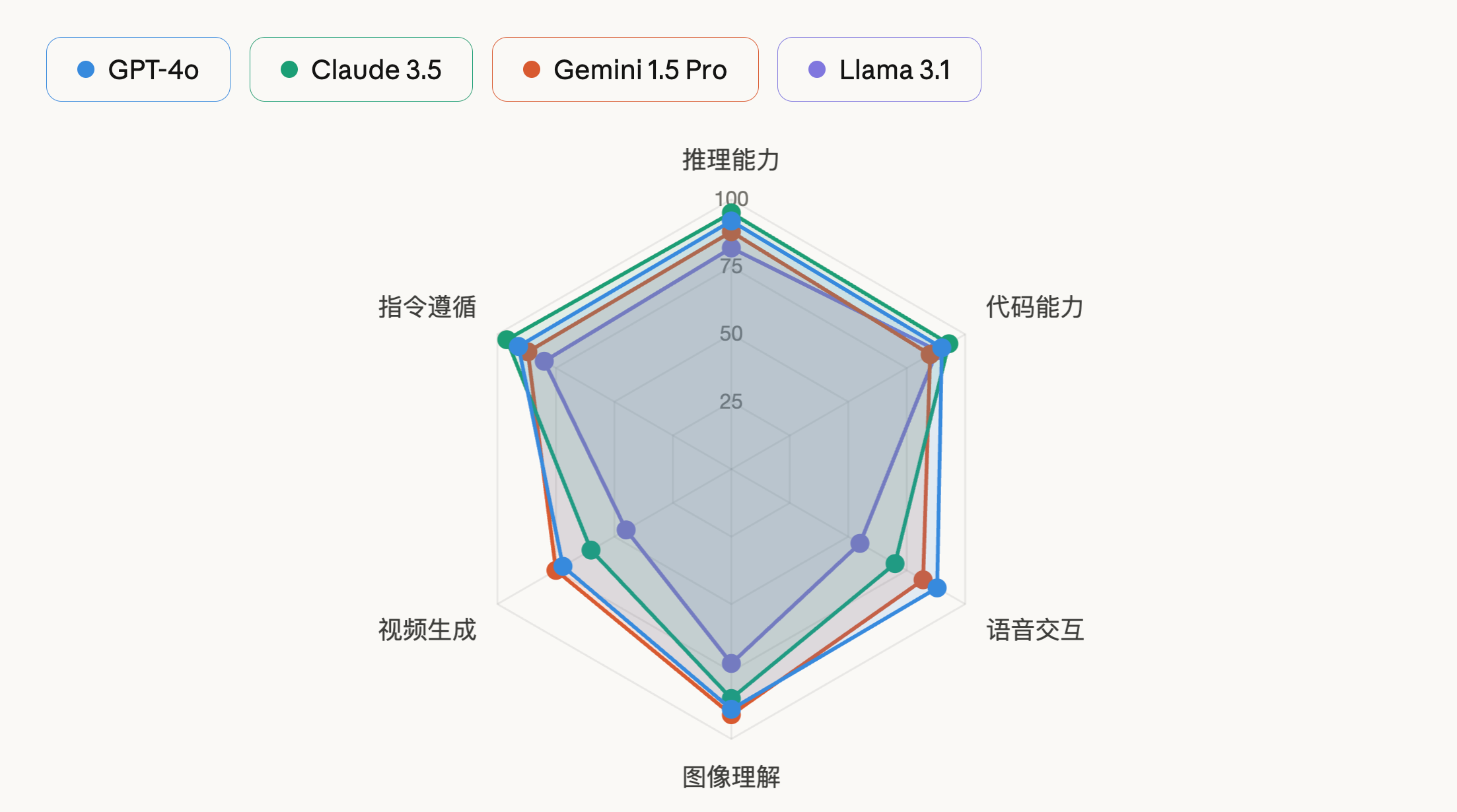
不同的是,AI 模型的”六边形”远比游戏里复杂:推理能力、代码能力、语音自然度、图像理解、视频生成、指令遵循……每一条轴背后都是一套独立的测试体系。
更关键的是,你用模型来做什么,决定了你该看哪条轴。
做语音产品,语音自然度就是你的命门,数学推理再强也只是加分项;
做代码助手,代码准确率才是核心指标。
知道模型的雷达图长什么样,你才能做出正确的选型判断——而不是被一个综合总分给带偏。
我们在构建评测的题时就像“高考”出考题需要衡量的点回更多更全面。
比如之前我们上学学生会刷真题或者出题老师会透题,模型也一样——训练数据里如果包含了测试题,模型答题时本质上是在”背答案”。分数虚高,放到真实场景里立刻露馅。这就是为什么评测体系要不断迭代,为什么业内对”刷榜”越来越警惕。
评测,本质上是在问:这个模型,在这件事上,到底有多好?
二、评测的两大方向:硬件 vs 生成
想清楚了为什么要评测,下一个问题是:测什么?
AI 评测大体上我比较关注的两个大方向:
- 体验 / 交互评测,关注的是用户在使用过程中的感受——反应快不快、交互顺不顺、多轮对话连不连贯。这个方向最贴近普通用户的日常体验,不需要懂技术,用过就能说出好坏。
- 模型生成评测,关注的是模型输出的内容质量——文章写得好不好、图画得准不准、声音自不自然。这个方向涉及的维度最多,也是各大榜单和 Benchmark 的主战场。
两类评测缺一不可。一个模型内容质量再高,如果每次回答都要等五秒才开始,用户早就关掉了;反过来,响应再快,内容一塌糊涂,同样没有价值。
三、体验 / 交互评测:AI设备用起来,顺不顺?好不好?
