
 起点课堂会员权益
起点课堂会员权益产品复盘三大归因陷阱:裸差、辛普森悖论、幸存者偏差
裸差、A/B测试盲区、因果推断方法——产品复盘中的三大陷阱与破解之道。本文将深入剖析为何简单的数据对比会误导决策,揭示A/B测试在网络效应场景下的局限性,并手把手教你用PSM与DiD方法在历史数据中还原真相。当AI让数据分析门槛降低时,这些底层思维框架比算法更重要。

在做产品复盘时,你一定这么干过:一个功能上线两周,留存涨了三个百分点。你把这三个点写进PPT,标题是《XX功能成效复盘》。
没人会质疑这个数字,它真实存在。
但它衡量的是:效果 = 上线后 − 上线前。这个减法背后藏着一个几乎没人挑明的假设,这两周里,世界上唯一变了的,只有你的功能。
大盘没动,没有大促,没有新一轮投放,进来的用户和上个月还是同一批人。
上述任何一条不成立,那三个百分点里就混进了本不属于你的功劳。
这个没扣掉任何外部变化的差值,本文称之为裸差。
复盘里最贵的错误,就是把裸差当作效果。
接下来,我想讲清楚三件事:裸差为什么骗人,A/B测试为什么也不总能救你,以及当你只有历史数据时,怎么用因果推断逼近真相,同时避免被一个看起来很科学的结论误导。
一、裸差:复盘里的伪因果
先把公式拆开看。
效果 = 上线后 − 上线前。
它成立的前提是:这段时间内唯一的变量就是你的功能。可现实中的产品环境,从来不是一间真空实验室,而是一条同时被几十只手推动的河。
留存上涨的那两周,也许恰好是行业旺季。也许市场部刚启动了一轮投放,进来一批天然更精准的用户。也许上个版本修复了一个严重崩溃,整体用户体验本就抬了一截。也许什么都没发生,只是上上周的数字偶然偏低,这周回到了正常水位。
这些变化都与你的功能无关,但它们全都涌入了「上线后」那个数字。
裸差的危险,不在于减法算错了,减法本身没错。危险在于,它把一段时间内所有正面变化,都默记在了你这一个功能头上。大盘、季节、投放、用户画像漂移,这些本该被剔除的因素,全被打包成了功能的成绩单。
这就是伪因果。两件事先后发生,看起来像前者导致了后者,可「先后」从来不等于「因果」。
公鸡打鸣在日出之前,但没人说是公鸡叫醒了太阳。可一旦换成产品指标,这个错误就变得无比隐蔽,因为数字是真的,图表是涨的,故事是顺的。
一个真实、能写进PPT、却完全站不住脚的结论,比一个明显的错误危险得多。
所以复盘的第一步,不是急着算「涨了多少」,而是先问:这段时间里,除了我的功能,还有什么是动的?
问出这个问题,你才算从裸差里走出来了一步。
二、三类归因陷阱:混淆变量、辛普森悖论、幸存者偏差
裸差只是伪因果最粗糙的一种,它错在时间维度:把上线前后的差,当成功能的差。下面这类更隐蔽,错在人群维度,相关性本身就长着一张因果的脸。
这里有三种最常见的伪装,每一种都能让一份看似严谨的复盘,得出恰恰相反的结论。
第一种,混淆变量。
指有第三个因素,同时影响着你所关注的两端。
一个经典例子:你上线了一个新功能,发现用过它的用户,留存明显高于没用过的。结论呼之欲出:功能提升了留存。
