
 起点课堂会员权益
起点课堂会员权益决胜“黄金数据集”:产品经理在0-1微调中的数据供应链管理指南
在AI产品领域,数据质量的重要性日益凸显。本文探讨了为何产品经理需转变为‘数据产品经理’,并提供了从数据为中心的范式转移、警惕‘垃圾进,垃圾出’的商业代价,到破局冷启动及搭建标准化数据工厂的实用策略。

一、认知重构——为什么PM要成为“数据产品经理”?
聊到AI,很多人第一反应就是模型、算法、参数量。好像只要模型够大,算力够猛,一切问题都能迎刃而解。自我从事AI产品以来,越来越觉得这个想法有点偏。尤其是在我们做具体业务落地的时候,这种“唯模型论”的思路,有时候真的会把团队带到沟里去。
说实话,现在这个阶段,基础大模型的能力越来越趋同,算力成本也在不断下降。对于绝大多数公司来说,从头训练一个千亿模型既不现实也没必要。真正的战场,已经悄悄转移了。PM的角色也必须跟着变,我们不能再只是个提需求、画原型的人了,得往深处走,成为一个懂数据的“数据产品经理”。

1.1 从 Model-Centric 到 Data-Centric 的范式转移
吴恩达(Andrew Ng)教授一直在提一个理念,叫 Data-Centric AI,以数据为中心的AI。这个提法真的说到了点子上。过去大家玩命地优化模型(Model-Centric),就像军备竞赛一样,比谁的模型参数多,结构更复杂。但吴教授的研究发现,在很多场景下,把精力花在提升数据质量上,比单纯调优模型带来的效果提升要明显得多。
这个道理其实不难懂。你可以把微调的过程想象成在“教育一个学生”。模型就是那个学生,它很聪明,学得很快。而我们喂给它的数据,就是“教材”。现在的情况是,我们手里的学生(比如Llama、Qwen这些开源模型)已经足够聪明了,智商都很高。决定他最终能考多少分的,关键在于我们给他什么样的教材,让他做什么样的练习题。
我带过一个项目,刚开始模型效果很差,答非所问。技术团队的第一反应是:“模型不行,我们换个更大的,或者加点训练轮次。” 我当时拦住了他们,我说我们先停一停,别急着烧钱。我们花了两天时间,把一小批标注好的数据拿出来,一条一条地过。结果发现,里面有将近20%的数据都有问题:指令不清晰、答案有事实错误、格式乱七八糟。我们把这100条错误数据修正过来,再用同样小的模型跑了一遍,你猜怎么着?效果提升立竿见影,比他们之前调半天参数管用多了。
所以你看,在0-1的阶段,修正100条错误数据带来的性能提升,可能远远超过你把模型参数量翻一倍。这就是ROI(投资回报率)的差别。作为PM,我们的核心职责已经变了,不再是去研究那些复杂的模型参数怎么调,而是要成为那个“编写教材大纲”的人。我们要定义,这本教材应该包含哪些知识点,例题要怎么出,练习题要覆盖哪些场景。数据的质量,直接决定了我们培养出来的“学生”的上限。

1.2 警惕“垃圾进,垃圾出”(GIGO)的商业代价
GIGO,Garbage In, Garbage Out。这是计算机科学里一个很古老的词,但在大模型时代,它的杀伤力被放大了无数倍。以前一个规则系统出错了,我们很容易定位。现在模型是个黑箱,你喂给它一堆“垃圾”,它会学得有模有样,然后一本正经地吐出更多的“垃圾”。