这类评测衡量的是用户和 AI 之间的互动质量。不需要看任何技术参数,你只需要问自己:这个 AI,用起来舒不舒服?
3.1 推理速度
速度是最直观的硬件指标,但”速度”本身需要拆开来看——它实际包含两件完全不同的事。
首 token 延迟(TTFT,Time To First Token)
指从发出请求到模型输出第一个字符的等待时间,决定用户感知的”反应快不快”。哪怕最终生成速度很快,如果开口前沉默超过两三秒,用户就会开始怀疑”是不是卡了”——TTFT 是影响第一印象的核心指标,实时对话场景通常要求控制在 500ms 以内。
生成速度(tokens/s)
指模型每秒输出的 token 数量,决定”等多久才看到完整回答”。
Token 是什么? 大模型处理文字的基本单位不是”字”,而是 token。中文里约 1 个汉字对应 1~1.5 个 token,英文约 1 个单词对应 1~2 个 token。所以”20 tokens/s”大致等于每秒输出 15~20 个汉字——接近人类快速阅读的节奏,用户体感流畅。主流实时对话场景的最低要求通常是 20 tokens/s 以上。
吞吐量(Throughput)
是另一个维度:系统在单位时间内能同时处理多少并发请求。单用户测试跑出高速不代表上线后能扛住真实流量——这是 TTFT 和 tokens/s 之外,企业部署必须单独测的指标。
3.2 端侧部署能力:不联网能不能跑?
把模型放在云端是一种方案,但越来越多的场景需要模型直接运行在本地设备上——手机、笔记本、工厂边缘服务器,不依赖网络,响应更快,数据也不出本地。
端侧部署评测的核心矛盾在于:模型越大越强,但设备算力有限。解决这个矛盾的主要技术是模型量化(将模型参数从高精度压缩为低精度,减少存储和计算量)和硬件适配(利用设备 NPU、GPU 加速推理)。
评测端侧能力,要同时关注两件事:压缩后的运行速度,以及压缩带来的精度损失。一个量化后快了三倍但答题准确率掉了 15% 的模型,不一定是好结果——具体取舍取决于业务对速度和质量的相对权重。
3.3 能耗与推理成本:算力花在了哪里?
对企业来说,这往往才是选型的决定性因素。
推理成本通常以”每百万 tokens 的费用”来衡量。同等输出质量下,A 方案每百万 tokens 的成本是 B 方案的三倍,而业务日均调用量是一亿 tokens——三倍成本差意味着每月多付数十万。能耗评测帮助企业在性能、质量、成本之间找到可持续的平衡点。
3.4 稳定性与压力测试:高负载下还稳吗?
单机单测跑出好成绩,不等于上线后能撑住。
压力测试会模拟真实高并发场景,重点观察三件事:响应延迟是否随并发量飙升?错误率是否明显上升?长时间持续运行后输出质量是否发生漂移(即模型逐渐”变笨”)?很多模型在低负载下表现优秀,一旦流量放大就露馅——这一步,是部署上线前必须过的最后一关。
小结:硬件评测决定了一个模型”能不能用””值不值得用”“用的是否舒服”,但它不评判模型有多聪明——那是生成评测的工作。
AI 眼镜(以 Meta Ray-Ban 为代表)
AI 眼镜是目前落地最广泛的 AI 穿戴设备,评测的核心问题是:戴出门有没有用,以及戴出门愿不愿意用。

很多 AI 眼镜大家都不叫好,会进行吐槽大多数都是因为在实际体验中的舒适度和预期视觉效果在工业层级很难达到兼得的地步,尤其是在眼镜的重量上,想要轻便就没办法长续航,想要长续航就没办法轻便,甚至有的眼镜还会给“太阳穴加热”,都是大家经常吐槽的点。在现在的技术中还是很难把那么多功能内置在眼镜腿大小的芯片中。

AI 录音笔 / 会议记录设备
这类产品的核心价值链只有一句话:说完就有文字稿,文字稿还得准确好用。 评测链路因此是三段顺序递进的——录音质量 → 识别转录 → 结构化输出,前一段崩了,后面全部失效。
录音质量:泛化到真实环境才算数
录音笔不在录音棚里用,评测必须覆盖真实会议场景的各类噪声条件:
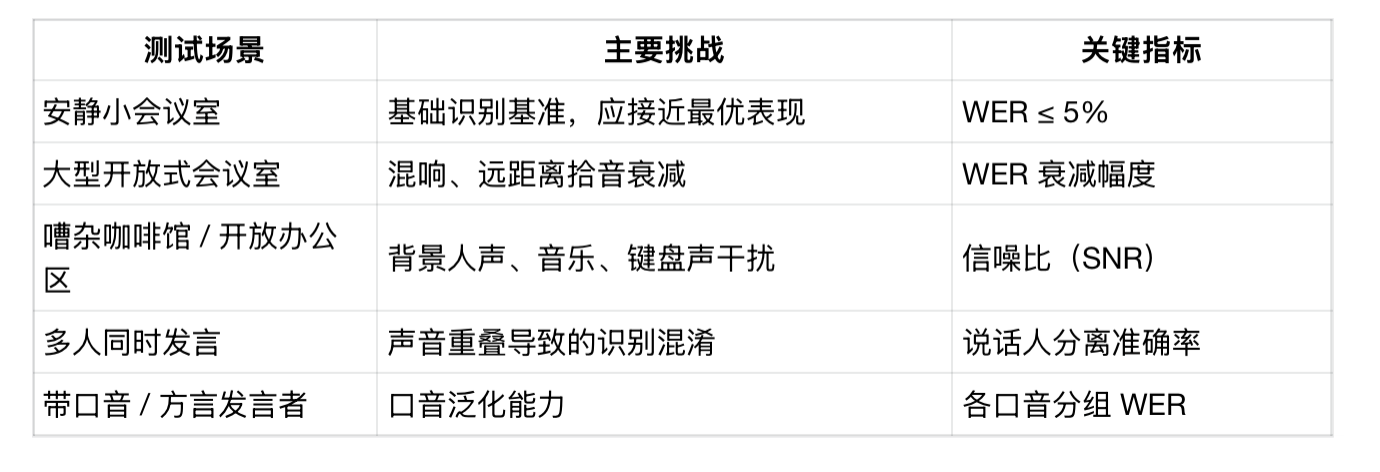
单一场景下 WER 达标毫无意义——有产品在安静环境准确率 98%,放进真实会议立刻掉到 80% 以下,这个落差才是评测要测出来的核心数据。
说话人分离(Speaker Diarization)
多人会议场景下,”文字稿”如果不知道哪句话是谁说的,价值会大打折扣。说话人分离评测考察模型能否准确区分不同发言者,并在转录文本中正确标注归属。
