
 起点课堂会员权益
起点课堂会员权益AI生成界面语义漂移怎么救?一套组件语义快照方法论
当AI从辅助设计转向直接生成界面,语义漂移正成为行业痛点。本文提出「组件语义快照」方法论,通过6个标准字段结构化记录界面证据,揭示6种通用漂移模式,并构建从观察到契约的完整技术闭环。带你看懂如何用Schema-As-Code守住AI产品的语义边界。

阶段一总结:从观察到模式
本文是 把设计规范写成代码格式(Schema-As-Code) 方法论的阶段一总结。核心回答三个问题:
- 怎么观察 AI 产品的语义漂移?(方法论定义)
- 观察到了什么?(证据库展示,简化版)
- 这些观察怎么变成可执行的契约?(技术架构论证,简化版)
摘要
AI 正在从”辅助设计”走向”直接生成界面”。当界面从”人画”变成”AI 猜”,一个新的问题出现了:
AI 生成的界面,意思对不对?
同样的红色按钮,在这个场景下是”删除”,在那个场景下是”保存”,AI 可能分不清楚。同样的”严重”一词,在告警场景下情绪权重被降级,用户可能低估风险。
这不是某个产品的 Bug,而是概率性生成带来的固有特性(内禀属性):AI 没有”语义一致性”的概念,它只有”概率最接近”。