什么是“垃圾”数据?我觉得可以分几类:
- 模型幻觉(Hallucination): 这是最常见的,模型为了回答你的问题,开始胡编乱造。如果你的训练数据里就包含了一些似是而非、甚至是错误的信息,模型会把这些“知识”当成事实记住。
- 格式错误: 比如你要求模型输出JSON,但训练数据里的JSON格式经常缺个逗号、少个括号,那模型输出的时候也大概率会出错。这对于需要程序化解析的下游应用来说,是致命的。
- 偏见与歧视(Bias): 如果你的数据源本身就带有某种偏见,比如对某个地域、某个群体的刻板印象,模型会忠实地学习并放大这种偏见。这在产品层面会带来巨大的公关风险。
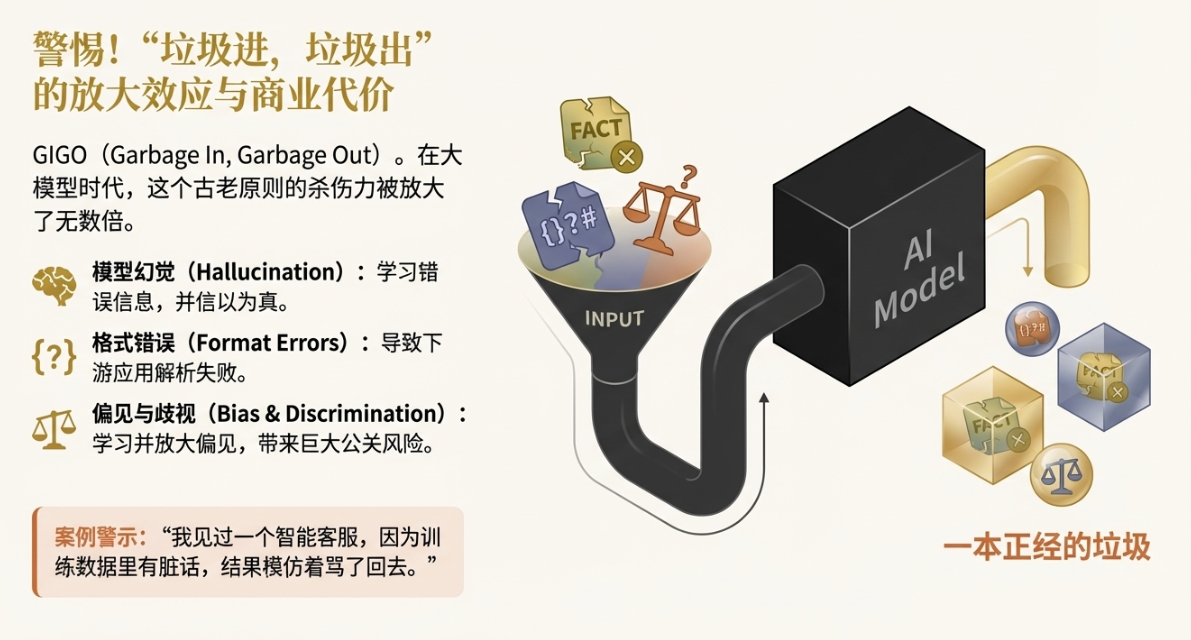
这些低质量数据导致的,就是各种各样的 Corner Case(长尾恶性案例)。可能95%的情况下模型都表现得很好,但在那5%的关键时刻,它会给你一个离谱的答案。我见过一个做智能客服的AI,因为训练数据里混入了一些用户抱怨的脏话,结果在跟一个重要客户沟通时,模仿着骂了回去。这种事听起来像个段子,但它在真实业务中,会直接转化为用户流失和品牌形象受损。
从一个产品经理最关心的 用户体验(UX) 角度来看,数据噪声对产品的破坏是深层次的。它会破坏产品的两个核心特性:
可解释性(Interpretability): 当用户得到一个奇怪的答案时,他会想“为什么”。如果连我们自己都不知道模型为什么这么说,因为它的知识来源是一堆混乱的数据,那我们怎么去跟用户解释?产品就成了一个无法预测的“盲盒”。
稳定性(Stability): 用户希望产品是可靠的。今天问一个问题是这个答案,明天问可能就变了,或者换种问法就完全胡说八道。这种不稳定性会让用户失去信任。而这种不稳定的根源,往往就是训练数据覆盖不全,或者数据之间存在矛盾。
所以,把数据质量当成产品的生命线,这绝不是一句空话。每一个PM都应该在项目开始前,反复问自己:我的数据干净吗?我的数据能代表真实的用户场景吗?如果答案是否定的,那后面的一切工作,都可能是在沙滩上盖楼。
二、破局冷启动——没有用户数据,如何开始微调?
好了,道理都懂了,数据很重要。但问题来了,对于一个从0到1的新项目,最大的痛点就是:我哪儿来的数据?特别是SFT(有监督微调)需要大量高质量的 `{Instruction, Input, Output}` 格式的数据对,这东西不会从天上掉下来。总不能等产品上线一年,攒够了用户数据再开始微调吧?那黄花菜都凉了。
这就是冷启动的困境。不过也别慌,办法总比困难多。作为PM,我们的价值就在于整合资源,创造性地解决问题。这里有几个我亲身实践过,并且觉得非常有效的策略,可以帮我们“无中生有”,搞到第一批宝贵的启动数据。

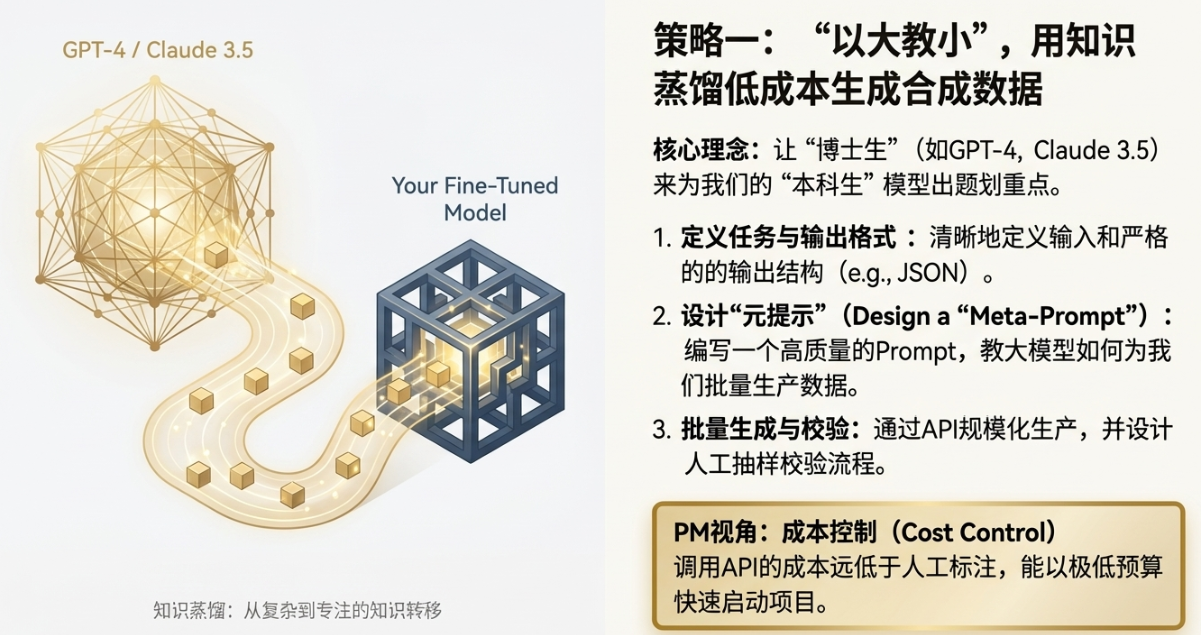
2.1 策略一:“以大教小”的知识蒸馏(Distillation)
