
 起点课堂会员权益
起点课堂会员权益金三银四求职刚需:我用Coze搭求职台账Agent,却被反爬狠狠上了一课
金三银四求职旺季,海量岗位信息整理成了求职者的共性痛点,我本想借助Coze快速搭建一款粘贴岗位链接即可自动整理入库的AI求职台账Agent,实现全流程零手动操作。但实际落地时,却被招聘平台强反爬、平台限制、大模型能力边界等问题接连阻拦,全自动方案无法落地。

金三银四求职旺季,无论是应届生海投还是职场人跳槽,都会面临同一个效率难题:每天浏览多个招聘平台的岗位,想要整理成规范的求职台账,手动复制公司、岗位、薪资、职责、地址等信息,动辄花费十几分钟,不同岗位的信息字段叫法不一(例如岗位职责有工作职责、任职资格等各种叫法),还要手动对齐,久而久之台账混乱,后续复盘对比也毫无章法。
依托当下低代码AI平台的能力,打造一款轻量级全自动的求职台账助手Agent,能快速解决这些问题——无需复杂开发,快速实现岗位信息自动抓取、结构化提取、一键录入多维表格,彻底解放双手。但在实际落地过程中,看似简单的全流程自动化,却藏着诸多易被忽视的壁垒,全自动方案从一开始就陷入困局,全程实战踩坑经验,对所有低代码AI工具开发者都具有参考价值。
一、需求与理想方案:全自动求职台账Agent设计
结合求职场景的核心痛点,这款AI Agent的核心需求十分明确:用户仅需粘贴招聘岗位链接,Agent自动完成网页内容抓取、字段提取、格式标准化,最终一键写入飞书多维表格,全程无额外操作。
选用Coze平台,依托平台内置能力快速搭建,核心模块与流程如下:
- 输入层:开始节点,支持用户输入招聘链接(URL)
- 抓取层:链接读取插件,自动获取招聘网页正文内容
- 处理层:大模型节点,完成信息提取、同义字段合并、格式标准化
- 输出层:飞书多维表格API节点,自动新增记录、写入台账
理想全流程:开始(URL输入)→ 网页自动抓取 → 大模型结构化处理 → 飞书自动写入 → 结束

这套方案看似闭环,完全贴合轻量化、全自动的产品目标,可实际试运行后,却发现全流程根本跑不通。
二、全自动方案落地:三大致命障碍,理想彻底碰壁
在Coze平台搭建完成后,多次试运行均显示“运行成功”,但飞书表格始终无新数据写入,深挖问题根源,发现并非流程搭建失误,而是外部反爬机制、低代码平台限制、大模型能力边界三大客观壁垒,直接堵死了全自动路径。
招聘平台强反爬策略,直接拦截爬虫请求