本文提出组件语义快照(Component Semantic Snapshot)作为观察方法,通过 6 个标准字段记录界面证据,归纳出 6 种通用漂移模式,为后续”约束显化”提供第一手素材。
1. 观察方法:组件语义快照
1.1 为什么不是普通截图?
普通截图只有像素信息,没有语义信息。一张 ChatGPT 报错截图,三个月后回看,你可能已经忘了:
- 这是”什么类型”的组件?
- 用户”怎么困惑”的?
- 在”什么场景”下触发的?
组件语义快照是一种结构化的界面证据收集方法。在截图之上增加 6 个标准字段,让任何人在任何时间看到这张快照时,都能立刻理解问题全貌。
1.2 6 个标准字段
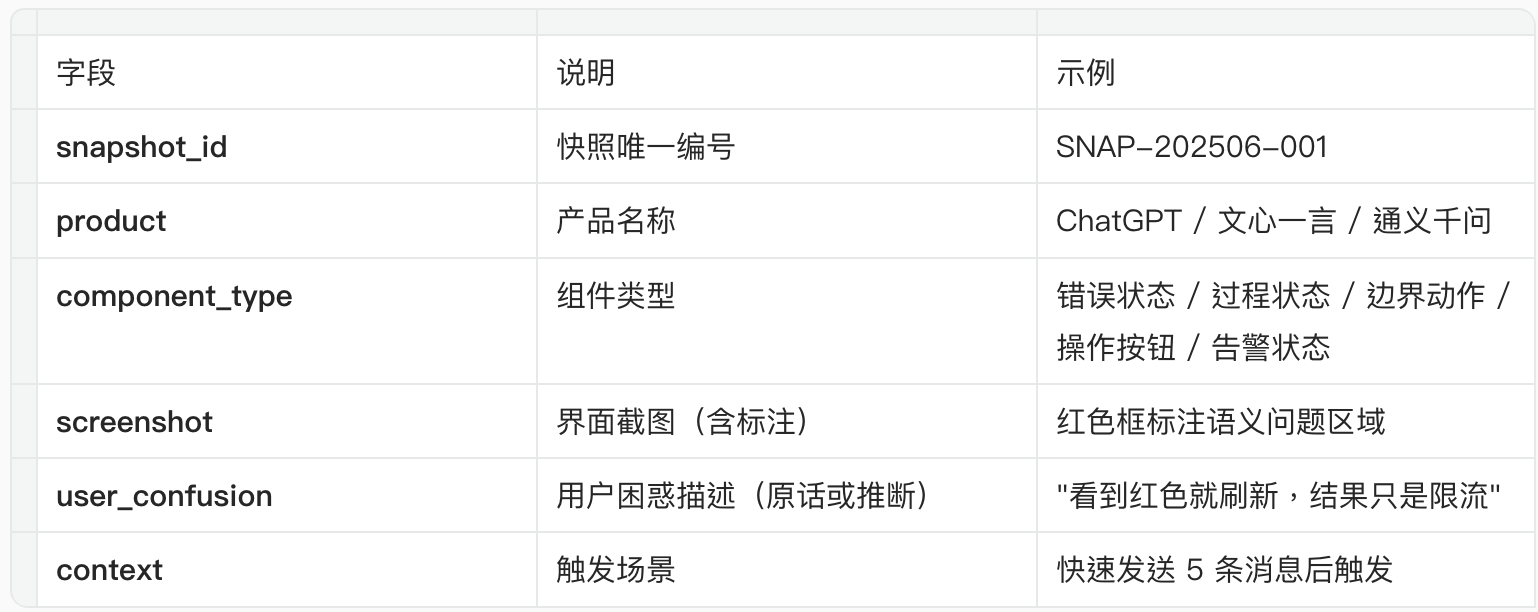
1.3 完整示例
SNAP-202506-001
- product: ChatGPT
- component_type: 错误状态
- screenshot: [红色框标注:4 种错误共用红色背景/文字]
- user_confusion: “看到红色就刷新,结果只是限流。红色让我以为系统崩了。”
- context: 高峰期快速发送 5 条消息后触发
- 匹配模式: ERR-001(后果差异未分级)
2. 产品观察:8 类 AI 产品的语义漂移证据