这个策略听起来高大上,其实核心思想很简单:让一个“博士生”来给“本科生”出题、划重点。这里的“博士生”,就是指像GPT-4、Claude-3.5 Opus这些顶级的超大模型。它们见过的数据量、拥有的世界知识,远超我们能接触到的任何模型。
具体怎么做?我们可以利用这些大模型的API,通过精心设计的Prompt,来生成我们需要的“合成数据”(Synthetic Data)。这个过程就像一个PM在给一个超级聪明的实习生派活。
举个例子,假设我们要做一个面向市场分析师的AI助手,需要它能根据一份财报,总结出核心的财务亮点。我们可以这样设计流程:
1)定义任务与输出格式: 我们先明确,需要模型做什么。比如,输入是一段财报原文,输出是一个包含“营收增长”、“利润变化”、“关键风险”等字段的结构化摘要。
2)设计“元提示”(Meta-Prompt): 这是关键一步。我们要写一个Prompt,去“教”GPT-4如何为我们生产数据。这个Prompt可能会很长,里面会包含:
- 角色扮演: “你是一位顶尖的金融分析师,你的任务是为我生成用于训练AI模型的数据。”
- 任务描述: “请你阅读我提供的财报片段,然后生成一个`{instruction, input, output}`格式的数据对。”
- 格式要求: “`instruction`应该是‘请总结这份财报的核心亮点’,`input`是财报原文,`output`必须是严格的JSON格式,包含`revenue_growth`, `profit_margin`, `risks`三个字段。”
- 质量要求: “摘要必须客观、忠于原文,并且语言要专业。请生成50个不同财报的例子。”
3)批量生成与校验: 把这个Meta-Prompt和一堆财报原文通过API批量发给GPT-4,它就会源源不断地为我们生产出格式统一、质量很高的数据。当然,不能完全信任机器。PM需要设计一个“生成-校验”流程,比如随机抽取10%的数据进行人工检查,看看逻辑是否自洽,有没有事实性错误。
从PM最关心的 成本控制(Cost Control) 角度看,这个方法的优势太明显了。找一个金融分析师来手动标注一条这样的数据,可能需要几十块钱,而且耗时很长。而调用一次GPT-4 API的成本可能只要几分钱到几毛钱。即使算上一些人工校验的成本,整体效率和性价比也是碾压式的。这让我们在项目初期,能用很低的预算快速启动数据准备工作。
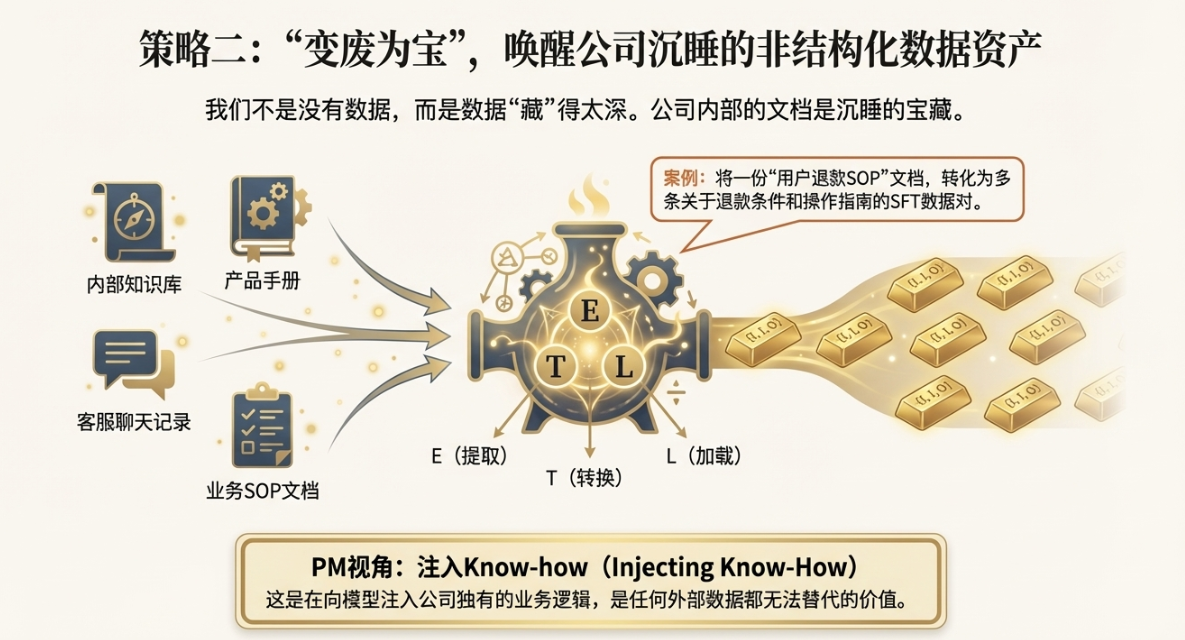
2.2 策略二:存量资产的“ETL再造”
很多时候,我们不是真的没有数据,而是数据“藏”得太深,格式不对。几乎每家公司内部,都沉淀了大量的非结构化或半结构化的文档,这些都是沉睡的宝藏。比如:
- 公司的内部知识库(Wiki、Confluence)
- 产品手册、技术文档(PDF、Word)
- 客服与客户的聊天记录
- 销售培训材料
- 业务流程的SOP(标准作业程序)文档
