
 起点课堂会员权益
起点课堂会员权益还在写PRD?AI时代的产品经理,核心交付物变了
在传统软件开发中,PRD是产品经理的圣经;但在AI时代,这份‘圣经’正在失效。面对非确定性的模型输出,静态的需求文档已无法指导迭代。本文深度拆解为何Eval(评测)正在取代PRD成为AI PM的核心交付物,从‘写文档’到‘定义好坏’,揭示如何通过构建评测飞轮实现AI产品的持续进化与复利增长。

Braintrust 发了一篇文章,标题六个字:Eval 就是新的 PRD。
一句话把 AI 时代产品经理的核心工作重新定义了。
传统产品开发是一条直线:问题 → 需求文档 → 设计 → 工程 → 上线。写个 spec,按 spec 做,验证 spec。但 AI 产品不是这么玩的——同一个 prompt 每次跑出来的结果都不一样。一句 “模型应该有帮助且简洁” 写在 PRD 里,太模糊没法执行,太含糊没法验证,太静态跟不上模型的变化。
PRD 是为确定性世界设计的。AI 产品的世界是非确定性的。
那 PRD 该被什么取代?答案是 eval——结构化、可重复、自动化的产品质量评测。这不是一个新概念,做机器学习的人一直在用。但 Braintrust 这篇文章的核心观点是:eval 不只是工程工具,它应该成为产品经理的核心交付物。
Braintrust (@braintrust) 发布的 “Evals are the new PRD” 长文,作者 @ornelladotcom
01 旧循环
传统产品开发的循环大家都很熟悉:
Problem → Spec → Design → Engineering → Ship
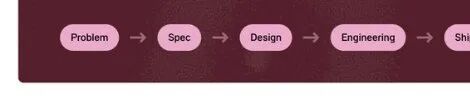
传统产品开发流程:问题→规格→设计→工程→上线,线性且确定
这套流程的前提是:你能在动手之前完整描述系统应该做什么。写一份需求文档,工程师按文档做,QA 按文档验。每个环节都有明确的输入和预期输出。
但 AI 产品打破了这个前提。你没法在 PRD 里写 “模型回答要准确”,因为 “准确” 是什么意思?一个食谱生成器,”准确” 是指食材没漏、步骤对、格式好看、还是用词简洁?每一个维度都需要单独定义、单独衡量。
更要命的是,AI 产品的行为会随着模型更新而变化。你上周写的 PRD,这周模型一升级,整个行为可能就变了。PRD 躺在 Google Doc 里吃灰,而你的产品已经面目全非。
这就好比你给一个厨师写了一份详细的菜谱,但每次做出来的味道都不一样。厨师还会时不时自动换口味——上周偏甜,这周偏咸。你的菜谱再详细,也管不住这个厨师。你唯一能做的,是在每道菜端出来之后尝一口,告诉他:这道对了,那道不行。
这就是 eval 的本质。
02 新循环
Braintrust 提出的新循环是这样的:PM 不再写需求文档,而是用代码定义 “好” 是什么样子。
Eval 同时扮演三个角色:它是产品规格(定义目标)、验收标准(衡量通过/失败)、产品路线图(指向下一步该改进什么)。
一份 eval 抵三份文档。
团队的工作方式变成了 hillclimbing——PM 设定 eval 的标准线,工程团队在 prompt、检索策略、工具选择、模型选型、系统架构上反复迭代,直到产品达标。eval 不及格?那就继续爬。分数提上去了?这个功能可以上线。下一轮 eval 的目标线再调高一点。永远在往上走。
“Writing evals is the most important thing a PM can do in the AI era.”