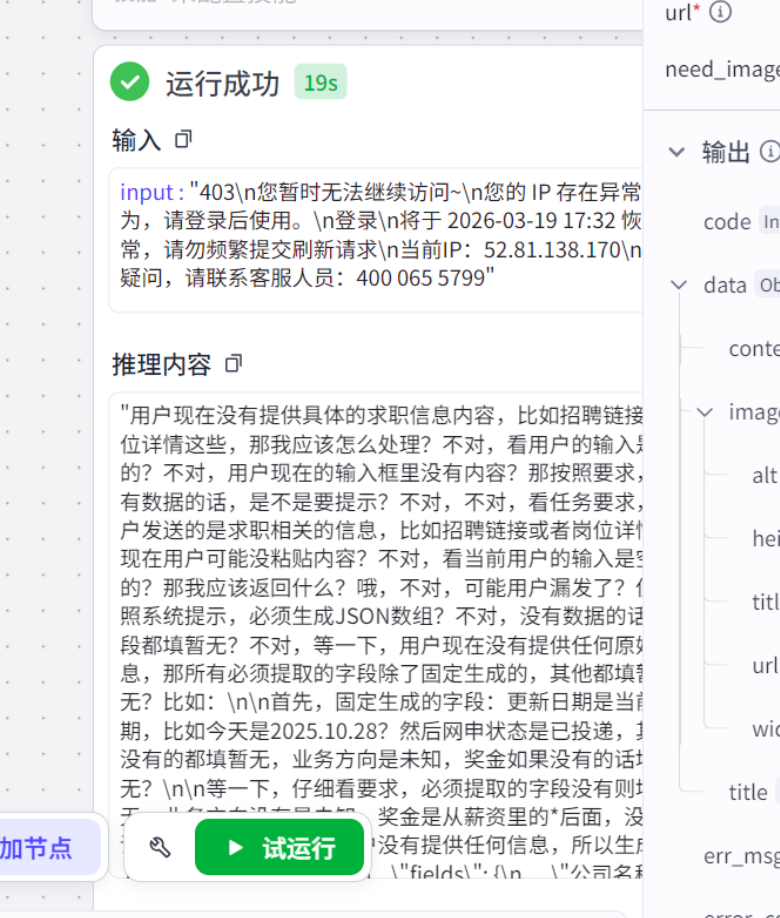
BOSS直聘、猎聘、智联等主流招聘平台,将岗位信息视为核心商业资产,反爬机制远比公开内容平台严格,普通链接读取插件根本无法突破:
- IP异常检测:识别非浏览器访问的爬虫IP,直接返回403报错,提示“IP异常,请登录后使用”
- 强制登录校验:未登录账号无法查看完整岗位详情,仅展示部分简介,抓取内容无效
- 人机行为识别:通过鼠标滑动、点击频率、访问轨迹判断是否为机器操作,拦截脚本访问
- 动态JS渲染:岗位正文通过JS加密渲染,普通静态抓取无法获取真实内容,返回空数据
而公众号文章、新闻网页等内容可轻松抓取,核心原因是公开内容平台鼓励传播,反爬策略极弱,而招聘平台封闭保护核心数据,全力拦截爬虫,二者底层逻辑天差地别。
低代码平台安全边界,无法突破抓取限制
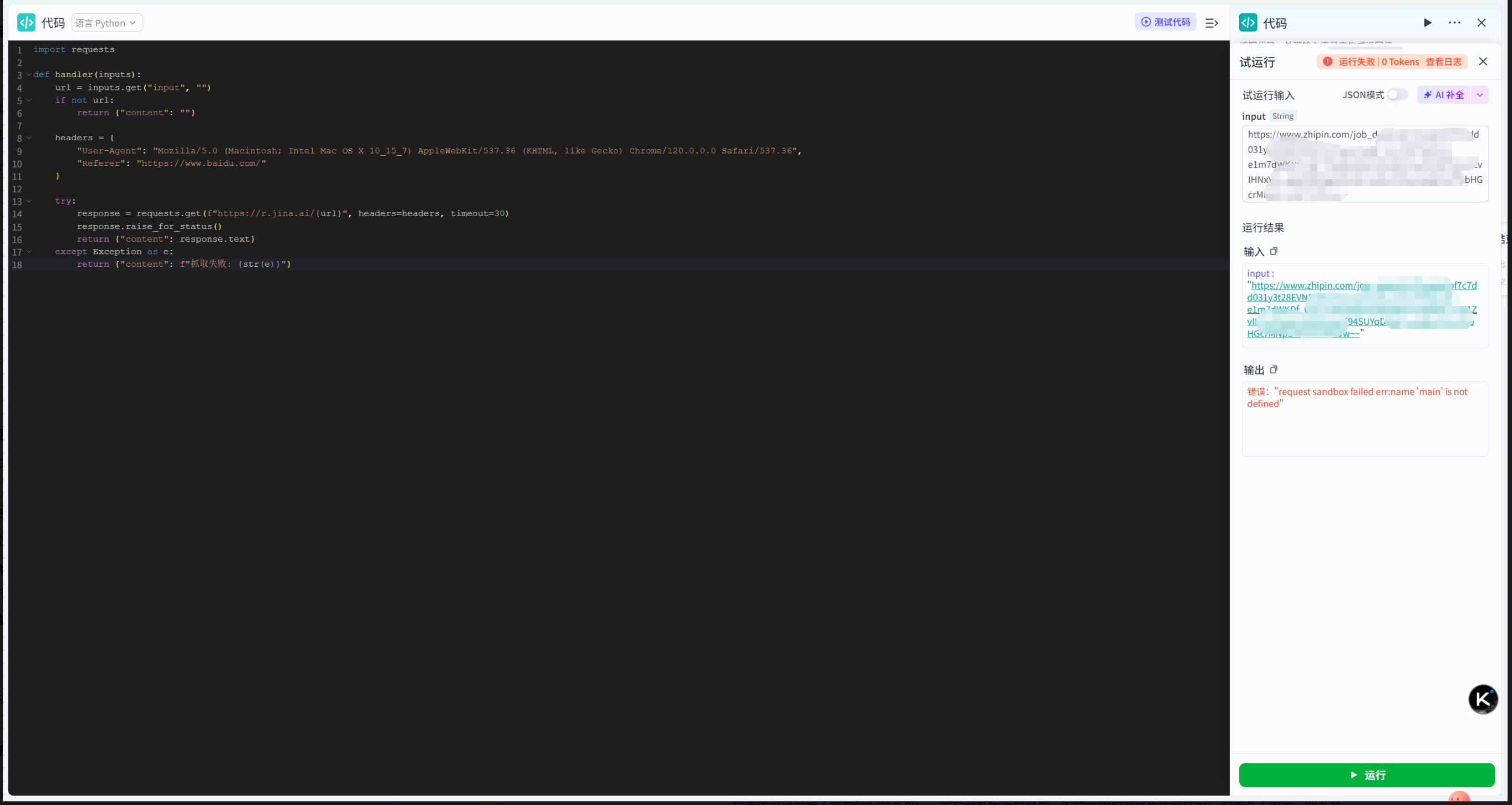
为绕过插件抓取失败的问题,尝试通过代码节点自定义编写抓取脚本,却发现Coze等低代码平台出于安全合规考量,设有明确的能力边界,根本无法实现自主爬虫:
- 沙箱环境隔离,不支持requests等网络请求库,代码直接运行报错
- 禁止调用第三方网页解析API,无法借助外部服务突破反爬
- 无内置RPA机器人能力,无法模拟浏览器、登录、点击等人工操作
- 不支持Playwright、Selenium等自动化工具,无法实现浏览器仿真访问
简单来说,低代码平台的核心定位是快速搭建AI应用与工作流,而非爬虫或自动化脚本运行环境,在平台内无法突破招聘平台的反爬限制。
大模型能力边界:无主动访问网页的权限
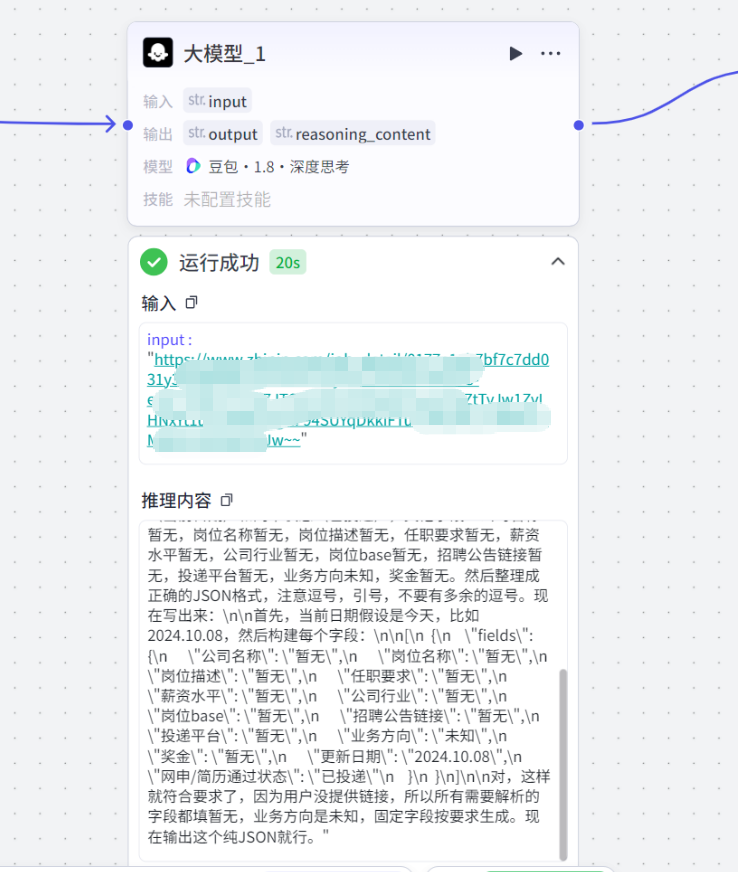
很多人(包括我)会陷入一个误区:在大模型提示词中加入“自动解析链接”指令,就能让模型主动读取网页内容。但实际情况是,大模型本身没有主动访问互联网、抓取网页的权限,仅能处理用户输入的现有文本数据。
所谓的“大模型链接解析”,仅适用于平台提前缓存的公开页面(如公众号、通用新闻),针对需要登录、强反爬的招聘页面完全无效,这也是试运行显示成功、但无数据写入的核心原因。
三、核心困境:全自动方案彻底碰壁,无有效绕路方式
尝试过多重补救方案,依旧无法突破全自动落地的壁垒:更换链接读取插件、调整大模型提示词、尝试代码节点自定义请求,均以失败告终。归根结底,招聘平台的反爬底线、低代码平台的安全规则、大模型的能力边界,三者共同堵死了Coze平台内实现全自动抓取的路径,没有任何轻量化、无部署的方式能在现有框架下突破。