这些存量资产,就是我们进行“ETL再造”的原材料。ETL是数据仓库里的概念,指Extract(提取)、Transform(转换)、Load(加载)。在这里,我们可以借用这个思想,把这些五花八门的文档,转换成模型能“吃”的 `{Instruction, Input, Output}` 格式。
这恰恰是PM最擅长的能力:业务逻辑抽象。我们最懂公司的业务流程和规则。比如,我们可以把一份“用户退款SOP”文档,转化成一系列的微调数据:
原始SOP文档片段: “如果用户购买的商品在7天内出现非人为质量问题,且能提供有效凭证,则应为其办理全额退款。操作路径为:登录后台 -> 订单管理 -> 找到对应订单 -> 点击退款按钮。”
PM可以基于这段话,抽象出好几条SFT数据:
1)数据对1(规则问答):
- Instruction: “用户申请退款的条件是什么?”
- Input: “” (无)
- Output: “用户购买的商品在7天内出现非人为质量问题,并能提供有效凭证,就可以申请全额退款。”
2)数据对2(操作指南):
- Instruction: “如何为符合条件的用户办理退款?”
- Input: “” (无)
- Output: “您可以登录后台,在订单管理中找到对应订单,然后点击退款按钮来完成操作。”
你看,通过这种方式,我们把原本给“人”看的业务规则,翻译成了让“模型”也能听懂的指令集。这个过程不仅是在生产数据,更是在向模型注入公司的核心业务逻辑和Know-how。这是任何外部通用数据都无法替代的价值。作为PM,我们应该主动去挖掘这些沉睡的资产,把它们变废为宝。
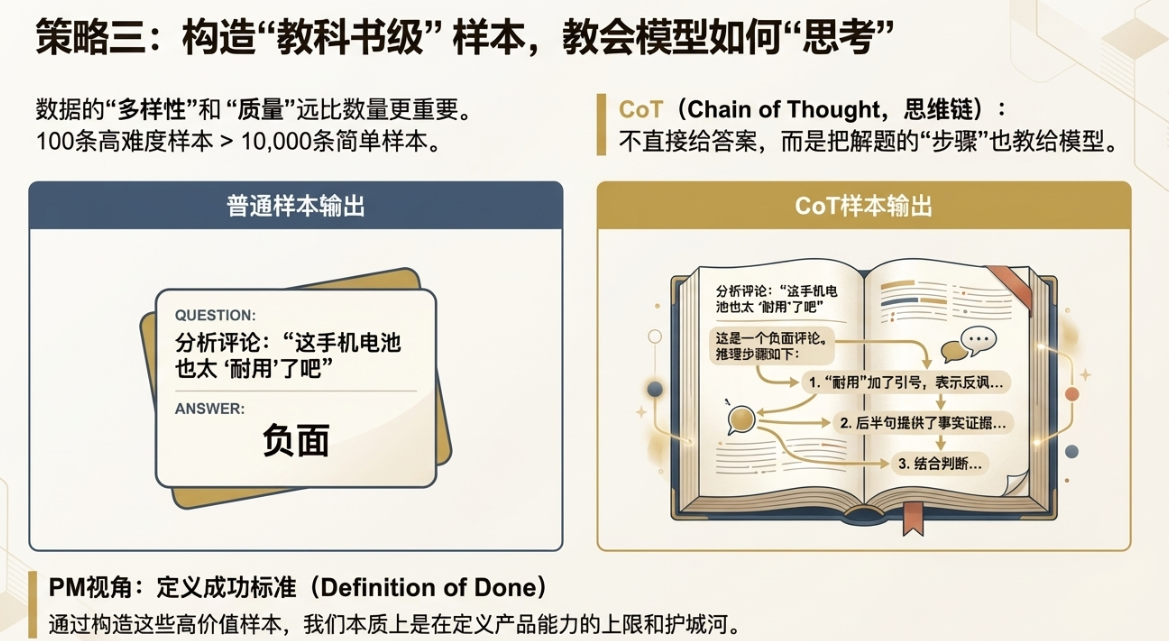
2.3 策略三:构造高难度的“教科书级”样本
在准备数据时,一个常见的误区是盲目追求数量。觉得数据越多越好。但实际上,数据的“多样性”和“质量”远比单纯的数量更重要。100条精心设计、覆盖各种边界情况的高难度样本,其价值可能超过10000条简单重复的普通样本。
我们需要为模型打造一本高质量的“教科书”,里面不仅要有基础概念题,更要有附加题和奥赛题。这些高难度样本,就是我们定义产品能力上限的关键。
一个特别重要的概念是 CoT(Chain of Thought,思维链)。简单说,就是不直接给模型答案,而是把解题的“步骤”也教给它。这样,模型就不是在死记硬背,而是在学习如何“思考”和“推理”。
假设我们要做一个分析用户评论情感的AI。对于一条评论:“这手机电池也太‘耐用’了吧,我出门吃个饭就没了。”
1)普通样本(非CoT):
- Instruction: “分析这条评论的情感。”
- Input: “这手机电池也太‘耐用’了吧,我出门吃个饭就没了。”
- Output: “负面”
2)教科书级样本(CoT):
- Instruction: “分析这条评论的情感,并给出推理过程。”
- Input: “这手机电池也太‘耐用’了吧,我出门吃个饭就没了。”
- Output: “这是一个负面评论。推理步骤如下:1. 用户提到了‘耐用’,但这个词加上了引号,这通常表示反讽。2. 后半句‘我出门吃个饭就没了’提供了具体的场景,说明电池续航时间非常短。3. 结合反讽的语气和具体事实,可以判断用户是在抱怨电池不耐用,因此情感是负面的。”