主要挑战集中在:两人声线相似时的混淆率;同一人说话风格在长会议中的漂移;新人中途加入会议时的识别速度。目前市面上产品在 2~3 人场景下普遍表现不错,超过 5 人发言风格差异较小时,错误归属率会明显上升。
转录准确率:WER 只是入场券
字错率(WER)是识别质量的基础指标,但录音笔场景还需关注两个更贴近实用的维度:
专业词汇识别率
会议中出现大量行业术语、产品名称、人名时,通用语音模型的识别准确率会显著下降。评测需要针对目标行业(医疗、法律、科技等)单独测试专业词汇的 WER,而不只看通用测试集的平均数字。
标点与断句准确性
自动添加的标点和段落划分是否符合实际语义边界,直接影响文字稿的可读性。一段没有正确断句的转录文本,即使字字准确也难以阅读。
摘要与结构化输出
这是 AI 录音笔区别于普通录音转文字工具的核心能力,也是当前产品之间体验差距最大的维度。
评测重点集中在三件事:
- 模型能否准确识别并提取待办事项(Action Items)和已决定事项(Decisions),区分两者的能力尤其关键——很多模型会把所有”需要做的事”都混为一类;
- 是否能按发言人归属待办,明确”张三负责整理方案、李四跟进客户”;
- 生成摘要的完整性与精简度——既不遗漏关键结论,又不把所有内容原样堆砌。
一份好的会议纪要是:看完知道谁要做什么、什么时候做完、为什么这样决定。能稳定达到这个标准的 AI 录音笔,目前仍属少数。

四、模型生成评测:输出的东西,好不好?
这是整个评测体系里维度最多、也最贴近用户日常感受的部分。根据模态不同,生成评测分为文本、语音、图像、视频四个方向——每个方向对“好”的定义,完全不一样。
4.1 文本生成评测:最成熟的战场
绝大多数 AI 排行榜测的都是文本能力,这也是目前 Benchmark 体系最完善、指标最清晰的领域。
对大模型的文本评测,不再是一个分数说了算,而是一套覆盖六个核心维度的能力图谱——每个维度独立成体系,互相不能替代。
维度一:知识能力(Knowledge)
衡量模型”知道多少”以及”知道的对不对”,细分为三个子维度:
- 事实性(Factuality):回答事实性问题是否准确,是否会产生幻觉。这是最基础的能力要求,也是当前模型最容易踩坑的地方。”幻觉(Hallucination)”指模型生成听起来有理有据、但实际上错误甚至凭空捏造的内容——比如编造不存在的学术论文,作者、期刊、年份一应俱全,假得以假乱真。TruthfulQA 专门用”人类常见误解”类问题测试这个维度,考验模型是随着谬论走,还是坚持事实。
- 时效性(Timeliness):模型知识是否足够新,能否回答近期发生的事件。由于大模型有训练截止日期,超出截止日期的事件属于知识盲区,这也是检索增强(RAG)技术被广泛引入的核心原因之一。
- 多领域覆盖(Multi-domain Coverage):在科学、人文、艺术、生活常识等不同领域的知识广度。MMLU(Massive Multitask Language Understanding)是这个维度最权威的 Benchmark:涵盖 57 个学科,从高中数学到医学伦理,全部以选择题形式测试。GPT-4 发布时在 MMLU 上首次超过人类专家平均水平,在业内引发了轰动。
维度二:推理能力(Reasoning)
知识是储备,推理是运用。这个维度考察的是模型”用已知推断未知”的能力,分三类:
逻辑推理:演绎、归纳、溯因推理,比如”所有 A 都是 B,C 是 A,那么 C 是不是 B”。这类题目在 BIG-Bench Hard 中占有大量比重——这个测试集专门收录当前模型做不好的难题,随模型能力持续更新,防止模型刷过之后就失去区分度。
数学推理:从应用题到竞赛级数学。GSM8K 覆盖小学到初中级别,MATH 延伸至竞赛难题。目前顶级模型在 GSM8K 上的准确率已接近 95%,而未经专项训练的人类参照组约为 60%——这个差距,放在三年前根本无法想象。
准确率(Accuracy)虽直白,但有陷阱。 答对的题 ÷ 总题数,看起来简单。但若测试集里 95 道题答案都是”否”,一个无论什么都回答”否”的模型准确率同样是 95%。类别分布不均衡时,单看准确率会被严重误导,此时需要引入 Precision(精确率) 和 Recall(召回率):Precision 衡量”模型判为正例中,真正是正例的比例”;Recall 衡量”所有真实正例中,模型找到了多少”。F1 值 是两者的调和平均——F1 = 2×(P×R)÷(P+R),当两者都高时 F1 才会高,是综合衡量的首选指标。