对于求职者而言,这款Agent的核心价值本就是彻底摆脱手动操作,实现“丢链接即入库”的零负担体验,一旦需要用户手动复制粘贴文本,就违背了打造AI助手的初衷。求职者的痛点本就是“不想复制粘贴、不想触碰任何繁琐操作”,半自动的形式本质上只是减少了部分整理成本,并没有解决“不想手动操作”的核心诉求,对于个人求职场景来说,实用性大打折扣,完全达不到预期的工具价值。
四、全自动方案不可行的深层原因复盘
这场实战并非流程设计失误,而是底层规则和场景属性决定了全自动路径不通,核心根源可总结为三点,也是所有低代码AI自动化工具都会面临的共性壁垒:
商业数据与公开内容的本质差异
招聘岗位信息属于平台核心商业资产,平台靠此类信息盈利,必然会用最强反爬手段拦截一切非人工访问。而公众号、新闻等内容属于公开传播属性,平台鼓励抓取和分发,反爬几乎为零。二者的底层定位不同,决定了抓取难度天差地别,不能用公开内容的抓取逻辑,套用商业数据场景。
低代码平台的合规性红线
Coze等低代码AI平台面向大众用户,必须严守网络安全与合规底线,全面禁止违规爬虫、浏览器模拟、IP穿透等操作,这是平台生存的核心底线。低代码的“低门槛”“轻量化”定位,本身就和“突破反爬”“自动化爬虫”存在天然矛盾,平台不可能为了单个垂直工具场景,放开合规限制,承担违规风险。
大模型的能力天花板
大模型本质是文本处理模型,而非专业网络爬虫工具,本身没有主动访问互联网、突破登录校验、获取动态加密内容的能力。所谓的“大模型自动解析链接”,只是产品层面的理想化设想,仅能适配平台提前缓存的公开页面,对于招聘平台这类强反爬、需登录的页面完全无效,大模型永远无法替代专业爬虫和RPA工具,更无法突破外部平台的风控策略。
五、此次实战启示
这次全自动方案的落地失败,给我带来了极强的警示,尤其针对垂直场景的轻量化工具开发。
垂直刚需场景,别盲目迷信低代码全能化
低代码平台适合标准化、无风控、公开数据的AI应用搭建,比如文本总结、格式转换、信息分类等。一旦涉及强反爬、需登录、商业数据类的垂直刚需场景,低代码的能力边界极为明显,前期一定要做好场景调研,避免投入时间后全盘落空。
AI工具的核心价值,在于解决核心痛点