看到了吗?CoT样本让模型学会了如何处理反讽、如何结合上下文进行判断。当它再遇到类似的复杂评论时,就能举一反三,而不是简单地因为看到“耐用”两个字就判断为正面。
从PM的视角看,构造这些高价值样本,本质上是在 定义成功标准(Definition of Done)。我们需要深入业务,识别出那些最核心、最复杂、最容易出错的场景。比如,金融风控里的模糊欺诈意图识别、医疗问答里的复杂因果关系判断、法律咨询里的多条款应用分析等等。针对这些场景,PM要亲自下场,甚至组织专家团队,去构造一批“教科书级”的样本。这些样本,就是我们为产品打造的“护城河”。
三、搭建流水线——构建标准化数据工厂(SOP)
通过第二章的方法,我们解决了从0到1的冷启动问题,手里有了一批原始数据。但这只是第一步。这些数据来源各异,质量参差不齐,就像刚从地里挖出来的矿石,里面混着大量的泥沙和杂质。如果直接把这些“原矿”扔进模型这个“熔炉”里,炼出来的很可能是“废铁”。
所以,我们需要一个标准化的处理流程,把数据处理从“手工作坊”模式,升级为可复制、可管理的“工业流水线”。我喜欢称之为“数据工厂”。这个工厂的目标很明确:持续、稳定地生产出高质量、符合规范的“精矿”——也就是最终用于训练的数据集。
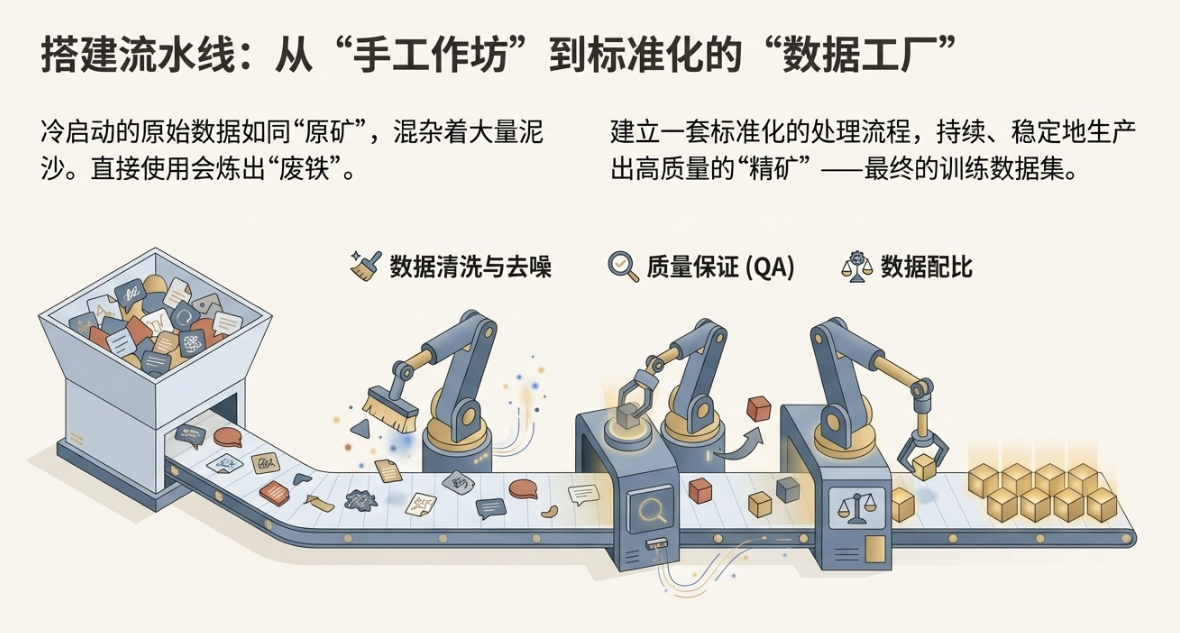
3.1 清洗与去噪:建立QA(质量保证)机制
数据清洗,是数据工厂里最重要,也是最繁琐的一道工序。就像做菜前要洗菜、摘菜一样,这个步骤决定了最终菜品的口感和安全。在数据处理中,清洗和去噪的标准动作通常包括:
- 数据去重: 同样的数据重复出现,会让模型对某些模式产生“过拟合”,降低泛化能力。我们需要用算法(比如计算文本的哈希值)来剔除重复或高度相似的数据。
- PII去除: PII(Personally Identifiable Information),也就是个人敏感信息,比如姓名、身份证号、手机号、家庭住址等。在训练数据中保留这些信息,既有隐私泄露的巨大风险,也可能让模型在生成内容时“泄露”这些信息。我们需要用规则或模型来识别并脱敏这些信息,比如替换成`[NAME]`、`[PHONE]`这样的占位符。
- 长度截断与过滤: 太长或太短的数据都可能是噪声。比如,一个问题只有一个字,或者一个回答有几万字,这些通常都是无效数据,需要设定一个合理的长度阈值进行过滤。
- 格式校验: 尤其是对于需要输出特定格式(如JSON、Markdown)的任务,必须严格校验训练数据中的Output格式是否正确。一个脚本就能搞定,确保括号匹配、逗号无误。
这些动作听起来像是技术活,但从PM的视角看,我们的核心工作是 制定验收标准。我们要像写PRD(产品需求文档)一样,去撰写一份极其严谨的 数据标注规范(Annotation Guideline)。这份规范就是数据工厂的“质量管理体系文件”,它需要明确地告诉所有参与数据处理的人(无论是标注员还是算法),什么是好的数据,什么是不好的数据。