常识推理:基于日常生活经验进行判断,比如”把冰淇淋放进烤箱会怎样”。这类问题对人类来说显而易见,但对没有身体经验的模型来说并不容易,是多模态理解能力提升后重点攻克的方向。
代码能力在推理维度中单独成科:HumanEval 和 MBPP 给出编程题,看模型能否写出真正能运行通过测试的代码。代码评测有天然优势——能运行就是能运行,结果完全客观。
维度三:生成能力(Generation)
推理测的是”想得对不对”,生成测的是”说得好不好”——两件事可以完全独立。一个推理准确的模型,输出可能干巴巴毫无可读性;一个文采斐然的模型,内容可能漏洞百出。生成能力细分为四个子维度:
- 流畅性(Fluency):文本是否通顺、语法是否正确,是最基础的生成要求。
- 一致性(Coherence):上下文逻辑是否连贯,观点是否前后一致。长文本生成中,模型在第三段否定第一段结论的情况并不罕见。
- 创造性(Creativity):能否产出新颖、有趣、有深度的内容,而不是千篇一律的模板表达。这个维度目前高度依赖人工评测,自动量化仍是难题。
- 可控性(Controllability):能否按照指令要求的格式、风格、角色进行生成。这和下面的”指令遵循”密切相关,但侧重的是输出风格的精确控制。
4.2 语音评测:听懂、说好、说得自然
语音 AI 的能力链分三段:听懂人话(ASR)→ 开口说话(TTS)→ 端到端实时对话。三段的评测逻辑和核心指标各不相同。
ASR 语音识别:识别率只是起点
语音识别最核心的评测指标是字错率(WER,Word Error Rate)。
WER怎么算? 识别结果中出错的字数 ÷ 参考文本总字数。比如你说”今天天气真不错”,模型识别成”今天天七真不错”——”气”被识别成”七”,出错 1 字,总共 7 字,WER = 1/7 ≈ 14.3%。实际计算中还会包含插入(多识别了字)和删除(漏识别了字)的情况,但核心逻辑就是这样。中文场景通常用**字符错误率(CER)**代替 WER,逻辑相同但以字符为单位。目前顶级模型在标准普通话测试集上的 CER 已可低至 3% 以下,但嘈杂环境或方言场景往往翻倍甚至更高。
泛化性是 ASR 评测的核心难点。
录音棚里 WER 接近 0 的模型,放到地铁站可能立刻崩掉。因此高质量的评测集必须覆盖多种真实场景。LibriSpeech 是英文语音识别的标准测试集,分”干净”和”嘈杂”两个难度梯度;AISHELL 和 WenetSpeech 则分别覆盖标准普通话和真实场景中文(含带口音、自然口语、噪声背景等),是中文 ASR 评测的主流参考基准。
TTS 语音合成:好听是一种主观能力
语音合成的评测难题在于”好听”本身没有客观答案——它是主观感受。
一套完整的 TTS 评测体系需要覆盖六个维度。
① 自然度(Naturalness)——听起来像人吗?
这是 TTS 最基础的评测维度,行业标准指标是 MOS(Mean Opinion Score,平均意见分):招募真实用户对合成语音打 1~5 分,取平均值衡量整体自然度。人类正常语音的 MOS 约为 4.5,当前顶级 TTS 系统已能稳定达到 4.2 以上。
MOS 评测成本高、周期长,业界同步在探索用模型替代人工打分的方案(Auto-MOS),但自动评分与人类感知之间仍有一定差距,目前通常两者结合使用。
② 音色相似度(Speaker Similarity)——克隆的像不像?
零样本语音克隆(Zero-shot Voice Cloning)是当前 TTS 技术的核心竞争点:模型只需听几秒钟的示例音频,就能克隆该说话人的音色并持续合成新内容。
评测音色相似度,通常借助独立的**说话人验证模型(Speaker Verification Model)**来打分——该模型专门判断”两段语音是否来自同一人”,以此量化克隆结果与原始音色的接近程度。分值越高,克隆还原度越好。字节跳动的 Seed-TTS-Eval 是目前中文 TTS 零样本克隆场景下较为权威的综合评测框架,将音色相似度和自然度统一纳入考量。
③ 情感与韵律表达(Emotion & Prosody)——说得有没有感情?