— Kevin Weil, VP of Science, OpenAI
OpenAI 的科学副总裁亲口说了:在 AI 时代,写 eval 是 PM 能做的最重要的事。
这句话有多重分量。不是 “写 PRD”、不是 “画原型”、不是 “做用户访谈”。是写 eval。
想想看,这意味着什么。传统 PM 的核心能力是 “把需求写清楚”。AI PM 的核心能力是 “把好坏定义清楚”。一个是散文写作,一个是考试出题。你不再是写文档给工程师看的人,你是给 AI 出考卷的人。
而且这个考卷不是出一次就完了。它会随着产品的演进不断更新,每一次线上出现的新问题都会变成新的考题。这不是一份文档,这是一个活的质量系统。
03 什么是 Eval
Eval 就是AI 行为的单元测试。
定义一组输入和预期输出,把它们跑过你的 AI 系统,然后用算法或者 AI 评审员来打分。它回答的核心问题只有一个:我的 AI 系统做对了吗?
文章举了一个非常具体的例子。假设你在做一个从烹饪视频生成食谱的功能,PRD 写着 “要有帮助且准确”。这句话有什么用?什么都没有。
但如果你把它拆成三个可衡量的信号:
- 食谱格式对不对?食材在前,步骤在后 → AI 评审员按评分标准打分
- 视频里提到的食材是不是都包含了? → 确定性字符串匹配
- 步骤是不是简短易扫? → AI 评审员,用好/差示例校准
三个信号,一座山。你不再跟工程师说 “把它做好”,而是交出一个 eval 说:”把这个数字提上去”。
这个思路跟传统 PM 的工作方式有本质区别。传统 PM 在 Google Doc 里写 “用户需要什么”,AI PM 在代码里写 “好的输出长什么样”。前者是散文,后者是测试用例。
我自己在做 AI 产品的时候有非常深的体会。每次偷懒不写 eval,就会陷入一个死循环:改了 prompt → 感觉变好了 → 换个 case 又变差了 → 改回去 → 不知道到底进步了还是退步了。没有 eval,你就是在黑暗里摸象。有了 eval,你至少有一盏灯。
而且注意食谱这个例子的精妙之处:三个信号里,有一个是确定性的(字符串匹配),两个是非确定性的(AI 评审)。真实的 AI 产品评测就是这样——不是所有维度都需要 AI judge,能用硬规则搞定的就用硬规则,该上 AI 的再上 AI。混搭才是正解。
04 飞轮
写出第一个 eval 并不难。难的是建飞轮。
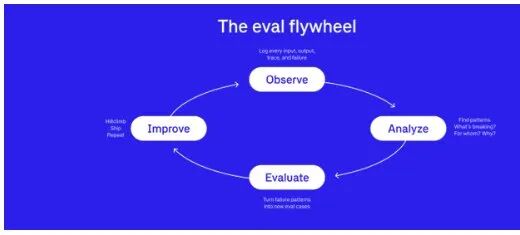
Eval 飞轮的四个阶段:Observe → Analyze → Evaluate → Improve,不断循环加速
飞轮有四个阶段:
- Observe(观察):记录每一次输入、输出、trace 和失败。你没法改进你看不到的东西。这一步最容易被忽视——很多团队上了 AI 功能,但连用户输入和模型输出都没有完整记录。没有数据,后面三步都是空中楼阁。
- Analyze(分析):找模式。什么在坏、在哪坏、为什么坏?是某一类输入总是出问题,还是某个时间段质量特别差?观测数据变成产品洞察。这一步需要 PM 像侦探一样去看数据,从一堆噪声里找到信号。