这份规范可能要细致到什么程度?举个例子,在定义“什么是不能说的”时,我们不能只写一句“不要包含攻击性言论”。而是要具体定义:
- 哪些词汇属于人身攻击?
- 对历史事件的评论边界在哪里?
- 什么样的玩笑属于不适宜的?
- 当用户的问题本身就带有恶意时,模型应该如何回应?是拒绝回答,还是温和地引导?
这份规范,就是我们为模型设定的“价值观”和“行为准则”。PM必须主导这件事,因为这直接关系到最终产品的性格和安全底线。一个没有严格QA机制的数据工厂,生产规模越大,带来的灾难可能也越大。
3.2 数据配比的艺术:通用能力与专业能力的平衡
当我们专注于垂直领域微调时,很容易陷入一个误区:只用我们自己的专业数据去训练。比如做法律AI,就只喂法律条文和案例。这样做会导致一个严重的问题,叫做 “灾难性遗忘”(Catastrophic Forgetting)。
什么意思呢?就是模型在学习新知识(比如法律)的过程中,会把它原来掌握的通用知识(比如日常对话、文史知识)给忘了。最后你得到的,可能是一个只会背法条、但连“今天天气怎么样”都答不好的“书呆子”。这样的产品,用户体验会非常差,感觉很“傻”,不智能。
所以,数据配比是一门艺术,我们需要在通用能力和专业能力之间找到一个精妙的平衡。这就像我们招聘一个岗位专家,我们既要考核他的专业技能,也要看他的沟通能力、团队协作等通用素质。
在实践中,我们通常会采用 混合训练(Mixture Training) 的策略。具体来说,就是在我们的垂直领域数据中,掺入一定比例的通用语料。这个比例没有一个放之四海而皆准的答案,需要根据具体业务来定。
从PM的视角,这是一个典型的 用户体验权衡 问题。我们需要通过实验,特别是 A/B测试,来找到那个最佳的数据配比。比如,我们可以尝试几个不同版本的模型:
- 版本A(纯专才): 100% 垂直领域数据。
- 版本B(T型人才): 80% 垂直领域数据 + 20% 通用对话数据。
- 版本C(均衡人才): 60% 垂直领域数据 + 40% 通用对话数据。
然后,我们可以设计一个评估集,里面既有专业的业务问题,也有日常的闲聊问题。让一小部分真实用户或者内部测试人员来使用这几个版本的模型,收集他们的反馈。哪个版本既能专业地解决问题,又能自然地进行交流,哪个版本就是我们想要的。
我个人的经验是,对于大多数应用,一个类似 80%垂类 + 20%通用 的配比是一个不错的起点。这能确保模型在专业性上足够强,同时不至于丧失基本的对话能力。但重点是,PM必须要有这个“数据配比”的意识,把它当成一个产品决策,通过数据和用户反馈来驱动,而不是凭感觉拍脑袋。

四、闭环进化——Human-in-the-loop(人在回路)的数据飞轮
到这里,我们已经有了一个能生产高质量数据的工厂,也训练出了第一个版本的模型。很多团队可能觉得大功告成了。但我想说,这恰恰只是个开始。微调,绝对不是一个一次性的工程,它应该是一个持续迭代、不断进化的过程。一个真正有生命力的AI产品,必须建立起一个能够自我完善的闭环系统。