但先停一下。谁会主动去用新功能?大概率是那些本来就高频、本来就活跃、本来就离不开你产品的人。高活跃用户天生留存就高,跟这个功能没关系。「活跃度」才是躲在背后的第三只手,它同时推高了「使用新功能的概率」和「留存」。
你看到的不是功能在起作用,而是高活跃用户的自我筛选。功能只是搭了个顺风车。
第二种,辛普森悖论。
它更反直觉:分组看和合并看,结论可以完全相反。
设想一次改版,你想评估它对转化率的影响。合并所有用户看,新版转化率更低,于是你判定改版失败。
可一旦把用户拆成新客和老客分别看,新版在新客中转化更高,在老客中也更高。两个分组都赢了,合在一起却输了。
为什么?因为新版上线后,用户结构变了:这批用户里新客比例大幅上升,而新客的转化天然低于老客。是用户画像构成的变化拉低了整体数字,而非改版本身变差了。
辛普森悖论的杀伤力在于,合并与分组这两个口径,单独看都「没错」,但指向截然相反的行动。你是该回滚还是该加码,取决于你有没有把人群拆开来看。
第三种,幸存者偏差。
指的是你手上的样本,已经经过了某种筛选。
我们就栽过一次。做一个新功能时,用户天天在群里骂「太难用了」,我们当真了,连夜加班改交互。上线后日活跌了20%。复盘才发现:在群里骂的人只占1%,剩下99%的沉默用户,早就用熟了旧版的路径,新版反而让他们集体懵了。我们听见的是最吵的那1%,照着他们改,结果把沉默的99%推走了。
这就是幸存者偏差最常见的形态:会发声的样本,从来不等于全部样本。反过来也一样,好评同样会骗你。你翻遍评论区、问卷、客服记录,发现对新版的评价整体偏正面,于是松了口气。可那些用了一次就卸载、默默流失的用户,已经不会再给你任何反馈了。留下来说话的,本就是相对认可你的那批人。
幸存者偏差不会篡改你看到的数据,它只是悄悄拿走了一部分本应出现的数据。不管拿走的是沉默的不满,还是沉默的流失,你以为自己在看全貌,其实只看到了发声者的面孔。
这三种误判有一个共同点:数据都是真的,逻辑链条看起来也通,但结论是反的。它们之所以危险,恰恰是因为它们足够真实、足够顺滑、足够说服一屋子人。
三、A/B测试的盲区:SUTVA与网络效应
说到这里,懂行的人会讲:这些问题,A/B测试不就解决了么。
很大程度上,对。
A/B测试的厉害之处,在于它用随机分组,把上述混淆变量、画像差异、自我筛选,一次性、平均地分配到实验组和对照组两边。
两组用户除了「是否用到新功能」这一个差别,其余在统计上基本一致。这时两组的指标差,才干净地等于功能的效果。随机化,是迄今为止人类对付伪因果最强的手段。
但A/B有一个前提,平时藏得很深,叫SUTVA——稳定单元处理值假设。
翻译成人话,核心只有一句:每个用户受到的影响,只取决于他自己被分到哪一组,跟别人被分到哪一组无关。实验组与对照组之间,必须彼此独立,互不干扰。
大多数时候这个假设成立。我看不看到一个新的按钮颜色,不影响你看不看得到。
可一旦你的产品涉及网络效应、双边市场或社交传播,这个假设就会被悄悄打破。
打车App是最清晰的例子。