- Evaluate(评测):把发现的失败模式变成新的 eval case。每一个线上故障都是 eval suite 的候选。用户投诉不再是令人烦躁的事——它是免费的 eval case。
- Improve(改进):针对更新后的 eval suite 做 hillclimbing,上线,然后重复。
这个循环会自我加速。更多线上数据 → 更好的 eval → 更好的 AI → 更好的产品 → 更多用户 → 更多线上数据。这才是复利。
传统软件也有反馈循环,但通常是 “用户投诉 → 产品经理写需求 → 工程师修复 → 上线验证” 这样一个需要人工中介的慢循环。eval 飞轮的核心突破在于:失败到改进的路径被大幅压缩了。一个线上错误案例不需要经过产品经理翻译成需求文档,它直接变成一个 eval case,工程师跑一遍 suite 就知道改动有没有效。
从 “一个月一次大版本” 变成 “每天都在变好”。这不是效率提升,这是质变。
05 四个阶段
文章把团队的 eval 成熟度分为四个阶段,我觉得这个分级非常实用,可以直接对号入座:
Stage 0:Vibes(直觉阶段)。靠手动抽查、直觉和用户投诉。没有结构化的衡量,完全在盲飞。老实说,现在大部分 AI 团队还在这个阶段。你改了个 prompt,在 playground 里试了三个 case 觉得 “嗯不错”,就上线了。这不叫质量控制,这叫赌博。
Stage 1:Test Sets(测试集阶段)。有了带通过/失败标准的测试集,在大版本发布前跑。比 vibes 好太多,但还是被动的。
Stage 2:CI/CD(自动化阶段)。Eval 集成到 CI/CD 流水线里。坏的发布会被自动拦住,质量是系统性保障的。这就像给你的产品装了一个自动安检门——每次有人要推代码上线,先过一遍 eval。分数跌了就拦住,不让上。工程师不需要记得跑测试,系统替你记。
Stage 3:Flywheel(飞轮阶段)。线上数据持续回流到 eval suite。系统每周都在变好,因为真实世界的失败自动变成新的测试用例。这是复利开始积累的阶段,也是大多数团队应该瞄准的目标。到了这个阶段,你的产品就像一个永远在学习的学生——每次考试暴露的弱点,都会变成下一轮复习的重点。而且这个学生永远不会毕业,因为用户的需求和模型的能力都在不断进化。

Eval 成熟度四阶梯:从人工抽查(Vibes)到线上数据持续回流的飞轮
你的团队在哪个阶段?
06 三种评委
Eval 的核心组件之一是 judge——谁来判断 AI 的输出好不好。文章把 judge 分成三类:
算法评委:处理确定性检查。字符串匹配、格式验证、长度约束。快、便宜、完全可靠。比如检查食谱里有没有漏掉视频提到的食材——这就是纯字符串匹配,不需要 AI。
AI 评委:处理模糊的质量评估——语气、有用性、连贯性。可以瞬间扩展,但需要用人类判断来校准才可信。比如判断一段食谱说明写得是否 “简洁易读”,这就需要用好例子和差例子来校准 AI judge。