这个闭环的核心,就是 Human-in-the-loop(人在回路),把“人”的智慧和反馈,源源不断地注入到数据供应链中,形成一个正向循环的“数据飞轮”。

4.1 产品侧埋点与反馈机制设计
数据飞轮的第一推动力,来自我们的最终用户。用户在使用产品过程中的每一次交互,都是在用脚投票,告诉我们模型哪里做得好,哪里做得不好。这些信号,是比任何人工标注都更真实、更宝贵的养料。
关键在于,我们如何设计产品,来“无感”地收集这些偏好数据?这考验的是PM的产品设计功力。一些常见的、有效的设计包括:
- 点赞/点踩(Thumbs Up/Down): 这是最直接的反馈机制。用户对模型的回答点赞,说明这是一条高质量的Positive Sample;点踩,说明这是一条Bad Case,需要我们重点分析。
- 修改重发(Edit & Resubmit): 当用户对模型的回答不满意,并自己动手修改后重新提交时,这个行为的价值极高。用户的修改版,就是一个完美的、符合他真实意图的Output。这为我们提供了高质量的修正数据。
- 一键复制/分享: 如果用户选择复制或分享模型的回答,这通常是一个强烈的积极信号,说明这个回答对他很有用。
- 追问与澄清: 如果用户在得到回答后,继续追问“你说的是什么意思?”或者“能说得更具体一点吗?”,这往往意味着模型的回答不够清晰或完整。这些对话本身,就是很好的负样本。
从PM的视角,我们需要绘制一幅产品的 用户旅程地图(User Journey Map)。在这幅地图上,我们需要仔细审视用户与AI交互的每一个环节,思考在哪些节点,用户最有可能产生满意或不满的情绪。然后,在这些关键节点上,巧妙地植入我们的数据收集机制。
比如,在一个生成营销文案的AI产品中,当用户反复点击“重新生成”按钮时,系统可以主动弹出一个小窗口:“您是对哪方面不满意呢?A. 风格太死板 B. 长度不合适 C. 卖点不突出”。用户的这个选择,就为我们下一次迭代指明了方向。
通过这种方式,我们把每一个Bad Case,都转化成了一次优化产品的机会,一次获取优质数据资产的机会。这就是RLHF(基于人类反馈的强化学习)思想在产品设计上的体现。我们不是在被动地等待用户投诉,而是在主动地、结构化地收集他们的隐性反馈。

4.2 持续集成与版本管理
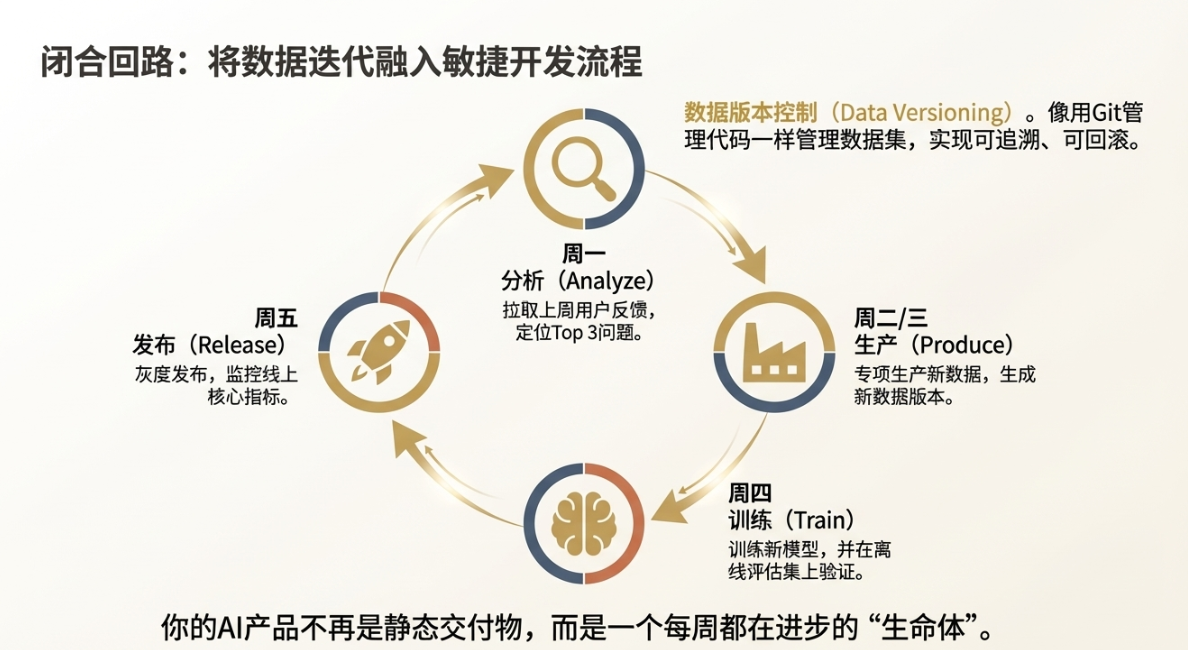
收集到了反馈数据,飞轮转动了半圈。接下来是关键的后半圈:如何把这些新数据用起来,让模型真正实现“进化”?这就需要我们在工程上建立起一套敏捷的迭代机制。
一个核心实践,是建立 数据版本控制(Data Versioning)。这和我们管理代码用Git一样,我们的数据集也需要有版本。为什么这很重要?
- 可追溯性与归因: 当新版模型上线后,效果突然变差了,我们需要能快速定位问题。如果数据没有版本管理,我们就很难知道是哪一批新加入的数据“污染”了模型。有了版本控制,我们可以清晰地看到 `模型V1.1` 是由 `数据集V1.1` 训练的,而 `数据集V1.1` = `数据集V1.0` + `本周新增的1000条用户反馈数据`。这样排查问题就有了依据。