你给实验组的乘客上线了一个新的派单策略,让他们更容易叫到车。听起来是个标准A/B。但乘客和司机共享的是同一个运力池。实验组乘客多抢走了几辆车,对照组乘客能叫到的车就变少了。你的实验非但没让两组独立,反而让实验组直接踩着对照组得分。这时你测出的差值是被放大的、虚高的,因为对照组的体验是被你的实验亲手拉低的。
在IM产品里更隐蔽。
你给实验组上线了一个新的互动玩法,实验组用户兴高采烈,跑去跟好友互动。而那些好友,有一半在对照组里。对照组明明没拿到新功能,却因为收到实验组发来的消息,活跃度也跟着涨了。两组的差值被抹平,你的功能看起来「没效果」,但它的效果其实通过社交关系泄漏到了对照组。
网络效应、双边市场、社交传播。这三个词只要出现在你的产品里,A/B的独立性前提就值得你停下来仔细检查。SUTVA一旦被打破,随机化这把好刀,也会切出一个错误的数字。
A/B不是万能的。它是一把好刀,但有自己的锋利不到的地方。
四、因果推断补位:PSM与DiD怎么做事后归因
A/B还有一个更朴素的局限:它要求你提前设计。
你得在功能上线之前,就划分好实验组和对照组,定好指标,留好放量节奏。
可现实中有太多场景没有这个「提前量」:功能已经全量上线,你没留对照组;这是一次公司级的大改版,无法只给一半人;或者你要复盘的是三个月前的某个决定,当时压根没人想到要做实验。
这时候你手里只剩一样东西:历史数据。
A/B适合提前设计实验,验证未来。因果推断,适合利用已发生的历史数据,做事后归因。前者管「接下来该不该做」,后者管「上次那件事到底有没有用」。两者填补的是不同的盲区。
事后归因中,有两个最常用、也最值得先掌握的方法。
第一个是PSM,倾向得分匹配。
它的思路极其朴素:既然没法随机分组,那我就在历史数据里,人工找出条件尽量相似的两组人。
用了新功能的用户中,挑一个活跃度中等、注册三个月、城市在二线的。
我就到没用过新功能的用户里,去找一个活跃度、注册时长、城市都尽量一致的人,把他们配成一对。一对一对地配下去,配出两组在各项特征上高度接近的人群。两组的唯一系统性差别,回到只剩「用没用新功能」。这时再比留存,就接近于在比「同一类人,用与不用的差」。
PSM是在历史数据里,尽力把A/B的随机分组「补」出来。它应对的,正是第二节提到的混淆变量。
但PSM有个命门:它只能匹配你**观测得到**的变量。活跃度、注册时长、城市,这些表里有的,它能配平;可那些没进表的暗变量,比如用户的真实意图、被竞品影响的程度,它一个都够不着。两个人各项特征都配成一对,却可能在某个你没记录的维度上天差地别。PSM补的是你看得见的那部分偏差;看不见的那部分,它无能为力。
第二个是DiD,双重差分。
它要解决的是裸差中最核心的问题:怎么把大盘趋势扣掉。
DiD的做法是找一个对照组,一群没受到你这次改动影响、但跟你的目标用户走在同一条大盘趋势上的人。然后做两次相减。第一次,算你的目标用户上线前后的变化。第二次,算对照组在同一段时间里的变化。最后,用前者减去后者。
对照组那段变化,代表的是「就算什么都不做,大盘自己也会走出来的趋势」。用它去扣除,剩下的才是真正归因于你这次改动的净效果。裸差只做了第一次相减,DiD多减了一次,把混在里面的大盘趋势剔除掉了。