人类对齐的 AI 评委:处理深度主观的评估。人类审核提供 ground truth,AI judge 学着去逼近。这类最难做好,但对于 “合理的人可能会有不同意见” 的复杂质量维度,这是唯一的办法。比如判断一篇文章 “写得好不好”、一段对话 “是否有同理心”——这些维度没有标准答案,只能用人类标注来教 AI 什么是好的。
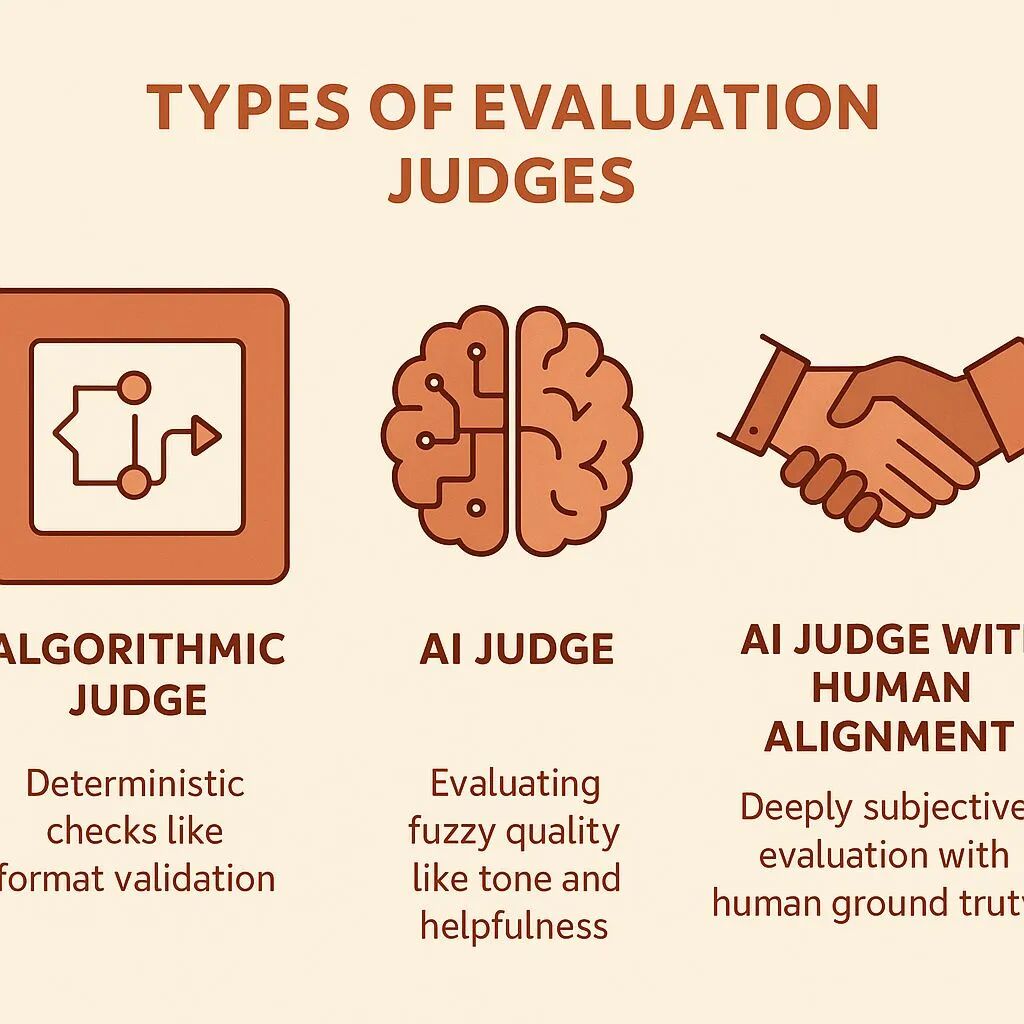
三种 Eval 评委:算法评委(确定性检查)、AI 评委(模糊质量评估)、人类对齐 AI 评委(主观评估)
关键不是选哪一种,而是知道什么时候用哪一种。能用算法解决的就别用 AI,需要 AI 的就别偷懒不校准。
07 常见坑
文章列了几个坑,我觉得每个都扎心:
试图衡量 “通用智能”。你的食谱生成器不需要在 MMLU 上拿高分。通用 benchmark 不会告诉你食谱格式对不对。给你的产品写它自己的考试。就像你不会用高考数学成绩来评价一个厨师的厨艺,你也不应该用通用 benchmark 来评价你的 AI 产品。你的产品有它自己的质量标准,只有你自己能定义。
Eval 设计拉太多人。人越多,妥协越多,eval 越没焦点。保持小团队、有主见。Eval 应该由最了解用户的人来写,通常就是一两个 PM,而不是一个十人评审委员会。
只在上线时跑 eval。模型在变,数据在漂移,边界 case 在积累。不持续跑的 eval 就是一次性的 sanity check,不是质量系统。你的模型供应商随时可能在你不知道的情况下更新底层模型,如果你不持续跑 eval,可能过了两周才发现产品质量已经悄悄退步了。
Goodhart’s Law:优化 eval 分数而不是真实结果。如果你纯粹追求指标,就会 game 它。必须持续把 eval 分数跟真实结果(任务完成率、满意度、留存)绑在一起。
还有一条我自己深有体会:盲信第三方 eval 不验证。别人的 eval 就是别人的 vibes。你没亲自检查过结果,就不算你的质量标准。就像老师不能拿别人出的考卷直接给自己学生考——你的产品、你的用户、你的场景,只有你自己最清楚什么叫 “好”。
最后是 Goodhart’s Law 的隐患——当 eval 分数本身变成目标,你就会开始 game 它。解决办法是持续把 eval 分数跟真实业务指标(任务完成率、用户留存、满意度)绑在一起校准。eval 是手段,不是目的。
08 PM 的新节奏
文章最后给出了 AI PM 的每周节奏,我觉得非常值得对照执行:
周一:看线上 trace,标记 20 个不达标的响应周二:从这 20 个里提炼出 5 个新的 eval case,加进 eval suite周三:跑完整的 eval suite,对比上周模型和本周候选周四:看差异。数据说了算——发布还是不发布周五:飞轮又转快了一圈
注意这个节奏的核心:线上失败变成测试用例,测试用例驱动改进,改进产生新的线上数据。每一周都在积累护城河。不是一次性的项目,而是永远在运转的系统。
给工程团队的指令也变了。不再是一份 30 页的 PRD,而是一句话:”这是 eval。把这个数字提上去。”