通过对 8 类 AI 产品的界面观察,发现语义漂移不是个案,是行业共性问题。
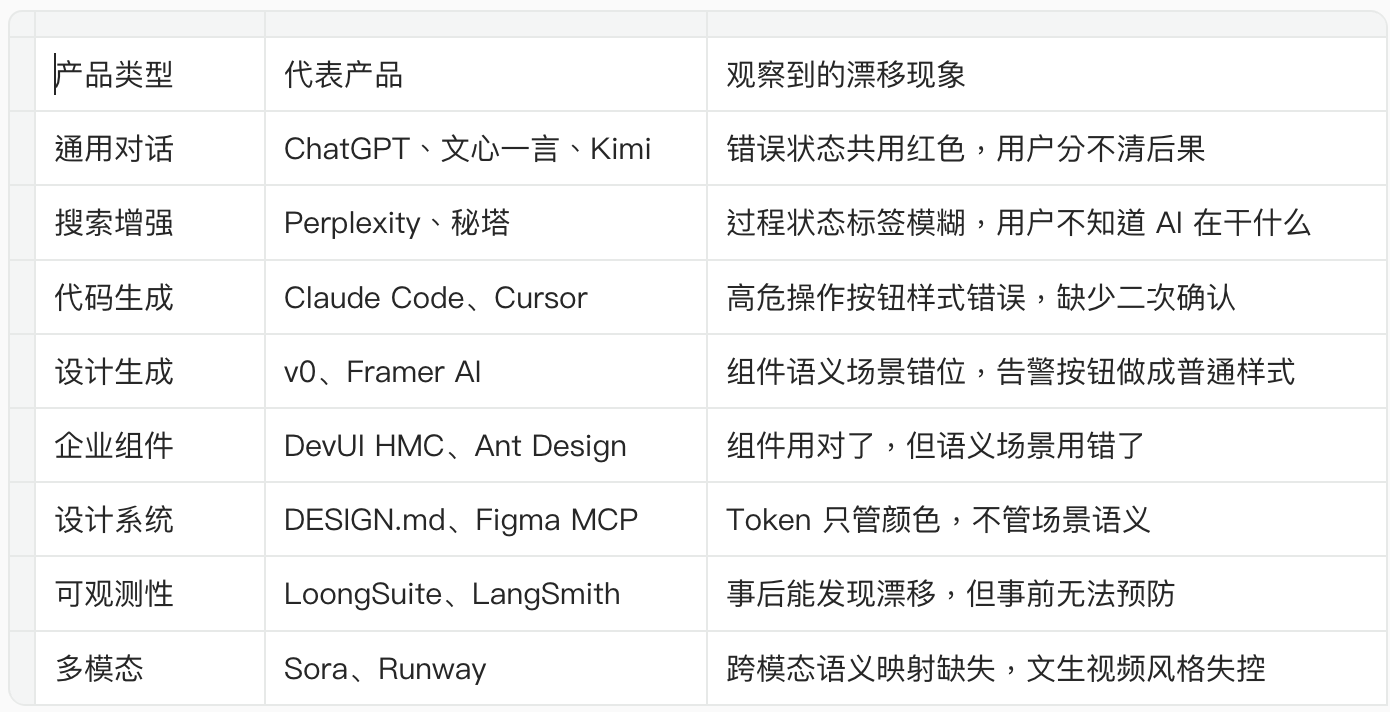
简化说明:完整证据库(含截图、用户抱怨、触发场景)见模式库详情页。本文仅展示归纳结论。
3. 组件分类与模式库:从证据到规律
3.1 5 种组件类型
语义漂移不是随机发生的,它集中在 5 类高频交互组件上:

3.2 6 个漂移模式(模式库 v0.1)
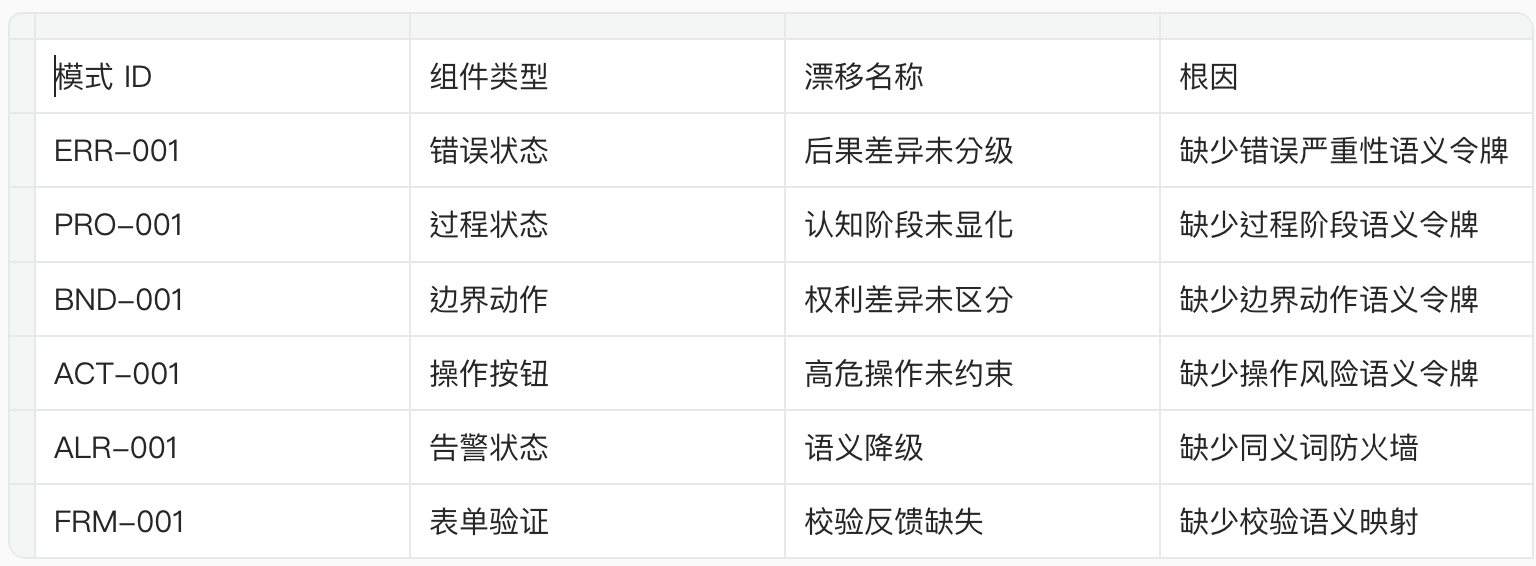
简化说明:每个模式的完整证据(截图、用户抱怨、YAML 契约)见模式库独立页面。
4. 诊断流程:3 个问题定位模式
模式库不是让用户”翻找”,而是通过结构化问诊自动匹配。
4.1 诊断机制
机制 1:这是什么类型的组件?
- 错误状态(用户遇到故障时看到的)
- 过程状态(AI 干活时显示的进度)
- 边界动作(AI 拒绝/终止/升级时)
- 操作按钮(用户点击执行的)
- 告警状态(系统状态提示)
机制 2:用户的核心困惑是什么?
- 不知道多严重(后果差异)
- 不知道在干什么(认知阶段)
- 不知道权利还在不在(权利差异)
- 不知道能不能点(操作风险)
- 不知道词对不对(语义降级)
机制 3:当前界面用什么视觉表达?