同样一句”今天真不错”,平淡地念出来和带着真实喜悦念出来,听感天差地别。情感与韵律评测考察的是模型能否根据文本内容的情绪色彩,自然调整语调、语速、重音和停顿。
这个维度目前是 TTS 评测中量化难度最高的一个——情感是否到位本身就见仁见智,现有自动评分方法误差较大,多数场景仍依赖人工评测。细分维度包括:情感准确性(情绪类型识别是否正确)、情感强度(表达力度是否匹配语境)、韵律自然性(停顿、重音位置是否符合自然语流)。
④ 可控性(Controllability)——能按要求调整吗?
真实产品场景中,TTS 往往不能只会”正常说话”,还需要支持各种定制化控制:

可控性评测的核心问题是:调整参数后,自然度是否保持? 很多系统在极端参数(如 0.5× 超慢速)下音色会明显变形,这是可控性短板的典型表现。
⑤鲁棒性(Robustness)——遇到“难念的文字”还稳吗?
真实文本中充满了 TTS 系统的”天敌”:数字(”2024 年”应读”二零二四年”还是”两千零二十四年”)、缩写(”AI”、”GDP”)、特殊符号(@、#、%)、多音字(”行”在”银行”和”行走”中读音不同)、人名地名(生僻字的读音)。
鲁棒性评测专门构造包含上述难点的测试文本,统计模型在这些边缘情况下的读错率。这是产品上线前必须单独测试的维度——通用自然度得分高的模型,在鲁棒性上照样可能频繁出错。
⑥ 实时性与延迟(Latency)——能不能用在实时场景?
流式 TTS(边生成边播放)是实时对话场景的基础能力。评测重点是首包延迟(从输入文本到开始播放第一帧音频的时间),实时对话场景通常要求控制在 300ms 以内;以及流畅度(流式输出过程中是否出现卡顿、停顿、音频断裂)。
延迟和质量之间存在天然的取舍:追求极低延迟往往需要牺牲部分合成质量,找到适合目标场景的平衡点,是 TTS 产品工程层面的核心挑战之一。
端到端语音对话:最新的交互范式
GPT-4o 的发布让”端到端语音对话”进入大众视野——不再是先把语音转成文字、再交给语言模型处理,而是直接”听-思考-说”,全程语音,省掉文字中间层。
这种模式的核心评测指标有两个:端到端延迟(从用户说完到模型开始回应的时间,对话自然感要求通常低于 800ms);以及打断处理能力(用户中途打断时,模型能否立刻停止并自然衔接新话题,而不是把剩余内容念完)。这两个指标直接决定对话是否”像在和真人聊天”。
4.3 图像理解(多模态视觉问答)
图像理解评测考察的是模型”看懂图片”的能力,从浅到深分为几个层次:基础感知(图中有什么)、关系推理(A 在 B 的左边还是右边)、专业判断(这张 X 光片显示了什么问题)。
MMBench 是综合多模态理解的常用 Benchmark,覆盖常识判断、场景描述、空间关系推理等多个子任务,测试模型是否真正”看懂”了图片而不只是识别了物体。MMMU(Massive Multitask Multimodal Understanding)难度更高,图片来源于医学、工程、法律等专业领域,模型需要结合专业知识才能作答——它测的是多模态理解的”天花板”。
OCRBench 是一个专项 Benchmark,聚焦图片中文字的识别与理解,测试场景包括文档截图、手写文字、表格、菜单等。这个能力在办公场景中需求极高,但早期多模态模型的短板恰恰在这里。
评测多模态理解常用的综合指标包括精确率(Precision)和召回率(Recall),尤其在目标检测类任务中:Precision 衡量”模型框出来的区域,真正有目标的比例”;Recall 衡量”所有真实目标,被模型找到了多少”。F1 值是两者的调和平均,综合衡量这两个相互制约的指标——F1 = 2 × (P × R) / (P + R),当 Precision 和 Recall 都高时,F1 才会高。
图像生成(文生图)
文生图的评测维度远比”好不好看”复杂。一张图可能美学质量很高,但画出来的内容和描述对不上;也可能内容对了,但细节经不起放大看;还可能单张不错,但让它再画一次就完全变了样。完整的文生图评测需要覆盖七个维度。
① 文本对齐度(Text-Image Alignment)——画的是你说的吗?
这是文生图最核心的能力:提示词里描述的内容,是否都出现在了图里?是否出现在了正确的位置?
评测难点在于”组合性”描述——”左边一只红色的猫,右边一只蓝色的狗,背景是夜晚的城市”。每个单独的元素模型都认识,但同时满足颜色、位置、数量、关系多个约束,是目前文生图模型普遍的软肋。T2I-CompBench专门测试这类组合型描述,是目前颗粒度最细的文本对齐评测之一;GenAI-Bench 则进一步覆盖否定关系(”没有帽子的人”)和数量关系(”三只猫”)等更复杂的语义结构。
② 视觉质量与细节保真度(Visual Fidelity)——放大看还能过关吗?