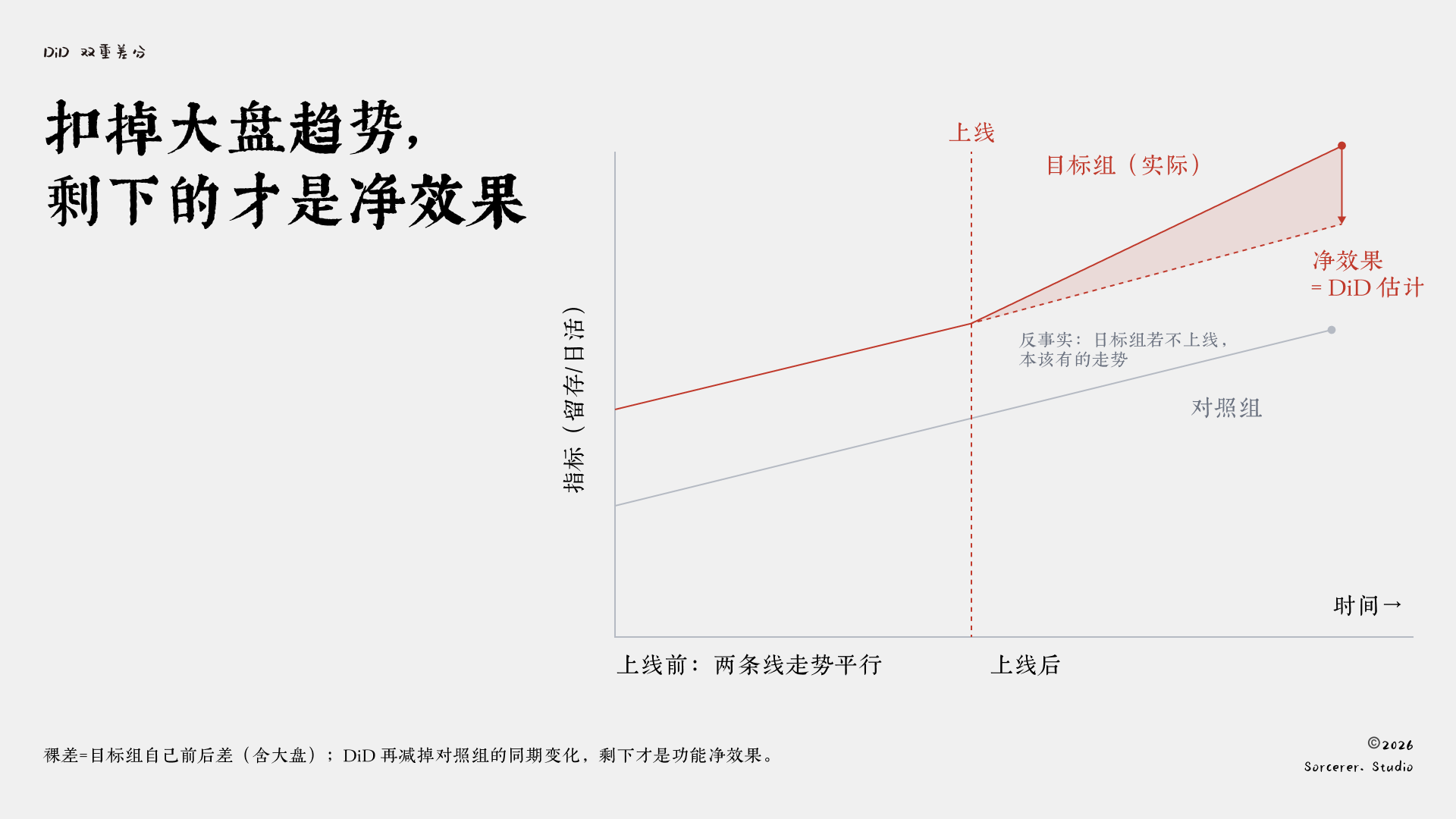
上线后目标组真实走势,减去它「没上线本该走的」那条反事实虚线(即沿对照组趋势平移),中间那道缺口才是净效果。裸差错把整段抬升都算成功能的功劳。
但DiD有一个关键前提,平时最容易被默认成立,叫平行趋势。
它要求:在你上线之前,目标组和对照组的指标趋势必须是平行的——两条线可以高低不同,但走势得一致。只有这样,你才能假设「要是没上线,它俩之后也会继续平行」,从而用对照组去代表目标组本该有的走势。
这个前提不能拍脑袋默认。你必须把上线前足够长一段时间的两条曲线拉出来,亲眼确认它们确实平行。如果上线前两条线就在收敛或发散,那DiD的整个地基就是歪的,算出来的净效果照样是假的。
你可能会说:现实里两条线几乎不可能完美平行,那DiD是不是基本没用?不是。
平行趋势不是一个「是或否」的开关,而是一个程度问题。上线前贴得越紧、越长一段时间同向,结论就越可信;偏离越明显,你就越该给净效果打个折,标上「仅供参考」。
它给你的本就不是真值,只是一个比裸差靠谱得多的估计。把「无法做到完美」直接当成「干脆不做」,是另一种偷懒。
PSM补的是「人群不可比」,DiD补的是「大盘没扣掉」。
两者还有一层高下:PSM只能控住你观测到的变量,DiD靠「相减」这个动作,连那些你没观测到、却不随时间变的差异,也一并扣掉了。这也是后面那条决策链里,DiD排在PSM前面的原因。它们都不如A/B干净,但当你只剩历史数据时,它们是你离真相最近的两条路。
五、AI时代的新风险:门槛降低,误用放大
看到这里,有人会想:这些方法听着就麻烦,PSM、DiD、平行趋势检验,还不如把数据丢给AI,让它帮我跑。
AI确实能跑。今天你把一张表丢给它,它能帮你做匹配、算双重差分、画出趋势图、给出一个带置信区间的漂亮结论。建模的门槛,确实被实实在在地拉低了。
问题是,AI能替你跑模型,但它替不了你做判断。
它判断不了,你这张表里哪些变量是混淆变量。
混淆变量是业务概念,不是数据特征。你得知道「高活跃的人本来就爱用新功能」,才会想到把活跃度放进匹配;AI看到的只是一列数字,它不知道这列数字在你的业务语境里意味着什么。
它判断不了,你的哪些假设其实站不住。
平行趋势成不成立,SUTVA破没破,这些要靠你对产品的理解去质疑。AI默认你给的前提都对,它只负责在你的前提上往下算。
它更判断不了,那些根本没进入数据的业务暗变量。
那次留存上涨,也许是因为同期一个竞品出了大故障,用户回流到了你这儿。这件事不在任何一张表里,AI永远不会知道,但它恰恰是真正的原因。
于是AI时代最危险的复盘,不是拍脑袋。拍脑袋至少所有人都知道那是拍脑袋,会本能地存一份怀疑。
最危险的,是用一组错误的假设,跑出了一个看起来无比科学的结论。它有模型,有p值,有置信区间,有一张严谨的图表。它把「我猜的」包装成了「数据证明的」。
一屋子人看着那张图点头,没有人再去问那个最该问的问题:这些假设,到底成不成立?