- 可回滚性: 如果发现新版模型有严重问题,我们可以立刻回滚到上一个稳定的版本。同时,数据也可以回滚到上一个版本,进行重新清洗和分析。
有了数据版本控制,我们就可以把AI的迭代,真正融入到团队的 敏捷开发(Agile) 流程中。作为PM,我们可以将“数据更新”作为一个常规任务,纳入到每个Sprint(迭代周期)的规划里。
一个典型的敏捷数据迭代流程可能是这样的:
- 周一(数据收集与分析): 自动脚本拉取上一周所有用户反馈数据(点踩、修改等),PM和数据分析师一起对这些Bad Case进行归类,找出Top 3的典型问题。
- 周二、周三(数据生产与清洗): 针对这Top 3问题,数据团队专项生产一批新的SFT数据或偏好数据,并合入主数据集,生成一个新的数据版本(如 `Dataset_v2.3`)。
- 周四(模型训练与评估): 算法工程师使用新的数据集,重新训练一个轻量的LoRA权重,并在离线评估集上验证效果。
- 周五(模型发布与监控): 评估通过后,将新模型灰度发布给一小部分用户,PM密切监控线上核心指标,确认无负向影响后,再全量推送。
你看,通过这样一套流程,我们的AI产品就不再是一个静态的交付物,而是一个能听、能看、能学习、每周都在进步的“生命体”。数据飞轮就这样被驱动起来,越转越快,产品的护城河也越来越深。
数据的长期主义
聊到这里,我想表达的核心观点其实很简单。在AI这个日新月异的领域,我们很容易被各种新模型、新框架晃得眼花缭乱,产生所谓的“技术焦虑”。今天追这个模型,明天学那个框架,生怕自己落伍了。
但我们不妨静下来想一想,什么东西是真正有长期价值的?模型架构会过时,三年前的SOTA(State-of-the-art)模型,今天可能无人问津。训练框架会更新,TensorFlow和PyTorch的战争还未结束,新的挑战者就已出现。算力会越来越便宜,就像水电煤一样,成为基础设施。
唯一不会轻易过时,并且会随着时间推移不断增值的,是什么?
是我们经过真实业务场景反复打磨、不断清洗和迭代、沉淀了行业深度Know-how的私有数据集。
这个“黄金数据集”,是竞争对手用钱也买不来的。它记录了你的用户最真实的需求,包含了你所在行业最独特的逻辑,体现了你的产品最核心的价值观。它才是企业在AI时代,那条最深、最宽、无法被轻易复制的核心护城河。构建和维护好这个数据集,是一件需要耐心和坚持的“难而正确的事”。这,就是数据的长期主义。

行动建议
建议每一位有志于在AI领域深耕的产品经理,从今天开始,停止对模型参数大小的过度焦虑,把目光收回到数据本身。去着手建立起属于你的第一条“数据流水线”,哪怕它最初很简陋。因为当你开始拥有、管理并迭代自己的数据集时,你才真正拥有了定义和塑造未来AI产品的权力。

本文由 @大叔拯救世界 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