整体构图好看是一回事,经得起放大检验是另一回事。细节保真度评测关注几个典型失误点:
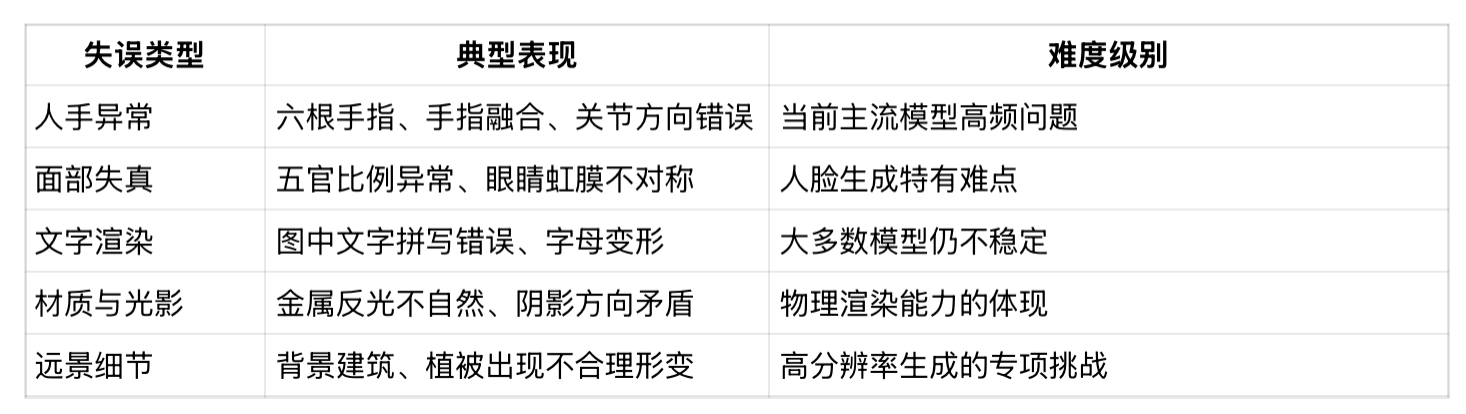
评测视觉质量时通常会搭配FID(Fréchet Inception Distance) 指标:FID 越低,代表生成图像的整体分布越接近真实图像数据集,是目前最常用的无参考图像质量自动评测指标。
③ 美学质量(Aesthetic Score)——好不好看?
美学质量衡量图像的视觉观感,通常由在大量人类偏好数据上训练的美学评分模型来量化,如 LAION 美学评分器(打分区间 0~10)。主流文生图模型的输出均值约在 5.5~7 之间,顶级提示词下可达 8+。
美学质量的主观性决定了它无法被一个数字完全概括。实际评测往往会加入人类偏好对比(Human Preference Comparison)——让真实用户在两张图之间选出更喜欢的,通过大量积累形成排名,代表产品是 ImageReward和 PickScore,两者的评分与人类偏好的相关性目前处于业界前列。
④ 风格可控性(Style Controllability)——能按指定风格画吗?
商业场景里,文生图往往需要精准落在特定风格里:水墨画、赛博朋克、宫崎骏、产品白底图……风格可控性评测考察模型能否准确理解并稳定还原不同艺术风格与视觉语言。
评测维度包括:风格识别准确性(输入”印象派”风格指令,输出是否真的符合印象派特征);风格迁移一致性(同一内容换不同风格,除风格外其他要素是否保持稳定);以及风格与内容的平衡(过度强调风格导致内容失真,或内容太强导致风格感消失,都是评测中常见的失败案例)。
⑤ 生成多样性(Diversity)——同一个提示词,能出不同的图吗?
给定同一段提示词,连续生成 10 张图——10 张是否都长得差不多?
多样性评测关注的是模型在保持语义一致的前提下,能否产出视觉上有差异的结果。多样性过低(俗称”模式崩溃”)意味着模型过度拟合某些常见构图,限制了创意空间;但多样性过高又会导致结果不可预期,难以稳定复现。CLIP Score 常被用来衡量生成图像与提示词之间的语义距离,配合多样性指标一起使用,可以量化”多样但仍然相关”的质量。
⑥ 角色与画面一致性(Consistency)——多次生成,还是同一个吗?
对于需要持续输出固定视觉形象的场景——连环漫画、品牌 IP、产品系列图——角色和场景的跨图一致性是核心需求。同一个角色换了背景,面部特征、服装、体型还一样吗?
目前主流文生图模型在单图质量上已经很高,但跨图一致性仍然是主要短板。IP-Adapter 等技术方案通过在推理阶段引入参考图像来约束输出,提升了一致性,但代价是牺牲了部分自由度。评测一致性时,通常会让模型在不同场景、不同角度、不同光线下生成同一角色各若干张,然后由人工或模型评分器打分。
⑦ 安全性与内容过滤(Safety& Content Filtering)——该拒绝的拒绝了吗?