- 全部红色 / 全部灰色 / 没有区分 / 文案模糊
4.2 输出结果
回答 3 个问题后,系统自动匹配模式 ID,输出:
- 模式定义(这是什么)
- 同类产品证据(3-5 个产品截图)
- 用户抱怨证据(社区截图)
- YAML 契约模板(可直接复制)
5. 技术架构:从观察到契约的流转
5.1 核心流转:Code-Text-Code
观察到的界面证据(截图/文本)→ 写成结构化文本(YAML 契约)→ 编译成机器可执行代码(Prompt 前缀 / 校验规则)。
5.2 分工架构:AI 生成 + 规则把关
- AI 负责生成:发挥创造力,快速产出界面
- 规则负责把关:守住语义边界,防止漂移
5.3 四级审查流程
人工审核 → 系统判决 → 人工修正 → 系统验证。
简化说明:完整技术架构(Registry / Compiler / Validator / Runtime / Bridge 五模块)见工程实现文档。本文仅保留核心流转逻辑。
6. 可运行代码示例:简单的语义分级器
以下是一段可直接运行的 Python 脚本,演示如何用规则对 AI 产品的错误文案进行语义分级:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
“””
语义分级器示例:基于关键词匹配的错误状态分级
运行方式:python semantic_classifier.py
“””
# 定义分级规则库
RULES = {
“fatal”: {
“keywords”: [“stream”, “断开”, “中断”, “context lost”, “会话丢失”],
“level”: “致命”,
“color”: “红色脉冲”,
“user_action”: [“刷新页面”, “导出历史”],
“reason”: “对话上下文可能丢失,需要明确恢复路径”
},
“transient”: {
“keywords”: [“network”, “网络错误”, “加载失败”, “connection lost”, “连接失败”],
“level”: “网络抖动”,
“color”: “灰色加载”,
“user_action”: [“等待自动恢复”, “手动重试”],
“reason”: “系统可自动恢复,避免用户恐慌性刷新”
},
“retryable”: {
“keywords”: [“429”, “throttling”, “请求过于频繁”, “服务繁忙”, “限流”, “rate limit”],
“level”: “限流/流控”,
“color”: “黄色提示”,
“user_action”: [“等待倒计时”, “升级套餐”],
“reason”: “用户可自助恢复,需要提供倒计时和升级路径”
},
“degraded”: {
“keywords”: [“something went wrong”, “创造失败”, “服务异常”, “部分失败”, “部分可用”],
“level”: “部分可用”,
“color”: “蓝色提示”,
“user_action”: [“继续生成”, “简化问题重试”],
“reason”: “部分功能可用,需要说明哪些功能正常”
}
}
def classify_error(text):
“””
对输入的错误文案进行语义分级
返回:(分级结果, 建议视觉, 用户行动, 原因)
“””
text_lower = text.lower()
for rule_id, rule in RULES.items():
if any(kw.lower() in text_lower for kw in rule[“keywords”]):
return {
“rule_id”: rule_id,
“level”: rule[“level”],
“color”: rule[“color”],
“user_action”: rule[“user_action”],
“reason”: rule[“reason”],
“confidence”: “high”
}
return {
“rule_id”: “unknown”,
“level”: “未识别”,
“color”: “灰色中性”,
“user_action”: [“人工审核”],
“reason”: “未匹配到已知规则,建议补充到规则库”,
“confidence”: “low”
}
def print_diagnosis(result):
“””打印诊断结果”””
print(f”\n{‘=’*50}”)
print(f”语义分级结果”)
print(f”{‘=’*50}”)
print(f”分级: {result[‘level’]} ({result[‘rule_id’]})”)
print(f”建议视觉: {result[‘color’]}”)