这种工作方式还有一个巨大的好处:减少 PM 和工程之间的沟通损耗。传统模式下,PM 写的 PRD 跟工程师理解的 PRD 经常不是一回事,中间要开无数次对齐会议。但 eval 是代码,代码不含糊。工程师跑一遍 eval 就知道差距在哪,不需要你在旁边解释 “有帮助” 到底是什么意思。
当然了,这不是说 PM 不需要跟工程师沟通了。而是沟通的内容从 “这个需求是什么意思” 变成了 “这个 eval 应该怎么优化”。从理解问题到解决问题,效率完全不一样。
09 对我们意味着什么
这篇文章表面上是给 PM 看的,但它真正说的是一个更大的趋势:
- AI 产品的质量不是 “做出来再说”,而是 “先定义好”。在不确定的系统里,eval 是唯一的锚。你不可能 “验” 一个你没定义的东西。大多数 AI 产品的质量问题不是技术问题,是 “没人定义好什么叫好” 的问题。
- Eval 是 AI 产品的复利引擎。PRD 是一次性消耗品,写完就过期。Eval 是资产,每一轮线上数据让它变得更好。积累 eval 就是积累壁垒——你的 eval suite 越好,你对 “好” 的定义越精准,竞争对手越难追上。
- PM 的角色正在从 “写文档的人” 变成 “定义质量的人”。这个转变比很多人意识到的要深刻。传统 PM 的核心交付物是需求文档,AI PM 的核心交付物是 eval suite。不会写 eval 的 PM,在 AI 时代会越来越难。
我自己在做 AI 产品的过程中也在体会这一点。每次想 “先做出来看看效果”,最后都会后悔——改了三版不知道到底哪版好,因为没有基线。而每次先花时间想清楚 “好的输出长什么样” 并写成可测试的标准,后面的迭代就快很多。因为有了锚,你才知道往哪个方向爬。
而且 eval 还有一个隐藏价值:它是团队知识的沉淀。一个有 500 条 case 的 eval suite,记录了你过去半年遇到的所有边界情况、用户投诉和产品决策。新人加入团队,跑一遍 eval suite,就能理解 “这个产品关心什么”。这是任何 PRD 都做不到的。
如果你还在写传统 PRD 来管理 AI 产品,可以试试从一个功能开始:定义三个可衡量的信号,写你的第一个 eval。不需要很复杂,甚至可以从一个 spreadsheet 开始——列出 20 个输入 case,手动标记期望输出,跑一遍看通过率。这就是 Stage 1。
然后从那里往前走。每次线上出了一个坏 case,加进 eval suite。每次换模型、改 prompt,跑一遍 suite 看有没有退步。几个月之后,你会发现你的 eval suite 变成了你最有价值的资产——它比任何 PRD 都精确地定义了 “什么是好产品”。
PRD 会过期。Eval 会进化。
那就是这份工作现在的样子。
相关链接:
原文:https://x.com/braintrust/status/2039356267949445230
数据来源:Braintrust (@braintrust), @ornelladotcom
本文由人人都是产品经理作者【深思SenseAI】,微信公众号:【深思SenseAI】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