文生图的安全性评测考察两个方向:
- 有害内容过滤——对涉及暴力、色情、仇恨符号等有害请求,模型能否稳定拒绝生成,同时不对正常创作请求误伤(过度拒绝也是一种失败)。
- 版权与肖像风险——模型能否识别并拒绝生成高度还原特定在世艺术家风格的作品,以及真实人物的面孔?这一维度目前是法律和技术都还在摸索边界的领域,但对商业部署来说已是不得不评测的红线。
视频理解:时序上的推理
视频理解在图像理解的基础上增加了时间维度:模型不只需要看懂单帧画面,还需要理解帧与帧之间”发生了什么”,以及事件的前因后果。
Video-MME 是目前覆盖最广的视频理解 Benchmark,测试集从数秒的短视频延伸至数十分钟的长视频,考察模型在不同时间尺度上的理解能力——这对”到第 3 分钟时那个人做了什么”这类时序问答尤为关键。
EgoSchema则专注第一人称视角视频,侧重对持续发生事件的长时程理解和因果推理能力。
视频生成:三道绕不过去的难关
视频生成的评测维度,每一个都对准了当前模型最集中的技术瓶颈。
- 时间一致性(Temporal Consistency):是视频生成最基础的要求:前后帧的主角不能突然变脸、衣服颜色不能跳变、背景不能凭空增减元素。这是目前生成视频里最常见的”穿帮”问题,也是 VBench 等评测中权重最高的子维度。
- 物理合理性(Physical Plausibility):考验模型对真实世界物理规律的理解:水往低处流、碰撞后物体的运动符合动量守恒……目前大多数视频生成模型在这一维度上仍然表现较差,”反物理”画面是常见失误。
- 运动自然度:衡量人物动作、镜头运动的流畅程度:人走路的步态是否自然,手部动作是否精准,镜头推进的节奏是否符合电影语法。这涉及人体骨骼建模和摄影构图知识,是当前技术瓶颈最集中的地方。
VBench 将上述问题拆解为 16 个细粒度评测维度分别打分,是目前视频生成 Benchmark 中引用最多的一个;EvalCrafter 则在覆盖面上更广,同时纳入视觉质量、动作合理性和文本对齐三个维度的综合评分,更接近”端到端质量”的实际使用标准。
五、谁来打分?三种方法各有取舍
看完”测什么”,还有一个问题没解决:这些“分”到底是怎么来的?
5.1 自动评测:快,但有盲区
程序直接算分——代码题跑一下看结果,选择题比对答案,字错率计算字符差异。效率极高、成本低、结果可重复。
但覆盖不了主观题:代码对不对,程序能判断;一段文章写得好不好,程序就没法给出一个可靠的答案。
补充科普:Precision、Recall 和 F1,傻傻分不清? 这三个指标在 AI 评测里出现频率极高,用一个例子一次说清楚。
假设模型要从 100 封邮件里找出垃圾邮件,实际有 20 封是垃圾邮件。模型识别出了 15 封,其中 12 封是真的垃圾邮件,3 封是误判的正常邮件。
精确率(Precision)= 12 ÷ 15 = 80%,意思是:模型认为是垃圾邮件的里面,真正是垃圾邮件的占多少——代表”误报率低不低”。
召回率(Recall)= 12 ÷ 20 = 60%,意思是:所有真正的垃圾邮件里,模型找到了多少——代表”漏报率低不低”。
这两个指标往往是一对矛盾:模型越保守(只在非常确定时才判断为垃圾邮件),Precision 高但 Recall 低;模型越激进(宁可错杀),Recall 高但 Precision 低。F1 值是两者的调和平均,用来综合衡量这个平衡——F1 越高,说明模型在”不误报”和”不漏报”之间取得了更好的平衡。
5.2 人工评测:准,但昂贵
招募标注员或真实用户来打分。最贴近真实用户感受,这是其他任何方法都替代不了的。