print(f”用户行动: {‘ / ‘.join(result[‘user_action’])}”)
print(f”原因: {result[‘reason’]}”)
print(f”置信度: {result[‘confidence’]}”)
print(f”{‘=’*50}\n”)
if __name__ == “__main__”:
# 测试用例
test_cases = [
“Error in message stream”,
“network error”,
“请求过于频繁,请稍后再试”,
“Something went wrong”,
“连接断开,请刷新页面”
]
print(“\n语义分级器测试开始…”)
for text in test_cases:
print(f”\n输入: “{text}””)
result = classify_error(text)
print_diagnosis(result)
运行结果示例:
语义分级器测试开始…
输入: “Error in message stream”
==================================================
语义分级结果
==================================================
分级: 致命 (fatal)
建议视觉: 红色脉冲
用户行动: 刷新页面 / 导出历史
原因: 对话上下文可能丢失,需要明确恢复路径
置信度: high
==================================================
输入: “请求过于频繁,请稍后再试”
==================================================
语义分级结果
==================================================
分级: 限流/流控 (retryable)
建议视觉: 黄色提示
用户行动: 等待倒计时 / 升级套餐
原因: 用户可自助恢复,需要提供倒计时和升级路径
置信度: high
==================================================
7. 工程实现:Semantic Pipeline
7.1 三阶段衔接
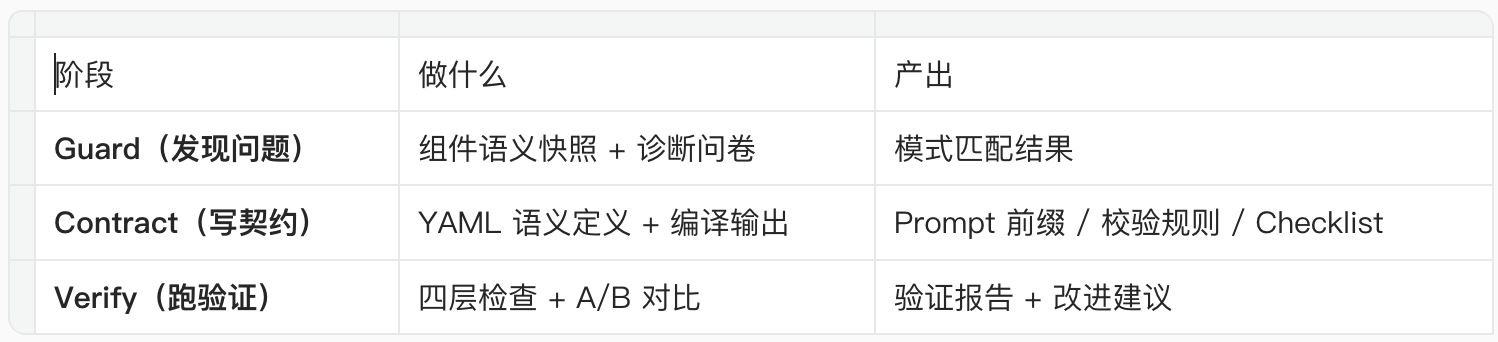
7.2 消费方工作流

8. 定位:不是替代,是叠加
现有工具(v0、Claude Code、DevUI HMC)解决”怎么写代码”。
Schema-As-Code 解决”这个场景下必须表达什么语义、不能突破什么边界”。
关系:Schema-As-Code 是所有形态层工具的上游约束层。
9. 组织经济学价值

9. 下一阶段预告:从观察到约束
阶段一(本文)解决了”发现问题”:
- ✅ 有了观察方法(组件语义快照 6 字段)
- ✅ 有了证据库(6 个漂移模式)
- ✅ 有了诊断工具(3 问题问卷)
阶段二(即将发布)解决”写出契约”:
- 契约工作台(Contract Library):浏览所有 YAML 契约,一键复制 Prompt 前缀 / Checklist / CI 规则
- 语义令牌规范:Design Token 之上叠加 Semantic Token,让颜色携带场景语义
- Prompt 前缀模板:前端工程师直接复制粘贴到 Claude Code / Cursor 指令里
阶段三(即将发布)解决”验证闭环”:
- 验证实验室(Validation Toolkit):输入任意 AI 生成的文案/组件,跑四层检查,看有契约 vs 无契约的对比
- 在线分级器:输入错误文案,自动匹配 Fatal/Transient/Retryable/Degraded 分级
- 语义漂移观测 Dashboard:设计时约束 + 运行时归因,双轨闭环
下一步行动:
如果你也想开始观察自己产品的语义漂移,第一步:打开你的 AI 产品,触发一个错误状态,按本文的 6 字段格式记录第一张快照。
第二张会比第一张快 10 倍。
资源
- 语义流水线站点:https://2436041978-ops.github.io/semantic-pipeline/
- 完整模式库及验证工具:见语义流水线站点
Gap 期局限性声明
当前状态: 架构推演与最小可行原型阶段。YAML 规范、校验逻辑为定义层实现,尚未接入生产级 LLM API 或 CI 流水线。欢迎基于现有思路共建。
本文由 @de. 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议








6个标准字段记录界面证据挺实用,但用户困惑这个字段太依赖人工采集,产品侧很难规模化。要是能自动化抓取用户行为日志做语义标注,会更落地一些。