工具越强,那个被跳过的判断,代价就越大。
AI没有降低做因果归因的难度,它只是把难的部分从「算」挪到了「想」。而「想」这部分,至今没有任何工具能替你完成。
六、少变一点,优先于多算一点
讲完这些方法,最后我想把它压成一条可以随身带走的原则。
回头看这一路:裸差不可信,是因为变量太多。
三类误判会骗人,是因为有看不见的变量在搅局。A/B之所以强,是因为它用随机化,把变量这件事一次性摁住了。PSM和DiD之所以要费那么大力气,是因为它们在历史数据里,亡羊补牢地去控制那些当初没能控住的变量。
所有方法都在干同一件事:让变化的东西尽可能少。
少变一点,优先于多算一点。
我们做归因时的本能,是想算得更复杂、更全面、更高级,上更花哨的模型。
但归因可信度的真正来源,从来不是算法多精巧,而是除了你关心的那个变量,别的东西变得有多少。能在源头上少变一个变量,胜过事后用十个模型去补救。
把这条原则展开,就是一条清晰的决策链:
第一步,能做随机A/B,就做A/B。这是控制变量最干净的方式,没有之一。只要场景允许、伤害可控、又不存在SUTVA那种相互干扰,优先用随机化把变量摁死在源头。
第二步,A/B做不了,但你有一个干净的对照组,就用DiD。全量上线了、改版没法切一半、要复盘的是过去的事,这些时候,找一个走在同一条大盘趋势上的对照组,用双重差分把趋势扣掉。前提是先确认平行趋势,别默认。
第三步,连干净的对照组都没有,只能在历史数据中匹配,就考虑PSM。人工配出条件尽量相似的两组人,逼近「同一种人用与不用」的对比。它最不稳,但有时是你唯一的路。
第四步,如果连匹配的假设都站不住,就承认这次无法归因。
最后这一步最难,也最值钱。承认「我无法判断这个功能到底有没有用」,远比硬编一个三个百分点的成绩单要诚实,也要安全。
一个诚实的「不知道」,不会把你引向错误的下一步决策;一个伪造的「有效」,会。
有人会立刻反驳:老板就是要一个数,我说「无法归因」,挨骂的是我。
这话没错。但「无法归因」不等于「两手一摊」,你可以给一个带条件的答案:在平行趋势大致成立的前提下,净效果大概落在某个区间;这几个假设一旦松动,结论就不作数。
把假设和不确定性一起交出去,比单递一个干净却虚假的数字,既更诚实,也更经得起追问。真正会让你挨骂的,是那个你拍着胸脯保证、半年后被证伪的「3个点」。
产品复盘的目的,从来不是给一个功能颁奖,而是为下一个决定找准方向。而找准方向的前提,是你算的那个效果,得是真的。
下次再写复盘PPT,落笔那个「效果」数字之前,先问自己一句:这段时间里,除了我的功能,还有什么也变了?
把这个问题追问到底,就已经躲开了产品复盘里最贵的那个错觉。
本文由 @巫师Sorcerer 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









复盘更多的总结过往成功或者失败的经验,这些积累会让我们下次遇到同类或某一些新的项目可以得心应手
裸差那段说得特别透——不是减法算错了,而是把所有变化都记在自己头上。补充一点:即使你做了A/B,如果实验组和对照组的用户画像在实验期间因外部投放而漂移,结果同样会偏。所以上线前锁定用户分桶、监控画像稳定性也是落地条件。