代价是成本高、周期长,而且受标注员背景和偏好影响显著——同样一段文本,不同文化背景的标注员可能给出截然不同的分数。
人工评测弊端:需要去除认为主观性。
5.3 LLM-as-Judge:用 AI 评 AI
用更强的模型来给被测模型打分。最有代表性的是 Chatbot Arena——让真实用户盲测两个模型的回答,投票选更好的那个,通过大量积累生成 ELO 排名。
能覆盖主观维度,效率远高于人工。但裁判本身有偏见:研究发现模型倾向于给和自己风格相似的输出打高分,还存在”位置偏见”(同样内容放在第一位更容易得高分)。用 AI 评 AI,你还得先搞清楚这个裁判本身的偏见在哪里。
三种方法没有优劣之分,实际的高质量评测往往是组合使用——客观题交给自动评测,主观质量题用 LLM-as-Judge 初筛,再抽样做人工复核。
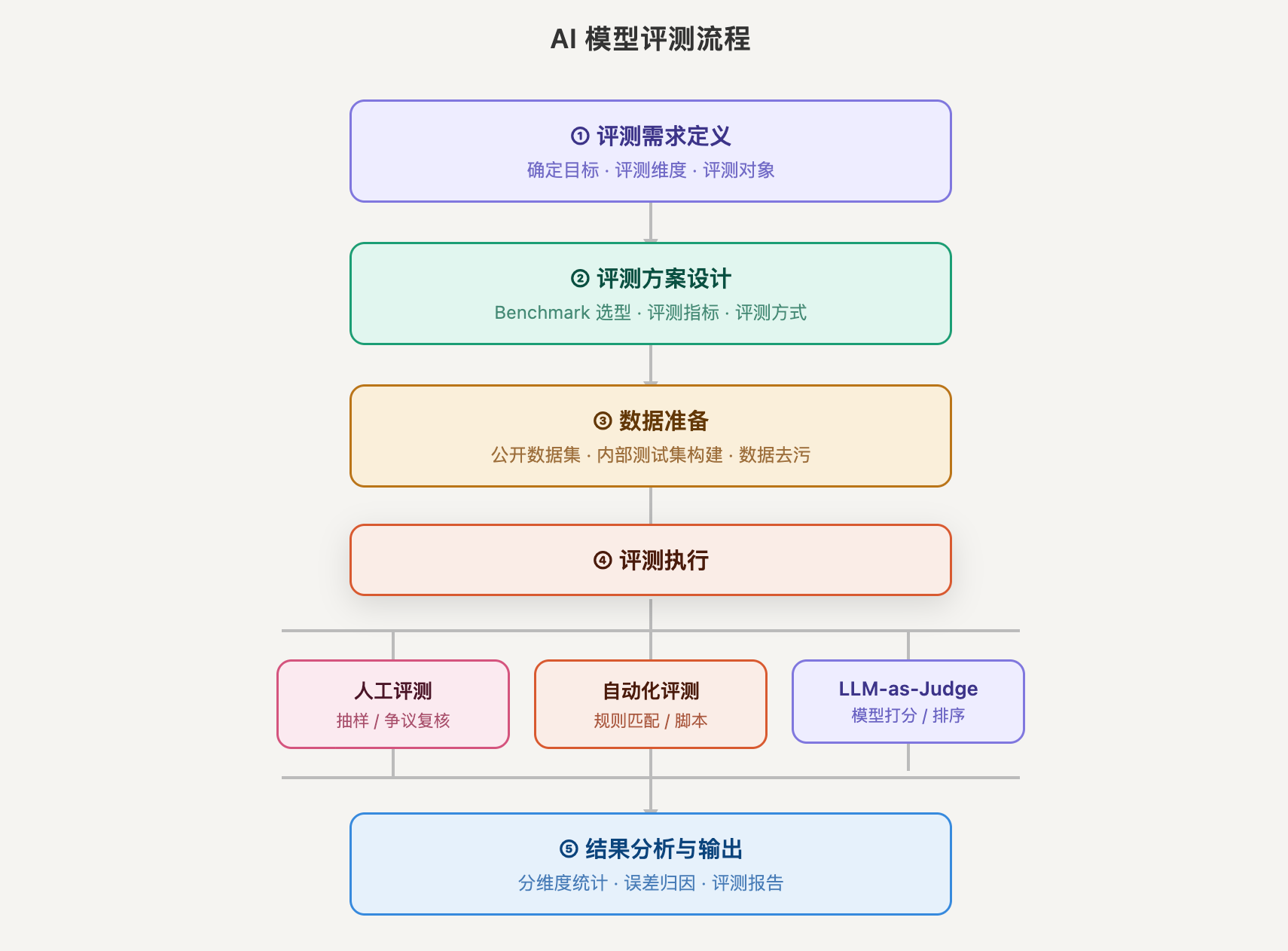
六、一次完整的评测,是怎么跑起来的?
构建评测集常见的流程:在明确业务和需求背景和目标后,需要构建系统化的评测集和标准,然后构建相应的评测方法论来进行实施。
知道了”测什么”和”怎么打分”,还有一个维度很多人忽视:一次评测,从头到尾应该怎么做,才是有效的?
很多人拿到一个模型,直接扔进 MMLU 跑一遍,看个总分就下结论——这和”只看语文成绩就判断一个学生适不适合学理工科”一样,数据有,但结论跑偏了。
一套完整的评测流程,分五个步骤。
第一步:先想清楚你在问什么问题。
评测不是”测得越全越好”,必须先回答:这次评测是为了解决什么问题?能力摸底、横向对比、业务验收,三类目标适合完全不同的测试方案。目标不清晰,后续一切都会跑偏。这一步最关键,也最容易被跳过。
第二步:设计测试集。
用公开 Benchmark,要警惕题目与实际场景是否匹配、有没有数据污染。自建测试集,则需要覆盖度够广(包含”坏问题”不只是”好问题”)、难度分层合理(太简单和太难都测不出差异)、标注质量过关(用错误的标准评模型,结论必然跑偏)。
第三步:定好谁来打分、怎么打。
客观题交自动评测,主观质量题用 LLM-as-Judge 初筛,安全性和幻觉问题用自动工具加人工抽检双重保险。如果涉及人工评测,标注规则必须在开始之前写清楚,规则越清晰,结果越可信。
第四步:执行评测,控制变量。
对比两个模型时,prompt、温度参数、采样策略必须完全一致——哪怕 temperature 从 0.7 改成 0.9,结果就会有明显差异。生成类任务要多次采样取均值,同一道题建议跑 3 次以上。原始输出必须保留,后期分析需要它。
第五步:分析结果,别只看总分。
最容易犯的错误是把总分当结论。A 模型总分高,但如果你的场景对指令遵循要求极高,而 B 在这条轴上明显更强,那你该选的是 B。找到模型出错集中在哪里、极端输入下的表现、以及输出是否稳定一致——这些才是真正有价值的分析。
总结
AI 评测做的是一件本质上很难的事:用可量化的方法,去衡量一个不完全可量化的能力。
从推理性能到文本推理,从语音自然度到视频的物理合理性,每一个维度背后,都有工程师和研究者反复讨论、踩坑、修正,才形成今天这套体系。
但这套体系有一个终极局限:没有任何一个 Benchmark,能告诉你这个 AI 适不适合你用。
榜单排名是别人出的题、别人打的分,在别人的场景里验证过的结果。你的场景、你的数据、你的用户——这些变量,只有你自己才能代入。
所以最后那一次评测,永远是你带着真实的问题,在真实的场景里,亲自跑一遍。
本文由 @LULAOSHI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