求职台账Agent的核心痛点,是求职者彻底摆脱手动操作,实现“丢链接即入库”的零负担体验,如果无法实现这一点,工具的存在意义就大幅降低。做AI工具不能退而求其次,更不能为了强行落地而妥协核心需求,要么找到可行的全自动路径,要么坦然承认场景局限性,绝不能用“半自动也能用”弱化求职者的核心诉求。
技术选型要匹配场景,而非跟风用低代码
如果执意要打造全自动求职记录工具,低代码平台绝非合适选型,不能因为低代码开发速度快、门槛低,就忽视场景的技术要求,永远是场景决定技术,而非技术决定场景。垂直刚需场景的技术选型,必须先考量场景壁垒,再匹配对应能力的技术方案。
六、无奈备选:仅作为临时过渡的半自动化形式
如果短期内没有条件搭建专业自动化服务,又想借助AI减少部分整理负担,半自动化仅能作为临时、无奈的过渡方案,绝非最优解,更不适合作为长期使用的工具形态。
半自动化仅需简单调整流程:放弃链接抓取环节,改为用户手动复制岗位文本粘贴输入,由大模型完成后续信息提取和入库操作,全程仍需用户手动参与,只是省去了字段对齐和手动填表的步骤,并没有实现求职者想要的“全自动”效果,仅能勉强降低部分劳动成本。
其流程仅为临时适配:开始(文本粘贴输入)→ 大模型提取与标准化 → 飞书API写入 → 结束,不推荐作为正式工具方案使用。
七、真正实现全自动的可行路径(需跳出低代码)
如果想要打造真正满足求职者核心需求、实现“丢链接即入库”的全自动求职台账Agent,必须彻底跳出低代码平台的限制,走专业的自动化开发路线,放弃轻量化低代码方案。
例如采用Python+Playwright/Selenium,搭建专属浏览器自动化服务,模拟真人真实操作,绕过招聘平台反爬和风控,将抓取到的内容传输给大模型做结构化处理,再调用飞书API完成自动入库。
但该方案需要独立服务器部署、具备一定开发能力、还要处理IP风控、账号登录等问题,个人开发者需权衡时间和技术成本,对于只想轻量化使用工具的求职者来说门槛较高,短期内难以实现。
八、总结
低代码平台目前做不了强反爬场景的全自动AI工具,求职台账Agent的全自动需求,和低代码的能力边界存在不可调和的矛盾。不要盲目理想化设计,更不要为了落地而妥协成半自动形式,毕竟求职者要的是彻底解放双手,而非多一步手动复制粘贴。
本文由 @飞上天的狗 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Pixabay,基于CC0协议






- 目前还没评论,等你发挥!


